[[Image:Sw-horz-w3c.png|thumb|right|W3C's Semantic Web logo]]
[[Image:Sw-horz-w3c.png|thumb|right|W3C's Semantic Web logo]]
The '''Semantic Web''' is a group of methodsandtechnologies to allow machines to understand the meaning – or "semantics" – of information on the [[World Wide Web]].<ref name="w3c faq">{{cite web |url=http://www.w3.org/2001/sw/SW-FAQ |title= W3C Semantic Web Frequently Asked Questions |publisher=[[W3C]] |accessdate=March 13, 2008}}</ref> Thetermwascoinedby [[WorldWideWebConsortium]] (W3C)director [[Tim Berners-Lee]].<ref>{{cite journal |last=Berners-Lee |first=Tim |coauthors=James Hendler and Ora Lassila |title=The Semantic Web |journal=Scientific American Magazine |date=May 17, 2001 |url=http://www.sciam.com/article.cfm?id=the-semantic-web&print=true |accessdate=March 26, 2008}}</ref> He defines the ''Semantic Web'' as “a web of data that can be processed directly and indirectly by machines.”
The '''Semantic Web''' is a "web of data" that enables machines to understand the [[semantics]], or meaning, of information on the [[World Wide Web]].<ref name="w3c faq">{{cite web |url=http://www.w3.org/2001/sw/SW-FAQ |title= W3C Semantic Web Frequently Asked Questions |publisher=[[W3C]] |accessdate=March 13, 2008}}</ref> It extends the network of [[hyperlink]]ed human-readable [[web pages]] by inserting machine-readable [[metadata]] about pages and how they are related to each other, which greatly increases the ease of automated data gathering and analysis. The term was coined by [[Tim Berners-Lee]],<ref>{{cite journal |last=Berners-Lee |first=Tim |coauthors=James Hendler and Ora Lassila |title=The Semantic Web |journal=Scientific American Magazine |date=May 17, 2001 |url=http://www.sciam.com/article.cfm?id=the-semantic-web&print=true |accessdate=March 26, 2008}}</ref> the inventor of the World Wide Web and director of the [[World Wide Web Consortium]], which oversees the development of proposed Semantic Web standards. He defines the Semantic Web as "a web of data that can be processed directly and indirectly by machines."
While the term "Semantic Web" is notformallydefineditismainly used to describe the model and technologies<ref name="W3C, SemWeb" >{{cite web |url=http://www.w3.org/2001/sw/ |title=W3C Semantic Web Activity |publisher=[[W3C]] |accessdate=March 13, 2008 |date=March 12, 2008 |author=Herman, Ivan}}</ref> proposed by the W3C. These technologies include the [[Resource Description Framework]] (RDF), a variety of data interchange formats (e.g. [[Resource Description Framework|RDF/XML]], [[Notation 3|N3]], [[Turtle (syntax)|Turtle]], [[N-Triples]]), and notations such as [[RDF Schema]] (RDFS) and the [[Web Ontology Language]] (OWL), all of which are intended to provide a [[description logic|formal description]] of [[concept]]s, [[terminology|terms]], and [[Causality|relationships]] within a given [[knowledge domain]].
The term "Semantic Web" is often used more specifically to refer to the formats and technologies that enable it.<ref name="W3C, SemWeb" >{{cite web |url=http://www.w3.org/2001/sw/ |title=W3C Semantic Web Activity |publisher=[[W3C]] |accessdate=March 13, 2008 |date=March 12, 2008 |author=Herman, Ivan}}</ref> These technologies include the [[Resource Description Framework]] (RDF), a variety of data interchange formats (e.g. [[Resource Description Framework|RDF/XML]], [[Notation 3|N3]], [[Turtle (syntax)|Turtle]], [[N-Triples]]), and notations such as [[RDF Schema]] (RDFS) and the [[Web Ontology Language]] (OWL), all of which are intended to provide a [[description logic|formal description]] of [[concept]]s, [[terminology|terms]], and [[Causality|relationships]] within a given [[knowledge domain]].
Many of the technologies proposed by the W3C already exist and are used in various contexts, particularly those dealing with information that encompasses a limited and defined domain, and where sharing data is a common necessity, such as scientific research or data exchange among businesses. In addition, other technologies with similar goals have emerged, such as [[microformat]]s. However, the Semantic Web as originally envisioned, a system that enables machines to understand and respond to complex human requests based on their meaning, has remained largely unrealized and its critics have questioned its feasibility.
The key element is that the application in context will try to determine the meaning of the text or other data and then create connections for the user. The evolution of Semantic Web will specifically make possible scenarios that were not otherwise, such as allowing customers to share and utilize computerized applications simultaneously in order to cross reference the time frame of activities with documentation and/or data. According to the original vision, the availability of machine-readable [[Metadata (computing)|metadata]] would enable automated agents and other software to access the Web more intelligently. The agents would be able to perform tasks automatically and locate related information on behalf of the user.
Many of the technologies proposed by the W3C already exist and are used in various projects. The Semantic Web as a global vision, however, has remained largely unrealized and its critics have questioned the feasibility of the approach.
In addition other technologies with similar goals, such as [[microformat]]s, have evolved, which are not always described as "Semantic Web".
The Semantic Web is a "web of data" that enables machines to understand the semantics, or meaning, of information on the World Wide Web.[1] It extends the network of hyperlinked human-readable web pages by inserting machine-readable metadata about pages and how they are related to each other, which greatly increases the ease of automated data gathering and analysis. The term was coined by Tim Berners-Lee,[2] the inventor of the World Wide Web and director of the World Wide Web Consortium, which oversees the development of proposed Semantic Web standards. He defines the Semantic Web as "a web of data that can be processed directly and indirectly by machines."
Many of the technologies proposed by the W3C already exist and are used in various contexts, particularly those dealing with information that encompasses a limited and defined domain, and where sharing data is a common necessity, such as scientific research or data exchange among businesses. In addition, other technologies with similar goals have emerged, such as microformats. However, the Semantic Web as originally envisioned, a system that enables machines to understand and respond to complex human requests based on their meaning, has remained largely unrealized and its critics have questioned its feasibility.
Purpose
The main purpose of the Semantic Web is driving the evolution of the current Web by allowing users to use it to its full potential, thus allowing them to find, share, and combine information more easily.
Humans are capable of using the Web to carry out tasks such as finding the Irish word for "folder," reserving a library book, and searching for a low price for a DVD. However, machines cannot accomplish all of these tasks without human direction, because web pages are designed to be read by people, not machines. The semantic web is a vision of information that can be interpreted by machines, so machines can perform more of the tedious work involved in finding, combining, and acting upon information on the web.
Tim Berners-Lee originally expressed the vision of the semantic web as follows:[4]
I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web – the content, links, and transactions between people and computers. A ‘Semantic Web’, which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ‘intelligent agents’ people have touted for ages will finally materialize.
Semantic Web application areas are experiencing intensified interest due to the rapid growth in the use of the Web, together with the innovation and renovation of information content technologies. The Semantic Web is regarded as an integrator across different content, information applications and systems, it also provides mechanisms for the realisation of Enterprise Information Systems. The rapidity of the growth experienced provides the impetus for researchers to focus on the creation and dissemination of innovative Semantic Web technologies, where the envisaged ’Semantic Web’ is long overdue. Often the terms ’Semantics’, ’metadata’, ’ontologies’ and ’Semantic Web’ are used inconsistently. In particular, these terms are used as everyday terminology by researchers and practitioners, spanning a vast landscape of different fields, technologies, concepts and application areas. Furthermore, there is confusion with regards to the current status of the enabling technologies envisioned to realise the Semantic Web. In a paper presented by Gerber, Barnard and Van der Merwe[5] the Semantic Web landscape is charted and a brief summary of related terms and enabling technologies is presented. The architectural model proposed by Tim Berners-Lee is used as basis to present a status model that reflects current and emerging technologies.[6]
Semantic Publishing
Semantic publishing will greatly benefit from the semantic web. In particular, the semantic web is expected to revolutionize scientific publishing, such as real-time publishing and sharing of experimental data on the Internet. This simple but radical idea is now being explored by W3C HCLS group's Scientific Publishing Task Force.
Semantic Blogging
Semantic blogging, like semantic publishing, will change the way blogs are read. Currently "the process of blogging inherently emphasizes metadata creation more than traditional Web publishing methodologies".[7] Some blog users already tag their entries with topics, allowing for easier migration into a semantic web environment. It is intentionally saved in not only a human-readable format, but also in a machine-readable format as the tags can be linked easily to other blogs containing similar information. When a release of a game or movie occurs, bloggers tend to rate them using their own system. If there were to be a unified system, these blogs could easily become assimilated using similar semantics and give a user a score when searching using a semantic search. RSS feeds are another way that blogs already have machine-readable data that is easily accessible by the semantic web.
Tim Berners-Lee has described the semantic web as a component of 'Web 3.0'.[8]
The internet community as a whole tends to find the two terms "Semantic Web" and "Web 3.0" to be at least synonymous in concept if not completely interchangeable. The definition continues to vary depending on to whom you speak. The overwhelming consensus is that Web 3.0 is most assuredly the "next big thing" but there only lies speculation as to just what that might be. It will be an improvement in the respect that it will still contain Web 2.0 properties while continuing to add to its ever expanding lexicon and library of applications. There are some who claim that Web 3.0 will be more application based and center its efforts towards more graphically capable environments, "non-browser applications and non-computer based devices...geographic or location-based information retrieval" and even more applicable use and growth of Artificial Intelligence.[9] For example, Conrad Wolfram, has argued that Web 3.0 is where "the computer is generating new information", rather than humans.[10]
Others simply state their belief that Web 3.0 will primarily focus on dramatically improving the functionality and usability of search engines.[11] An important factor that users must continue to keep in mind is that the transition to Web 2.0 from "Web 1.0" took approximately ten years. Given the same time frame, this next transition will not be complete until around the year 2015.
People keep asking what Web 3.0 is. I think maybe when you've got an overlay of scalable vector graphics – everything rippling and folding and looking misty — on Web 2.0 and access to a semantic Web integrated across a huge space of data, you'll have access to an unbelievable data resource..."
Highly specialized information silos, moderated by a cult of personality, validated by the community, and put into context with the inclusion of meta-data through widgets.[12]
Many files on a typical computer can be loosely divided into documents and data. Documents like mail messages, reports, and brochures are read by humans. Data, like calendars, addressbooks, playlists, and spreadsheets are presented using an application program which lets them be viewed, searched and combined in many ways.
Currently, the World Wide Web is based mainly on documents written in Hypertext Markup Language (HTML), a markup convention that is used for coding a body of text interspersed with multimedia objects such as images and interactive forms. Metadata tags, for example
<metaname="keywords"content="computing, computer studies, computer"><metaname="description"content="Cheap widgets for sale"><metaname="author"content="John Doe">
provide a method by which computers can categorise the content of web pages.
With HTML and a tool to render it (perhaps web browser software, perhaps another user agent), one can create and present a page that lists items for sale. The HTML of this catalog page can make simple, document-level assertions such as "this document's title is 'Widget Superstore'", but there is no capability within the HTML itself to assert unambiguously that, for example, item number X586172 is an Acme Gizmo with a retail price of €199, or that it is a consumer product. Rather, HTML can only say that the span of text "X586172" is something that should be positioned near "Acme Gizmo" and "€199", etc. There is no way to say "this is a catalog" or even to establish that "Acme Gizmo" is a kind of title or that "€199" is a price. There is also no way to express that these pieces of information are bound together in describing a discrete item, distinct from other items perhaps listed on the page.
Semantic HTML refers to the traditional HTML practice of markup following intention, rather than specifying layout details directly. For example, the use of <em> denoting "emphasis" rather than <i>, which specifies italics. Layout details are left up to the browser, in combination with Cascading Style Sheets. But this practice falls short of specifying the semantics of objects such as items for sale or prices.
Microformats represent unofficial attempts to extend HTML syntax to create machine-readable semantic markup about objects such as retail stores and items for sale.
Semantic Web solutions
The Semantic Web takes the solution further. It involves publishing in languages specifically designed for data: Resource Description Framework (RDF), Web Ontology Language (OWL), and Extensible Markup Language (XML). HTML describes documents and the links between them. RDF, OWL, and XML, by contrast, can describe arbitrary things such as people, meetings, or airplane parts. Tim Berners-Lee calls the resulting network of Linked Data the Giant Global Graph, in contrast to the HTML-based World Wide Web.
These technologies are combined in order to provide descriptions that supplement or replace the content of Web documents. Thus, content may manifest itself as descriptive data stored in Web-accessible databases,[13] or as markup within documents (particularly, in Extensible HTML (XHTML) interspersed with XML, or, more often, purely in XML, with layout or rendering cues stored separately). The machine-readable descriptions enable content managers to add meaning to the content, i.e., to describe the structure of the knowledge we have about that content. In this way, a machine can process knowledge itself, instead of text, using processes similar to human deductive reasoning and inference, thereby obtaining more meaningful results and helping computers to perform automated information gathering and research.
An example of a tag that would be used in a non-semantic web page:
<item>cat</item>
Encoding similar information in a semantic web page might look like this:
Critics (e.g. Which Semantic Web?) question the basic feasibility of a complete or even partial fulfillment of the semantic web. Cory Doctorow's critique ("metacrap") is from the perspective of human behavior and personal preferences. For example, people lie: they may include spurious metadata into Web pages in an attempt to mislead Semantic Web engines that naively assume the metadata's veracity. This phenomenon was well-known with metatags that fooled the AltaVista ranking algorithm into elevating the ranking of certain Web pages: the Google indexing engine specifically looks for such attempts at manipulation. Peter Gärdenfors and Timo Honkela point out that logic-based semantic web technologies cover only a fraction of the relevant phenomena related to semantics.[14][15]
Where semantic web technologies have found a greater degree of practical adoption, it has tended to be among core specialized communities and organizations for intra-company projects.[16] The practical constraints toward adoption have appeared less challenging where domain and scope is more limited than that of the general public and the World-Wide Web.[16]
The potential of an idea in fast progress
The original 2001 Scientific American article by Berners-Lee described an expected evolution of the existing Web to a Semantic Web.[17] A complete evolution as described by Berners-Lee has yet to occur. In 2006, Berners-Lee and colleagues stated that: "This simple idea, however, remains largely unrealized."[18] While the idea is still in the making, it seems to evolve quickly and inspire many. Between 2007–2010 several scholars have already explored first applications and the social potential of the semantic web in the business and health sectors, and for social networking [19] and even for the broader evolution of democracy, specifically, how a society forms its common will in a democratic manner through a semantic web[20]
Censorship and privacy
Enthusiasm about the semantic web could be tempered by concerns regarding censorship and privacy. For instance, text-analyzing techniques can now be easily bypassed by using other words, metaphors for instance, or by using images in place of words. An advanced implementation of the semantic web would make it much easier for governments to control the viewing and creation of online information, as this information would be much easier for an automated content-blocking machine to understand. In addition, the issue has also been raised that, with the use of FOAF files and geo location meta-data, there would be very little anonymity associated with the authorship of articles on things such as a personal blog. Some of these concerns were addressed in the "Policy Aware Web" project[21] and is an active research and development topic.
Doubling output formats
Another criticism of the semantic web is that it would be much more time-consuming to create and publish content because there would need to be two formats for one piece of data: one for human viewing and one for machines. However, many web applications in development are addressing this issue by creating a machine-readable format upon the publishing of data or the request of a machine for such data. The development of microformats has been one reaction to this kind of criticism. Another argument in defense of the feasibility of semantic web is the likely falling price of human intelligence tasks in digital labor markets like the Amazon Mechanical Turk.
Specifications such as eRDF and RDFa allow arbitrary RDF data to be embedded in HTML pages. The GRDDL (Gleaning Resource Descriptions from Dialects of Language) mechanism allows existing material (including microformats) to be automatically interpreted as RDF, so publishers only need to use a single format, such as HTML.
Need
The idea of a semantic web, able to describe and associate meaning with data necessarily involves more than simple XHTML mark-up code. It is based on an assumption that in order for it to be possible to endow machines with an ability to accurately interpret web homed content, far more than the mere ordered relationships involving letters and words, is necessary as underlying infrastructure (attendant to semantic issues). Otherwise, most of the supportive functionality would have been available in Web 2.0 (and before) and it would have been possible to derive a semantically capable Web with minor, incremental additions.
Additions to the infrastructure to support semantic functionality include latent dynamic network models that can, under certain conditions, be 'trained' to appropriately 'learn' meaning based on order data, in the process 'learning' relationships with order (a kind of rudimentary working grammar). See for example latent semantic analysis
XML provides an elemental syntax for content structure within documents, yet associates no semantics with the meaning of the content contained within. XML is not at present a necessary component of Semantic Web technologies in most cases, as alternative syntaxes exists, such as Turtle. Turtle is a de facto standard, but has not been through a formal standardization process.
XML Schema is a language for providing and restricting the structure and content of elements contained within XML documents.
RDF is a simple language for expressing data models, which refer to objects ("resources") and their relationships. An RDF-based model can be represented in XML syntax.
RDF Schema extends RDF and is a vocabulary for describing properties and classes of RDF-based resources, with semantics for generalized-hierarchies of such properties and classes.
OWL adds more vocabulary for describing properties and classes: among others, relations between classes (e.g. disjointness), cardinality (e.g. "exactly one"), equality, richer typing of properties, characteristics of properties (e.g. symmetry), and enumerated classes.
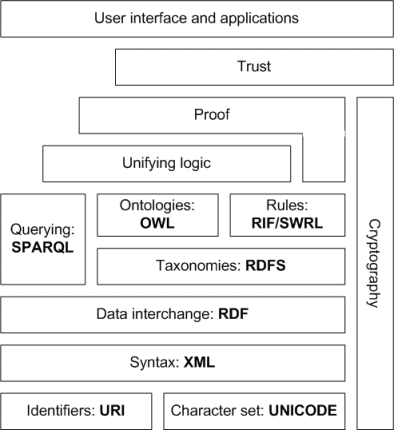
SPARQL is a protocol and query language for semantic web data sources.
Unifying Logic and Proof layers are undergoing active research.
The intent is to enhance the usability and usefulness of the Web and its interconnected resources through:
Servers which expose existing data systems using the RDF and SPARQL standards. Many converters to RDF exist from different applications. Relational databases are an important source. The semantic web server attaches to the existing system without affecting its operation.
Documents "marked up" with semantic information (an extension of the HTML <meta>tags used in today's Web pages to supply information for Web search engines using web crawlers). This could be machine-understandable information about the human-understandable content of the document (such as the creator, title, description, etc., of the document) or it could be purely metadata representing a set of facts (such as resources and services elsewhere in the site). (Note that anything that can be identified with a Uniform Resource Identifier (URI) can be described, so the semantic web can reason about animals, people, places, ideas, etc.) Semantic markup is often generated automatically, rather than manually.
Common metadata vocabularies (ontologies) and maps between vocabularies that allow document creators to know how to mark up their documents so that agents can use the information in the supplied metadata (so that Author in the sense of 'the Author of the page' won't be confused with Author in the sense of a book that is the subject of a book review).
Automated agents to perform tasks for users of the semantic web using this data
Web-based services (often with agents of their own) to supply information specifically to agents (for example, a Trust service that an agent could ask if some online store has a history of poor service or spamming)
Challenges
Some of the challenges for the Semantic Web include vastness, vagueness, uncertainty, inconsistency, and deceit. Automated reasoning systems will have to deal with all of these issues in order to deliver on the promise of the Semantic Web.
Vastness: The World Wide Web contains at least 24 billion pages as of this writing (June 13, 2010). The SNOMED CT medical terminology ontology contains 370,000 class names, and existing technology has not yet been able to eliminate all semantically duplicated terms. Any automated reasoning system will have to deal with truly huge inputs.
Vagueness: These are imprecise concepts like "young" or "tall". This arises from the vagueness of user queries, of concepts represented by content providers, of matching query terms to provider terms and of trying to combine different knowledge bases with overlapping but subtly different concepts. Fuzzy logic is the most common technique for dealing with vagueness.
Uncertainty: These are precise concepts with uncertain values. For example, a patient might present a set of symptoms which correspond to a number of different distinct diagnoses each with a different probability. Probabilistic reasoning techniques are generally employed to address uncertainty.
Inconsistency: These are logical contradictions which will inevitably arise during the development of large ontologies, and when ontologies from separate sources are combined. Deductive reasoning fails catastrophically when faced with inconsistency, because "anything follows from a contradiction". Defeasible reasoning and paraconsistent reasoning are two techniques which can be employed to deal with inconsistency.
Deceit: This is when the producer of the information is intentionally misleading the consumer of the information. Cryptography techniques are currently utilized to alleviate this threat.
This list of challenges is illustrative rather than exhaustive, and it focuses on the challenges to the "unifying logic" and "proof" layers of the Semantic Web. The World Wide Web Consortium (W3C) Incubator Group for Uncertainty Reasoning for the World Wide Web (URW3-XG) final report lumps these problems together under the single heading of "uncertainty". Many of the techniques mentioned here will require extensions to the Web Ontology Language (OWL) for example to annotate conditional probabilities. This is an area of active research.[22]
This section lists some of the many projects and tools that exist to create Semantic Web solutions.[23]
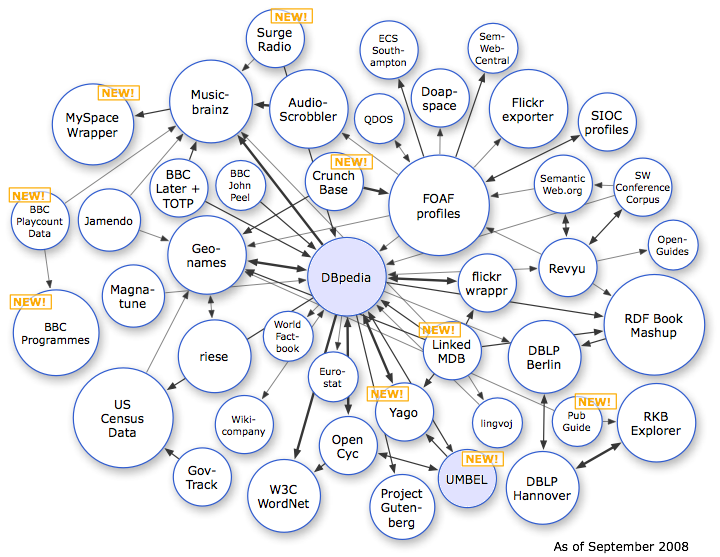
DBpedia
DBpedia is an effort to publish structured data extracted from Wikipedia: the data is published in RDF and made available on the Web for use under the GNU Free Documentation License, thus allowing Semantic Web agents to provide inferencing and advanced querying over the Wikipedia-derived dataset and facilitating interlinking, re-use and extension in other data-sources.
FOAF
A popular application of the semantic web is Friend of a Friend (or FoaF), which uses RDF to describe the relationships people have to other people and the "things" around them. FOAF permits intelligent agents to make sense of the thousands of connections people have with each other, their jobs and the items important to their lives; connections that may or may not be enumerated in searches using traditional web search engines. Because the connections are so vast in number, human interpretation of the information may not be the best way of analyzing them.
FOAF is an example of how the Semantic Web attempts to make use of the relationships within a social context.
GoodRelations for e-commerce
A huge potential for Semantic Web technologies lies in adding data structure and typed links to the vast amount of offer data, product model features, and tendering / request for quotation data.
The GoodRelations ontology[24][25][26] is a popular vocabulary for expressing product information, prices, payment options, etc. It also allows expressing demand in a straightforward fashion.
GoodRelations has been adopted by Google, BestBuy, Overstock, Yahoo, OpenLink Software, O'Reilly Media, the Book Mashup, and many others.
SIOC
The Semantically-Interlinked Online Communities project (SIOC, pronounced "shock") provides a vocabulary of terms and relationships that model web data spaces. Examples of such data spaces include, among others: discussion forums, blogs, blogrolls / feed subscriptions, mailing lists, shared bookmarks and image galleries.
SIMILE
Semantic Interoperability of Metadata and Information in unLike Environments
SIMILE is a joint project, conducted by the MIT Libraries and MIT CSAIL, which seeks to enhance interoperability among digital assets, schemata/vocabularies/ontologies, meta data, and services.
Quertle
Finding relevant information in the biomedical literature is critical to the advancement of medicine, life sciences, and chemical sciences. With more than 20 million documents and over one million new documents being added every year, finding what is relevant is extremely difficult using traditional search methods.[27]Quertle is search engine of the biomedical and life science literature that matches a user's search against a metadatabase of subject-verb-object relationships extracted from the literature. Additional semantic methods are used to automatically identify key concepts for drilling down.
NextBio
A database consolidating high-throughput life sciences experimental data tagged and connected via biomedical ontologies. Nextbio is accessible via a search engine interface. Researchers can contribute their findings for incorporation to the database. The database currently supports gene or protein expression data and is steadily expanding to support other biological data types.
Class linkages within the Linking Open Data datasets
The Linking Open Data project is a W3C-led effort to create openly accessible, and interlinked, RDF Data on the Web. The data in question takes the form of RDF Data Sets drawn from a broad collection of data sources. There is a focus on the Linked Data style of publishing RDF on the Web.
^Gerber, AJ, Barnard, A & Van der Merwe, Alta (2006), A Semantic Web Status Model, Integrated Design & Process Technology, Special Issue: IDPT 2006
^Gerber, Aurona; Van der Merwe, Alta; Barnard, Andries; (2008), A Functional Semantic Web architecture, European Semantic Web Conference 2008, ESWC’08, Tenerife, June 2008.
^Steve Spalding (July 14, 2007). "How To Define Web 3.0". howtosplitanatom.com. Retrieved November 14, 2010.
^Artem Chebotko and Shiyong Lu, "Querying the Semantic Web: An Efficient Approach Using Relational Databases", LAP Lambert Academic Publishing, ISBN 978-3-8383-0264-5, 2009.
^Gärdenfors, Peter (2004). How to make the Semantic Web more semantic. IOS Press. pp. 17–34. {{cite book}}: |work= ignored (help)





{kind=link}
{kind=link}
 Wikimedia Commons has media related to Semantic Web.
Wikimedia Commons has media related to Semantic Web.