
Fam158a
| EMC9 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Identifiers | |||||||||||||||||||||||||||||||||||||||||||||||||||
| Aliases | EMC9, C14orf122, FAM158A, CGI-112, Fam158a, ER membrane protein complex subunit 9 | ||||||||||||||||||||||||||||||||||||||||||||||||||
| External IDs | MGI: 1934682; HomoloGene: 41095; GeneCards: EMC9; OMA:EMC9 - orthologs | ||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| Wikidata | |||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||




UPF0172 protein FAM158A, also known as c14orf122 or CGI112, is a protein that in humans is encoded by the FAM158A gene located on chromosome 14q11.2.[5][6]
Human FAM158A and its paralogs in other species are part of the uncharacterized protein family UPF0172 family, which is a subset of the JAB1/Mov34/MPN/PAD-1 ubiquitin protease protein family. The MPN superfamily contributes to ubiquitination and de-ubiquitination activity within the cell. The UPF0172 subset no longer has a functional ubiquitination domain and the function is uncharacterized.[7]
Gene
[edit]Fam158a is positioned between PSME1 (antisense) and PSME2 (sense).[8] RNF31 is upstream and antisense to Fam158a. DCAF11 and FITM1 are both upstream of PSME1 antisense to Fam158a. PSME1 is a subunit of the 11S regulator which is a part of the immunoproteasome responsible for cleaving MHC class I peptides.[9] PSME2 is another subunit of the 11S regulator[10] RNF31 encodes a protein which contains a ring finger motif found in several proteins which mediate protein-DNA and protein-protein interactions.[11] FITM1 is a protein involved in fat storage.[12] DCAF11 is a protein that is known to interact with COP9 and has several alternative transcripts.[13]
-
 Conceptual Translation of Fam158a annotated with predicted phosphorylation sites, exon boundaries, and conserved regions
Conceptual Translation of Fam158a annotated with predicted phosphorylation sites, exon boundaries, and conserved regions -
 Fam158a chromosomal location and neighboring genes
Fam158a chromosomal location and neighboring genes -
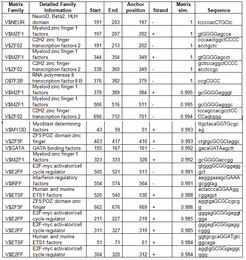 transcription factor binding sites in the promoter of Fam158a
transcription factor binding sites in the promoter of Fam158a



Promoter
[edit]The promoter is conserved as far back as Danio rerio. Softberry's FGenesH predicts two upstream promoters, a TATA Box 461bp upstream of the start site and another uncharacterized promoter 83bp upstream.[citation needed] Genomatix ElDorado predicts several transcription factor binding sites in the promoter region.[citation needed][14] found that Fam158a expression increases in GATA3 mutants, and as seen in the table, the Fam158a promoter region contains a Gata binding site. Another study shows FAM158A responds to Beta-catenin depletion.[15] Although there are no known beta-catenin binding sites in the promoter, there is a NeuroD site and NeuroD responds to beta-catenin.
Homology
[edit]



Paralogs
[edit]| Name | Species | Species Common Name | NCBI Accession Number | length | Protein Identity |
|---|---|---|---|---|---|
| Fam158a | Homo sapiens | Human | NP_057133.2 | 208aa | 100% |
| Cox4NB | Homo sapiens | Human | O43402.1 | 210aa | 41.6% |
The paralog to FAM158A is commonly known as Cox4NB and is located at 16q24.[16] It is also referred to as Cox4AL, Noc4, and Fam158b. The paralog partially overlaps COX4I1 and has two isoforms. Isoform 1 is the complete isoform at 210 amino acids while isoform 2 is 126 amino acids.[17] Like Fam158a, Cox4NB is highly conserved in Eukaryotes from mammals to as far back as fish. Currently there is no known function of Cox4NB. In most fish and further back there is a single homolog, the predecessor to Cox4NB and Fam158a.
Homologs
[edit]| Species | Species common name | NCBI Accession Number (mRNA/Protein) | Length (bp/aa) | Protein Identity | mRNA Identity | Notes |
|---|---|---|---|---|---|---|
| Homo sapiens | Human | NM_16049.3 / NP_057133.2 | 896bp/208aa | 100% | 100% | |
| Pan troglodytes | Chimpanzee | XM_001167788.2 / XP_001167788.1 | 842bp/208aa | 99.5% | 98.7% | Identity based on SDSC alignment [18] |
| Mus musculus | Mouse | NM_033146.1[permanent dead link] / NP_149158.1 | 805bp/206aa | 90.4% | 77.7% | |
| Xenopus (Silurona) tropicalis | Western Clawed Frog | XM_002939019.1 / XP_002939065.1 | 1182bp/205aa | 49.8% | 40.4% | |
| 'Xenopus laevis | African Clawed Frog | NM_001096278.1/ NP_001089747.1 | 750bp/206aa | 49.8% | 51.9% | mRNA missing 5' UTR |
| Danio rerio | Zebrafish | NM_200126.1 / NP_956420.1 | 962bp/205aa | 51.4% | 46.3% | |
| Bombus impatiens | Eastern Bumble Bee | XM_003489887.1 / XP_003489935.1 | 846bp/207aa | 35.8% | 41.1% | mRNA missing 5' UTR |
| Volvox carteri f. nagariensis | Green Algae | XM_002953071.1 / XP_002953117.1 | 1677bp/222aa | 29.3% | 34.8% | |
| Salicornia bigelovii | Dwarf Saltwort | DQ444286.1 / ABD97881.1 | 870bp/198aa | 31.3% | 47.5% | |
| Arabidopsis thaliana | Thale cress | NM_124976.3 / NP_568832.1 | 1039bp/208aa | 29.1% | 44.7% | |
| Physcomitrella patens patens | Moss | XM_001763974 / XP_001764026.1 | 609bp/202aa | 30.9% | 49.2% | mRNA missing 5' UTR |
| Serpula lacrymans S7.3 | Basidiomycetes type yeast- no common name | GL945481.1 / EGN98368.1 | 203aa | 30.3% | mRNA shotgun sequence, no mRNA information | |
| Capsaspora owczarzaki | a protist- no common name | GG697244.1 / EFW44366.1 | 202aa | 31.2% | mRNA shotgun sequence, no mRNA information | |
| Plasmodium knowlesi Strain H | Plasmodium, malaria causing, no common name | XM_002259366.1 / XP_002259402.1 | 609bp/202aa | 24.7% | 45.9% | mRNA missing 5' UTR |
As shown in the alignment, the protein is highly conserved chemically, although the exact sequence varies. There are also several regions of high conservation (highlighted by the red boxes). The degree of conservation follows the expected evolutionary pattern. The graph demonstrates this by plotting each species protein similarity to the human protein vs. the time since the species shared a common ancestor. The unrooted phylogenetic tree also demonstrates this relationship.
Protein
[edit]Fam158a has an isoelectric point of 5.5[19] and a molecular weight of 23 kilodaltons.[20] Fam158a does not have any predicted signal peptides or transmembrane regions. There are several predicted phosphorylation sites.[21][22] marked in the conceptual translation as well as the predicted secondary structure.[23] There are no regions significantly different from other human proteins with regard to composition, regions of polarity, or regions of hydrophobicity. iPsortII predicts no signal peptides and localizes Fam158a to the cytoplasm-[24] I-Tasser[25] predicts several structures for Fam158a and the best prediction is shown. Swiss Model[26] predicts two potential protein structures, as seen in the images. The first structure predicts the protein forms a protein dimer, the second as a monomer. Rual et al.[27] found that Fam158a interacts with a protein called TTC35. The function of TTC35 is unknown but it is also known to interact with Cox4NB and Ubiquitin C.
-
 Predicted Protein Structures using SwissModel
Predicted Protein Structures using SwissModel -
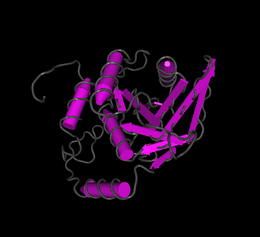 Predicted Fam158a structure from I Tasser
Predicted Fam158a structure from I Tasser


Function
[edit]Fam158a is nearly ubiquitously expressed throughout the human body.[28] The homolog in mice also shows expression throughout the entire body.[29] Several micro-arrays demonstrate the variable expression of Fam158a in response to other factors and in various cancer types. None of this information gives any indication of a specific function but the wide expression of the gene and its high conservation indicate that Fam158a plays an important role in cellular function.
Clinical significance
[edit]There are several diseases associated with deletions of 14q11.2, but none have been linked specifically to Fam158a. T-Lymphocytic Leukemia with or without ataxia telangiectasia has been associated with inversions and tandem translocations of 14q11 and 14q32 and other chromosomes.[30] Also, syndactyly type 2 has been isolated to 14q11.2-12.[31] This form of syndactyly is characterized by fusion of the third and fourth digits of the hand and the fourth and fifth digits of the foot in addition to other fusions and malformations.
References
[edit]- ^ a b c ENSG00000285377 GRCh38: Ensembl release 89: ENSG00000100908, ENSG00000285377 – Ensembl, May 2017
- ^ a b c GRCm38: Ensembl release 89: ENSMUSG00000022217 – Ensembl, May 2017
- ^ "Human PubMed Reference:". National Center for Biotechnology Information, U.S. National Library of Medicine.
- ^ "Mouse PubMed Reference:". National Center for Biotechnology Information, U.S. National Library of Medicine.
- ^ GeneCard for fam158a
- ^ HomoloGene: 41095
- ^ "NCBI CDD cd08060". Conserved Domain Database. National Center for Biotechnology Information.Marchler-Bauer A, Anderson JB, Chitsaz F, Derbyshire MK, DeWeese-Scott C, Fong JH, Geer LY, Geer RC, Gonzales NR, Gwadz M, He S, Hurwitz DI, Jackson JD, Ke Z, Lanczycki CJ, Liebert CA, Liu C, Lu F, Lu S, Marchler GH, Mullokandov M, Song JS, Tasneem A, Thanki N, Yamashita RA, Zhang D, Zhang N, Bryant SH (January 2009). "CDD: specific functional annotation with the Conserved Domain Database". Nucleic Acids Res. 37 (Database issue): D205–10. doi:10.1093/nar/gkn845. PMC 2686570. PMID 18984618.
- ^ EntrezGene 51016
- ^ EntrezGene 5720
- ^ EntrezGene 5721
- ^ EntrezGene 55072
- ^ EntrezGene 161247
- ^ EntrezGene 80344
- ^ Usary J, Llaca V, Karaca G, Presswala S, Karaca M, He X, Langerød A, Kåresen R, Oh DS, Dressler LG, Lønning PE, Strausberg RL, Chanock S, Børresen-Dale AL, Perou CM (October 2004). "Mutation of GATA3 in human breast tumors". Oncogene. 23 (46): 7669–78. doi:10.1038/sj.onc.1207966. PMID 15361840. S2CID 23108934.
- ^ Dutta-Simmons J, Zhang Y, Gorgun G, Gatt M, Mani M, Hideshima T, Takada K, Carlson NE, Carrasco DE, Tai YT, Raje N, Letai AG, Anderson KC, Carrasco DR (September 2009). "Aurora kinase A is a target of Wnt/beta-catenin involved in multiple myeloma disease progression". Blood. 114 (13): 2699–708. doi:10.1182/blood-2008-12-194290. PMID 19652203.
- ^ Bachman NJ, Wu W, Schmidt TR, Grossman LI, Lomax MI (May 1999). "The 5' region of the COX4 gene contains a novel overlapping gene, NOC4" (PDF). Mamm. Genome. 10 (5): 506–12. doi:10.1007/s003359901031. hdl:2027.42/42117. PMID 10337626. S2CID 8776340.
- ^ NCBI (24 June 2018). "Homo sapiens COX4 neighbor (COX4NB), transcript variant 1, mRNA - Nucleotide". NCBI Reference Sequence: NM_006067.4. National Center for Biotechnology Information.
- ^ Thompson JD, Higgins DG, Gibson TJ (November 1994). "CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice". Nucleic Acids Res. 22 (22): 4673–80. doi:10.1093/nar/22.22.4673. PMC 308517. PMID 7984417.
- ^ Toldo L, Kindler B. "EMBL WWW Gateway to Isoelectric Point Service". EMBL Heidelberg. Archived from the original on 2012-02-12. Retrieved 2012-05-09.
- ^ Brendel V, Bucher P, Nourbakhsh IR, Blaisdell BE, Karlin S (March 1992). "Methods and algorithms for statistical analysis of protein sequences". Proc. Natl. Acad. Sci. U.S.A. 89 (6): 2002–6. Bibcode:1992PNAS...89.2002B. doi:10.1073/pnas.89.6.2002. PMC 48584. PMID 1549558.
- ^ Blom N, Gammeltoft S, Brunak S (December 1999). "Sequence and structure-based prediction of eukaryotic protein phosphorylation sites". J. Mol. Biol. 294 (5): 1351–62. doi:10.1006/jmbi.1999.3310. PMID 10600390.
- ^ Blom N, Sicheritz-Pontén T, Gupta R, Gammeltoft S, Brunak S (June 2004). "Prediction of post-translational glycosylation and phosphorylation of proteins from the amino acid sequence". Proteomics. 4 (6): 1633–49. doi:10.1002/pmic.200300771. PMID 15174133. S2CID 18810164.
- ^ Qian N, Sejnowski TJ (August 1988). "Predicting the secondary structure of globular proteins using neural network models". J. Mol. Biol. 202 (4): 865–84. doi:10.1016/0022-2836(88)90564-5. PMID 3172241.
Joint prediction - Prediction made by the program that assigns the structure using a "winner takes all" procedure for each amino acid prediction using the other methods
- ^ Bannai H, Tamada Y, Maruyama O, Nakai K, Miyano S (February 2002). "Extensive feature detection of N-terminal protein sorting signals". Bioinformatics. 18 (2): 298–305. doi:10.1093/bioinformatics/18.2.298. PMID 11847077.
- ^ Ambrish Roy, Alper Kucukural, Yang Zhang. I-TASSER: a unified platform for automated protein structure and function prediction. Nature Protocols, vol 5, 725-738 (2010)
- ^ Arnold K, Bordoli L, Kopp J, Schwede T (January 2006). "The SWISS-MODEL workspace: a web-based environment for protein structure homology modelling". Bioinformatics. 22 (2): 195–201. doi:10.1093/bioinformatics/bti770. PMID 16301204.
- ^ Rual JF, Venkatesan K, Hao T, Hirozane-Kishikawa T, Dricot A, Li N, Berriz GF, Gibbons FD, Dreze M, Ayivi-Guedehoussou N, Klitgord N, Simon C, Boxem M, Milstein S, Rosenberg J, Goldberg DS, Zhang LV, Wong SL, Franklin G, Li S, Albala JS, Lim J, Fraughton C, Llamosas E, Cevik S, Bex C, Lamesch P, Sikorski RS, Vandenhaute J, Zoghbi HY, Smolyar A, Bosak S, Sequerra R, Doucette-Stamm L, Cusick ME, Hill DE, Roth FP, Vidal M (October 2005). "Towards a proteome-scale map of the human protein-protein interaction network". Nature. 437 (7062): 1173–8. Bibcode:2005Natur.437.1173R. doi:10.1038/nature04209. PMID 16189514. S2CID 4427026.
- ^ "EST Profile - Hs.271614". EST Profile Viewer. National Center for Biotechnology Information (NCBI).
- ^ "GENEPAINT Set ID: EH1992". GenePaint.org.
digital atlas of gene expression patterns in the mouse
[permanent dead link] - ^ Brito-Babapulle V, Catovsky D (August 1991). "Inversions and tandem translocations involving chromosome 14q11 and 14q32 in T-prolymphocytic leukemia and T-cell leukemias in patients with ataxia telangiectasia". Cancer Genet. Cytogenet. 55 (1): 1–9. doi:10.1016/0165-4608(91)90228-M. PMID 1913594.
- ^ Malik S, Abbasi AA, Ansar M, Ahmad W, Koch MC, Grzeschik KH (June 2006). "Genetic heterogeneity of synpolydactyly: a novel locus SPD3 maps to chromosome 14q11.2-q12". Clin. Genet. 69 (6): 518–24. doi:10.1111/j.1399-0004.2006.00620.x. PMID 16712704. S2CID 10887786.