
Talk:Linear regression
| Mathematics Unassessed High‑priority | ||||||||||
| ||||||||||

| Statistics B‑class High‑importance | ||||||||||
| ||||||||||

Endogenous/exogenous
The uses of "endogenous" and "exogenous" variables here are not consistent with the only way I've ever heard them used. Exogenous means outside of the model -- i.e., a latent/hidden variable. Endogenous describes a variable that IS accounted for by your model, be it independent OR dependent. See Wiki entry for "exogenous," which supports this.
I recommend that these two words be deleted from the list of alternate names for predictor and criterion variables. (unsigned comments by 72.87.187.241)
- I have found economists use exogenous in lenear models to mean non response variables. The contrast is endogenous variables that appear on the right hand side of one or more other variables equations but also on the left hand side of their own regression. Pdbailey 00:06, 7 October 2006 (UTC)
- In economics exogenous means something determined outside of the model, such as X which is determined by God, or random chance, or anything but not the model itself. On the other hand Y is endogenous, since it is determined within the model, via the equation Y = Xβ + ε. This terminology becomes more useful when discussing simultaneous equations models. Also within the context of IV whenever one of the X's is correlated with ε's we will call such X endogenous as well. Stpasha (talk) 19:10, 30 June 2009 (UTC)
Name: Regression? Or Linear Models, or Linear Statistical Models, etc.
There are substantial portions of the literature which have moved away from the use of the term "regression". The term "regression" is used for historical reasons but does not capture the meaning of what is actually going on.
Terms such as "Linear Models", "Linear Statistical Models" are becoming at least as widely used as "linear regression" in the literature, and their meaning is more descriptive of what is actually going on. I think we ought to consider renaming this article and have "Linear regression" forward to the new page. At the very least, we ought to discuss the issues regarding naming on this page. Cazort 19:24, 17 October 2007 (UTC)
Regression articles discussion July 2009
A discussion of content overlap of some regression-related articles has been started at Talk:Linear least squares#Merger proposal but it isn't really just a question of merging and no actual merge proposal has been made. Melcombe (talk) 11:33, 14 July 2009 (UTC)
Rename?
Dear All,
- I wonder what do you all think about renaming this article into the Linear regression model? It seems to me that such name better expresses the topic of the article: some people use the word “regression” to refer to the process of estimation, while for others “regression” means the statistical model itself; however combination “regression model” is unambiguous. ... stpasha » talk » 01:17, 21 July 2009 (UTC)
Generally I prefer shorter titles, but I will think about this one. Michael Hardy (talk) 02:00, 21 July 2009 (UTC)
- I reopened this topic for discussion at the WPStatistics talk page. Please leave your comments there. // stpasha » 23:54, 21 April 2010 (UTC)
Merge Trend estimation to here
The article Trend estimation does not go beyond linear models and contains much that is actually generic for linear regression and dealt with better here. It appears to me that Trend estimation could simply become a redirect to Linear regression#Trend line (which might be renamed Linear regression#Trend estimation) after merging any useful stuff from there to here. --Lambiam 19:17, 27 July 2009 (UTC)
- I think it would be better left separate, but changed to better reflect actual trend estimation rather than saying it is essentially equivalent to least squares regression, which it shouldn't be. Melcombe (talk) 10:50, 29 July 2009 (UTC)
- But who is going to execute that change and when? Don't you agree that until someone actually creates an article on trend estimation going beyond linear regression to find a trend line (which is more specialized than least squares regression, which might apply to other than linear trend models), the reader is better served by the proposed redirect? --Lambiam 12:48, 2 August 2009 (UTC)
- I agree with Nelcombe 78.86.230.145 (talk) 14:13, 9 September 2009 (UTC)
But, isn't Linear regression just a tool used in Trend estimation? How can the over-arcing topic be listed under a tool? It would be like putting an on trees or woodworking in another article talking only about hammers. You use hammers to work wood, but you also use saws and other things that don't fit under the category of hammers. However, saws and the other tools are key to woodworking. Therefor, just put a link for Trend estimation at the bottom of the Linear regression page. if people want to read it, they can click the link. ~ Talon SFSU 12 September 2009
Typography Disambiguation
The ' character is used in several different contexts without clarification.
e.g:
http://upload.wikimedia.org/math/8/2/5/8255bd19aeed347fd8173d8038eb71ad.png aggregation
http://upload.wikimedia.org/math/6/8/3/683c3fe809a780a8bca83553bf0f6921.png transposition?
The contextual meaning of the character should be explicitly stated, whether it means "Transpose" or is used to aggregate individual variables into rows and vectors.
Use of T notation is less ambiguous in all cases.
--67.198.45.12 (talk) 14:38, 30 July 2009 (UTC)Matt Fowler
- I think it means transposition either way. Michael Hardy (talk) 17:10, 30 July 2009 (UTC)
- aah i see, they dropped the second subscript to denote the entire row.
- so still the confusion derives from a lack of explicit definition of the typography!
- The article states that is a p-vector in the first sentence of Definition section; then it defines ’ notation right after the formula: it says “ is an inner product between two vectors”. Maybe we could state that ’ is transposition more explicitly.
- As for T notation, it isn’t less ambiguous as it could be misunderstood for raising the matrix to the T-th power. ... stpasha » talk » 14:52, 31 July 2009 (UTC)


Re: Assumptions
I think this could be written to be more usable to more people, along the lines of the following:
- 1) Linear relationship between independent and dependent variable(s)
- How to Check: Make an XY scatter plot, then look for data grouping along a line,instead of along a curve.
- 2) Homoskedastic, meaning that, as independent variables change, errors do not tend to get bigger or smaller.
- How to Check: a residual plot is symmetric, or points on an XY scatter plot do not tend to spread toward the left, or toward the right.
- 3) Normal Distribution of Data, which meets the three following conditions:
- a) Unimodal:
- How to Check: Make a histogram, then look for only one major peak, instead of many.
- b) Symmetric, or Unskewed Data Distribution:
- How to Check: Make that histogram, then compare the left and right tails for size, etc.
- c) Kurtosis is about Zero:
- How to Check: Make that histogram, then compare its peakedness to a normal distribution.
Briancady413 (talk) 19:53, 4 November 2009 (UTC)
- These assumptions are unnecessary for the linear regression, that is, they are too strong. Well, except for the first one. But “making an XY scatterplot” recipe really works only in case of a simple linear regression. Besides, the approach suggested here contradicts the WP:NOTHOWTO(1) policy. … stpasha » 19:52, 30 November 2009 (UTC)
- I agree with Stpasha. I like the assumptions as they are now, because they are valid for the general case of linear regression, whatever the method of estimation or underlying statistical model at hand. --Forich (talk) 22:24, 30 November 2009 (UTC)
Example in the introductory section
Shouldn't it be mentioned in the example paragraph that, in general, predictor variables of type x, x^2, x^3 a.s.o. are mutually correlated? I know that this recipe is frequently given, but I think interpreting the results without accounting for these correlations makes it a dangerous recipe. Perhaps, a hint on how to normalize variables to a certain interval (which might be useful from numerical reasons, too) and on how to use a set of independent polynomials on that interval might be provided. Of course, interpreting the resulting coefficients may be much more complex. ChaosSchorsch (talk) 17:42, 18 February 2010 (UTC)
Epidemiology example
I am a bit confused by the inclusion of the example of tobacco smoking given in the section on applications of linear regression. Is it not more likely that the model used in these analyses was logistic regression?Jimjamjak (talk) 15:03, 26 March 2010 (UTC)
- The specific nature of the dependent variable is not given. If it were lifespan (measured in years), then linear regression would be perfectly appropriate. If it were "ever diagnosed with lung cancer" then it would probably be a logistic regression analysis. But the points made in this section mainly focus on issues with observational studies versus randomized experiments. So this is not a major point here. Skbkekas (talk) 23:07, 26 March 2010 (UTC)
A line has form y=mx + b, where m is the slope and b is the y-intercept. The current exposition seems to assume that the y-intercept is zero in all cases; that is, it says the form of the points is y_i = beta * x_i + epsilon_i, where epsilon_i is the "noise". There is no mention of the y-intercept, so it looks to me like the data is assumed to be centered at the origin. However, the figure at the top of the page clearly shows that the best-fit line does not need to pass through the origin. So what am I missing? —Preceding unsigned comment added by 86.141.197.132 (talk) 21:55, 6 April 2010 (UTC)
There is no mention of the y-intercept? See the section that begins "Usually a constant is included as one of the regressors." Skbkekas (talk) 12:20, 7 April 2010 (UTC)
Likely inaccurate portrayal of weighted linear regression
Quote: "GLS can be viewed as applying a linear transformation to the data so that the assumptions of OLS are met for the transformed data. "
This seems to be incorrect. Firstly, because a linear transformation of the data cannot make it meet the assumptions for OLS, and secondly because the introduction of the weights into the equation does not correspond to a linear transformation of the *data*. The intuitive explanation of weighted linear regression that makes sense to me is that higher weighted data items have more impact on the result, as if they were replicated in the data set, but there may be better explanations than that. Grevillea (talk) 04:22, 20 April 2010 (UTC)
- You take the linear regression equation and multiply it by a constant . Then you apply OLS to the transformed data: . In this regression η is already homoscedastic, so the "assumptions of OLS" are met. // stpasha » 09:09, 20 April 2010 (UTC)



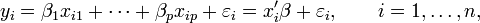{kind=link}
{kind=link}
- The above argument is only relevant if all the elements of Ω are known, otherwise the new "observations" depend on unknown parameters, and often Ω is not fully known. While, for the simplest applications of "weighted regression", the weights may be known, this is not always the case (depending on exactly how "weighted regression is defined"): however, even in this case, the idea of "replicated observations" doesn't fully work because of the difficulty of treating factional observations. In the "transformation approach", the idea of "more highly weighted observations" is treated by taking the initial formal regression model, in which an observation has an error variance which is smaller than for others, and creating the transformed model in which the regression equation for that observation is replaced by one in which each term (observation, dependent variables and error) in multiplied by a factor such that the new error term (factor × old error) has a constant variance across observations. Melcombe (talk) 16:27, 17 May 2010 (UTC)
Should this article be renamed?
- User:Stpasha has proposed renaming this article, from linear regression to linear regression model. (He mentioned this in a thread higher up on this page where no on is likely to see it.) The discussion is at Wikipedia_talk:WikiProject_Statistics#Rename_suggestion. Michael Hardy (talk) 23:33, 22 April 2010 (UTC)
- I have placed a move request to revert the change that was made change the name to linear regression model without any backing here or on the Stats project talk page, and in the face of a previous revert of the same change. See [requests]. Melcombe (talk) 12:59, 17 May 2010 (UTC)
Move?
- The following discussion is an archived discussion of a requested move. Please do not modify it. Subsequent comments should be made in a new section on the talk page. No further edits should be made to this section.
The result of the move request was: page moved. I did move the dab page to preserve the edit history and make it available if it is decided to use that in addition to the hat note (which needs adding). Also the previous moves left some archives scattered around. These are, I think, all at the dab page. I'll leave it to the editors here to move those back if that is correct. If you need an admin to do the moves, leave me a note on my talk page about what needs to happen. Vegaswikian (talk) 03:49, 11 June 2010 (UTC)
Linear regression model → Linear regression — Relisted to allow the last comment a chance to see if that is a consensus. Vegaswikian (talk) 02:20, 4 June 2010 (UTC)
Relisted. Arbitrarily0 (talk) 14:16, 25 May 2010 (UTC)
- Previous name change not backed on talk pages mentioned and the same change was previously reverted (21 April) by a 3rd editor for good reason Melcombe (talk) 12:10, 17 May 2010 (UTC)
- I have reverted page Linear regression to a disambig page. See discussion at Talk:Linear regression#Reverted to redirect. Anthony Appleyard (talk) 14:22, 17 May 2010 (UTC)
- Oppose. The topic was discussed on WPStatistics discussion thread, and all arguments were listed there. The reason why the same edit was previously reverted was that “the shorter name is more likely to be linked”, which I see as an argument in favor of the current name. Too often people link to “linear regression” while in fact they meant to link to OLS. // stpasha » 20:17, 17 May 2010 (UTC)
- Support The most common meaning being linked to is a form of linear regression is it not? It would be better to use the simpler title for the general method and just use a hatnote to help readers looking for the specific implementation of linear regression. This would probably even help people realize that there are many systems of linear regression. --Polaron | Talk 14:53, 27 May 2010 (UTC)
This discussion won't go anywhere, at least not without the clear statement of the arguments in favor of the name change. The discussion preceding changing this article's title into “Linear regression model” is quite old — its traces can be found on this talk page, talk pages of other linear regression articles, and at the WPStatistics discussion board. The conclusion from those debates was that we need to restructure the coverage of the linear regression topics, — starting from clearly delineating what the topic of each article is. This is why the name was changed from linear regression into linear regression model — because it is unambiguous and people are less likely to add irrelevant material to it. In contrast, the linear regression article is currently a disambiguation page, exactly because that name is ambiguous. On Wikipedia the titles of the articles strive to be not the shortest, nor the most common — but most precise and least ambiguous. The convenience is secondary, and is achieved through redirects. // stpasha » 20:07, 28 May 2010 (UTC)
- Comment - Since there doesn't seem to be an effective consensus to keep Linear regression a dab page, perhaps it would make sense to add a hatnote to the top of this article, helping people locate the OLS article? -GTBacchus(talk) 16:02, 2 June 2010 (UTC)
- Comment - I'm having trouble following this conversation, but feel like I have a stake in this decision. I thought Wikipedia tried to use the most common naming for articles, so my feeling is that the article should be Linear regression, not Linear regression model. Linear regression is hands down the term used in the non-mathematical community. To appease the statisticians, the hatnote idea sounds appropriate, with the hatnote either redirecting to a specific page, or a disambig page for the general notion of linear regression. I have no idea what an OLS is (perhaps "ordinary least squares"?), but it should at a minimum be spelled out for this discussion. As a general regression model framework would be inaccessible and unnecessary for 99% of users, I sincerely hope that the page accessible by default is a special case model, with only one independent variable, and least squares error estimation. I also hope there is an article for General linear model, another term I hear used in slightly more advanced contexts, but probably not sufficiently advanced for statisticians. 70.250.178.31 (talk) 04:50, 7 June 2010 (UTC)
- The above discussion is preserved as an archive of a requested move. Please do not modify it. Subsequent comments should be made in a new section on this talk page. No further edits should be made to this section.
First sentence
Should "linear regression" be simply "regression" in the first sentence? As written, it doesn't specify anything that requires linearity.205.248.102.81 (talk) 23:06, 10 September 2010 (UTC)
- No. The sentence is the topic sentence of a paragraph that defines the term. 018 (talk) 23:33, 10 September 2010 (UTC)
- What I meant was that the phrase "any approach to modeling the relationship between a scalar variable y and one or more variables denoted X" sounds like the definition of regression, not the definition of linear regression.