
User talk:Qwfp

Tea bag userbox
what's so bad about milk in with the tea bag? Does that mean something about the order of adding or about the final product? Pdbailey (talk) 05:20, 16 January 2008 (UTC)
- Thanks for starting off my Talk page with a friendly question! It feels like a gut reaction, but after a bit of thinking and research (or rather googling - follow links from the first hit for "milk in with the tea bag") i think there are good reasons behind it (I didn't design that userbox by the way and i've no idea who did):
- If you put the milk in with the tea bag before the water, the watery mixture isn't hot enough to brew the tea properly, as the tea should brew in freshly boiled water.
- If you put the milk in straight after the boiling water, then not only does it reduce the temperature too soon and stop the tea brewing properly, but it also "scalds" the milk and affects the taste of it (makes it taste like UHT milk - yuck. In countries where UHT milk is the only milk you can get, it's not going to make any difference of course.). Apparently, more scientifically it denatures the protein in the milk, according to the BBC news page on how to make a perfect cuppa.
- So the best way to make tea in a cup/mug with a tea bag is to pour freshly boiled water on the tea bag, leave it to brew for a few seconds up to a minute or so (very much dependent on how strong you like your tea) while stirring occasionally (mainly to pass the time) until it's the colour/strength you like, take the tea bag out, then pour in milk to taste (just a splash in my case).
- Why add milk at all? An old friend told me that the milk protein binds to the tannin in the tea and reduces the astringency (as this is just my talk page, for once i'm going to resist the temptation to try to find a reference to verify that..)
- You should really make tea in a pot of course, but often that's just a bit too much hassle.
- Qwfp (talk) 13:14, 16 January 2008 (UTC)
Good Work
Kudos for fleshing out some stat modeling articles, generalized linear model in particular. Baccyak4H (Yak!) 14:49, 23 January 2008 (UTC)
- Thanks! I guess it's time i came out of hiding and added Category:Wikipedian statisticians to my user page. Qwfp (talk) 16:14, 23 January 2008 (UTC)
Reverting Edits
Do not revert edits; when you do not know why you are doing it, anti-free will; as you did with Kate Bush, info came from her own video biog, for, Sensual World.-{This Wikipedia thing; is now becoming a mental health issue, for a lot of people, may I suggest; see a doctor}. Your problem, Group Paranoid Delusive Dynamic, or, Group-MSbP. Russpear (talk) 18:22, 2 October 2008 (UTC)
Logistic distribution

Hi, the recent edit you made to Logistic distribution has been reverted, as it appears to be unconstructive. Use the sandbox for testing; if you believe the edit was constructive, ensure that you provide an informative edit summary. You may also wish to read the introduction to editing. Thanks. Alexfusco5 22:13, 31 January 2008 (UTC)
- I said in the edit summary that i'd explain on the talk page and i'm about to submit that, give me a chance! Qwfp (talk) 22:18, 31 January 2008 (UTC)
Link to Roger Clemens Drug Testing article
Hello, you seem to have removed my links to the Roger Clemens Drug Testing article citing it as spam. The page that it is on has no products for sale, no plugs for any products, and is an unbiased review of the data behind Clemens and Bonds. Why would you remove the link? —Preceding unsigned comment added by FinnMan (talk • contribs) 18:18, 1 February 2008 (UTC)
- Please see the message I placed on your talk page. Wikipedia is not a collection of external links; see WP:EL and WP:NOT#LINK. The term "linkspam" is sometimes used in this context for the placing of links to one commercial website on multiple Wikipedia articles for the purpose of promoting a website or a product. After using this term in the edit summary I regretted it as you are a new editor and I cannot be sure of your intent, and wish I had simply referred to WP:EL. I apologise if I offended you. A single link to this article from the Roger Clemens page may be reasonable, but as indicated as WP:EL, "repeatedly adding links will in most cases result in all of them being removed".
- By the way, it's the custom to add new messages at the bottom of a user talk page rather than the top, so i've moved your comment down here. Regards, and welcome to Wikipedia, Qwfp (talk) 18:49, 1 February 2008 (UTC)
1.96
Axiomatic numbers in statistics
I tried searching for 1.9599639845401 in the OEIS, and, as you said, there were no results. I then tried 1.9599 and 1.95, getting slightly more results but none relevant to statistics. Lastly, I tried the words "confidence interval" and got two results, neither relevant to the one you mentioned. What would be the landmark statistics textbook or journal article that gives this number with any degree of precision? CompositeFan (talk) 15:43, 1 February 2008 (UTC)
- I guess the classic text would have to be Ronald Fisher's Statistical Methods for Research Workers (1925). Table 1 gives 1.959964. I think this is the earliest publication giving this number to any precision but I wouldn't bet my life on it.
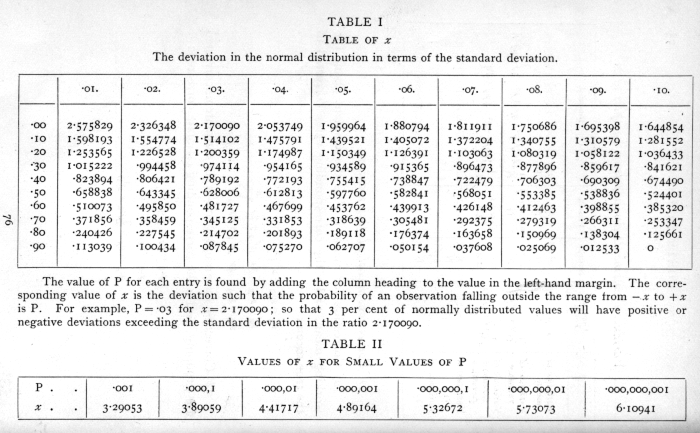{kind=link}
- For more precision, googling various truncations of the number above lead me to a 1970 publication containing these 20 decimal places:
- 1.95996398454005423552
- "The results were reduced to 20 DP (in general 21 significant figures) by truncation rather than rounding; i.e., the 20th decimal place is exact but the missing 21st decimal digit might be 5 or greater."
- White, John S. (1970), "Tables of Normal Percentile Points", Journal of the American Statistical Association, 65 (330): 635–638
{{citation}}: Unknown parameter|month=ignored (help)
- Of course 1.96 is quite accurate enough for all common statistical purposes (in fact 2 is probably accurate enough for most purposes).
- Hmm, having spent a bit of time on that research, i'm tempted to go ahead and create 1.96.--Qwfp (talk) 17:22, 1 February 2008 (UTC)
Proposed deletion of 1.96

Another editor has added the "{{prod}}" template to the article 1.96, suggesting that it be deleted according to the proposed deletion process. All contributions are appreciated, but the editor doesn't believe it satisfies Wikipedia's criteria for inclusion, and has explained why in the article (see also Wikipedia:What Wikipedia is not and Wikipedia:Notability). Please either work to improve the article if the topic is worthy of inclusion in Wikipedia or discuss the relevant issues at its talk page. If you remove the {{prod}} template, the article will not be deleted, but note that it may still be sent to Wikipedia:Articles for deletion, where it may be deleted if consensus to delete is reached. BJBot (talk) 10:14, 2 February 2008 (UTC)
AfD nomination of 1.96

An article that you have been involved in editing, 1.96, has been listed for deletion. If you are interested in the deletion discussion, please participate by adding your comments at Wikipedia:Articles for deletion/1.96. Thank you. — Arthur Rubin | (talk) 15:36, 2 February 2008 (UTC)
Epilogue
Well, that was an interesting experience. The result was keep, but as I indicated at the end of the discussion, I plan to turn 1.96 into a redirect to normal distribution#Standard deviation and confidence interval and incorporate some of the content into there and/or confidence interval. --Qwfp (talk) 22:23, 8 February 2008 (UTC)
Impressed by your unbelievably diplomatic post to User:Johnbibby on this topic. Good to know you are a statistician available to help out with some of our articles. EdJohnston (talk) 19:20, 11 February 2008 (UTC)
Rollback
Hello Qwfp, I noticed you revert vandalism, occasionally, but correctly. I was wondering, would you like rollback rights granted to your account? Rollback is a vandalism-reversion feature, and it's quicker at reverting than any other type of reversion tool. Acalamari 00:04, 23 February 2008 (UTC)
- Hi Acalamari, Yes, I'd like to take you up on your kind offer, thanks. Sometimes I use popups to revert vandalism but it sounds like official rollback would be quicker and cleaner. Qwfp (talk) 10:08, 23 February 2008 (UTC)
- Rollback granted. :) For practice and additional information on rollback, you may want to see Wikipedia:New admin school/Rollback. Good luck. Acalamari 18:12, 23 February 2008 (UTC)
confidence interval
I would argue the that the claims in the section on the interpretation of confidence intervals are controversial and, in fact, are contrary to the concensus among professional statisticians. If you compute a 90% CI for the mass of an object based on several observations (each with their own error), you are saying that the probability that the true mass is within the stated interval is 90%. This can even be experimentally verified. Suppose we randomly sample a large population with a known mean 30 times and we compute the 90% CI. We repeat this until we have a large number of 90% CI's. We will find that the known mean of the population falls within 90% of the computed 90% CI's. The error in the section is to claim that P(a<x<b) is not really a probability because x is not random. But a and b are random by virtue of the fact that they were computed from random samples. I have a large number of stats texts in my bookshelves, I'm a statistician myself, and I'm published in this area. Every text I have discusses P(a<x<b) as an honest-to-goodness probability without any discusson of this alleged "misinterpretation". The section produces neither a mathematical proof for this position nor experimental evidence (which would contradict it). It is merely a philosophical position and one which has no bearing on observable outcomes (as my experiment would show). I see you are a statistician, too, so I would like to see any citations that support this claim. And if the content of the citation is merely itself a philisophical position - not a mathematical proof - then section should make that clear. Hubbardaie (talk) 16:50, 28 February 2008 (UTC)
- Would you have any objection to me moving the above to Talk:confidence interval, which is where I suggested discussing this? User:Melcombe has started a discussion over there about your edits. Or would you prefer to answer there directly? Thanks, Qwfp (talk) 16:58, 28 February 2008 (UTC)
- You are right, we should move this discussion over there. I've made similar comments a while back on that page.Hubbardaie (talk) 17:13, 28 February 2008 (UTC)
- can i take you literally on that and copy&paste some of the above and some of my first comment from your talk page? In retrospect I should have started the substantive part of my argument on Talk:confidence interval in the first place and referred there. Feel free to edit the paste of your comment there before it's replied to. Sorry I didn't notice that you'd commented previously on Talk:confidence interval - i'm sure i've read the whole of that in the past but without paying too much attention to names. I'll reread it now. Qwfp (talk) 17:20, 28 February 2008 (UTC)
Re: Username block
I'm just curious why you blocked User talk:Blahblahblah4536. It doesn't matter to me either way, but I can't myself see how this name contravenes the username policy. Feel free to ignore this is you're busy with more important things (as I should be myself really). Qwfp (talk) 17:34, 28 February 2008 (UTC)
- Quite borderline. In my opinion, he looks to be a sockpuppet of Scott4545 (talk · contribs · deleted contribs · logs · filter log · block user · block log). Rudget. 17:36, 28 February 2008 (UTC)
- Thanks for replying and satisfying my curiousity. Evidence for or against sockpuppetry is not something i've ever looked into and I wouldn't know where to start so I'll leave it there (you know what curiousity did to the cat...). Qwfp (talk) 17:53, 28 February 2008 (UTC)
- I can give you a hand if you like. Rudget. 17:58, 28 February 2008 (UTC)
- Thanks for the offer but I'm happy leaving such matters to admins. Actually I just clicked on those userlinks and quickly started to see... but that really is as far as I want to go. I've been patrolling new pages a bit, partly as I've recently been given rollback, and felt obliged to stick warnings on user pages at least some of the time, but the novelty is wearing off fast and my user page says, i've no wish to be an admin. I'm mainly here to try to improve content on statistics topics - so i'll get back to the debate on Talk:confidence interval now. Thanks again, Qwfp (talk) 18:12, 28 February 2008 (UTC)
- I can give you a hand if you like. Rudget. 17:58, 28 February 2008 (UTC)
- Thanks for replying and satisfying my curiousity. Evidence for or against sockpuppetry is not something i've ever looked into and I wouldn't know where to start so I'll leave it there (you know what curiousity did to the cat...). Qwfp (talk) 17:53, 28 February 2008 (UTC)
loglogistic
wow... you did a really great job with the article on the loglogistic distribution!!! congratulations! P--Philtime (talk) 20:46, 1 March 2008 (UTC)
- Thanks! I can be more than a bit of an obsessive perfectionist at times, and that was certainly one of them. But I learnt quite a lot in the process of writing that. Qwfp (talk) 23:42, 1 March 2008 (UTC)
Reverts and my talk
See my talk I have responded there to your puzzling question. -Justin (koavf)·T·C·M 01:06, 6 March 2008 (UTC)
- Good, good All's well then. Thanks for your vigilance, even if it was somewhat out-of-step with fact. -Justin (koavf)·T·C·M 17:28, 6 March 2008 (UTC)
Articles you might like to edit, from SuggestBot
SuggestBot predicts that you will enjoy editing some of these articles. Have fun!
SuggestBot picks articles in a number of ways based on other articles you've edited, including straight text similarity, following wikilinks, and matching your editing patterns against those of other Wikipedians. It tries to recommend only articles that other Wikipedians have marked as needing work. Your contributions make Wikipedia better -- thanks for helping.
If you have feedback on how to make SuggestBot better, please tell me on SuggestBot's talk page. Thanks from ForteTuba, SuggestBot's caretaker.
P.S. You received these suggestions because your name was listed on the SuggestBot request page. If this was in error, sorry about the confusion. -- SuggestBot (talk) 22:14, 11 March 2008 (UTC)
chi-square
Why would you want to merge chi-square test into Pearson's chi-square test? This seems to me like the exact opposite of what needs to be done: articles about the many many other chi-square tests besides Pearsons should be written and should be listed in the chi-square test article. Michael Hardy (talk) 19:00, 21 March 2008 (UTC)
- Well, for the reasons I explained at Talk:Chi-square test#Move Pearson's chi-square test to chi-square test?. I don't like having parallel discussions on the same subject so would you like to contribute to the discussion over there? Qwfp (talk) 20:10, 21 March 2008 (UTC)
Re: Weibull Distribution
The only changes I could see managed to break the template, there was not any addition of or other material. Thus it is difficult to understand how it could be an edit of good faith. It could have been a mistake or vandalism, difficult to determine as the edit was from an IP address. Noodle snacks (talk) 03:39, 29 March 2008 (UTC)
Commetns at WPM
Hi Qwfp, thank you for your comments at the Math project talk page. Unfortunately, no matter how long a wikibreak I will take, there is a near certainty that when I come back, MathSci will still be here, jealously guarding his "perfect" versions and attacking everyone who dares to come near. I was hoping that more mathematics editors would agree that his actions are highly inappropriate, but given the present state of affairs, permanent withdrawal seems like the best solution. Cheers, Arcfrk (talk) 08:22, 13 April 2008 (UTC)
I love what you have done to the nav box (Template talk:ProbDistributions) Aastrup (talk) 21:41, 16 April 2008 (UTC)
- Thanks! You might like to have a look at WikiProject Statistics, if you haven't already, and consider adding your name to the list of participants. Qwfp (talk) 05:45, 17 April 2008 (UTC)
could you please do me a favor?
Hello,
I am a master student at the Institute of Technology Management, National Tsing Hua University, Taiwan. Currently I am wrapping up my master thesis titled “Can Wikipedia be used for knowledge service?” In order to validate the knowledge evolution maps of identified users in Wikipedia, I need your help. I have generated a knowledge evolution map to denote your knowledge activities in Wikipedia according to your inputs including the creation and modification of contents in Wikipedia, and I need you to validate whether the generated knowledge evolution map matches the knowledge that you perceive you own it. Could you please do me a favor?
- I will send you a URL link to a webpage on which your knowledge evolution map displays. Please assign the topic (concept) in the map to a certain cluster on the map according to the relationship between the topic and clusters in your cognition, or you can assign it to ‘none of above’ if there is no suitable cluster.
- I will also send a questionnaire to you. The questions are related to my research topic, and I need your viewpoints about these questions.
The deadline of my thesis defense is set by the end of June, 2008. There is no much time left for me to wrap up the thesis. If you can help me, please reply this message. I will send you the URL link of the first part once I receive your response. The completion of my thesis heavily relies much on your generous help.
Sincerely
JnWtalk 07:35, 2 June 2008 (UTC)
Can you give me a hand?
Hi
- I noticed that you are a statistician and I wonder if you can help with a question I've. My question is what kind of statistical analysis I need to do if I want to compare an improvement under two different paradigms: I am running an experiment in which each observer is participating in two different conditions (paradigms). In each of the conditions observers have two different kinds of trials - in one they have a cue that should improve their accuracy rates (i.e., the dependent variable) and in the other they don't. I assume that in one of the conditions the cue will be more beneficial than in the other-and hence I want to compare these paradigms/conditions improvement rates. Now, comparing them by their Z scores is impossible because the STD of each observer is 0 as there are only two values that each trial in each paradigm can get ( 1 for correct answer and 0 for a wrong one, hence for each kind of trials (i.e., with or without cue) observers will have only one average-meaning their accuracy rates in it) - My English is still limited and I'm not sure that I made myself clear, but if you can help me with this, then I'll be grateful.
Regarsds--Lion210 (talk) 08:43, 1 August 2008 (UTC)
Sorry, but that has no connection to writing an encyclopedia. I'm not here to provide free statistical consultancy. Qwfp (talk) 14:17, 1 August 2008 (UTC) Ho, ok-sorry for asking. but problem was solved anyway my lovely man. —Preceding unsigned comment added by Lion210 (talk • contribs) 07:39, 4 August 2008 (UTC)
Stata versions history
Hey Qwfp, I like your edit on the Timeline of releases section. What I had put up there was way too long, especially for such a short article. And, considering STATA is pretty consistent in their 2-year major releases, people can do the math themselves if for whatever reason they want to estimate when, say, STATA 8.0 was released. You seem to like editing statistical pages so I have a question for you: why is MATLAB listed under the List of statistical packages but not the Comparison of statistical packages? In the discussion on statistical packages, someone posed the same question but I did not see a response. Thanks, PGScooter (talk) 03:15, 19 August 2008 (UTC)
- Thanks! I thought anyone wanting the complete timeline could always follow the link in the ref to the Stata website. Copying large parts of an external webpage into WP always strikes me as bad form, even if it's not strictly infringing anyone's copyright.
- Perhaps MATLAB isn't in comparison of statistical packages as it's a numerical computing environment with statistical features, rather than specifically a statistical package? Though the boundary between the two is clearly somewhat fuzzy. I've never used MATLAB so I know nothing about its statistical features myself. I notice there's no mention of statistics in the MATLAB entry. But it could be that it's not included simply because no-one's gone to the effort of including it. If you think it should be included and know enough about it then be bold! Qwfp (talk) 05:57, 19 August 2008 (UTC)
- MATLAB is pretty nice as far as statistics, just because it is so powerful with matrices so I feel you get a lot more control over what you're doing. However, I agree with your classification of MATLAB not as a statistical package. My main point was that MATLAB should either be included in both the List of statistical packages and Comparison of statistical packages or neither of them, but this is not the case. Likewise, I believe that Mathematica should not be included if MATLAB isn't (but it is!). I think a main question is whether the List of statistical packages should only include software whose dedicated purpose is to statistics, or all software that can be used for statistical analysis. I am going to add MATLAB and raise the question of dedicated statistical packages in the discussion, perhaps a solution would be to have a * next to the ones which are not only dedicated statistical packages. I am still getting to know my way around Wikipedia, and am also trying to figure out whether I do "know enough about" something or not, so I have indeed been a little hesitant, but I will start to become bolder :) PGScooter (talk) 20:19, 21 August 2008 (UTC)
Regarding the message you left on my talk page
Sorry, is this true? I thought this was vandalism - it certainly seemed like it
(please respond on my talk page.) —Preceding unsigned comment added by Fahadsadah (talk • contribs) 16:23, 4 September 2008 (UTC)
- Sorry about not signing it - I forgot. Anyway, I didn't notice that you beat me to reverting the vandalism - sorry Fahadsadah (talk) 15:47, 5 September 2008 (UTC)
Merging concern
Instead of merging, having a brief paragraph about the main article is better, because in the future, when the article gets expanded, it would simply be too much information in one place, and it should be divided into subcategories. Imagine what it would be like if someone tried to merge the article supercell into thunderstorm. That's the purpose that the {{mainarticle}} template serves. -- IRP ☎ 00:05, 8 October 2008 (UTC)
Sue Perkins
LDA
- Thank you for your work on LDA per WP:DAB & WP:MOSDAB. Originally I only wanted to add London Democratic Association but thought I should take the opportunity to put the entries into alphabetical order and add what links I could. GrahamSmith (talk) 21:40, 11 January 2009 (UTC)
Lucy Mangan
You appear to have changed the entry for Lucy Mangan to claim that Mick Mangan is her father. He is not. Please stop doing this. —Preceding unsigned comment added by 86.134.93.175 (talk) 00:10, 29 January 2009 (UTC)
- Many thanks for pointing that out. Please convey my apologies to Professor Mangan. I have now corrected the entry. Qwfp (talk) 20:47, 29 January 2009 (UTC)
use of Stata to produce Travel_time_histogram_total_n_Stata.png
{kind=link}
I have been trying to recreate using stata the histogram you posted on histogram -- without success. Would you be willing to share with me the Stata command that produced it? I want the ability to graph variable-width histograms for an unrelated application. Any help greatly appreciated! Openlander (talk) 22:57, 2 February 2009 (UTC)
- I usually put the code in the File page with the graph. Not sure why I didn't that time. Command was:
twoway bar freq interval , bartype(spanning) bstyle(histogram) scheme(lean1)
- Key is the undocumented bartype option, but also requires a bit of data-manipulation first (maybe that's why i didn't put the code on the File page). For (much) more info see Nick Cox. Speaking Stata: Graphing Distributions. Stata Journal 2004; 4(1):66-88. Qwfp (talk) 08:37, 3 February 2009 (UTC)
- thank you very much. great reference! Openlander (talk) 09:24, 6 February 2009 (UTC)
Ben Goldacre
Regarding the "MPhil vs MA in Philosophy" point - sorry about that, I hadn't seen the earlier discussion on the talk page (I'd asked a question later and nobody had answered it, and I see why now). It does seem likelier to me that he's got a research MPhil in something like psychology or neurology rather than a master's degree actually in philosophy - the latter would seem an unusual detour for someone otherwise following a medical career path. Also, "Master's degree in Philosophy" is the sort of ambiguous wording that tends to turn up in biographies provided by agents. On the other hand, maybe he did do an MA in philosophy - I can believe there are some interesting overlaps between cognitive neuroscience and the philosophy of the mind. I'll hunt around and see if I can find anything out, anyway. -- Nicholas Jackson (talk) 11:07, 8 February 2009 (UTC)