
Sensitivity and specificity: Difference between revisions
ClueBot NG (talk | contribs) m Reverting possible vandalism by 111.220.215.230 to version by MerlIwBot. False positive? Report it. Thanks, ClueBot NG. (374342) (Bot) |
|||
| Line 11: | Line 11: | ||
===Specificity=== |
===Specificity=== |
||
Consider the example of a [[detection dog]] used by [[Law enforcement agency|law enforcement]] to track drugs, a dog may be trained ''specifically'' to find cocaine. Another dog may be trained to find cocaine, heroin and marijuana. The second dog is looking for so many smells it can get confused and sometimes picks out odours like [[shampoo]], so it will begin to lead the law enforcement agents to innocent packages, thus it is ''less specific''. Thus, a much larger number of packages will be "picked up" as suspicious by the second dog, leading to what is called ''false positives'' – test results labeled as ''positive'' (drugs) but that are really negative (shampoo). |
|||
In terms of specificity, the first dog doesn't miss any cocaine and does not pick out any shampoo, so it is very ''specific''. If it makes a call it has a high chance of being right. The second dog finds more drugs (''sensitivity''), but is less ''specific'' for cocaine because it also finds shampoo. It makes more calls, but has more chance of being wrong. Which dog you choose depends on what you want to do. |
In terms of specificity, the first dog doesn't miss any cocaine and does not pick out any shampoo, so it is very ''specific''. If it makes a call it has a high chance of being right. The second dog finds more drugs (''sensitivity''), but is less ''specific'' for cocaine because it also finds shampoo. It makes more calls, but has more chance of being wrong. Which dog you choose depends on what you want to do. |
||
Revision as of 21:50, 13 April 2011
Sensitivity and specificity are statistical measures of the performance of a binary classification test. Sensitivity (also called recall rate in some fields) measures the proportion of actual positives which are correctly identified as such (e.g. the percentage of sick people who are correctly identified as having the condition). Specificity measures the proportion of negatives which are correctly identified (e.g. the percentage of healthy people who are correctly identified as not having the condition). These two measures are closely related to the concepts of type I and type II errors. A theoretical, optimal prediction aims to achieve 100% sensitivity (i.e. predict all people from the sick group as sick) and 100% specificity (i.e. not predict anyone from the healthy group as sick), however theoretically any predictor will possess a minimum error bound known as the Bayes error rate. .
For any test, there is usually a trade-off between the measures. For example: in an airport security setting in which one is testing for potential threats to safety, scanners may be set to trigger on low-risk items like belt buckles and keys (low specificity), in order to reduce the risk of missing objects that do pose a threat to the aircraft and those aboard (high sensitivity). This trade-off can be represented graphically using an ROC curve.
Definitions
Imagine a study evaluating a new test that screens people for a disease. Each person taking the test either has or does not have the disease. The test outcome can be positive (predicting that the person has the disease) or negative (predicting that the person does not have the disease). The test results for each subject may or may not match the subject's actual status. In that setting:
- True positive: Sick people correctly diagnosed as sick
- False positive: Healthy people incorrectly identified as sick
- True negative: Healthy people correctly identified as healthy
- False negative: Sick people incorrectly identified as healthy.
Specificity
Consider the example of a detection dog used by law enforcement to track drugs, a dog may be trained specifically to find cocaine. Another dog may be trained to find cocaine, heroin and marijuana. The second dog is looking for so many smells it can get confused and sometimes picks out odours like shampoo, so it will begin to lead the law enforcement agents to innocent packages, thus it is less specific. Thus, a much larger number of packages will be "picked up" as suspicious by the second dog, leading to what is called false positives – test results labeled as positive (drugs) but that are really negative (shampoo).
In terms of specificity, the first dog doesn't miss any cocaine and does not pick out any shampoo, so it is very specific. If it makes a call it has a high chance of being right. The second dog finds more drugs (sensitivity), but is less specific for cocaine because it also finds shampoo. It makes more calls, but has more chance of being wrong. Which dog you choose depends on what you want to do.

A specificity of 100% means that the test recognizes all actual negatives – for example, in a test for a certain disease, all disease free people will be recognized as disease free. A positive result in a high specificity test can confirm the presence of disease.[1] However, from a theoretical point of view, a 100%-specific test standard can also be ascribed to a 'bogus' test kit whereby the test simply always indicates negative. Therefore the specificity alone does not tell us how well the test recognizes positive cases. We also need to know the sensitivity of the test.
A test with a high specificity has a low type I error rate.
Sensitivity
Continuing with the example of the law enforcement tracking dog, an old dog might be retired because its nose becomes less sensitive to picking up the odor of drugs, and it begins to miss lots of drugs that it ordinarily would have sniffed out. This dog illustrates poor sensitivity, as it would give an "all clear" to not only those packages that do not contain any drugs (true negatives), but also to some packages that do contain drugs (false negatives).

A sensitivity of 100% means that the test recognizes all actual positives – for example, all sick people are recognized as being ill. Thus, in contrast to a high specificity test, negative results in a high sensitivity test are used to rule out the disease.[1]
Sensitivity alone does not tell us how well the test predicts other classes (that is, about the negative cases). In the binary classification, as illustrated above, this is the corresponding specificity test.
Sensitivity is not the same as the precision or positive predictive value (ratio of true positives to combined true and false positives), which is as much a statement about the proportion of actual positives in the population being tested as it is about the test.
The calculation of sensitivity does not take into account indeterminate test results. If a test cannot be repeated, the options are to exclude indeterminate samples from analysis (but the number of exclusions should be stated when quoting sensitivity), or, alternatively, indeterminate samples can be treated as false negatives (which gives the worst-case value for sensitivity and may therefore underestimate it).
A test with a high sensitivity has a low type II error rate.
Graphical illustration
-
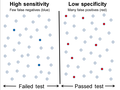 High sensitivity and low specificity
High sensitivity and low specificity -
 Low sensitivity and high specificity
Low sensitivity and high specificity


Medical example
In medical diagnostics, test sensitivity is the ability of a test to correctly identify those with the disease (true +ve rate), whereas test specificity is the ability of the test to correctly identify those without the disease (true -ve rate)[2].
If 100 patients known to have a disease were tested, and 43 test positive, then the test has 43% sensitivity. If 100 with no disease are tested and 96 return a negative result, then the test has 96% specificity.
A highly specific test is unlikely to give a false positive result: a positive result should thus be regarded as a true positive. A sensitive test rarely misses a condition, so a negative result should be reassuring (the disease tested for is absent). A
SPIN and SNOUT are commonly used mnemonics which says: A highly SPecific test, when Positive, rules IN disease (SP-P-IN), and a highly 'SeNsitive' test, when Negative rules OUT disease (SN-N-OUT).
Worked example
- A worked example
- A diagnostic test with sensitivity 67% and specificity 91% is applied to 2030 people to look for a disorder with a population prevalence of 1.48%
| Fecal occult blood screen test outcome | |||||
| Total population (pop.) = 2030 |
Test outcome positive | Test outcome negative | Accuracy (ACC) = (TP + TN) / pop.
= (20 + 1820) / 2030 ≈ 90.64% |
F1 score = 2 × precision × recall/precision + recall
≈ 0.174 | |
| Patients with bowel cancer (as confirmed on endoscopy) |
Actual condition positive (AP) = 30 (2030 × 1.48%) |
True positive (TP) = 20 (2030 × 1.48% × 67%) |
False negative (FN) = 10 (2030 × 1.48% × (100% − 67%)) |
True positive rate (TPR), recall, sensitivity = TP / AP
= 20 / 30 ≈ 66.7% |
False negative rate (FNR), miss rate = FN / AP
= 10 / 30 ≈ 33.3% |
| Actual condition negative (AN) = 2000 (2030 × (100% − 1.48%)) |
False positive (FP) = 180 (2030 × (100% − 1.48%) × (100% − 91%)) |
True negative (TN) = 1820 (2030 × (100% − 1.48%) × 91%) |
False positive rate (FPR), fall-out, probability of false alarm = FP / AN
= 180 / 2000 = 9.0% |
Specificity, selectivity, true negative rate (TNR) = TN / AN
= 1820 / 2000 = 91% | |
| Prevalence = AP / pop.
= 30 / 2030 ≈ 1.48% |
Positive predictive value (PPV), precision = TP / (TP + FP)
= 20 / (20 + 180) = 10% |
False omission rate (FOR) = FN / (FN + TN)
= 10 / (10 + 1820) ≈ 0.55% |
Positive likelihood ratio (LR+) = TPR/FPR
= (20 / 30) / (180 / 2000) ≈ 7.41 |
Negative likelihood ratio (LR−) = FNR/TNR
= (10 / 30) / (1820 / 2000) ≈ 0.366 | |
| False discovery rate (FDR) = FP / (TP + FP)
= 180 / (20 + 180) = 90.0% |
Negative predictive value (NPV) = TN / (FN + TN)
= 1820 / (10 + 1820) ≈ 99.45% |
Diagnostic odds ratio (DOR) = LR+/LR−
≈ 20.2 | |||
Related calculations
- False positive rate (α) = type I error = 1 − specificity = FP / (FP + TN) = 180 / (180 + 1820) = 9%
- False negative rate (β) = type II error = 1 − sensitivity = FN / (TP + FN) = 10 / (20 + 10) ≈ 33%
- Power = sensitivity = 1 − β
- Positive likelihood ratio = sensitivity / (1 − specificity) ≈ 0.67 / (1 − 0.91) ≈ 7.4
- Negative likelihood ratio = (1 − sensitivity) / specificity ≈ (1 − 0.67) / 0.91 ≈ 0.37
- Prevalence threshold = ≈ 0.2686 ≈ 26.9%

This hypothetical screening test (fecal occult blood test) correctly identified two-thirds (66.7%) of patients with colorectal cancer.[a] Unfortunately, factoring in prevalence rates reveals that this hypothetical test has a high false positive rate, and it does not reliably identify colorectal cancer in the overall population of asymptomatic people (PPV = 10%).
On the other hand, this hypothetical test demonstrates very accurate detection of cancer-free individuals (NPV ≈ 99.5%). Therefore, when used for routine colorectal cancer screening with asymptomatic adults, a negative result supplies important data for the patient and doctor, such as ruling out cancer as the cause of gastrointestinal symptoms or reassuring patients worried about developing colorectal cancer.
Terminology in information retrieval
In information retrieval positive predictive value is called precision, and sensitivity is called recall.
The F-measure can be used as a single measure of performance of the test. The F-measure is the harmonic mean of precision and recall:

In the traditional language of statistical hypothesis testing, the sensitivity of a test is called the statistical power of the test, although the word power in that context has a more general usage that is not applicable in the present context. A sensitive test will have fewer Type II errors.
See also
Source: Fawcett (2004). |








- Binary classification
- Detection theory
- Receiver operating characteristic
- Statistical significance
- Type I and type II errors
- Selectivity
- Youden's J statistic
- Matthews correlation coefficient
- Gain (information retrieval)
- Accuracy and precision
Further reading
The template {{Expand}} has been deprecated since 26 December 2010, and is retained only for old revisions. If this page is a current revision, please remove the template.
- Altman DG, Bland JM (1994). "Diagnostic tests. 1: Sensitivity and specificity". BMJ. 308 (6943): 1552. PMC 2540489. PMID 8019315.
External links
- Calculators:
- Vassar College's Sensitivity/Specificity Calculator
- OpenEpi software program
References
- ^ a b http://www.cebm.net/index.aspx?o=1042
- ^ MedStats.Org
- ^ Lin, Jennifer S.; Piper, Margaret A.; Perdue, Leslie A.; Rutter, Carolyn M.; Webber, Elizabeth M.; O'Connor, Elizabeth; Smith, Ning; Whitlock, Evelyn P. (21 June 2016). "Screening for Colorectal Cancer". JAMA. 315 (23): 2576–2594. doi:10.1001/jama.2016.3332. ISSN 0098-7484. PMID 27305422.
- ^ Bénard, Florence; Barkun, Alan N.; Martel, Myriam; Renteln, Daniel von (7 January 2018). "Systematic review of colorectal cancer screening guidelines for average-risk adults: Summarizing the current global recommendations". World Journal of Gastroenterology. 24 (1): 124–138. doi:10.3748/wjg.v24.i1.124. PMC 5757117. PMID 29358889.
Cite error: There are <ref group=lower-alpha> tags or {{efn}} templates on this page, but the references will not show without a {{reflist|group=lower-alpha}} template or {{notelist}} template (see the help page).