
Metagenomics
| Part of a series on |
| Genetics |
|---|
 |

Metagenomics is the study of genetic material recovered directly from environmental or clinical samples by a method called sequencing. The broad field may also be referred to as environmental genomics, ecogenomics, community genomics or microbiomics.
While traditional microbiology and microbial genome sequencing and genomics rely upon cultivated clonal cultures, early environmental gene sequencing cloned specific genes (often the 16S rRNA gene) to produce a profile of diversity in a natural sample. Such work revealed that the vast majority of microbial biodiversity had been missed by cultivation-based methods.[2]
Because of its ability to reveal the previously hidden diversity of microscopic life, metagenomics offers a powerful way of understanding the microbial world that might revolutionize understanding of biology.[3] As the price of DNA sequencing continues to fall, metagenomics now allows microbial ecology to be investigated at a much greater scale and detail than before. Recent studies use either "shotgun" or PCR directed sequencing to get largely unbiased samples of all genes from all the members of the sampled communities.[4]
Etymology
[edit]The term "metagenomics" was first used by Jo Handelsman, Robert M. Goodman, Michelle R. Rondon, Jon Clardy, and Sean F. Brady, and first appeared in publication in 1998.[5] The term metagenome referenced the idea that a collection of genes sequenced from the environment could be analyzed in a way analogous to the study of a single genome. In 2005, Kevin Chen and Lior Pachter (researchers at the University of California, Berkeley) defined metagenomics as "the application of modern genomics technique without the need for isolation and lab cultivation of individual species".[6]
History
[edit]| Part of a series on |
| DNA barcoding |
|---|
 |
| By taxa |
| Other |
Conventional sequencing begins with a culture of identical cells as a source of DNA. However, early metagenomic studies revealed that there are probably large groups of microorganisms in many environments that cannot be cultured and thus cannot be sequenced. These early studies focused on 16S ribosomal RNA (rRNA) sequences which are relatively short, often conserved within a species, and generally different between species. Many 16S rRNA sequences have been found which do not belong to any known cultured species, indicating that there are numerous non-isolated organisms. These surveys of ribosomal RNA genes taken directly from the environment revealed that cultivation based methods find less than 1% of the bacterial and archaeal species in a sample.[2] Much of the interest in metagenomics comes from these discoveries that showed that the vast majority of microorganisms had previously gone unnoticed.
In the 1980s early molecular work in the field was conducted by Norman R. Pace and colleagues, who used PCR to explore the diversity of ribosomal RNA sequences.[7] The insights gained from these breakthrough studies led Pace to propose the idea of cloning DNA directly from environmental samples as early as 1985.[8] This led to the first report of isolating and cloning bulk DNA from an environmental sample, published by Pace and colleagues in 1991[9] while Pace was in the Department of Biology at Indiana University. Considerable efforts ensured that these were not PCR false positives and supported the existence of a complex community of unexplored species. Although this methodology was limited to exploring highly conserved, non-protein coding genes, it did support early microbial morphology-based observations that diversity was far more complex than was known by culturing methods. Soon after that in 1995, Healy reported the metagenomic isolation of functional genes from "zoolibraries" constructed from a complex culture of environmental organisms grown in the laboratory on dried grasses.[10] After leaving the Pace laboratory, Edward DeLong continued in the field and has published work that has largely laid the groundwork for environmental phylogenies based on signature 16S sequences, beginning with his group's construction of libraries from marine samples.[11]
In 2002, Mya Breitbart, Forest Rohwer, and colleagues used environmental shotgun sequencing (see below) to show that 200 liters of seawater contains over 5000 different viruses.[12] Subsequent studies showed that there are more than a thousand viral species in human stool and possibly a million different viruses per kilogram of marine sediment, including many bacteriophages. Essentially all of the viruses in these studies were new species. In 2004, Gene Tyson, Jill Banfield, and colleagues at the University of California, Berkeley and the Joint Genome Institute sequenced DNA extracted from an acid mine drainage system.[13] This effort resulted in the complete, or nearly complete, genomes for a handful of bacteria and archaea that had previously resisted attempts to culture them.[14]
Beginning in 2003, Craig Venter, leader of the privately funded parallel of the Human Genome Project, has led the Global Ocean Sampling Expedition (GOS), circumnavigating the globe and collecting metagenomic samples throughout the journey. All of these samples were sequenced using shotgun sequencing, in hopes that new genomes (and therefore new organisms) would be identified. The pilot project, conducted in the Sargasso Sea, found DNA from nearly 2000 different species, including 148 types of bacteria never before seen.[15] Venter thoroughly explored the West Coast of the United States, and completed a two-year expedition in 2006 to explore the Baltic, Mediterranean, and Black Seas. Analysis of the metagenomic data collected during this journey revealed two groups of organisms, one composed of taxa adapted to environmental conditions of 'feast or famine', and a second composed of relatively fewer but more abundantly and widely distributed taxa primarily composed of plankton.[16]
In 2005 Stephan C. Schuster at Penn State University and colleagues published the first sequences of an environmental sample generated with high-throughput sequencing, in this case massively parallel pyrosequencing developed by 454 Life Sciences.[17] Another early paper in this area appeared in 2006 by Robert Edwards, Forest Rohwer, and colleagues at San Diego State University.[18]
Sequencing
[edit]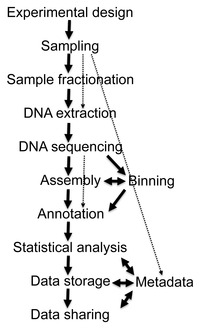
Recovery of DNA sequences longer than a few thousand base pairs from environmental samples was very difficult until recent advances in molecular biological techniques allowed the construction of libraries in bacterial artificial chromosomes (BACs), which provided better vectors for molecular cloning.[20]
Shotgun metagenomics
[edit]Advances in bioinformatics, refinements of DNA amplification, and the proliferation of computational power have greatly aided the analysis of DNA sequences recovered from environmental samples, allowing the adaptation of shotgun sequencing to metagenomic samples (known also as whole metagenome shotgun or WMGS sequencing). The approach, used to sequence many cultured microorganisms and the human genome, randomly shears DNA, sequences many short sequences, and reconstructs them into a consensus sequence. Shotgun sequencing reveals genes present in environmental samples. Historically, clone libraries were used to facilitate this sequencing. However, with advances in high throughput sequencing technologies, the cloning step is no longer necessary and greater yields of sequencing data can be obtained without this labour-intensive bottleneck step. Shotgun metagenomics provides information both about which organisms are present and what metabolic processes are possible in the community.[21] Because the collection of DNA from an environment is largely uncontrolled, the most abundant organisms in an environmental sample are most highly represented in the resulting sequence data. To achieve the high coverage needed to fully resolve the genomes of under-represented community members, large samples, often prohibitively so, are needed. On the other hand, the random nature of shotgun sequencing ensures that many of these organisms, which would otherwise go unnoticed using traditional culturing techniques, will be represented by at least some small sequence segments.[13]
High-throughput sequencing
[edit]An advantage to high throughput sequencing is that this technique does not require cloning the DNA before sequencing, removing one of the main biases and bottlenecks in environmental sampling. The first metagenomic studies conducted using high-throughput sequencing used massively parallel 454 pyrosequencing.[17] Three other technologies commonly applied to environmental sampling are the Ion Torrent Personal Genome Machine, the Illumina MiSeq or HiSeq and the Applied Biosystems SOLiD system.[22] These techniques for sequencing DNA generate shorter fragments than Sanger sequencing; Ion Torrent PGM System and 454 pyrosequencing typically produces ~400 bp reads, Illumina MiSeq produces 400-700bp reads (depending on whether paired end options are used), and SOLiD produce 25–75 bp reads.[23] Historically, these read lengths were significantly shorter than the typical Sanger sequencing read length of ~750 bp, however the Illumina technology is quickly coming close to this benchmark. However, this limitation is compensated for by the much larger number of sequence reads. In 2009, pyrosequenced metagenomes generate 200–500 megabases, and Illumina platforms generate around 20–50 gigabases, but these outputs have increased by orders of magnitude in recent years.[24]
An emerging approach combines shotgun sequencing and chromosome conformation capture (Hi-C), which measures the proximity of any two DNA sequences within the same cell, to guide microbial genome assembly.[25] Long read sequencing technologies, including PacBio RSII and PacBio Sequel by Pacific Biosciences, and Nanopore MinION, GridION, PromethION by Oxford Nanopore Technologies, is another choice to get long shotgun sequencing reads that should make ease in assembling process.[26]
Bioinformatics
[edit]This section is missing information about quality assessment: on assembly (N50, MetaQUAST), on genome (universal single-copy marker genes – CheckM and BUSCO). (February 2022) |

The data generated by metagenomics experiments are both enormous and inherently noisy, containing fragmented data representing as many as 10,000 species.[1] The sequencing of the cow rumen metagenome generated 279 gigabases, or 279 billion base pairs of nucleotide sequence data,[28] while the human gut microbiome gene catalog identified 3.3 million genes assembled from 567.7 gigabases of sequence data.[29] Collecting, curating, and extracting useful biological information from datasets of this size represent significant computational challenges for researchers.[21][30][31][32]
Sequence pre-filtering
[edit]The first step of metagenomic data analysis requires the execution of certain pre-filtering steps, including the removal of redundant, low-quality sequences and sequences of probable eukaryotic origin (especially in metagenomes of human origin).[33][34] The methods available for the removal of contaminating eukaryotic genomic DNA sequences include Eu-Detect and DeConseq.[35][36]
Assembly
[edit]DNA sequence data from genomic and metagenomic projects are essentially the same, but genomic sequence data offers higher coverage while metagenomic data is usually highly non-redundant.[31] Furthermore, the increased use of second-generation sequencing technologies with short read lengths means that much of future metagenomic data will be error-prone. Taken in combination, these factors make the assembly of metagenomic sequence reads into genomes difficult and unreliable. Misassemblies are caused by the presence of repetitive DNA sequences that make assembly especially difficult because of the difference in the relative abundance of species present in the sample.[37] Misassemblies can also involve the combination of sequences from more than one species into chimeric contigs.[37]
There are several assembly programs, most of which can use information from paired-end tags in order to improve the accuracy of assemblies. Some programs, such as Phrap or Celera Assembler, were designed to be used to assemble single genomes but nevertheless produce good results when assembling metagenomic data sets.[1] Other programs, such as Velvet assembler, have been optimized for the shorter reads produced by second-generation sequencing through the use of de Bruijn graphs.[38][39] The use of reference genomes allows researchers to improve the assembly of the most abundant microbial species, but this approach is limited by the small subset of microbial phyla for which sequenced genomes are available.[37] After an assembly is created, an additional challenge is "metagenomic deconvolution", or determining which sequences come from which species in the sample.[40]
Species diversity
[edit]Gene annotations provide the "what", while measurements of species diversity provide the "who".[41] In order to connect community composition and function in metagenomes, sequences must be binned. Binning is the process of associating a particular sequence with an organism.[37] In similarity-based binning, methods such as BLAST are used to rapidly search for phylogenetic markers or otherwise similar sequences in existing public databases. This approach is implemented in MEGAN.[42] Another tool, PhymmBL, uses interpolated Markov models to assign reads.[1] MetaPhlAn and AMPHORA are methods based on unique clade-specific markers for estimating organismal relative abundances with improved computational performances.[43] Other tools, like mOTUs[44][45] and MetaPhyler,[46] use universal marker genes to profile prokaryotic species. With the mOTUs profiler is possible to profile species without a reference genome, improving the estimation of microbial community diversity.[45] Recent methods, such as SLIMM, use read coverage landscape of individual reference genomes to minimize false-positive hits and get reliable relative abundances.[47] In composition based binning, methods use intrinsic features of the sequence, such as oligonucleotide frequencies or codon usage bias.[1] Once sequences are binned, it is possible to carry out comparative analysis of diversity and richness.
After binning, assembled contigs are collected into "bins" each representing a species-like collection of organisms (see: operational taxonomic unit), to the best ability of the binning tool. Each bin consists of a metagenome-assembled genome (MAG), as all included sequences can be thought of being derived from the genome of the organism being represented. Tools based on single-copy genes such as CheckM and BUSCO can then be used to estimate the completeness percentage and contamination percentage of the MAG.[48]
Gene prediction
[edit]Metagenomic analysis pipelines use two approaches in the annotation of coding regions in the assembled contigs.[37] The first approach is to identify genes based upon homology with genes that are already publicly available in sequence databases, usually by BLAST searches. This type of approach is implemented in the program MEGAN4.[49] The second, ab initio, uses intrinsic features of the sequence to predict coding regions based upon gene training sets from related organisms. This is the approach taken by programs such as GeneMark[50] and GLIMMER. The main advantage of ab initio prediction is that it enables the detection of coding regions that lack homologs in the sequence databases; however, it is most accurate when there are large regions of contiguous genomic DNA available for comparison.[1] Gene prediction is usually done after binning.[27]
Data integration
[edit]The massive amount of exponentially growing sequence data is a daunting challenge that is complicated by the complexity of the metadata associated with metagenomic projects. Metadata includes detailed information about the three-dimensional (including depth, or height) geography and environmental features of the sample, physical data about the sample site, and the methodology of the sampling.[31] This information is necessary both to ensure replicability and to enable downstream analysis. Because of its importance, metadata and collaborative data review and curation require standardized data formats located in specialized databases, such as the Genomes OnLine Database (GOLD).[51]
Several tools have been developed to integrate metadata and sequence data, allowing downstream comparative analyses of different datasets using a number of ecological indices. In 2007, Folker Meyer and Robert Edwards and a team at Argonne National Laboratory and the University of Chicago released the Metagenomics Rapid Annotation using Subsystem Technology server (MG-RAST) a community resource for metagenome data set analysis.[52] As of June 2012 over 14.8 terabases (14x1012 bases) of DNA have been analyzed, with more than 10,000 public data sets freely available for comparison within MG-RAST. Over 8,000 users now have submitted a total of 50,000 metagenomes to MG-RAST. The Integrated Microbial Genomes/Metagenomes (IMG/M) system also provides a collection of tools for functional analysis of microbial communities based on their metagenome sequence, based upon reference isolate genomes included from the Integrated Microbial Genomes (IMG) system and the Genomic Encyclopedia of Bacteria and Archaea (GEBA) project.[53]
One of the first standalone tools for analysing high-throughput metagenome shotgun data was MEGAN (MEta Genome ANalyzer).[49][42] A first version of the program was used in 2005 to analyse the metagenomic context of DNA sequences obtained from a mammoth bone.[17] Based on a BLAST comparison against a reference database, this tool performs both taxonomic and functional binning, by placing the reads onto the nodes of the NCBI taxonomy using a simple lowest common ancestor (LCA) algorithm or onto the nodes of the SEED or KEGG classifications, respectively.[54]
With the advent of fast and inexpensive sequencing instruments, the growth of databases of DNA sequences is now exponential (e.g., the NCBI GenBank database [55]). Faster and efficient tools are needed to keep pace with the high-throughput sequencing, because the BLAST-based approaches such as MG-RAST or MEGAN run slowly to annotate large samples (e.g., several hours to process a small/medium size dataset/sample [56]). Thus, ultra-fast classifiers have recently emerged, thanks to more affordable powerful servers. These tools can perform the taxonomic annotation at extremely high speed, for example CLARK [57] (according to CLARK's authors, it can classify accurately "32 million metagenomic short reads per minute"). At such a speed, a very large dataset/sample of a billion short reads can be processed in about 30 minutes.
With the increasing availability of samples containing ancient DNA and due to the uncertainty associated with the nature of those samples (ancient DNA damage),[58] a fast tool capable of producing conservative similarity estimates has been made available. According to FALCON's authors, it can use relaxed thresholds and edit distances without affecting the memory and speed performance.
Comparative metagenomics
[edit]Comparative analyses between metagenomes can provide additional insight into the function of complex microbial communities and their role in host health.[59] Pairwise or multiple comparisons between metagenomes can be made at the level of sequence composition (comparing GC-content or genome size), taxonomic diversity, or functional complement. Comparisons of population structure and phylogenetic diversity can be made on the basis of 16S rRNA and other phylogenetic marker genes, or—in the case of low-diversity communities—by genome reconstruction from the metagenomic dataset.[60] Functional comparisons between metagenomes may be made by comparing sequences against reference databases such as COG or KEGG, and tabulating the abundance by category and evaluating any differences for statistical significance.[54] This gene-centric approach emphasizes the functional complement of the community as a whole rather than taxonomic groups, and shows that the functional complements are analogous under similar environmental conditions.[60] Consequently, metadata on the environmental context of the metagenomic sample is especially important in comparative analyses, as it provides researchers with the ability to study the effect of habitat upon community structure and function.[1]
Additionally, several studies have also utilized oligonucleotide usage patterns to identify the differences across diverse microbial communities. Examples of such methodologies include the dinucleotide relative abundance approach by Willner et al.[61] and the HabiSign approach of Ghosh et al.[62] This latter study also indicated that differences in tetranucleotide usage patterns can be used to identify genes (or metagenomic reads) originating from specific habitats. Additionally some methods as TriageTools[63] or Compareads[64] detect similar reads between two read sets. The similarity measure they apply on reads is based on a number of identical words of length k shared by pairs of reads.
A key goal in comparative metagenomics is to identify microbial group(s) which are responsible for conferring specific characteristics to a given environment. However, due to issues in the sequencing technologies artifacts need to be accounted for like in metagenomeSeq.[30] Others have characterized inter-microbial interactions between the resident microbial groups. A GUI-based comparative metagenomic analysis application called Community-Analyzer has been developed by Kuntal et al. [65] which implements a correlation-based graph layout algorithm that not only facilitates a quick visualization of the differences in the analyzed microbial communities (in terms of their taxonomic composition), but also provides insights into the inherent inter-microbial interactions occurring therein. Notably, this layout algorithm also enables grouping of the metagenomes based on the probable inter-microbial interaction patterns rather than simply comparing abundance values of various taxonomic groups. In addition, the tool implements several interactive GUI-based functionalities that enable users to perform standard comparative analyses across microbiomes.
Data analysis
[edit]Community metabolism
[edit]In many bacterial communities, natural or engineered (such as bioreactors), there is significant division of labor in metabolism (syntrophy), during which the waste products of some organisms are metabolites for others.[66] In one such system, the methanogenic bioreactor, functional stability requires the presence of several syntrophic species (Syntrophobacterales and Synergistia) working together in order to turn raw resources into fully metabolized waste (methane).[67] Using comparative gene studies and expression experiments with microarrays or proteomics researchers can piece together a metabolic network that goes beyond species boundaries. Such studies require detailed knowledge about which versions of which proteins are coded by which species and even by which strains of which species. Therefore, community genomic information is another fundamental tool (with metabolomics and proteomics) in the quest to determine how metabolites are transferred and transformed by a community.[68]
Metatranscriptomics
[edit]Metagenomics allows researchers to access the functional and metabolic diversity of microbial communities, but it cannot show which of these processes are active.[60] The extraction and analysis of metagenomic mRNA (the metatranscriptome) provides information on the regulation and expression profiles of complex communities. Because of the technical difficulties (the short half-life of mRNA, for example) in the collection of environmental RNA there have been relatively few in situ metatranscriptomic studies of microbial communities to date.[60] While originally limited to microarray technology, metatranscriptomics studies have made use of transcriptomics technologies to measure whole-genome expression and quantification of a microbial community,[60] first employed in analysis of ammonia oxidation in soils.[69]
Viruses
[edit]Metagenomic sequencing is particularly useful in the study of viral communities. As viruses lack a shared universal phylogenetic marker (as 16S RNA for bacteria and archaea, and 18S RNA for eukarya), the only way to access the genetic diversity of the viral community from an environmental sample is through metagenomics. Viral metagenomes (also called viromes) should thus provide more and more information about viral diversity and evolution.[70][71][72][73][74] For example, a metagenomic pipeline called Giant Virus Finder showed the first evidence of existence of giant viruses in a saline desert[75] and in Antarctic dry valleys.[76]
Applications
[edit]Metagenomics has the potential to advance knowledge in a wide variety of fields. It can also be applied to solve practical challenges in medicine, engineering, agriculture, sustainability and ecology.[31][77]
Agriculture
[edit]The soils in which plants grow are inhabited by microbial communities, with one gram of soil containing around 109-1010 microbial cells which comprise about one gigabase of sequence information.[78][79] The microbial communities which inhabit soils are some of the most complex known to science, and remain poorly understood despite their economic importance.[80] Microbial consortia perform a wide variety of ecosystem services necessary for plant growth, including fixing atmospheric nitrogen, nutrient cycling, disease suppression, and sequester iron and other metals.[81] Functional metagenomics strategies are being used to explore the interactions between plants and microbes through cultivation-independent study of these microbial communities.[82][83] By allowing insights into the role of previously uncultivated or rare community members in nutrient cycling and the promotion of plant growth, metagenomic approaches can contribute to improved disease detection in crops and livestock and the adaptation of enhanced farming practices which improve crop health by harnessing the relationship between microbes and plants.[31]
Biofuel
[edit]Biofuels are fuels derived from biomass conversion, as in the conversion of cellulose contained in corn stalks, switchgrass, and other biomass into cellulosic ethanol.[31] This process is dependent upon microbial consortia (association) that transform the cellulose into sugars, followed by the fermentation of the sugars into ethanol. Microbes also produce a variety of sources of bioenergy including methane and hydrogen.[31]
The efficient industrial-scale deconstruction of biomass requires novel enzymes with higher productivity and lower cost.[28] Metagenomic approaches to the analysis of complex microbial communities allow the targeted screening of enzymes with industrial applications in biofuel production, such as glycoside hydrolases.[84] Furthermore, knowledge of how these microbial communities function is required to control them, and metagenomics is a key tool in their understanding. Metagenomic approaches allow comparative analyses between convergent microbial systems like biogas fermenters[85] or insect herbivores such as the fungus garden of the leafcutter ants.[86]
Biotechnology
[edit]Microbial communities produce a vast array of biologically active chemicals that are used in competition and communication.[81] Many of the drugs in use today were originally uncovered in microbes; recent progress in mining the rich genetic resource of non-culturable microbes has led to the discovery of new genes, enzymes, and natural products.[60][87] The application of metagenomics has allowed the development of commodity and fine chemicals, agrochemicals and pharmaceuticals where the benefit of enzyme-catalyzed chiral synthesis is increasingly recognized.[88]
Two types of analysis are used in the bioprospecting of metagenomic data: function-driven screening for an expressed trait, and sequence-driven screening for DNA sequences of interest.[89] Function-driven analysis seeks to identify clones expressing a desired trait or useful activity, followed by biochemical characterization and sequence analysis. This approach is limited by availability of a suitable screen and the requirement that the desired trait be expressed in the host cell. Moreover, the low rate of discovery (less than one per 1,000 clones screened) and its labor-intensive nature further limit this approach.[90] In contrast, sequence-driven analysis uses conserved DNA sequences to design PCR primers to screen clones for the sequence of interest.[89] In comparison to cloning-based approaches, using a sequence-only approach further reduces the amount of bench work required. The application of massively parallel sequencing also greatly increases the amount of sequence data generated, which require high-throughput bioinformatic analysis pipelines.[90] The sequence-driven approach to screening is limited by the breadth and accuracy of gene functions present in public sequence databases. In practice, experiments make use of a combination of both functional and sequence-based approaches based upon the function of interest, the complexity of the sample to be screened, and other factors.[90][91] An example of success using metagenomics as a biotechnology for drug discovery is illustrated with the malacidin antibiotics.[92]
Ecology
[edit]
Metagenomics can provide valuable insights into the functional ecology of environmental communities.[93] Metagenomic analysis of the bacterial consortia found in the defecations of Australian sea lions suggests that nutrient-rich sea lion faeces may be an important nutrient source for coastal ecosystems. This is because the bacteria that are expelled simultaneously with the defecations are adept at breaking down the nutrients in the faeces into a bioavailable form that can be taken up into the food chain.[94]
DNA sequencing can also be used more broadly to identify species present in a body of water,[95] debris filtered from the air, sample of dirt, or animal's faeces,[96] and even detect diet items from blood meals.[97] This can establish the range of invasive species and endangered species, and track seasonal populations.
Environmental remediation
[edit]Metagenomics can improve strategies for monitoring the impact of pollutants on ecosystems and for cleaning up contaminated environments. Increased understanding of how microbial communities cope with pollutants improves assessments of the potential of contaminated sites to recover from pollution and increases the chances of bioaugmentation or biostimulation trials to succeed.[98]
Gut microbe characterization
[edit]Microbial communities play a key role in preserving human health, but their composition and the mechanism by which they do so remains mysterious.[99] Metagenomic sequencing is being used to characterize the microbial communities from 15–18 body sites from at least 250 individuals. This is part of the Human Microbiome initiative with primary goals to determine if there is a core human microbiome, to understand the changes in the human microbiome that can be correlated with human health, and to develop new technological and bioinformatics tools to support these goals.[100]
Another medical study as part of the MetaHit (Metagenomics of the Human Intestinal Tract) project consisted of 124 individuals from Denmark and Spain consisting of healthy, overweight, and irritable bowel disease patients.[101] The study attempted to categorize the depth and phylogenetic diversity of gastrointestinal bacteria. Using Illumina GA sequence data and SOAPdenovo, a de Bruijn graph-based tool specifically designed for assembly short reads, they were able to generate 6.58 million contigs greater than 500 bp for a total contig length of 10.3 Gb and a N50 length of 2.2 kb.
The study demonstrated that two bacterial divisions, Bacteroidetes and Firmicutes, constitute over 90% of the known phylogenetic categories that dominate distal gut bacteria. Using the relative gene frequencies found within the gut these researchers identified 1,244 metagenomic clusters that are critically important for the health of the intestinal tract. There are two types of functions in these range clusters: housekeeping and those specific to the intestine. The housekeeping gene clusters are required in all bacteria and are often major players in the main metabolic pathways including central carbon metabolism and amino acid synthesis. The gut-specific functions include adhesion to host proteins and the harvesting of sugars from globoseries glycolipids. Patients with irritable bowel syndrome were shown to exhibit 25% fewer genes and lower bacterial diversity than individuals not suffering from irritable bowel syndrome indicating that changes in patients' gut biome diversity may be associated with this condition.[101]
While these studies highlight some potentially valuable medical applications, only 31–48.8% of the reads could be aligned to 194 public human gut bacterial genomes and 7.6–21.2% to bacterial genomes available in GenBank which indicates that there is still far more research necessary to capture novel bacterial genomes.[102]
In the Human Microbiome Project (HMP), gut microbial communities were assayed using high-throughput DNA sequencing. HMP showed that, unlike individual microbial species, many metabolic processes were present among all body habitats with varying frequencies. Microbial communities of 649 metagenomes drawn from seven primary body sites on 102 individuals were studied as part of the human microbiome project. The metagenomic analysis revealed variations in niche specific abundance among 168 functional modules and 196 metabolic pathways within the microbiome. These included glycosaminoglycan degradation in the gut, as well as phosphate and amino acid transport linked to host phenotype (vaginal pH) in the posterior fornix. The HMP has brought to light the utility of metagenomics in diagnostics and evidence-based medicine. Thus metagenomics is a powerful tool to address many of the pressing issues in the field of personalized medicine.[103]
In animals, metagenomics can be used to profile their gut microbiomes and enable detection of antibiotic-resistant bacteria.[104] This can have implications in monitoring the spread of diseases from wildlife to farmed animals and humans.
Infectious disease diagnosis
[edit]Differentiating between infectious and non-infectious illness, and identifying the underlying etiology of infection, can be challenging. For example, more than half of cases of encephalitis remain undiagnosed, despite extensive testing using state-of-the-art clinical laboratory methods. Clinical metagenomic sequencing shows promise as a sensitive and rapid method to diagnose infection by comparing genetic material found in a patient's sample to databases of all known microscopic human pathogens and thousands of other bacterial, viral, fungal, and parasitic organisms and databases on antimicrobial resistances gene sequences with associated clinical phenotypes.[105]
Arbovirus surveillance
[edit]Metagenomics has been an invaluable tool to help characterise the diversity and ecology of pathogens that are vectored by hematophagous (blood-feeding) insects such as mosquitoes and ticks.[106][107][108] Metagenomics is[when?] routinely used by public health officials and organisations[where?] for the surveillance of arboviruses.[109][110]
See also
[edit]References
[edit]- ^ a b c d e f g Wooley JC, Godzik A, Friedberg I (February 2010). Bourne PE (ed.). "A primer on metagenomics". PLOS Computational Biology. 6 (2): e1000667. Bibcode:2010PLSCB...6E0667W. doi:10.1371/journal.pcbi.1000667. PMC 2829047. PMID 20195499.
- ^ a b Hugenholtz P, Goebel BM, Pace NR (September 1998). "Impact of culture-independent studies on the emerging phylogenetic view of bacterial diversity". Journal of Bacteriology. 180 (18): 4765–74. doi:10.1128/JB.180.18.4765-4774.1998. PMC 107498. PMID 9733676.
- ^ Marco, D, ed. (2011). Metagenomics: Current Innovations and Future Trends. Caister Academic Press. ISBN 978-1-904455-87-5.
- ^ Eisen JA (March 2007). "Environmental shotgun sequencing: its potential and challenges for studying the hidden world of microbes". PLOS Biology. 5 (3): e82. doi:10.1371/journal.pbio.0050082. PMC 1821061. PMID 17355177.
- ^ Handelsman J, Rondon MR, Brady SF, Clardy J, Goodman RM (October 1998). "Molecular biological access to the chemistry of unknown soil microbes: a new frontier for natural products". Chemistry & Biology. 5 (10): R245-9. doi:10.1016/S1074-5521(98)90108-9. PMID 9818143..
- ^ Chen K, Pachter L (July 2005). "Bioinformatics for whole-genome shotgun sequencing of microbial communities". PLOS Computational Biology. 1 (2): 106–12. Bibcode:2005PLSCB...1...24C. doi:10.1371/journal.pcbi.0010024. PMC 1185649. PMID 16110337.
- ^ Lane DJ, Pace B, Olsen GJ, Stahl DA, Sogin ML, Pace NR (October 1985). "Rapid determination of 16S ribosomal RNA sequences for phylogenetic analyses". Proceedings of the National Academy of Sciences of the United States of America. 82 (20): 6955–9. Bibcode:1985PNAS...82.6955L. doi:10.1073/pnas.82.20.6955. PMC 391288. PMID 2413450.
- ^ Pace NR, Stahl DA, Lane DJ, Olsen GJ (1986). "The Analysis of Natural Microbial Populations by Ribosomal RNA Sequences". In Marshall KC (ed.). Advances in Microbial Ecology. Vol. 9. Springer US. pp. 1–55. doi:10.1007/978-1-4757-0611-6_1. ISBN 978-1-4757-0611-6.
- ^ Schmidt TM, DeLong EF, Pace NR (July 1991). "Analysis of a marine picoplankton community by 16S rRNA gene cloning and sequencing". Journal of Bacteriology. 173 (14): 4371–8. doi:10.1128/jb.173.14.4371-4378.1991. PMC 208098. PMID 2066334.
- ^ Healy FG, Ray RM, Aldrich HC, Wilkie AC, Ingram LO, Shanmugam KT (1995). "Direct isolation of functional genes encoding cellulases from the microbial consortia in a thermophilic, anaerobic digester maintained on lignocellulose". Applied Microbiology and Biotechnology. 43 (4): 667–74. doi:10.1007/BF00164771. PMID 7546604. S2CID 31384119.
- ^ Stein JL, Marsh TL, Wu KY, Shizuya H, DeLong EF (February 1996). "Characterization of uncultivated prokaryotes: isolation and analysis of a 40-kilobase-pair genome fragment from a planktonic marine archaeon". Journal of Bacteriology. 178 (3): 591–9. doi:10.1128/jb.178.3.591-599.1996. PMC 177699. PMID 8550487.
- ^ Breitbart M, Salamon P, Andresen B, Mahaffy JM, Segall AM, Mead D, et al. (October 2002). "Genomic analysis of uncultured marine viral communities". Proceedings of the National Academy of Sciences of the United States of America. 99 (22): 14250–5. Bibcode:2002PNAS...9914250B. doi:10.1073/pnas.202488399. PMC 137870. PMID 12384570.
- ^ a b Tyson GW, Chapman J, Hugenholtz P, Allen EE, Ram RJ, Richardson PM, et al. (March 2004). "Community structure and metabolism through reconstruction of microbial genomes from the environment". Nature. 428 (6978): 37–43. Bibcode:2004Natur.428...37T. doi:10.1038/nature02340. PMID 14961025. S2CID 4420754.(subscription required)
- ^ Hugenholtz P (2002). "Exploring prokaryotic diversity in the genomic era". Genome Biology. 3 (2): REVIEWS0003. doi:10.1186/gb-2002-3-2-reviews0003. PMC 139013. PMID 11864374.
- ^ Venter JC, Remington K, Heidelberg JF, Halpern AL, Rusch D, Eisen JA, et al. (April 2004). "Environmental genome shotgun sequencing of the Sargasso Sea". Science. 304 (5667): 66–74. Bibcode:2004Sci...304...66V. CiteSeerX 10.1.1.124.1840. doi:10.1126/science.1093857. PMID 15001713. S2CID 1454587.
- ^ Yooseph S, Nealson KH, Rusch DB, McCrow JP, Dupont CL, Kim M, et al. (November 2010). "Genomic and functional adaptation in surface ocean planktonic prokaryotes". Nature. 468 (7320): 60–6. Bibcode:2010Natur.468...60Y. doi:10.1038/nature09530. PMID 21048761.(subscription required)
- ^ a b c Poinar HN, Schwarz C, Qi J, Shapiro B, Macphee RD, Buigues B, et al. (January 2006). "Metagenomics to paleogenomics: large-scale sequencing of mammoth DNA". Science. 311 (5759): 392–4. Bibcode:2006Sci...311..392P. doi:10.1126/science.1123360. PMID 16368896. S2CID 11238470.
- ^ Edwards RA, Rodriguez-Brito B, Wegley L, Haynes M, Breitbart M, Peterson DM, et al. (March 2006). "Using pyrosequencing to shed light on deep mine microbial ecology". BMC Genomics. 7: 57. doi:10.1186/1471-2164-7-57. PMC 1483832. PMID 16549033.
- ^ Thomas T, Gilbert J, Meyer F (February 2012). "Metagenomics - a guide from sampling to data analysis". Microbial Informatics and Experimentation. 2 (1): 3. doi:10.1186/2042-5783-2-3. PMC 3351745. PMID 22587947.
- ^ Béjà O, Suzuki MT, Koonin EV, Aravind L, Hadd A, Nguyen LP, et al. (October 2000). "Construction and analysis of bacterial artificial chromosome libraries from a marine microbial assemblage". Environmental Microbiology. 2 (5): 516–29. Bibcode:2000EnvMi...2..516B. doi:10.1046/j.1462-2920.2000.00133.x. PMID 11233160. S2CID 8267748.
- ^ a b Segata N, Boernigen D, Tickle TL, Morgan XC, Garrett WS, Huttenhower C (May 2013). "Computational meta'omics for microbial community studies". Molecular Systems Biology. 9 (666): 666. doi:10.1038/msb.2013.22. PMC 4039370. PMID 23670539.
- ^ Rodrigue S, Materna AC, Timberlake SC, Blackburn MC, Malmstrom RR, Alm EJ, Chisholm SW (July 2010). Gilbert JA (ed.). "Unlocking short read sequencing for metagenomics". PLOS ONE. 5 (7): e11840. Bibcode:2010PLoSO...511840R. doi:10.1371/journal.pone.0011840. PMC 2911387. PMID 20676378.
- ^ Schuster SC (January 2008). "Next-generation sequencing transforms today's biology". Nature Methods. 5 (1): 16–8. doi:10.1038/nmeth1156. PMID 18165802. S2CID 1465786.
- ^ "Metagenomics versus Moore's law". Nature Methods. 6 (9): 623. 2009. doi:10.1038/nmeth0909-623.
- ^ Stewart RD, Auffret MD, Warr A, Wiser AH, Press MO, Langford KW, et al. (February 2018). "Assembly of 913 microbial genomes from metagenomic sequencing of the cow rumen". Nature Communications. 9 (1): 870. Bibcode:2018NatCo...9..870S. doi:10.1038/s41467-018-03317-6. PMC 5830445. PMID 29491419.
- ^ Hiraoka S, Yang CC, Iwasaki W (September 2016). "Metagenomics and Bioinformatics in Microbial Ecology: Current Status and Beyond". Microbes and Environments. 31 (3): 204–12. doi:10.1264/jsme2.ME16024. PMC 5017796. PMID 27383682.
- ^ a b Pérez-Cobas AE, Gomez-Valero L, Buchrieser C (2020). "Metagenomic approaches in microbial ecology: an update on whole-genome and marker gene sequencing analyses". Microbial Genomics. 6 (8). doi:10.1099/mgen.0.000409. PMC 7641418. PMID 32706331.
- ^ a b Hess M, Sczyrba A, Egan R, Kim TW, Chokhawala H, Schroth G, et al. (January 2011). "Metagenomic discovery of biomass-degrading genes and genomes from cow rumen". Science. 331 (6016): 463–7. Bibcode:2011Sci...331..463H. doi:10.1126/science.1200387. PMID 21273488. S2CID 36572885.
- ^ Qin J, Li R, Raes J, Arumugam M, Burgdorf KS, Manichanh C, et al. (March 2010). "A human gut microbial gene catalogue established by metagenomic sequencing". Nature. 464 (7285): 59–65. Bibcode:2010Natur.464...59.. doi:10.1038/nature08821. PMC 3779803. PMID 20203603.(subscription required)
- ^ a b Paulson JN, Stine OC, Bravo HC, Pop M (December 2013). "Differential abundance analysis for microbial marker-gene surveys". Nature Methods. 10 (12): 1200–2. doi:10.1038/nmeth.2658. PMC 4010126. PMID 24076764.
- ^ a b c d e f g Committee on Metagenomics: Challenges and Functional Applications, National Research Council (2007). The New Science of Metagenomics: Revealing the Secrets of Our Microbial Planet. Washington, D.C.: The National Academies Press. doi:10.17226/11902. ISBN 978-0-309-10676-4. PMID 21678629.
- ^ Oulas A, Pavloudi C, Polymenakou P, Pavlopoulos GA, Papanikolaou N, Kotoulas G, et al. (2015). "Metagenomics: tools and insights for analyzing next-generation sequencing data derived from biodiversity studies". Bioinformatics and Biology Insights. 9: 75–88. doi:10.4137/BBI.S12462. PMC 4426941. PMID 25983555.
- ^ Mende DR, Waller AS, Sunagawa S, Järvelin AI, Chan MM, Arumugam M, et al. (23 February 2012). "Assessment of metagenomic assembly using simulated next generation sequencing data". PLOS ONE. 7 (2): e31386. Bibcode:2012PLoSO...731386M. doi:10.1371/journal.pone.0031386. PMC 3285633. PMID 22384016.
- ^ Balzer S, Malde K, Grohme MA, Jonassen I (April 2013). "Filtering duplicate reads from 454 pyrosequencing data". Bioinformatics. 29 (7): 830–6. doi:10.1093/bioinformatics/btt047. PMC 3605598. PMID 23376350.
- ^ Mohammed MH, Chadaram S, Komanduri D, Ghosh TS, Mande SS (September 2011). "Eu-Detect: an algorithm for detecting eukaryotic sequences in metagenomic data sets". Journal of Biosciences. 36 (4): 709–17. doi:10.1007/s12038-011-9105-2. PMID 21857117. S2CID 25857874.
- ^ Schmieder R, Edwards R (March 2011). "Fast identification and removal of sequence contamination from genomic and metagenomic datasets". PLOS ONE. 6 (3): e17288. Bibcode:2011PLoSO...617288S. doi:10.1371/journal.pone.0017288. PMC 3052304. PMID 21408061.
- ^ a b c d e Kunin V, Copeland A, Lapidus A, Mavromatis K, Hugenholtz P (December 2008). "A bioinformatician's guide to metagenomics". Microbiology and Molecular Biology Reviews. 72 (4): 557–78, Table of Contents. doi:10.1128/MMBR.00009-08. PMC 2593568. PMID 19052320.
- ^ Namiki T, Hachiya T, Tanaka H, Sakakibara Y (November 2012). "MetaVelvet: an extension of Velvet assembler to de novo metagenome assembly from short sequence reads". Nucleic Acids Research. 40 (20): e155. doi:10.1093/nar/gks678. PMC 3488206. PMID 22821567.
- ^ Zerbino DR, Birney E (May 2008). "Velvet: algorithms for de novo short read assembly using de Bruijn graphs". Genome Research. 18 (5): 821–9. doi:10.1101/gr.074492.107. PMC 2336801. PMID 18349386.
- ^ Burton JN, Liachko I, Dunham MJ, Shendure J (May 2014). "Species-level deconvolution of metagenome assemblies with Hi-C-based contact probability maps". G3. 4 (7): 1339–46. doi:10.1534/g3.114.011825. PMC 4455782. PMID 24855317.
- ^ Konopka A (November 2009). "What is microbial community ecology?". The ISME Journal. 3 (11): 1223–30. Bibcode:2009ISMEJ...3.1223K. doi:10.1038/ismej.2009.88. PMID 19657372.
- ^ a b Huson DH, Auch AF, Qi J, Schuster SC (March 2007). "MEGAN analysis of metagenomic data". Genome Research. 17 (3): 377–86. doi:10.1101/gr.5969107. PMC 1800929. PMID 17255551.
- ^ Segata N, Waldron L, Ballarini A, Narasimhan V, Jousson O, Huttenhower C (June 2012). "Metagenomic microbial community profiling using unique clade-specific marker genes". Nature Methods. 9 (8): 811–4. doi:10.1038/nmeth.2066. PMC 3443552. PMID 22688413.
- ^ Sunagawa S, Mende DR, Zeller G, Izquierdo-Carrasco F, Berger SA, Kultima JR, et al. (December 2013). "Metagenomic species profiling using universal phylogenetic marker genes". Nature Methods. 10 (12): 1196–9. doi:10.1038/nmeth.2693. PMID 24141494. S2CID 7728395.
- ^ a b Milanese A, Mende DR, Paoli L, Salazar G, Ruscheweyh HJ, Cuenca M, et al. (March 2019). "Microbial abundance, activity and population genomic profiling with mOTUs2". Nature Communications. 10 (1): 1014. Bibcode:2019NatCo..10.1014M. doi:10.1038/s41467-019-08844-4. PMC 6399450. PMID 30833550.
- ^ Liu B, Gibbons T, Ghodsi M, Treangen T, Pop M (2011). "Accurate and fast estimation of taxonomic profiles from metagenomic shotgun sequences". BMC Genomics. 12 (Suppl 2): S4. doi:10.1186/1471-2164-12-S2-S4. PMC 3194235. PMID 21989143.
- ^ Dadi TH, Renard BY, Wieler LH, Semmler T, Reinert K (2017). "SLIMM: species level identification of microorganisms from metagenomes". PeerJ. 5: e3138. doi:10.7717/peerj.3138. PMC 5372838. PMID 28367376.
- ^ Bowers, Robert M; Kyrpides, Nikos C; Stepanauskas, Ramunas; Harmon-Smith, Miranda; Doud, Devin; Reddy, T B K; Schulz, Frederik; Jarett, Jessica; Rivers, Adam R; Eloe-Fadrosh, Emiley A; Tringe, Susannah G; Ivanova, Natalia N; Copeland, Alex; Clum, Alicia; Becraft, Eric D; Malmstrom, Rex R; Birren, Bruce; Podar, Mircea; Bork, Peer; Weinstock, George M; Garrity, George M; Dodsworth, Jeremy A; Yooseph, Shibu; Sutton, Granger; Glöckner, Frank O; Gilbert, Jack A; Nelson, William C; Hallam, Steven J; Jungbluth, Sean P; Ettema, Thijs J G; Tighe, Scott; Konstantinidis, Konstantinos T; Liu, Wen-Tso; Baker, Brett J; Rattei, Thomas; Eisen, Jonathan A; Hedlund, Brian; McMahon, Katherine D; Fierer, Noah; Knight, Rob; Finn, Rob; Cochrane, Guy; Karsch-Mizrachi, Ilene; Tyson, Gene W; Rinke, Christian; Lapidus, Alla; Meyer, Folker; Yilmaz, Pelin; Parks, Donovan H; Murat Eren, A; Schriml, Lynn; Banfield, Jillian F; Hugenholtz, Philip; Woyke, Tanja (August 2017). "Minimum information about a single amplified genome (MISAG) and a metagenome-assembled genome (MIMAG) of bacteria and archaea". Nature Biotechnology. 35 (8): 725–731. doi:10.1038/nbt.3893. PMC 6436528.
- ^ a b Huson DH, Mitra S, Ruscheweyh HJ, Weber N, Schuster SC (September 2011). "Integrative analysis of environmental sequences using MEGAN4". Genome Research. 21 (9): 1552–60. doi:10.1101/gr.120618.111. PMC 3166839. PMID 21690186.
- ^ Zhu W, Lomsadze A, Borodovsky M (July 2010). "Ab initio gene identification in metagenomic sequences". Nucleic Acids Research. 38 (12): e132. doi:10.1093/nar/gkq275. PMC 2896542. PMID 20403810.
- ^ Pagani I, Liolios K, Jansson J, Chen IM, Smirnova T, Nosrat B, et al. (January 2012). "The Genomes OnLine Database (GOLD) v.4: status of genomic and metagenomic projects and their associated metadata". Nucleic Acids Research. 40 (Database issue): D571-9. doi:10.1093/nar/gkr1100. PMC 3245063. PMID 22135293.
- ^ Meyer F, Paarmann D, D'Souza M, Olson R, Glass EM, Kubal M, et al. (September 2008). "The metagenomics RAST server - a public resource for the automatic phylogenetic and functional analysis of metagenomes". BMC Bioinformatics. 9: 386. doi:10.1186/1471-2105-9-386. PMC 2563014. PMID 18803844.
- ^ Markowitz VM, Chen IM, Chu K, Szeto E, Palaniappan K, Grechkin Y, et al. (January 2012). "IMG/M: the integrated metagenome data management and comparative analysis system". Nucleic Acids Research. 40 (Database issue): D123-9. doi:10.1093/nar/gkr975. PMC 3245048. PMID 22086953.
- ^ a b Mitra S, Rupek P, Richter DC, Urich T, Gilbert JA, Meyer F, et al. (February 2011). "Functional analysis of metagenomes and metatranscriptomes using SEED and KEGG". BMC Bioinformatics. 12 (Suppl 1): S21. doi:10.1186/1471-2105-12-S1-S21. PMC 3044276. PMID 21342551.
- ^ Benson DA, Cavanaugh M, Clark K, Karsch-Mizrachi I, Lipman DJ, Ostell J, Sayers EW (January 2013). "GenBank". Nucleic Acids Research. 41 (Database issue): D36-42. doi:10.1093/nar/gks1195. PMC 3531190. PMID 23193287.
- ^ Bazinet AL, Cummings MP (May 2012). "A comparative evaluation of sequence classification programs". BMC Bioinformatics. 13: 92. doi:10.1186/1471-2105-13-92. PMC 3428669. PMID 22574964.
- ^ Ounit R, Wanamaker S, Close TJ, Lonardi S (March 2015). "CLARK: fast and accurate classification of metagenomic and genomic sequences using discriminative k-mers". BMC Genomics. 16 (1): 236. doi:10.1186/s12864-015-1419-2. PMC 4428112. PMID 25879410.
- ^ Pratas D, Pinho AJ, Silva RM, Rodrigues JM, Hosseini M, Caetano T, Ferreira PJ (February 2018). "FALCON: a method to infer metagenomic composition of ancient DNA". bioRxiv 10.1101/267179.
- ^ Kurokawa K, Itoh T, Kuwahara T, Oshima K, Toh H, Toyoda A, et al. (August 2007). "Comparative metagenomics revealed commonly enriched gene sets in human gut microbiomes". DNA Research. 14 (4): 169–81. doi:10.1093/dnares/dsm018. PMC 2533590. PMID 17916580.
- ^ a b c d e f Simon C, Daniel R (February 2011). "Metagenomic analyses: past and future trends". Applied and Environmental Microbiology. 77 (4): 1153–61. Bibcode:2011ApEnM..77.1153S. doi:10.1128/AEM.02345-10. PMC 3067235. PMID 21169428.
- ^ Willner D, Thurber RV, Rohwer F (July 2009). "Metagenomic signatures of 86 microbial and viral metagenomes". Environmental Microbiology. 11 (7): 1752–66. Bibcode:2009EnvMi..11.1752W. doi:10.1111/j.1462-2920.2009.01901.x. PMID 19302541.
- ^ Ghosh TS, Mohammed MH, Rajasingh H, Chadaram S, Mande SS (2011). "HabiSign: a novel approach for comparison of metagenomes and rapid identification of habitat-specific sequences". BMC Bioinformatics. 12 Suppl 13 (Supplement 13): S9. doi:10.1186/1471-2105-12-s13-s9. PMC 3278849. PMID 22373355.
- ^ Fimereli D, Detours V, Konopka T (April 2013). "TriageTools: tools for partitioning and prioritizing analysis of high-throughput sequencing data". Nucleic Acids Research. 41 (7): e86. doi:10.1093/nar/gkt094. PMC 3627586. PMID 23408855.
- ^ Maillet N, Lemaitre C, Chikhi R, Lavenier D, Peterlongo P (2012). "Compareads: comparing huge metagenomic experiments". BMC Bioinformatics. 13 (Suppl 19): S10. doi:10.1186/1471-2105-13-S19-S10. PMC 3526429. PMID 23282463.
- ^ Kuntal BK, Ghosh TS, Mande SS (October 2013). "Community-analyzer: a platform for visualizing and comparing microbial community structure across microbiomes". Genomics. 102 (4): 409–18. doi:10.1016/j.ygeno.2013.08.004. PMID 23978768.
- ^ Werner JJ, Knights D, Garcia ML, Scalfone NB, Smith S, Yarasheski K, et al. (March 2011). "Bacterial community structures are unique and resilient in full-scale bioenergy systems". Proceedings of the National Academy of Sciences of the United States of America. 108 (10): 4158–63. Bibcode:2011PNAS..108.4158W. doi:10.1073/pnas.1015676108. PMC 3053989. PMID 21368115.
- ^ McInerney MJ, Sieber JR, Gunsalus RP (December 2009). "Syntrophy in anaerobic global carbon cycles". Current Opinion in Biotechnology. 20 (6): 623–32. doi:10.1016/j.copbio.2009.10.001. PMC 2790021. PMID 19897353.
- ^ Klitgord N, Segrè D (August 2011). "Ecosystems biology of microbial metabolism". Current Opinion in Biotechnology. 22 (4): 541–6. doi:10.1016/j.copbio.2011.04.018. PMID 21592777.
- ^ Leininger S, Urich T, Schloter M, Schwark L, Qi J, Nicol GW, et al. (August 2006). "Archaea predominate among ammonia-oxidizing prokaryotes in soils". Nature. 442 (7104): 806–9. Bibcode:2006Natur.442..806L. doi:10.1038/nature04983. PMID 16915287. S2CID 4380804.
- ^ Paez-Espino D, Eloe-Fadrosh EA, Pavlopoulos GA, Thomas AD, Huntemann M, Mikhailova N, et al. (August 2016). "Uncovering Earth's virome". Nature. 536 (7617): 425–30. Bibcode:2016Natur.536..425P. doi:10.1038/nature19094. PMID 27533034. S2CID 4466854.
- ^ Paez-Espino D, Chen IA, Palaniappan K, Ratner A, Chu K, Szeto E, et al. (January 2017). "IMG/VR: a database of cultured and uncultured DNA Viruses and retroviruses". Nucleic Acids Research. 45 (D1): D457–D465. doi:10.1093/nar/gkw1030. PMC 5210529. PMID 27799466.
- ^ Paez-Espino D, Roux S, Chen IA, Palaniappan K, Ratner A, Chu K, et al. (January 2019). "IMG/VR v.2.0: an integrated data management and analysis system for cultivated and environmental viral genomes". Nucleic Acids Research. 47 (D1): D678–D686. doi:10.1093/nar/gky1127. PMC 6323928. PMID 30407573.
- ^ Paez-Espino D, Pavlopoulos GA, Ivanova NN, Kyrpides NC (August 2017). "Nontargeted virus sequence discovery pipeline and virus clustering for metagenomic data" (PDF). Nature Protocols. 12 (8): 1673–1682. doi:10.1038/nprot.2017.063. PMID 28749930. S2CID 2127494.
- ^ Kristensen DM, Mushegian AR, Dolja VV, Koonin EV (January 2010). "New dimensions of the virus world discovered through metagenomics". Trends in Microbiology. 18 (1): 11–9. doi:10.1016/j.tim.2009.11.003. PMC 3293453. PMID 19942437.
- ^ Kerepesi C, Grolmusz V (March 2016). "Giant viruses of the Kutch Desert". Archives of Virology. 161 (3): 721–4. arXiv:1410.1278. doi:10.1007/s00705-015-2720-8. PMID 26666442. S2CID 13145926.
- ^ Kerepesi C, Grolmusz V (June 2017). "The "Giant Virus Finder" discovers an abundance of giant viruses in the Antarctic dry valleys". Archives of Virology. 162 (6): 1671–1676. arXiv:1503.05575. doi:10.1007/s00705-017-3286-4. PMID 28247094. S2CID 1925728.
- ^ Copeland CS (September–October 2017). "The World Within Us" (PDF). Healthcare Journal of New Orleans: 21–26.
- ^ Jansson J (2011). "Towards "Tera-Terra": Terabase Sequencing of Terrestrial Metagenomes Print E-mail". Microbe. Vol. 6, no. 7. p. 309. Archived from the original on 31 March 2012.
- ^ Vogel TM, Simonet P, Jansson JK, Hirsch PR, Tiedje JM, Van Elsas JD, Bailey MJ, Nalin R, Philippot L (2009). "TerraGenome: A consortium for the sequencing of a soil metagenome". Nature Reviews Microbiology. 7 (4): 252. doi:10.1038/nrmicro2119.
- ^ "TerraGenome Homepage". TerraGenome international sequencing consortium. Retrieved 30 December 2011.
- ^ a b Committee on Metagenomics: Challenges and Functional Applications, National Research Council (2007). Understanding Our Microbial Planet: The New Science of Metagenomics (PDF). The National Academies Press. Archived from the original (PDF) on 30 October 2012. Retrieved 30 December 2011.
- ^ Charles T (2010). "The Potential for Investigation of Plant-microbe Interactions Using Metagenomics Methods". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ^ Bringel F, Couée I (22 May 2015). "Pivotal roles of phyllosphere microorganisms at the interface between plant functioning and atmospheric trace gas dynamics". Frontiers in Microbiology. 6: 486. doi:10.3389/fmicb.2015.00486. PMC 4440916. PMID 26052316.
- ^ Li LL, McCorkle SR, Monchy S, Taghavi S, van der Lelie D (May 2009). "Bioprospecting metagenomes: glycosyl hydrolases for converting biomass". Biotechnology for Biofuels. 2: 10. doi:10.1186/1754-6834-2-10. PMC 2694162. PMID 19450243.
- ^ Jaenicke S, Ander C, Bekel T, Bisdorf R, Dröge M, Gartemann KH, et al. (January 2011). Aziz RK (ed.). "Comparative and joint analysis of two metagenomic datasets from a biogas fermenter obtained by 454-pyrosequencing". PLOS ONE. 6 (1): e14519. Bibcode:2011PLoSO...614519J. doi:10.1371/journal.pone.0014519. PMC 3027613. PMID 21297863.
- ^ Suen G, Scott JJ, Aylward FO, Adams SM, Tringe SG, Pinto-Tomás AA, et al. (September 2010). Sonnenburg J (ed.). "An insect herbivore microbiome with high plant biomass-degrading capacity". PLOS Genetics. 6 (9): e1001129. doi:10.1371/journal.pgen.1001129. PMC 2944797. PMID 20885794.
- ^ Simon C, Daniel R (November 2009). "Achievements and new knowledge unraveled by metagenomic approaches". Applied Microbiology and Biotechnology. 85 (2): 265–76. doi:10.1007/s00253-009-2233-z. PMC 2773367. PMID 19760178.
- ^ Wong D (2010). "Applications of Metagenomics for Industrial Bioproducts". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ^ a b Schloss PD, Handelsman J (June 2003). "Biotechnological prospects from metagenomics" (PDF). Current Opinion in Biotechnology. 14 (3): 303–10. doi:10.1016/S0958-1669(03)00067-3. PMID 12849784. Archived from the original (PDF) on 4 March 2016. Retrieved 20 January 2012.
- ^ a b c Kakirde KS, Parsley LC, Liles MR (November 2010). "Size Does Matter: Application-driven Approaches for Soil Metagenomics". Soil Biology & Biochemistry. 42 (11): 1911–1923. doi:10.1016/j.soilbio.2010.07.021. PMC 2976544. PMID 21076656.
- ^ Parachin NS, Gorwa-Grauslund MF (May 2011). "Isolation of xylose isomerases by sequence- and function-based screening from a soil metagenomic library". Biotechnology for Biofuels. 4 (1): 9. doi:10.1186/1754-6834-4-9. PMC 3113934. PMID 21545702.
- ^ Hover BM, Kim SH, Katz M, Charlop-Powers Z, Owen JG, Ternei MA, et al. (April 2018). "Culture-independent discovery of the malacidins as calcium-dependent antibiotics with activity against multidrug-resistant Gram-positive pathogens". Nature Microbiology. 3 (4): 415–422. doi:10.1038/s41564-018-0110-1. PMC 5874163. PMID 29434326.
- ^ Raes J, Letunic I, Yamada T, Jensen LJ, Bork P (March 2011). "Toward molecular trait-based ecology through integration of biogeochemical, geographical and metagenomic data". Molecular Systems Biology. 7: 473. doi:10.1038/msb.2011.6. PMC 3094067. PMID 21407210.
- ^ Lavery TJ, Roudnew B, Seymour J, Mitchell JG, Jeffries T (2012). Steinke D (ed.). "High nutrient transport and cycling potential revealed in the microbial metagenome of Australian sea lion (Neophoca cinerea) faeces". PLOS ONE. 7 (5): e36478. Bibcode:2012PLoSO...736478L. doi:10.1371/journal.pone.0036478. PMC 3350522. PMID 22606263.
- ^ "What's Swimming in the River? Just Look For DNA". NPR.org. 24 July 2013. Retrieved 10 October 2014.
- ^ Chua, Physilia Y. S.; Crampton-Platt, Alex; Lammers, Youri; Alsos, Inger G.; Boessenkool, Sanne; Bohmann, Kristine (25 May 2021). "Metagenomics: A viable tool for reconstructing herbivore diet". Molecular Ecology Resources. 21 (7): 1755–0998.13425. doi:10.1111/1755-0998.13425. PMC 8518049. PMID 33971086.
- ^ Chua, Physilia Y. S.; Carøe, Christian; Crampton-Platt, Alex; Reyes-Avila, Claudia S.; Jones, Gareth; Streicker, Daniel G.; Bohmann, Kristine (4 July 2022). "A two-step metagenomics approach for the identification and mitochondrial DNA contig assembly of vertebrate prey from the blood meals of common vampire bats (Desmodus rotundus)". Metabarcoding and Metagenomics. 6: e78756. doi:10.3897/mbmg.6.78756. ISSN 2534-9708. S2CID 248041252.
- ^ George I, Stenuit B, Agathos SN (2010). "Application of Metagenomics to Bioremediation". In Marco D (ed.). Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ^ Zimmer C (13 July 2010). "How Microbes Defend and Define Us". New York Times. Retrieved 29 December 2011.
- ^ Nelson KE and White BA (2010). "Metagenomics and Its Applications to the Study of the Human Microbiome". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ^ a b Qin, Junjie; Li, Ruiqiang; Raes, Jeroen; Arumugam, Manimozhiyan; Burgdorf, Kristoffer Solvsten; Manichanh, Chaysavanh; Nielsen, Trine; Pons, Nicolas; Levenez, Florence; Yamada, Takuji; Mende, Daniel R.; Li, Junhua; Xu, Junming; Li, Shaochuan; Li, Dongfang (2010). "A human gut microbial gene catalogue established by metagenomic sequencing". Nature. 464 (7285): 59–65. Bibcode:2010Natur.464...59.. doi:10.1038/nature08821. ISSN 1476-4687. PMC 3779803. PMID 20203603.
- ^ Qin J, Li R, Raes J, Arumugam M, Burgdorf KS, Manichanh C, et al. (March 2010). "A human gut microbial gene catalogue established by metagenomic sequencing". Nature. 464 (7285): 59–65. Bibcode:2010Natur.464...59.. doi:10.1038/nature08821. PMC 3779803. PMID 20203603.
- ^ Abubucker, Sahar; Segata, Nicola; Goll, Johannes; Schubert, Alyxandria M.; Izard, Jacques; Cantarel, Brandi L.; Rodriguez-Mueller, Beltran; Zucker, Jeremy; Thiagarajan, Mathangi; Henrissat, Bernard; White, Owen; Kelley, Scott T.; Methé, Barbara; Schloss, Patrick D.; Gevers, Dirk; Mitreva, Makedonka; Huttenhower, Curtis (2012). "PLOS Computational Biology: Metabolic Reconstruction for Metagenomic Data and Its Application to the Human Microbiome". PLOS Computational Biology. 8 (6): e1002358. Bibcode:2012PLSCB...8E2358A. doi:10.1371/journal.pcbi.1002358. PMC 3374609. PMID 22719234.
- ^ Chua, Physilia Ying Shi; Rasmussen, Jacob Agerbo (11 May 2022). "Taking metagenomics under the wings". Nature Reviews Microbiology. 20 (8): 447. doi:10.1038/s41579-022-00746-5. ISSN 1740-1534. PMID 35546350. S2CID 248739527.
- ^ Chiu, Charles Y.; Miller, Steven A. (2019). "Clinical metagenomics". Nature Reviews Genetics. 20 (6): 341–355. doi:10.1038/s41576-019-0113-7. ISSN 1471-0064. PMC 6858796. PMID 30918369.
- ^ Zakrzewski M, Rašić G, Darbro J, Krause L, Poo YS, Filipović I, et al. (2018). "Mapping the virome in wild-caught Aedes aegypti from Cairns and Bangkok". Sci Rep. 8 (1): 4690. Bibcode:2018NatSR...8.4690Z. doi:10.1038/s41598-018-22945-y. PMC 5856816. PMID 29549363.
- ^ Thoendel M (2020). "Targeted Metagenomics Offers Insights into Potential Tick-Borne Pathogens". J Clin Microbiol. 58 (11). doi:10.1128/JCM.01893-20. PMC 7587107. PMID 32878948.
- ^ Parry R, James ME, Asgari S (2021). "Uncovering the Worldwide Diversity and Evolution of the Virome of the Mosquitoes Aedes aegypti and Aedes albopictus". Microorganisms. 9 (8): 1653. doi:10.3390/microorganisms9081653. PMC 8398489. PMID 34442732.
- ^ Batovska J, Mee PT, Lynch SE, Sawbridge TI, Rodoni BC (2019). "Sensitivity and specificity of metatranscriptomics as an arbovirus surveillance tool". Sci Rep. 9 (1): 19398. Bibcode:2019NatSR...919398B. doi:10.1038/s41598-019-55741-3. PMC 6920425. PMID 31852942.
- ^ Batovska J, Lynch SE, Rodoni BC, Sawbridge TI, Cogan NO (2017). "Metagenomic arbovirus detection using MinION nanopore sequencing". J Virol Methods. 249: 79–84. doi:10.1016/j.jviromet.2017.08.019. PMID 28855093.
External links
[edit]- Focus on Metagenomics at Nature Reviews Microbiology journal website
- The “Critical Assessment of Metagenome Interpretation” (CAMI) initiative to evaluate methods in metagenomics
| Fields | |
|---|---|
| Bioinformatics | |
| Structural biology | |
| Research tools | |
| Organizations | |