I just want to thank you for all your help you have provided in the past few days on some of my articles. You make some good points about notability and significant coverage. Your assist with my edit requests is also appreciated. You also have a great way with words.
In theory the WaybackMachine keeps crawling dead links over time if they come back alive it picks up automatically. You could test this theory by finding an example previously-dead link and checking the WaybackMachine. -- GreenC 15:22, 22 February 2024 (UTC)[reply]
Hello, I am NanoLuuke from Wookieepedia. I am reaching out to you because our editing community has expressed concern regarding our own reliance on the Wayback Machine. For context, much like Wikipedia, our own policy requires the inclusion of archival links (with around 1/6th to 1/5th of our 188000+ pages using web citation), and we use massively the Wayback Machine in this regard. Concerns have emerged from the earliest stages of the Hachette v. Internet Archive case, and with the publication of a recent article by the Jacobin, I'm seeing more and more editors worried that we could lose access to the Wayback Machine in the future. While I'm personally not currently feeling the same level of concern as my fellow editors, I do recognize that properly assessing the ongoing issue is a reasonable thing to do, at minima to appease the worried editors, and if worse must come, to prepare whatever steps we will need to circumvent the possible loss of the Wayback Machine's archives. That is why I wanted to reach out to you, since you seems one of the most knowledgeable editors on Wikipedia regarding web archives. I'm interested in your personal opinion on the matter, and I would also be interested if you could point me toward relevant talk pages if the Wikipedia's community as started discussing the issue. Thanks. NanoLuuke (talk) 13:13, 24 February 2024 (UTC)[reply]
Hi, the only thing I am allowed to report about that case, is to point you to this blog post: What the Hachette v. Internet Archive Decision Means for Our Library. This is the official and only response for the public. I notice the words "Wayback Machine" appear nowhere in that post. It says "The lawsuit only concerns our book lending program." It says "Separately, we have come to agreement with the Association of American Publishers (AAP).." (ie. an agreement has been reached). It says "Our library is still strong, growing, and serving millions of patrons." It says "Because this case was limited to our book lending program, the injunction does not significantly impact our other library services." It further says 'Regarding the monetary payment, we can say that “AAP’s significant attorney’s fees and costs incurred in the Action since 2020 have been substantially compensated by the Monetary Judgement Payment.'" I hope this helps. -- GreenC 16:19, 24 February 2024 (UTC)[reply]
Hello everyone, and welcome to the 24th issue of the Wikipedia Scripts++ Newsletter, covering all our favorite new and updated user scripts since 24 December 2021. Uh-huh, we're finally covering the good ones among the rest! Aren't you excited? Remember to include a link in double brackets to the script's .js page when you install the script, so that we can see who uses the script in WhatLinksHere! The ScriptInstaller gadget automatically does this. Aaron Liu (talk) 01:00, 1 March 2024 (UTC)[reply]
Got anything good? Tell us about your new, improved, old, or messed-up script here!
Making user scripts load faster by SD0001 is this month's featured script, which caches userscripts every day to eliminate the overhead caused by force-downloading the newest version of scripts every time you open a Wikipedia page. Despite being released in April 2021, our best script scouters have failed to locate it due to its omission from the US of L. For security reasons, the script only supports loading JavaScript pages.
Ahecht has created a fork of SiBr4/TemplateSearch, which adds the "TP:" shortcut for "Template:" in the search box, and updated it to be compatible with Vector 2022.
AquilaFasciata/goToTopFast is a much faster fork of the classic goToTop script that also adds compatibility for Minerva and Vector 2022.
Without caching. Each script takes 400–500ms. A particularly large script takes 1.11 s! Internet download speed is 50 Mbps.With caching enabled. Each script takes just 1-2 ms to load.
To a lesser extent, the same goes for PrimeHunter/Search sort. I wish someone would integrate the sorts into the sort menu instead of adding 11 portlet links.
Dragoniez/SuppressEnterInForm stops you from accidentally submitting anything due to pressing enter while in the smaller box, and works on almost anything... except the InputBox element itself, used in subscription lists and the Signpost Crossword! Oh, the humanity!
Doǵu/Adiutor(pictured) provides a nice, integrated interface to do some twinkley tasks such as copyvio detection, CSD tagging, and viewing the most recent diff.
Eejit43 has quite the aesthetically pleasing scripts, all made in TypeScript.
/afcrc-helper is a replacement for the unmaintained Enterprisey/AFCRHS and processes Redirects for Creation and Categories for Creation requests.
/ajax-undo stops the "undo" button from taking you to another page while providing a text box to provide a reason for the revert.
/redirect-helper(pictured) adds a much better interface for editing and redirects, including categorization, for which valid categories are dictated by /redirect-helper.json.
/rmtr-helper helps process technical requested moves without being able to actually move them.
Guycn2/UserInfoPopup(pictured) adds a flyout after the watchlist star on userspace pages that displays the common information you might use about a user.
Jeeputer/editCounter, under userspace, adds a portlet link to count your edits by namespace, put them in a table, and put that table in a hardcoded subpage, all in the background.
Hilst/Scripts/sectionLinks converts all section links to use the § sign, which are known to be preferred over the ugly # by 99% of the devils I've met.
PrimeHunter/Category source.js adds portlet links to tell you where a category for an article comes from and supports those from template transclusions.
Dragoniez/ToollinkTweaks adds more and customizable links next to users in page history, logs, watchlist, recent changes, etc.
Firefly/more-block-info optimizes the display of rangeblocks in contribution pages. Doesn't work outside the English locale of any wiki, unfortunately.
NguoiDungKhongDinhDanh/AjaxLoader makes paging links (e.g. older 50, 500, newest) load without refreshing and makes you realize how slow your internet actually is.
Ahecht/RedirectID adds the redirect target to all redirects. For all the WP:NAVPOPS haters. (Do these exist?)
Dragoniez/MarkBLockedGlobal: Remember the "strike blocked usernames" gadget? Now you can use a red, dotted line to highlight rangeblocks and global locks!
Jonesey/common(pictured) has some styles to overhaul your Vector 2022 experience. It reduces padding everywhere, and makes the top bar animation faster.
Aaron Liu/V22 is a fork that narrows the sidebars instead of upheaving them, reverts the January 2024 dropdown changes, and restores the old page-link color for links that don't go outside the current wiki.
Nardog: SmartDiff is a spiritual successor to Enterprisey/fancy-diffs. It makes the page title part of links in diffs clickable, along with template and parser function calls. Unnamed parameters can be configured per template to also be linked. All links are styled based on the normal CSS classes of rendered links.
For the paranoid: Rublov/anonymize replaces your username at the top of the screen with the generic "User page" text. Remember, it is your duty to persuade everyone that editing is an honor.
/AjaxBlock provides a dialog box for easy input of reasons while blocking users.
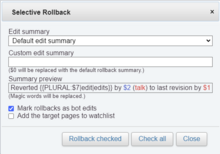
/Selective Rollback(pictured) provides a dialog box to customize rollback edit summaries and does them without reloading the page. Seriously, why doesn't MediaWiki already do this?
/flickrsearch adds a portlet link to search for uploadable flickr images about the subject.
/randomincategory adds a portlet link when on Category pages to go to a random page in the current category.
Vghfr/EasyTemplates adds a portlet link to automatically insert some of the most common inline {{fix}} templates.
Yes, we're just doing 'em as we go now. Thanks for reading through this looong issue, if you did! I'm sure this'll send a record for the longest issue ev-ah. You may need to wait even longer for the last issue, as our reserve of old-y and goodie scripts have ran out... We encourage you to try and do some of the requests or improvement tasks. See you in Summer, hopefully!
I'm going through your instructions, since they appear the easiest to get started with a bot. Thanks for creating them! Should I ask questions here or at the yet-to-be-created red-linked User talk:GreenC/BotWikiAwk? I'll ask here for now...
I know that Toolforge recently changed. I'm hoping that won't be a problem. I already observed that the page User:GreenC/BotWikiAwk/Toolforge says:
Deprecated - Toolforge no longer has a Grid, as of December 2023. These instructions are outdated. A future version of BWA that supports Toolforge concurrency will be forthcoming.
Fortunately, I am new to Toolforge, so I won't bother with trying out the old system. ;)
Questions/comments so far:
(1) I'm at User:GreenC/BotWikiAwk#Setup right now using SSH login to Toolforge. So far so good.
One line that confused me was that I thought "/home/adminuser/BotWikiAwk/lib" should be typed exactly, but I believe "adminuser" is my username. It might be helpful to make that clear in the instructions.
About to try that.
(2) Where it says:
Add BotWikiAwk to the PATH eg.
PATH=$PATH:/home/adminuser/BotWikiAwk/bin
Log out and back in so environment vars are set.
Why does is say to log out and log back in? If I log out, doesn't that clear the variables? I am planning to add it to my .bashrc (or possibly .kshrc or .zshrc [whatever that is]). I haven't used UNIX in about 30 years, so it's only slowly coming back and new features have been added!
Oh, I believe I see the problem. I think you mean it should be added to the .bash_profile just like the other one rather than from the command line... If that line was indented, I think it would be less confusing...
--David Tornheim (talk) 11:39, 16 March 2024 (UTC)[reply]
Well, if your intention is to use it on Toolforge instead of on another computer (home etc.), then I don't know what to do because they recently changed to using containers (in December) and you need to make a custom container since there is no container available for shell tools (that I am aware of)- and I don't know how to make one. If you do install on Toolforge, the PATH will be to wherever BWA was installed, use the 'pwd' command to check. The setup instructions are really for installing anywhere except Toolforge. -- GreenC 14:50, 16 March 2024 (UTC)[reply]
Note that you might also want to export the path. Aaron Liu (talk) 15:18, 16 March 2024 (UTC)[reply]
Hi! I saw your post on Materialscientist's talk and started tracking this problem yesterday. I've just blocked 2.45.126.120 for a month following an edit they made, and will do the same for any similar edits from the same vandal that I come across. Feel free to ping me if you spot any others. Nice to do something different for a change :) —Smalljim 17:46, 20 March 2024 (UTC)[reply]
The Italian editor is persistent over a long period. They don't mind reverts or blocks, as a mobile IP they show up every few days and make a series of subtle changes to numbers (heights of buildings and mountains). Mostly it's been in the 2.44.0.0 and 2.45.0.0 Class B ranges, lately. -- GreenC 18:40, 20 March 2024 (UTC)[reply]
Hey GreenC, about a month ago, I added the template to indicate a user is deceased to my talk page in anticipation of my suicide, which you removed with a fairly insensitive edit summary. I unfortunately survived the attempt, but in the future, please don't assume in bad faith that users would facetiously use that template for "retirement." I understand that you probably run into that situation more often than an actual death, and I also acknowledge that my own edit summary was not very specific (though it should be obvious why I might've wanted to keep the details under wraps), but just remember that there are human beings behind the usernames. I will also do my part and not reuse the template again for future attempts; rest assured I had read the guidelines about using the template beforehand, though it seems I misunderstood something. Anyway I've seen some of your contributions elsewhere on the site and they're always constructive, keep up the good work. --Nsophiay (talk) 02:16, 19 April 2024 (UTC)[reply]
Thank you for explaining the situation. Using the template for oneself could constitute a threat of self harm, which is governed by WP:SOS. I'll keep that in mind in the future. Thank you for bringing it to my attention. I am going to close this thread. Please email if you want. -- GreenC 05:15, 19 April 2024 (UTC)[reply]
Hey GreenC, quick Q - if I look at an old article that has been archived on the Wayback Machine, usually there are many versions over several years. What's the best practice in terms of picking up which link to include in a reference on Wikipedia? I am assuming in this scenario that any version would do for the purposes of providing a reference (i.e. the changes are minimal, if any, from one year to another). Thanks! --Molochmeditates (talk) 20:00, 24 April 2024 (UTC)[reply]



 Featured script[edit]
Featured script[edit] Newly maintained scripts[edit]
Newly maintained scripts[edit].png)
.png)

 Improve a script[edit]
Improve a script[edit] Requested scripts[edit]
Requested scripts[edit] New scripts[edit]
New scripts[edit]