Least mean squares (LMS) algorithms are a class of adaptive filter used to mimic a desired filter by finding the filter coefficients that relate to producing the least mean squares of the error signal (difference between the desired and the actual signal). It is a stochastic gradient descent method in that the filter is only adapted based on the error at the current time. It was invented in 1960 by Stanford University professor Bernard Widrow and his first Ph.D. student, Ted Hoff.
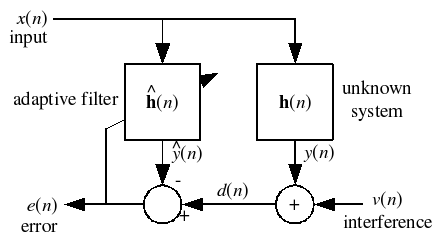
Most linear adaptive filtering problems can be formulated using the block diagram above. That is, an unknown system  is to be identified and the adaptive filter attempts to adapt the filter
is to be identified and the adaptive filter attempts to adapt the filter  to make it as close as possible to , while using only observable signals
to make it as close as possible to , while using only observable signals  ,
,  and
and  ; but
; but  ,
,  and
and  are not directly observable. Its solution is closely related to the Wiener filter.
are not directly observable. Its solution is closely related to the Wiener filter.
definition of symbols
![{\displaystyle \mathbf {x} (n)=\left[x(n),x(n-1),\dots ,x(n-p+1)\right]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5a9144713e4baa446220f201d7892010076e6e9e)
![{\displaystyle \mathbf {h} (n)=\left[h_{0}(n),h_{1}(n),\dots ,h_{p-1}(n)\right]^{T},\quad \mathbf {h} (n)\in \mathbb {C} ^{p}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c1220711a49789eabbf8ad814d71e7c3ea8155c)



Idea
The idea behind LMS filters is to use steepest descent to find filter weights which minimize a cost function.
We start by defining the cost function as

where is the error at the current sample 'n' and  denotes the expected value.
denotes the expected value.
This cost function ( ) is the mean square error, and it is minimized by the LMS. This is where the LMS gets its name. Applying steepest descent means to take the partial derivatives with respect to the individual entries of the filter coefficient (weight) vector
) is the mean square error, and it is minimized by the LMS. This is where the LMS gets its name. Applying steepest descent means to take the partial derivatives with respect to the individual entries of the filter coefficient (weight) vector

where  is the gradient operator.
is the gradient operator.


Now,  is a vector which points towards the steepest ascent of the cost function. To find the minimum of the cost function we need to take a step in the opposite direction of . To express that in mathematical terms
is a vector which points towards the steepest ascent of the cost function. To find the minimum of the cost function we need to take a step in the opposite direction of . To express that in mathematical terms

where  is the step size(adaptation constant). That means we have found a sequential update algorithm which minimizes the cost function. Unfortunately, this algorithm is not realizable until we know
is the step size(adaptation constant). That means we have found a sequential update algorithm which minimizes the cost function. Unfortunately, this algorithm is not realizable until we know  .
.
Generally, the expectation above is not computed. Instead, to run the LMS in an online (updating after each new sample is received) environment, we use an instantaneous estimate of that expectation. See below.
Simplifications
For most systems the expectation function  must be approximated. This can be done with the following unbiased estimator
must be approximated. This can be done with the following unbiased estimator

where  indicates the number of samples we use for that estimate. The simplest case is
indicates the number of samples we use for that estimate. The simplest case is 

For that simple case the update algorithm follows as

Indeed this constitutes the update algorithm for the LMS filter.
LMS algorithm summary
The LMS algorithm for a  th order algorithm can be summarized as
th order algorithm can be summarized as
| Parameters: |
 filter order filter order
|
|
 step size step size
|
| Initialisation: |

|
| Computation: |
For 
|
|
|
|

|
|

|
where  denotes the Hermitian transpose of .
denotes the Hermitian transpose of .
Convergence and stability in the mean
Assume that the true filter  is constant, and that the input signal is wide-sense stationary.
Then
is constant, and that the input signal is wide-sense stationary.
Then  converges to
converges to  as
as  if and only if
if and only if

where  is the greatest eigenvalue of the autocorrelation matrix
is the greatest eigenvalue of the autocorrelation matrix  . If this condition is not fulfilled, the algorithm becomes unstable and diverges.
. If this condition is not fulfilled, the algorithm becomes unstable and diverges.
Maximum convergence speed is achieved when

where  is the smallest eigenvalue of
is the smallest eigenvalue of  .
Given that
.
Given that  is less than or equal to this optimum, the convergence speed is determined by
is less than or equal to this optimum, the convergence speed is determined by  , with a larger value yielding faster convergence. This means that faster convergence can be achieved when is close to , that is, the maximum achievable convergence speed depends on the eigenvalue spread of .
, with a larger value yielding faster convergence. This means that faster convergence can be achieved when is close to , that is, the maximum achievable convergence speed depends on the eigenvalue spread of .
A white noise signal has autocorrelation matrix  , where
, where  is the variance of the signal. In this case all eigenvalues are equal, and the eigenvalue spread is the minimum over all possible matrices.
The common interpretation of this result is therefore that the LMS converges quickly for white input signals, and slowly for colored input signals, such as processes with low-pass or high-pass characteristics.
is the variance of the signal. In this case all eigenvalues are equal, and the eigenvalue spread is the minimum over all possible matrices.
The common interpretation of this result is therefore that the LMS converges quickly for white input signals, and slowly for colored input signals, such as processes with low-pass or high-pass characteristics.
It is important to note that the above upperbound on only enforces stability in the mean, but the coefficients of can still grow infinitely large, i.e. divergence of the coefficients is still possible. A more practical bound is
![{\displaystyle 0<\mu <{\frac {2}{tr\left[R\right]}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0d44445c12a5b49eb37105fc83b5e3df5c7e9d10)
where ![{\displaystyle tr\left[R\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/87dbb14f68e8e371e0c807485cf9c9e0cb706c67) denotes the trace of . This bound guarantees that the coefficients of do not diverge (in practice, the value of should not be chosen close to this upper bound, since it is somewhat optimistic due to approximations and assumptions made in the derivation of the bound).
denotes the trace of . This bound guarantees that the coefficients of do not diverge (in practice, the value of should not be chosen close to this upper bound, since it is somewhat optimistic due to approximations and assumptions made in the derivation of the bound).
Normalised least mean squares filter (NLMS)
The main drawback of the "pure" LMS algorithm is that it is sensitive to the scaling of its input . This makes it very hard (if not impossible) to choose a learning rate that guarantees stability of the algorithm (Haykin 2002). The Normalised least mean squares filter (NLMS) is a variant of the LMS algorithm that solves this problem by normalising with the power of the input. The NLMS algorithm can be summarised as:
| Parameters: |
filter order
|
|
step size
|
| Initialization: |
|
| Computation: |
For
|
|
|
|
|
|

|
Optimal learning rate
It can be shown that if there is no interference ( ), then the optimal learning rate for the NLMS algorithm is
), then the optimal learning rate for the NLMS algorithm is

and is independent of the input and the real (unknown) impulse response . In the general case with interference ( ), the optimal learning rate is
), the optimal learning rate is
![{\displaystyle \mu _{opt}={\frac {E\left[\left|y(n)-{\hat {y}}(n)\right|^{2}\right]}{E\left[|e(n)|^{2}\right]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/529e6acfc5f4e29be90cbf88167fad783860dce6)
The results above assume that the signals and are uncorrelated to each other, which is generally the case in practice.
sankara lingam mani changed
Proof
Let the filter misalignment be defined as  , we can derive the expected misalignment for the next sample as:
, we can derive the expected misalignment for the next sample as:
![{\displaystyle E\left[\Lambda (n+1)\right]=E\left[\left|{\hat {\mathbf {h} }}(n)+{\frac {\mu \,e^{*}(n)\mathbf {x} (n)}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}-\mathbf {h} (n)\right|^{2}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/18705eafd7fc2a82e519f9cefd9caa5ac6219c73)
![{\displaystyle E\left[\Lambda (n+1)\right]=E\left[\left|{\hat {\mathbf {h} }}(n)+{\frac {\mu \,\left(v^{*}(n)+y^{*}(n)-{\hat {y}}^{*}(n)\right)\mathbf {x} (n)}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}-\mathbf {h} (n)\right|^{2}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a548832404c6ae83e0cf2ca977652c6f942a8060)
Let  and
and 
![{\displaystyle E\left[\Lambda (n+1)\right]=E\left[\left|\mathbf {\delta } (n)-{\frac {\mu \,\left(v(n)+r(n)\right)\mathbf {x} (n)}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}\right|^{2}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6401070ffb4f3da143810178301b7c1b271f1927)
![{\displaystyle E\left[\Lambda (n+1)\right]=E\left[\left(\mathbf {\delta } (n)-{\frac {\mu \,\left(v(n)+r(n)\right)\mathbf {x} (n)}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}\right)^{H}\left(\mathbf {\delta } (n)-{\frac {\mu \,\left(v(n)+r(n)\right)\mathbf {x} (n)}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a54266b1c94d17951480c419fc4352a75602f99)
Assuming independence, we have:
![{\displaystyle E\left[\Lambda (n+1)\right]=\Lambda (n)+E\left[\left({\frac {\mu \,\left(v(n)-r(n)\right)\mathbf {x} (n)}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}\right)^{H}\left({\frac {\mu \,\left(v(n)-r(n)\right)\mathbf {x} (n)}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}\right)\right]-2E\left[{\frac {\mu |r(n)|^{2}}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1bafe15b22dbff4fdf05457fad9d4cba93420418)
![{\displaystyle E\left[\Lambda (n+1)\right]=\Lambda (n)+{\frac {\mu ^{2}E\left[|e(n)|^{2}\right]}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}-{\frac {2\mu E\left[|r(n)|^{2}\right]}{\mathbf {x} ^{H}(n)\mathbf {x} (n)}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f15422607283d5574f28261726f3b68b69fb2fd7)
The optimal learning rate is found at ![{\displaystyle {\frac {dE\left[\Lambda (n+1)\right]}{d\mu }}=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0bfdd63603bd46d57b17a745a4951fc35d4d4a9f) , which leads to:
, which leads to:
![{\displaystyle 2\mu E\left[|e(n)|^{2}\right]-2E\left[|r(n)|^{2}\right]=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8cd365f334fb1d99808f740d1255b8b893d7eb44)
![{\displaystyle \mu ={\frac {E\left[|r(n)|^{2}\right]}{E\left[|e(n)|^{2}\right]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3d03f34c36b43063aa4a98659f6c1fa9e8a3c9f7)
See also
References
- Monson H. Hayes: Statistical Digital Signal Processing and Modeling, Wiley, 1996, ISBN 0-471-59431-8
- Simon Haykin: Adaptive Filter Theory, Prentice Hall, 2002, ISBN 0-13-048434-2
- Simon S. Haykin, Bernard Widrow (Editor): Least-Mean-Square Adaptive Filters, Wiley, 2003, ISBN 0-471-21570-8
- Bernard Widrow, Samuel D. Stearns: Adaptive Signal Processing, Prentice Hall, 1985, ISBN 0-13-004029-0
- Weifeng Liu, Jose Principe and Simon Haykin: Kernel Adaptive Filtering: A Comprehensive Introduction, John Wiley, 2010, ISBN 0470447532
- Paulo S.R. Diniz: Adaptive Filtering: Algorithms and Practical Implementation, Kluwer Academic Publishers, 1997, ISBN 0-7923-9912-9
External links

