
Wikipedia:Reference desk/Archives/Computing/2008 May 16
| Computing desk | ||
|---|---|---|
| < May 15 | << Apr | May | Jun >> | May 17 > |
| Welcome to the Wikipedia Computing Reference Desk Archives |
|---|
| The page you are currently viewing is an archive page. While you can leave answers for any questions shown below, please ask new questions on one of the current reference desk pages. |
May 16[edit]
MS Word stops spell checking my files in the middle of a page – Why?[edit]
I write with MS Word, and on some documents I get this strange problem where the software stops doing the online spelling and grammar checks write in the middle of a document. For example, on one line, misspelt words are red-underlined, yet on the next and subsequent lines, they are not. I’ve tried to chase the prob down, and copied and pasted passages around and even into completely new documents, but it doesn’t work. It’s like there is some “don’t spell check this text” command written into the text itself, and it just sticks there. I know that this problem is triggered after I have copied some text from an external source into a file, but sometimes this seems to cause a problem, other times it all goes perfectly. Moreover, when I ask for help from MS Word Help thingies, it lists dozens of reasons why the spell checker might not work but not this one. I’m a lover not a techie, so can someone put me straight on this? Myles325a (talk) 02:51, 16 May 2008 (UTC)
- Off the top of my head: You might want to check that the text that isn't being spell-checked isn't set in another language -- that is to say, Word marks all text with a language tag, regardless of the language it's actually written in. That's so that it knows which language it's supposed to be spell-checking for. If the text is in one language but the language tag is wrong, fairly often Word simply appears to ignore it, probably because it can't get a handle on the grammar and none of the words are similar enough to the words of that language to appear misspelled, so it just assumes that they're correct words, but ones that just aren't in its dictionary. You can see the language information displayed on the bottom bar of the Word window. I'm assuming that you're an American, so it should probably say "U.S. English" on the bottom of the bar. Check to see if it changes into something else when you place your cursor there. To make sure (provided that all of the document is indeed written in the same language, of course!), you can just select all of the text in the document with ctrl+a and then select Tools -> Language -> Set Language, and then select "U.S. English" (or whatever language you're writing in) from the menu that pops up.
- Another possible solution is to copy the offending text into Notepad and then copying that text back into Word. That's a fairly classic method of stripping all formatting from the text. It's not that useful if the text is otherwise heavily formatted with italics or in some other way, but it may well do the trick. -- Captain Disdain (talk) 08:44, 16 May 2008 (UTC)
Quick and dirty edge detection?[edit]
I'm trying to write a program that will let me input images taken of type-written documents and will help me convert them in monochromatic bitmaps (to later be turned into PDF pages).
The problem is that the documents are uneven in their lighting. The paper is a hue of gray and at the top of the page it is a lot lighter than the bottom. So just applying a threshold (if pixel brightness > some threshold, make it white, etc.) doesn't help much, because it'll only work locally (what works for one part of the image won't work for another).
It occurred to me that maybe the way to approach this is something like a quick and dirty edge detection algorithm? The relative contrast is pretty similar across the entire document -- that is, the difference between the text and the page is pretty constant, so if I had something that could locally adapt, it would maybe let me easily filter out the page from the text.
I'm doing this in Visual Basic 2005 (VB.NET). I'm having trouble finding an edge detection algorithm that works well with this, in the sense that it must be 1. pretty quick (each image is quite large, say 3300x2500 pixels, and there are many), and 2. not too sensitive to noise. I've played around with a Sobel operator one and it is too slow and too sensitive.
I'm no CS major, and I know when I'm in over my head. Can someone give me some advice? I'm not having too hard a time coding things once I know what to code, but I'm not exactly sure about what I ought to be doing here. --Captain Ref Desk (talk) 04:02, 16 May 2008 (UTC)
- Another wasy is to do a two dimensional Fourier transform on the image and then give it a low pass filter to remove gradual changes in shading. You may be able to use libraries taht include these functions. For edge detection you have to make it work on a big enough scales that noise will not be enhanced too much, else every stray dot will become a black blob. Graeme Bartlett (talk) 05:09, 16 May 2008 (UTC)
- I'll look into that, though glancing at the Fourier transform page itself doesn't give me a great idea of what that would mean in practice... --Captain Ref Desk (talk) 15:28, 16 May 2008 (UTC)
- I have no specific knowledge of this, but this sounds so like what is needed to do decent OCR that I imagine that there are programs out there that will do this for you. -- SGBailey (talk) 10:22, 16 May 2008 (UTC)
- You'd think... but again, remember that most OCR assumes a "flat" image, where paper and text are reliably the same hues. On my images, the darkest paper on part of the image is the same hue as the text on the lightest part. There are local contrast differences (in each place, text and paper have probably a constant difference between them though their hues vary throughout the document). I suspect more OCR software doesn't deal with that sort of thing, it is the sort of thing you'd come up with if you were mad enough to photograph (not scan) the documents. (And why would I do such a thing? Because the Library of Congress Manuscript Room lets you bring in digital cameras, not scanners. The latter are more taxing on the fragile documents themselves than the former.) --Captain Ref Desk (talk) 15:28, 16 May 2008 (UTC)
- I have no specific knowledge of this, but this sounds so like what is needed to do decent OCR that I imagine that there are programs out there that will do this for you. -- SGBailey (talk) 10:22, 16 May 2008 (UTC)
- One way to do something like that would include dividing the whole image into relatively small blocks and applying different thresholds for each of them. However, the blocks should be small enough to allow the assumption of of even lighting in the block and big enough to include at least some text (or you can try to find out if there is any text in the block by analyzing the color distributions - in such case Gaussian distribution could be expected). Then mean intensity should be a good threshold. Maybe this would work? --Martynas Patasius (talk) 14:11, 16 May 2008 (UTC)
- Yeah, I thought of that while laying in bed last night, and I might actually give it a shot. I think, given the geometry of the document and the fact of how the irregularities lie, that breaking the document into, say, five horizontal bands and doing a local contrast on each of those might actually produce OK results. Will give it a go, in any case, sounds like it would be quicker than edge detection and have less of a noise problem. --Captain Ref Desk (talk) 15:28, 16 May 2008 (UTC)
- Many scanners come with software that will convert scans into PDFs directly. The scanner often gives you a choice between gray-scale and black-and-white images. (This type of image is made without doing any Optical Character Recognition; it is just a picture of the page). Don't see why you need to do any edge detection at all. EdJohnston (talk) 15:15, 16 May 2008 (UTC)
- What I have are photographs (digital ones) of documents, not scans. There is a big difference between photographing and scanning a document—on a scanner, the light source is uniform and the distance from the lens is uniform, so this isn't an issue. What I'm talking about using this for is converting grayscale photographs into something that approximates what the same thing would look like scanned; just adjusting contrast levels does not work well (I've tried). --Captain Ref Desk (talk) 15:28, 16 May 2008 (UTC)
- Many scanners come with software that will convert scans into PDFs directly. The scanner often gives you a choice between gray-scale and black-and-white images. (This type of image is made without doing any Optical Character Recognition; it is just a picture of the page). Don't see why you need to do any edge detection at all. EdJohnston (talk) 15:15, 16 May 2008 (UTC)
-
 full original
full original -
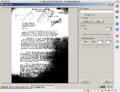 full single
full single -
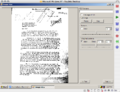 full multi
full multi



-
 zoomed original
zoomed original -
zoomed single
-
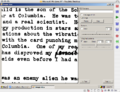 zoomed multi
zoomed multi


{kind=link}
Here's what I've come up with so far. The one on the left shows the original file (nothing applied except grayscale). The middle one shows a simple monochrome with threshold -- not very good results. The last one shows a little algorithm I've done that first breaks the image into a discrete number of horizontal strips, gets the average brightness of each strip, and then factors that into the threshold in a linear way. It doesn't really add any more time to the other monochrome algorithm except that it scans the entire image once to get the averages (it doesn't matter how many horizontal strips you have, it goes through it linearly and just keep track of the averages).
Thoughts? I'm pretty happy with this so far — not as good as one would get with a "true" auto-contrast filter of some sort (which would involve histograms and transformations and etc.) but I don't see any of those easily in the offing (no easily applicable or modifiable code) and the maths are way above my head. This is all done in Visual Basic 2005 (VB.NET), for the curious/disdainful. --Captain Ref Desk (talk) 20:07, 16 May 2008 (UTC)
- I have a (very) quick and dirty idea, but I'm not sure if it's in the realms of what you accept as a solution. How about using a green screen when scanning so that you get easy manipulation of those edges? --Wirbelwindヴィルヴェルヴィント (talk) 03:43, 17 May 2008 (UTC)
- I understand all the words in your reply, but it doesn't make any sense to me. How would I use a green screen in this context? --Captain Ref Desk (talk) 15:44, 17 May 2008 (UTC)
- Nothing, I misunderstood what you're trying to do. I thought you needed the edges of the page. --Wirbelwindヴィルヴェルヴィント (talk) 20:32, 17 May 2008 (UTC)
- I understand all the words in your reply, but it doesn't make any sense to me. How would I use a green screen in this context? --Captain Ref Desk (talk) 15:44, 17 May 2008 (UTC)
- Have you at least tried to use a good OCR program? It seems that dealing with dirty inputs would be their main area of advancement. --Sean 12:33, 21 May 2008 (UTC)
- The problem is not getting an OCR of it. The problem is that the subsequent files are too large and ungainly for practical use. I have not found an OCR program that would output the image in a useful form. --Captain Ref Desk (talk) 00:15, 23 May 2008 (UTC)
MICROSOFT VISIO 2007[edit]
Is this downloadable for free in any way?
(preferably not the trial because I've already found that —Preceding unsigned comment added by 203.217.35.134 (talk) 06:22, 16 May 2008 (UTC)
- Software piracy? Or else why on earth would Microsoft distribute its software for free when they charge a couple of hundred bucks for a hard copy? --antilivedT | C | G 07:30, 16 May 2008 (UTC)
Starcraft 2 is considering having their Creep Colonies to damage enemy buildings[edit]
Starcraft 2 is considering having their Creep Colonies to damage enemy buildings. I have 3 questions:
Is it possible for their game engine to make it so that the creep actually deals a maximum of 40 damage/second to an enemy, but if say there are 4 Marines, each Marine will take 10 damage/second? (Axiom: that Creep Colonies damage units instead of buildings, simply having enemy units stand on top of the Creep, or the Creep growing to the point that the Creep is under enemy feet. We are NOT talking about Sunken Colonies.)
Is it possible for their game engine to make it so that the creep actually deals a maximum of 40 damage/second to an enemy, but if say there are 4 Marines, each Marine will take 10 damage/second? (Axiom: that Creep Colonies damage units and buildings, simply having enemy units stand on top of the Creep, or the Creep growing to the point that the Creep is under enemy feet. We are NOT talking about Sunken Colonies.)
If this is not possible for Starcraft 2, is it possible for other games? Like other strategy games? What I am asking, is that can other games calculate damage in this way? (In this aoe-max-dmg-style?) Thanks.68.148.164.166 (talk) 09:00, 16 May 2008 (UTC)
- Of course any of this can be implemented without any difficulty, if the developer so wishes. I don't know what will be Blizzard's decision on the matter and why, but this is probably not the best place to discuss it (did you try the StarCraft 2 forum)? -- Meni Rosenfeld (talk) 09:42, 16 May 2008 (UTC)
- Not only is it possible, StarCraft's parent company already has something like this in one of their other game, World of Warcraft, where some area effect (AoE) spells split the damage when there are more than a certain number of targets. So yes, this is definately possible for Blizzard to implement into StarCraft II. --Wirbelwindヴィルヴェルヴィント (talk) 03:39, 17 May 2008 (UTC)
Windows XP compatibility[edit]
I have a program that was originally written for Windows 95 that I need to get running in XP/Vista. As far as I can tell there are no real compatibility issues, the program starts up fine, and it's a really simple program actually, just picture and text and like "links", but there is a line in the program that checks the Windows version and it tells you to "Run this program in Windows95" and quits if it doesn't find the correct version. For some reason it works in 98 (maybe me?) but the error message comes up in XP/Vista. I've heard that there are ways I can get around this, I guess by tricking it into thinking that I'm running Win95 before the program runs. Can anybody steer me in the right direction? Thanks a lot! 222.158.118.22 (talk) 09:33, 16 May 2008 (UTC)
- Try compatibility mode. Right-click the program's icon, select Properties and go to Compatibility. — Matt Eason (Talk • Contribs) 10:01, 16 May 2008 (UTC)
- Changing the compatibility mode doesn't work, because there are no real compatibility issues with the program, it runs fine. Whoever programmed it simply didn't want users of other operating systems trying to use it though, so s/he programmed a check into the program that can recognize it as non-95, and even in 95 compatibility mode it still says "please run this program in Windows 95". I've downloaded Microsoft Application Compatibility tools now, and I still can't get it to run. I'll admit I don't really know how to use this program though. 222.158.118.22 (talk) 10:53, 16 May 2008 (UTC)
Babelfish[edit]
I want the Altavista Babelfish back. If not that, I want the following features from the Altavista Babelfish to return:
- The text you want translated, in a different font.
- When translating a Web page, the text to be larger.
Interactive Fiction Expert/Talk to me 09:36, 16 May 2008 (UTC)
- And how do you hope the Wikipedia reference desk will advance these goals? Algebraist 09:54, 16 May 2008 (UTC)
- Did you know most browsers will do a text zoom for you? For example in Firefox you can go to View -> Text Size -> Increase/Decrease (Ctrl-+, Ctrl--, and Ctrl-0 to go back to default size). --Prestidigitator (talk) 15:59, 16 May 2008 (UTC)
Printing out columns with css[edit]
Is there a simple way of ensuring that columns organised with css divs are printed out more or less as they look on screen?
To be a bit more precise, my content is arranged in two pairs of columns:
XX
XX
where each X represents one column. An example is at http://www.chinese-poems.com/d47test.html . Most of the answers I've come across suggest simply taking out the floats and having the columns print below one another, but the parallel arrangement is important here. Any help much appreciated! HenryFlower 14:34, 16 May 2008 (UTC)
- Place each row in a div vertically aligned to top (assuming the internal divs are not the exact same height). So, you'll have a top row div that contains two divs (one float left and one float right). Then, below that, you'll have another div row with two internal divs (one float left, one float right). Your problem will be that the float will break if the two internal divs cannot be shown side-by-side in the width of the screen. You will have to hard-set a width on the div row to ensure that the two divs can fit. You can force a width using CSS - but you will have to somehow figure out what the width should be. I'd measure it in ems so it gets bigger as the font size gets bigger. -- kainaw™ 15:50, 16 May 2008 (UTC)
Thanks for that; now I have a new problem. The columns are nicely side by side, but when the content is longer than one page, the second row stops at the end of the page rather than continuing onto the next one. Any way round that? HenryFlower 08:10, 20 May 2008 (UTC)
Font in LaTex documents[edit]
What is the default font they use for pdf documents created by Latex? What is the name of that font in MS Office? Borisblue (talk) 16:07, 16 May 2008 (UTC)
- Computer Modern. It's not standard outside the TeX world but is available in TrueType format (link in the article). -- BenRG (talk) 16:19, 16 May 2008 (UTC)
- Latin Modern looks nearly identical except having much more characters and is available in OpenType. 89.76.165.87 (talk) 18:35, 16 May 2008 (UTC)
- You'll notice it doesn't look as nice outside of TeX - you won't get the ligatures for example. --90.203.189.22 (talk) 10:13, 18 May 2008 (UTC)
- Latin Modern looks nearly identical except having much more characters and is available in OpenType. 89.76.165.87 (talk) 18:35, 16 May 2008 (UTC)
IPV6 behaviour[edit]
Hello,
I just installed the IPv6 stack on this Windows XP Home Edition SP3 computer, and I'm currently using Teredo as my ipv6 tunneling gateway (with from time to time 6to4 when I bypass the nat thanks to a direct PPPoE connection).
Now the problem is that even if I can connect to some ipv6 website that only possess an AAAA record, say Google the websites possessing both record like the microsoft research site, having an accessible AAAA record and a useless A record, will make my computer try to connect to those site using ipv4 instead of teredo/6to4 tunneling. End result : I can't access them.
Now I assume there is a priority settings -somewhere- like a metric in a routing table asking my computer to prefer ipv4 address over ipv6. Does anyone have any remote idea where is this settings and how to change it? — Esurnir (talk) 16:16, 16 May 2008 (UTC)
XP specs[edit]
How do you get full fledged info about your computers specs in XP? I mean processor, RAM, graphics, etc. --Randoman412 (talk) 21:10, 16 May 2008 (UTC)
- Try DirectX diagnostics: Start -> Run -> 'dxdiag'. There's also Device Manager: Start -> Control Panel -> Hardware and Sound -> Device Manager (I may have got that path slightly wrong, using Vista here). CaptainVindaloo t c e 21:27, 16 May 2008 (UTC)
- Or possibly Programs -> Accessories -> System Tools -> System Information. --Prestidigitator (talk) 23:03, 16 May 2008 (UTC)
- I'm a fan of the Belarc Advisor. It gives it all to you in a nicely formatted web page. 24.76.169.85 (talk) 08:03, 18 May 2008 (UTC)
- If you have XP Pro, you can do Start > Run > "cmd" > "systeminfo" --67.170.53.118 (talk) 18:23, 19 May 2008 (UTC)
Decent font recognition freeware?[edit]
I want to scan grocery receipts for import to a spreadsheet. I have tried Acrobat Pro (school license) to detect the numbers but it almost always decides to break off in the middle of the line. I have 600DPI uncompressed TIFF scans and have tried downscaling and converting to several other formats. I sorta hate adobe software anyway given their tendency to obfuscate and disable options. I probably should have just given up and paid for the whole bill, but the roommates are stingy and wouldn't make it up to me on the next one and anyway (while I could just hand-type the numbers, or add them all in my head) I'd like a little diversion from work, not to mention a way to make it faster next time around when I don't want the diversion. What " OCR" image-to-text software packages do linux people like to use? Is Ocrad friendly? surely there is something out there for all those people who try to break CAPTCHAs, and all I need is one that can read a standard block font in black on a white background. open source would be nice in case I want to make the program do something besides what the original programmer(s) thought of, but anything that works will work for me. —Preceding unsigned comment added by Kodrin (talk • contribs) 21:26, 16 May 2008 (UTC)
- The only software I have used in the last 10+ years has been "PaperPort." Different versions have came with the last 3 OneTouch Scanners I have purchased. I've liked all three versions of PaperPort I have gotten, but the last I have (version 7.0 dated 2001) is awesome. I OCR stuff all the time and the only time it bombs is when I scan scripts that have a small, itallic, Times Roman font. Even my eyes have problems reading that - A receipt should not be a problem for that software.
- Yeah, I know that's not free because you have to buy it or a new scanner with it, but my last scanner was very cheap ($60 I'm thinking?) and like I said the software that came with it.
- One other thing you might try is dropping DOWN the DPI. I have my best luck with hard to read fonts at 300 DPI and unless the font is small I try even lower - like 150. You may be scanning such a large file that your PC has less resources to OCR what it just scanned. I have even taken digital photographs of pages that looked pretty rough and PaperPort OCR'd it OK.
- --Wonderley (talk) 10:45, 17 May 2008 (UTC)
Setting the time on a Linksys router[edit]
Apparently Linksys routers do not provide any means to allow a user to manually adjust the internal time clock. Does anyone know of a way to do it despite it not being a supported feature? —Preceding unsigned comment added by 72.94.50.11 (talk) 22:24, 16 May 2008 (UTC)
- Darn good question. My WRT54G (firmware version 8.2.03) also doesn't seem to have any setting for this other than timezone and whether to automatically adjust for daylight savings (given the lack of other settings, I'm not sure how you'd manually adjust for DST... O.o ). There isn't even a place to specify an NTP server. I guess it just has one hardcoded (yep; see [1]). That's a little disappointing. I'm happy with all other aspects of the admin interface so far. --Prestidigitator (talk) 23:42, 16 May 2008 (UTC)
- I doubt if what you are wanting to do can be done with a Linksys router. Although, Linksys routers are made by Cisco, Cisco router offer a whole lot more - but, cost more too. However, I called Linksys about something else that I thought for sure could not be done many years ago and I was wrong. It wasn't mentioned in the book and I can understand why my bizarre need was not mentioned. I LOVE Linksys. Any time I work on personal networks I go Linksys and I have been very impressed. Just last week I set up my niece in her new place with wireless and had a problem because she could not load SP2 on her Win XP. In a very short period of time Linksys had me working through a work-a-round.
- Even if the router does not do what you want to do, when I called I was talking to a human in less than 5 minutes. Ask them and worst case senerio, they tell you what you need and maybe explain why it can't easily do what you want.--Wonderley (talk) 10:25, 17 May 2008 (UTC)
- If your router supports them, Tomato Firmware, DD-WRT, and other third-party firmware let you choose an NTP server, though their web interfaces don't let you actually change the time manually as far as I'm aware. You may be able to SSH/Telnet in and enter some command to do it manually, but I'm not sure - you'd best ask on the forums for the respective firmware. 24.76.169.85 (talk) 07:57, 18 May 2008 (UTC)
- Hope it helps, although I have not verified it on the original Linksys'es firmware:
C:\Documents and Settings\kuba>telnet 192.168.1.1 DD-WRT v23 SP2 std (c) 2006 NewMedia-NET GmbH Release: 09/15/06 (SVN revision: 3932) DD-WRT login: root Password: ~ # date Thu May 22 16:50:01 UTC 2008 ~ # date 01020304 Wed Jan 2 03:04:00 UTC 2008 ~ # date 05221654 Mon May 22 16:54:00 UTC 2008