
Cascading failure

A cascading failure is a failure in a system of interconnected parts in which the failure of one or few parts leads to the failure of other parts, growing progressively as a result of positive feedback. This can occur when a single part fails, increasing the probability that other portions of the system fail.[1][2] Such a failure may happen in many types of systems, including power transmission, computer networking, finance, transportation systems, organisms, the human body, and ecosystems.
Cascading failures may occur when one part of the system fails. When this happens, other parts must then compensate for the failed component. This in turn overloads these nodes, causing them to fail as well, prompting additional nodes to fail one after another.
In power transmission[edit]
Cascading failure is common in power grids when one of the elements fails (completely or partially) and shifts its load to nearby elements in the system. Those nearby elements are then pushed beyond their capacity so they become overloaded and shift their load onto other elements. Cascading failure is a common effect seen in high voltage systems, where a single point of failure (SPF) on a fully loaded or slightly overloaded system results in a sudden spike across all nodes of the system. This surge current can induce the already overloaded nodes into failure, setting off more overloads and thereby taking down the entire system in a very short time.
This failure process cascades through the elements of the system like a ripple on a pond and continues until substantially all of the elements in the system are compromised and/or the system becomes functionally disconnected from the source of its load. For example, under certain conditions a large power grid can collapse after the failure of a single transformer.
Monitoring the operation of a system, in real-time, and judicious disconnection of parts can help stop a cascade. Another common technique is to calculate a safety margin for the system by computer simulation of possible failures, to establish safe operating levels below which none of the calculated scenarios is predicted to cause cascading failure, and to identify the parts of the network which are most likely to cause cascading failures.[3]
One of the primary problems with preventing electrical grid failures is that the speed of the control signal is no faster than the speed of the propagating power overload, i.e. since both the control signal and the electrical power are moving at the same speed, it is not possible to isolate the outage by sending a warning ahead to isolate the element.
Examples[edit]
Cascading failure caused the following power outages:
- Blackout in Northeast America in 1965
- Blackout in Southern Brazil in 1999
- Blackout in Northeast America in 2003
- Blackout in Italy in 2003
- Blackout in London in 2003
- European Blackout in 2006
- Blackout in Northern India in 2012
- Blackout in South Australia in 2016
- Blackout in southeast South America in 2019
- Countrywide blackout in Kenya 2022
- Countrywide blackout in Kenya 2023
In computer networks[edit]
Cascading failures can also occur in computer networks (such as the Internet) in which network traffic is severely impaired or halted to or between larger sections of the network, caused by failing or disconnected hardware or software. In this context, the cascading failure is known by the term cascade failure. A cascade failure can affect large groups of people and systems.
The cause of a cascade failure is usually the overloading of a single, crucial router or node, which causes the node to go down, even briefly. It can also be caused by taking a node down for maintenance or upgrades. In either case, traffic is routed to or through another (alternative) path. This alternative path, as a result, becomes overloaded, causing it to go down, and so on. It will also affect systems which depend on the node for regular operation.
Symptoms[edit]
The symptoms of a cascade failure include: packet loss and high network latency, not just to single systems, but to whole sections of a network or the internet. The high latency and packet loss is caused by the nodes that fail to operate due to congestion collapse, which causes them to still be present in the network but without much or any useful communication going through them. As a result, routes can still be considered valid, without them actually providing communication.
If enough routes go down because of a cascade failure, a complete section of the network or internet can become unreachable. Although undesired, this can help speed up the recovery from this failure as connections will time out, and other nodes will give up trying to establish connections to the section(s) that have become cut off, decreasing load on the involved nodes.
A common occurrence during a cascade failure is a walking failure, where sections go down, causing the next section to fail, after which the first section comes back up. This ripple can make several passes through the same sections or connecting nodes before stability is restored.
History[edit]
Cascade failures are a relatively recent development, with the massive increase in traffic and the high interconnectivity between systems and networks. The term was first applied in this context in the late 1990s by a Dutch IT professional and has slowly become a relatively common term for this kind of large-scale failure.[citation needed]
Example[edit]
Network failures typically start when a single network node fails. Initially, the traffic that would normally go through the node is stopped. Systems and users get errors about not being able to reach hosts. Usually, the redundant systems of an ISP respond very quickly, choosing another path through a different backbone. The routing path through this alternative route is longer, with more hops and subsequently going through more systems that normally do not process the amount of traffic suddenly offered.
This can cause one or more systems along the alternative route to go down, creating similar problems of their own.
Related systems are also affected in this case. As an example, DNS resolution might fail and what would normally cause systems to be interconnected, might break connections that are not even directly involved in the actual systems that went down. This, in turn, may cause seemingly unrelated nodes to develop problems, that can cause another cascade failure all on its own.
In December 2012, a partial loss (40%) of Gmail service occurred globally, for 18 minutes. This loss of service was caused by a routine update of load balancing software which contained faulty logic—in this case, the error was caused by logic using an inappropriate 'all' instead of the more appropriate 'some'.[4] The cascading error was fixed by fully updating a single node in the network instead of partially updating all nodes at one time.
Cascading structural failure[edit]
Certain load-bearing structures with discrete structural components can be subject to the "zipper effect", where the failure of a single structural member increases the load on adjacent members. In the case of the Hyatt Regency walkway collapse, a suspended walkway (which was already overstressed due to an error in construction) failed when a single vertical suspension rod failed, overloading the neighboring rods which failed sequentially (i.e. like a zipper). A bridge that can have such a failure is called fracture critical, and numerous bridge collapses have been caused by the failure of a single part. Properly designed structures use an adequate factor of safety and/or alternate load paths to prevent this type of mechanical cascade failure.[5]
Fracture cascade[edit]

Fracture cascade is a phenomenon in the context of geology and describes triggering a chain reaction of subsequent fractures by a single fracture.[6] The initial fracture leads to the propagation of additional fractures, causing a cascading effect throughout the material.
Fracture cascades can occur in various materials, including rocks, ice, metals, and ceramics.[7] A common example is the bending of dry spaghetti, which in most cases breaks into more than 2 pieces, as first observed by Richard Feynman.[7]
In the context of osteoporosis, a fracture cascade is the increased risk of subsequent bone fractures after an initial one.[8]
Other examples[edit]
Biology[edit]
Biochemical cascades exist in biology, where a small reaction can have system-wide implications. One negative example is ischemic cascade, in which a small ischemic attack releases toxins which kill off far more cells than the initial damage, resulting in more toxins being released. Current research is to find a way to block this cascade in stroke patients to minimize the damage.
In the study of extinction, sometimes the extinction of one species will cause many other extinctions to happen. Such a species is known as a keystone species.
Electronics[edit]
Another example is the Cockcroft–Walton generator, which can also experience cascade failures wherein one failed diode can result in all the diodes failing in a fraction of a second.
Yet another example of this effect in a scientific experiment was the implosion in 2001 of several thousand fragile glass photomultiplier tubes used in the Super-Kamiokande experiment, where the shock wave caused by the failure of a single detector appears to have triggered the implosion of the other detectors in a chain reaction.
Finance[edit]
In finance, the risk of cascading failures of financial institutions is referred to as systemic risk: the failure of one financial institution may cause other financial institutions (its counterparties) to fail, cascading throughout the system. Institutions that are believed to pose systemic risk are deemed either "too big to fail" (TBTF) or "too interconnected to fail" (TICTF), depending on why they appear to pose a threat.
Note however that systemic risk is not due to individual institutions per se, but due to the interconnections. Frameworks to study and predict the effects of cascading failures have been developed in the research literature.[9][10][11]
A related (though distinct) type of cascading failure in finance occurs in the stock market, exemplified by the 2010 Flash Crash.[11]
Interdependent cascading failures[edit]
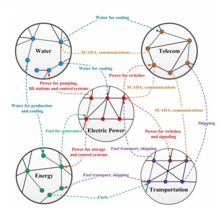
Diverse infrastructures such as water supply, transportation, fuel and power stations are coupled together and depend on each other for functioning, see Fig. 1. Owing to this coupling, interdependent networks are extremely sensitive to random failures, and in particular to targeted attacks, such that a failure of a small fraction of nodes in one network can trigger an iterative cascade of failures in several interdependent networks.[12][13] Electrical blackouts frequently result from a cascade of failures between interdependent networks, and the problem has been dramatically exemplified by the several large-scale blackouts that have occurred in recent years. Blackouts are a fascinating demonstration of the important role played by the dependencies between networks. For example, the 2003 Italy blackout resulted in a widespread failure of the railway network, health care systems, and financial services and, in addition, severely influenced the telecommunication networks. The partial failure of the communication system in turn further impaired the electrical grid management system, thus producing a positive feedback on the power grid.[14] This example emphasizes how inter-dependence can significantly magnify the damage in an interacting network system.
Model for overload cascading failures[edit]
A model for cascading failures due to overload propagation is the Motter–Lai model.[15]
See also[edit]
- Blackouts
- Brittle system
- Butterfly effect
- Byzantine failure
- Cascading rollback
- Chain reaction
- Chaos theory
- Cache stampede
- Congestion collapse
- Domino effect
- For Want of a Nail (proverb)
- Network science
- Network theory
- Interdependent networks
- Kessler Syndrome
- Percolation theory
- Progressive collapse
- Virtuous circle and vicious circle
- Wicked problem
References[edit]
- ^ "Cascading Failure - an overview | ScienceDirect Topics". www.sciencedirect.com.
- ^ Ulrich, Mike. "Chapter 22 - Addressing Cascading Failures". Google - Site Reliability Engineering.
- ^ Zhai, Chao (2017). "Modeling and Identification of Worst-Case Cascading Failures in Power Systems". arXiv:1703.05232 [cs.SY].
- ^ "Why Gmail went down: Google misconfigured load balancing servers (Updated)". 11 December 2012.
- ^ Petroski, Henry (1992). To Engineer Is Human: The Role of Failure in Structural Design. Vintage. ISBN 978-0-679-73416-1.
- ^ Boast, P. Baveye, C. W. (1998). "Fractal Geometry, Fragmentation Processes and the Physics of Scale-Invariance: An Introduction". Revival: Fractals in Soil Science (1998). CRC Press. doi:10.1201/9781315151052. ISBN 9781315151052.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ^ a b Heisser, Ronald H.; Patil, Vishal P.; Stoop, Norbert; Villermaux, Emmanuel; Dunkel, Jörn (28 August 2018). "Controlling fracture cascades through twisting and quenching". Proceedings of the National Academy of Sciences. 115 (35): 8665–8670. arXiv:1802.05402. Bibcode:2018PNAS..115.8665H. doi:10.1073/pnas.1802831115. ISSN 0027-8424. PMC 6126751. PMID 30104353.
- ^ Melton, L Joseph; Amin, Shreyasee (26 June 2013). "Is there a specific fracture 'cascade'?". BoneKEy Reports. 2: 367. doi:10.1038/bonekey.2013.101. PMC 3935254. PMID 24575296.
- ^ Acemoglu, Daron; Ozdaglar, Asuman; Tahbaz-Salehi, Alireza (2015). "Systemic Risk and Stability in Financial Networks". American Economic Review. 105 (2). American Economic Association: 564–608. doi:10.1257/aer.20130456. hdl:1721.1/100979. ISSN 0002-8282. S2CID 7447939.
- ^ Gai, Prasanna; Kapadia, Sujit (2010-08-08). "Contagion in financial networks". Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences. 466 (2120): 2401–2423. Bibcode:2010RSPSA.466.2401G. doi:10.1098/rspa.2009.0410. ISSN 1364-5021. S2CID 9945658.
- ^ a b Elliott, Matthew; Golub, Benjamin; Jackson, Matthew O. (2014-10-01). "Financial Networks and Contagion". American Economic Review. 104 (10): 3115–3153. doi:10.1257/aer.104.10.3115. ISSN 0002-8282.
- ^ "Report of the Commission to Assess the Threat to the United States from Electromagnetic Pulse (EMP) Attack" (PDF).
- ^ Rinaldi, S.M.; Peerenboom, J.P.; Kelly, T.K. (2001). "Identifying, understanding, and analyzing critical infrastructure interdependencies". IEEE Control Systems Magazine. 21 (6): 11–25. doi:10.1109/37.969131.
- ^ V. Rosato, Issacharoff, L., Tiriticco, F., Meloni, S., Porcellinis, S.D., & Setola, R. (2008). "Modelling interdependent infrastructures using interacting dynamical models". International Journal of Critical Infrastructures. 4: 63–79. doi:10.1504/IJCIS.2008.016092.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ^ Motter, A. E.; Lai, Y. C. (2002). "Cascade-based attacks on complex networks". Phys. Rev. E. 66 (6 Pt 2): 065102. arXiv:cond-mat/0301086. Bibcode:2002PhRvE..66f5102M. doi:10.1103/PhysRevE.66.065102. PMID 12513335. S2CID 17189308.
Further reading[edit]
- Toshiyuki Miyazaki (1 March 2005). "Comparison of defense strategies for cascade breakdown on SF networks with degree correlations" (PDF). Archived from the original (PDF) on 2009-02-20.
- Russ Cooper (1 June 2005). "(In)Secure Shell?". RedmondMag.com. Archived from the original on 2007-09-28. Retrieved 2007-09-08.
- US Department of Homeland Security (5 February 2007). "Cascade Net (simulation program)". Center for Homeland Defense and Security. Archived from the original on 2008-12-28. Retrieved 2007-09-08.
External links[edit]
- Space Weather: Blackout — Massive Power Grid Failure
- Cascading failure demo applet (Monash University's Virtual Lab)
- A. E. Motter and Y.-C. Lai, Cascade-based attacks on complex networks, Physical Review E (Rapid Communications) 66, 065102 (2002).
- P. Crucitti, V. Latora and M. Marchiori, Model for cascading failures in complex networks, Physical Review E (Rapid Communications) 69, 045104 (2004).
- Protection Strategies for Cascading Grid Failures — A Shortcut Approach
- I. Dobson, B. A. Carreras, and D. E. Newman, preprint A loading-dependent model of probabilistic cascading failure, Probability in the Engineering and Informational Sciences, vol. 19, no. 1, January 2005, pp. 15–32.
- Nova: Crash of Flight 111 on September 2, 1998. Swissair Flight 111 flying from New York to Geneva slammed into the Atlantic Ocean off the coast of Nova Scotia with 229 people aboard. Originally believed a terrorist act. After $39 million investigation, insurance settlement of $1.5 billion and more than four years, investigators unravel the puzzle: cascading failure. What is the legacy of Swissair 111? "We have a window into the internal structure of design, checks and balances, protection, and safety." -David Evans, Editor-in-Chief of Air Safety Week.
- PhysicsWeb story: Accident grounds neutrino lab
- The Structure and Dynamics of Large Scale Organizational Networks (Dan Braha, New England Complex Systems Institute)
- From Single Network to Network of Networks Archived 2015-11-14 at the Wayback Machine
