
Wikipedia:Reference desk/Computing
![]()
of the Wikipedia reference desk.
Main page: Help searching Wikipedia
How can I get my question answered?
- Select the section of the desk that best fits the general topic of your question (see the navigation column to the right).
- Post your question to only one section, providing a short header that gives the topic of your question.
- Type '~~~~' (that is, four tilde characters) at the end – this signs and dates your contribution so we know who wrote what and when.
- Don't post personal contact information – it will be removed. Any answers will be provided here.
- Please be as specific as possible, and include all relevant context – the usefulness of answers may depend on the context.
- Note:
- We don't answer (and may remove) questions that require medical diagnosis or legal advice.
- We don't answer requests for opinions, predictions or debate.
- We don't do your homework for you, though we'll help you past the stuck point.
- We don't conduct original research or provide a free source of ideas, but we'll help you find information you need.
How do I answer a question?
Main page: Wikipedia:Reference desk/Guidelines
- The best answers address the question directly, and back up facts with wikilinks and links to sources. Do not edit others' comments and do not give any medical or legal advice.
December 4
Software tool for a paywall
What software tool can be used for implementing a paywall for online content (articles)? One with membership management, query limits for each member, and so on. I don't want just one of those "soft" paywall that news sites implement since a while ago. Those can easily be circumvented. --3dcaddy (talk) 01:16, 4 December 2015 (UTC)
- You probably want to look at something like a content management system (commonly referred to by its initialism, CMS). --71.119.131.184 (talk) 04:12, 4 December 2015 (UTC)
- 3dcaddy I'm not sure you need a full blown content management system. Those tools are more for large sites that are being edited by many different people in parallel. It sounds like what you have is a smaller site with content from yourself and a few others. If that is the case most blog tools have options for putting content behind a paywall. I would look at Blogger which is now owned by Google: https://www.blogger.com or Wordpress: https://wordpress.com/ I've never set up a paywall with either tool but I know they both have widgets for credit card payments and also that you can control who can see what content so I think there is a good chance those could do what you want. Just my 2 cents: setting up a paywall is going to be a tough way to make money in most cases. We Internet users are just too spoiled by free content. I know once I hit a paywall I just try to find the info in another way. But of course it all depends on what the content is and who the audience is. Another option is to provide the content for free but include ads on the blog and make money that way. Of course that can always be short circuited by people like me who use Adblock Plus but surprisingly a lot of people don't know about it and ads still work to generate revenue. I know that Blogger provides ways to allow and get money from ads and I'm pretty sure wordpress does as well. Also, if you want a more general purpose tool you might want to check out Google Sites. They also have a credit card widget and could probably implement a paywall. Oh, one other tool I just found but I like a lot is something called Wix: https://www.wix.com I like this tool a LOT. They have templates that just IMO blow away what Google sites or those blogger tools have. The template I'm using is for a cleaning business so I don't know if they have something for what you want to do but I would definitely check them out. The only annoying thing is that they put a small ad for their site at the bottom of your home page. But its not too intrusive and you can get rid of it for a very small upgrade fee (about $12 a month which also gets you other benefits) and IMO its definitely worth it considering how professional their templates look compared to the competition. Hope that was helpful. Good luck. --MadScientistX11 (talk) 14:42, 4 December 2015 (UTC)
- I'd say look for plug-ins, but do not steer clear from CMSs. Drupal at least is very light-weight and easy to manage. It almost sure has a paywall plug-in. Drupal is also offered by several hosting services, and can be installed easily.--Denidi (talk) 19:09, 4 December 2015 (UTC)
MATLAB multicore CPU usage
Hi, I'm running some simulations in MATLAB (R2012a, 64 bit) on a 4-core CPU in OSX. Today I noticed that the process sometimes is listed at 101-105% CPU usage. Some quick googling suggests that is relative to cores, and that processes taking over 100% is not uncommon. My question, then is: how can I let Matlab use more CPU resources? If my understanding based on the above is correct, then I should be able to have all processes sum to ~400% CPU usage, yet for some reason, even when seemingly CPU-limited, Matlab never takes more than 105%, and the total for all processes seems to never go over ~110%. I'll also add that the process does not seem to be memory limited (using ~10Gb, >1Gb free), and not disk limited (disk read/writes are very low for most of the runtime) Thanks, SemanticMantis (talk) 16:32, 4 December 2015 (UTC)
- Some common linear algebra operations built into MATLAB are already multithreaded. If you are writing your own algorithms, MATLAB provides a threading model called "MATLAB Workers." To get started, read the resources at MATLAB Multicore, from Mathworks.
- It has been my experience that most MATLAB programmers write their algorithms as a giant "for loop." This design paradigm lends itself to serial processing - so you won't be able to "magically" use four cores to run an algorithm that you wrote as a loop. (Fundamentally, this paradigm commands one processor to execute and iterate one sequence of operations - the programmer is not explicitly expressing parallelism when writing code in this fashion). However, the fine engineers at Mathworks also noticed this design-trend, so they created "parfor" - the parallelizable for-loop - explained at the Introduction to Parallel Solutions. You'll have to rewrite and/or redesign some code - but it's designed to be less difficult to refactor your existing algorithm in this fashion, rather than switching to a true multi-threaded algorithm. (Note that the example for-loop they provide has no data-dependence and is really a trivial case where substituting the "parfor" keyword caused your loop to run n times faster ... it's not going to be so trivial to get an equivalent speedup if your algorithm actually does real work.)
- parfor is designed to be the MATLAB language's keyword that abstracts SIMD-style parallelism that efficiently runs on small multicore computers (like your 4-way Intel CPU system). The MATLAB language and host environment also supports other parallel programming paradigms for node-level parallelism, for distributed compute clusters, and so on. As a very high-level language, MATLAB permits you to write and run your parallel algorithm in any of these fashions: you must really expend engineering and design effort to determine whether that parallelism will actually give you a speed-up on your algorithm, running on your target hardware.
- Nimur (talk) 17:13, 4 December 2015 (UTC)
- Right, so I guess I don't understand the finer details of multithreading vs. parallel computing. One for loop I'm using is 100% dependent, and I don't think can be parallelized without some serious magic (think N_t+1=F(N_t) in a general sense). On the other hand, I am using another for loop to find a bunch of eigenvalues of matrices that are fairly independent, and I can/should try parfor for that. But with my perhaps simplistic programming, somehow the automatic multithreading is still able to use more than 1 core, even though I don't have explicit parallelism. I guess that extra few percent over 100 can't be altered without specific alteration of the built-in commands I'm using, does that sound right? Good call on parfor though, I got so caught up in the bits that have to be serial that I forgot that one rather intensive bit does not. SemanticMantis (talk) 18:33, 4 December 2015 (UTC)
Help me parfor please
So I'm having a hard time quickly understanding what syntax parfor allows. Can someone help me get it to work with this example code? I think this must be the type of case where it would help. Thanks, SemanticMantis (talk) 18:51, 4 December 2015 (UTC)
Sample code - three nested for loops
|
|---|
for step_ind1=1:steps1;
for step_ind2=1:steps2
for t_ind=1:sim_time
dom_eigs(1,step_ind1,step_ind2,t_ind)=max(eig(squeeze(Lambda(1,:,:,step_ind1,step_ind2,t_ind))));
dom_eigs(2,step_ind1,step_ind2,t_ind)=max(eig(squeeze(Lambda(2,:,:,step_ind1,step_ind2,t_ind))));
end
end
end
|
Ok, it was just something simple, matlab doesn't like loop indices to appear in two different lines within a parfor. The code below runs with parfor, perhaps not as well as possible but well enough for me to see performance increases by utilizing multiple cores:
working Sample code - one parfor inside two fors (cannot nest parfors)
|
|---|
for step_ind1=1:steps1;
for step_ind2=1:steps2
parfor t_ind=1:sim_time
dom_eigs(1,step_ind1,step_ind2,t_ind)=max(eig(squeeze(Lambda(1,:,:,step_ind1,step_ind2,t_ind))));
end
end
end
for step_ind1=1:steps1;
for step_ind2=1:steps2
parfor t_ind=1:sim_time
dom_eigs(2,step_ind1,step_ind2,t_ind)=max(eig(squeeze(Lambda(2,:,:,step_ind1,step_ind2,t_ind))));
end
end
end
|
SemanticMantis (talk) 15:38, 7 December 2015 (UTC)
A way to use document templates in MS Word?
can we use templates (That will contain some footer-text for example) in MS word? Usage similar to MS Excel templates.
I ask this because I've about 10 documents that all must have the same footer text and I have no intention to change it 10 times manually in any case I want to make a small change in their' footer. Ben-Yeudith (talk) 20:15, 4 December 2015 (UTC)
- The quick answer is "yes", Word supports templates. You would use the "save as" feature to save your blank document with the desired footers and select "Word Template" in the "save as type" field. Depending on the version, this will create a .dot or .dotx file. You can then open that file in Word, and save it as a regular Word file after making the changes to the rest of the document. There may be more specific instructions based on which version of Word you are using. --LarryMac | Talk 22:05, 4 December 2015 (UTC)
- The .dot/.dotx template just makes MS-Word / Winword not to keep the filename / documentname of the template. Users were required to [Save as…] their doucument. It might be an idea, to attribute the template file as read only to prevent accientially overwriting it. --Hans Haase (有问题吗) 00:02, 5 December 2015 (UTC)
- How could I import the .dot/.dotx text-piece into each word document if I use Word 2016? I just desire to know how to interact the "Text template" I maid (It's a decent way of naming it wouldn't you agree?) with the Regular word doucments... User:LarryMac or User:Hans Haase. Thanks!!!!!!!!!!!!!!! Ben-Yeudith (talk) 04:40, 5 December 2015 (UTC)
How does a person "own" a web site name (domain name)?
I saw on E-Bay that a guy was selling off a lot of domain names. (For this discussion, let's say that his name saw Bill.) For example, one domain name was something like "delicious pizza.com" (or something like that). So, it appears that Bill "scoops up" some domain names that might be popular and that someone else might want to buy off of him. So, of course, Bill makes a profit from this venture. So, if I buy it from Bill, I now own it. But, my question is, how did Bill own it to begin with? Where do these names originate and who owns them to begin with? Who owns them, originally? And -- a follow up question -- is every single "name" out there already owned by someone? For example, "delicious pizza 1.com" or "delicious pizza 78.com" or "delicaious pizza USA.com", etc., etc., etc. Is every single combination or permutation of characters already owned by someone? If so, who? If not, how do I originate my own so that I now own it? Say, for example, if I want the name "delicious pizza 83764.com" (or some such) and no one else already owns it. How do I become the owner of it? How does this all work? Thanks. 20:56, 4 December 2015 (UTC) — Preceding unsigned comment added by 2602:252:D13:6D70:6CC2:1D1C:D0F0:9193 (talk)
- You probably want to read the Domain Name System article, and maybe domain registrar. --71.119.131.184 (talk) 22:01, 4 December 2015 (UTC)
- You might also like to read our article on cybersquatting and this blog. (Are you Fred or Travis Sutherland or Mike or Rick Ross? If not, then if you get in quickly, www.deliciousPiza.com ; deliciousPizza1.com and deliciousPizzaUSA.com are still available for you to register.) Dbfirs 01:40, 5 December 2015 (UTC)
- Oh ... so this whole thing is illegal? I had no idea. If that's the case, why would E-Bay allow these sales? 2602:252:D13:6D70:6CC2:1D1C:D0F0:9193 (talk) 04:25, 5 December 2015 (UTC)
- It's not illegal to sell domain names, but if they were registered in "bad faith" then it is possible to take civil legal action in some countries to transfer ownership to a more "deserving" owner. The legalities are not clear-cut. See Microsoft vs. MikeRoweSoft for a borderline example. A Chinese company has squatted on a domain name that I failed to renew. I don't think there is any way that I could recover it without buying it back from them. Fortunately, it's not one that I am desperate to recover. Dbfirs 08:26, 5 December 2015 (UTC)
- Note that there's somewhat of a difference between trademark cases (which includes MikeRoweSoft) and non trademark cases (which I think deliciouspizza probably falls under, particularly if registered long before the trademark existed). Trademark cases have the Uniform Domain-Name Dispute-Resolution Policy which many generic TLD and a number of country code ones submit which can be resolved outside of court. (Although either party can still take court action.) Non trademark cases would always have to rely on local law and a civil case. Nil Einne (talk) 10:11, 5 December 2015 (UTC)
- It's not illegal to sell domain names, but if they were registered in "bad faith" then it is possible to take civil legal action in some countries to transfer ownership to a more "deserving" owner. The legalities are not clear-cut. See Microsoft vs. MikeRoweSoft for a borderline example. A Chinese company has squatted on a domain name that I failed to renew. I don't think there is any way that I could recover it without buying it back from them. Fortunately, it's not one that I am desperate to recover. Dbfirs 08:26, 5 December 2015 (UTC)
- Owning a domain name, You need to host Your site if You wanna use it. Usually, as the owner of a domain, You order a provider to host it and have Your web designer upload the finished web page to have it online. If You order an other provider to host Your domain, the new provider only will offer Webspace on his servers. You need to transfer or create new pages. Usually Your web designer does, when ordered. You might also do all or some of it Yourself, if You are ready to do so. Providers still offer You suggestions of available domains as a service, You wanna order them to host it for You to make You their customer. In the beginning of the WWW domains containing trademakrs where sold, some made money, some where judged to release the domain containing trademark they do not own and paid the attorneys and the court. As the websearch came, domain names were seen less and less by product, but even more on the site owner. --Hans Haase (有问题吗) 10:25, 5 December 2015 (UTC)
- To be clear, there's usually no need to do anything with a domain (although actually doing something may help if a claim of bad-faith registration comes up). But even if you did want to do something with a domain, there's no requirement you actually host a website (even a redirect) on it. With most domain names, it's perfectly acceptable if you have no A/AAAA/CNAME/DNAME records and simply have an MX record or whatever, so only use it for mail or something else. Whatever your MX record points to will have an A and/or AAAA record but these don't have to belong to the same domain and typical there is no website behind them only a mail server. (Generally speaking, even if you have an A/AAAA record, it doesn't mean there's a website behind it.) Nil Einne (talk) 03:47, 8 December 2015 (UTC)
- First you go to a domain name registrar. I recently registered AmbushCanyonGames.com - so I went to my favorite domain registrar (I happen to use DreamHost.com - but there are many others). I typed the name into their registration tool - it said that nobody else had registered the name - so I paid my $9.95 - and now it's mine for as long as I maintain the registration (which costs $9.95 per year). Prices vary between registrars - and some top-level-domains are more expensive than others.
- So, you could try to make money by finding names that aren't yet registered - paying to register each one - and hoping to find one that someone else will want to pay $100 for. Obviously, you're taking a risk that nobody will want your names - in which case it cost you a bunch of money for nothing...but when you make a sale, you make a killing.
- In practice, the people who do this probably have much cheaper domain name registration services - but still, there is a risk here. They can reduce the risk by picking existing web sites and finding very similar names. So quite soon after registering AmbushCanyonGames.com - I got an email from someone in China trying to sell me AmbushCanyonGames.cn ...since the most obvious ".com" address hadn't existed until I created it - these guys saw that I created it - then went out and registered the ".cn" varient in the hope of getting some cash out of me.
- If the domain really matters to you, you might want to short-circuit this trick by going out and registering all of the obvious ".net", ".org", ".co.uk" versions - then all of the most likely typos and spelling mistakes that look like your site. The extent that you do this depends on how important the name is to you - and how deep your pockets are...but it's unlikely you'll find them all.
- But if the name you want is already taken - either by a 'real' web site owner or by a cyber-squatter - you'd better start looking for another name - or expect to shell out some cash. I've owned "sjbaker.org" since the very early days of the Internet - but someone else had "sjbaker.com". Every once in a while, I'd go and look at the other sjbaker's web site - then one day, I saw that it no longer existed and was able to jump in and snag that one too. I still habitually use the ".org" name for my email - but a lot of people don't notice ".org" and type ".com" by habit - and it's useful that I can redirect the ".com" domain to ".org".
- So - pick a domain registrar that you like - there are hundreds of them - and start typing names that you like until you find one that's free. When you DO find one you like - don't hesitate to register it because many semi-unscrupulous registrars will go out and register the name for themselves if you don't grab it within an hour or two. Domain registrars are a mixed bunch - some *just* register the name for you - others offer web hosting, web site design and other services. Prices for the same domain can vary quite widely between registrars - but if you want to shop around, do it BEFORE you choose your name. SteveBaker (talk) 15:27, 5 December 2015 (UTC)
- Thanks. So, is there one central database that indicates if names are available or unavailable? Or do I have to go to each and every domain name registrar, one by one, to find if a name is available or unavailable? Or do I just type the name into my web browser address box and see what happens? Thanks. 2602:252:D13:6D70:BD83:3784:351:F8B4 (talk) 02:21, 6 December 2015 (UTC)
- You can check with WHOIS. —Tamfang (talk) 08:20, 6 December 2015 (UTC)
- In effect, it's one central database - although the mechanism by which it's maintained is distributed and much more complex than that. But you can treat it as if there was one giant list of who owns what name. Hence you only need to check with one domain registration service. Typing the name into your browser isn't enough - that only tells you whether there is a web site connected to that URL - not whether the name is already registered by someone. As Tamfang points out, you can use one of the many WHOIS lookup services out there - but those are generally made available by domain registration service companies - so it boils down to the same thing. But as I said before - pick one place to go to - check for what you want and register it right then and there if it's available. If you dawdle around and especially if you hop from one domain name registrar to another, you'll find that someone will register it and try to sell it to you for ten times what you could have paid for it if you'd jumped right in. SteveBaker (talk) 16:23, 6 December 2015 (UTC)
- Thanks. So, is there one central database that indicates if names are available or unavailable? Or do I have to go to each and every domain name registrar, one by one, to find if a name is available or unavailable? Or do I just type the name into my web browser address box and see what happens? Thanks. 2602:252:D13:6D70:BD83:3784:351:F8B4 (talk) 02:21, 6 December 2015 (UTC)
- The windfall for owning the right name that someone wants can be quite substantial. In that case, the person who owned pizza.com for 14 years, paying just $20 per year, was able to sell it for $2.6m. Dismas|(talk) 18:32, 5 December 2015 (UTC)
- The history of sex.com is even more horrifying - it was also originally purchased for some very small amount and eventually sold for $14,000,000. That's generally believed to be the most ever paid for a domain name...but the mess over who owned it spiralled way out of control. Fortunately, we have better regulations about that kind of mess these days. SteveBaker (talk) 16:23, 6 December 2015 (UTC)
- It's worth mentioning that "all of the good names are gone". Specifically, it's very rare to find a single english language word that isn't already registered - and most two-word pairs that make any sense are taken (at least in ".com"). Three-word names are easier to get - and nonsense words and acronyms are quite easy to find too - but then you have the problem of people remembering them and hating type them if they are too long. You can very often find names in less-often-used domains - so for example, the URL of my business at http://RenaissanceMiniatures.com is a pain to type - but easy for people to find by guessing - so we wanted to register a shorter version of it - and we found http://renm.us was free - which isn't bad for a six-keystroke URL! Short URLs are tough to find - but far fewer people want to use the country-specific domains (like ".us") that you can often still find nice free entries there. SteveBaker (talk) 16:23, 6 December 2015 (UTC)
- There is a believe (which I believe to be unfounded) that extremely long and descriptive domain names will help in search engine rankings. An organization that I work with hired a PR group to help with "branding." The PR group wanted them to use the domain name carecoordinationinstitute.org. Imagine typing emails to that group every day. 209.149.113.52 (talk) 14:33, 7 December 2015 (UTC)
- Google don't disclose their ranking algorithms - and they change them fairly frequently - so it's hard to be definite about this kind of thing. However, I'm doubtful that they really do improve the rankings of sites with long domain names because they generally work hard to prevent people from being able to affect their rankings other than as an indirect consequence of being a useful web site with good content. If it were true that there was an advantage for longer names then you'd see "http://we_here_at_amazon_sell_books_and_music_and_a_bunch_of_other_stuff.com" - and we don't. SteveBaker (talk) 20:30, 7 December 2015 (UTC)
- There is a believe (which I believe to be unfounded) that extremely long and descriptive domain names will help in search engine rankings. An organization that I work with hired a PR group to help with "branding." The PR group wanted them to use the domain name carecoordinationinstitute.org. Imagine typing emails to that group every day. 209.149.113.52 (talk) 14:33, 7 December 2015 (UTC)
- Sure, typing CareCoordinationInstitute.org the first few times would be annoying. But once you have all the people that you're going to be emailing there in your history, it's fairly easy to type the first few letters of a person's name. I emailed one guy today whose last name I can't remember how to spell. All I did was type "Mik" and Mike's last name and email address were right there in the list of suggested addresses. Dismas|(talk) 03:37, 8 December 2015 (UTC)
- But what about when I work with 8 different people named Ali, all at different universities? I've sent a hell of a lot of emails to Dr. Hurson when I meant to be emailing Dr. Schwartz, Dr. Wardle, Dr. Ever, etc... 209.149.113.52 (talk) 13:28, 8 December 2015 (UTC)
Active Directory
How replication happens in AD? — Preceding unsigned comment added by Sanjaytak7 (talk • contribs) 23:20, 4 December 2015 (UTC)
- I assume that you've read Active Directory#Replication and that there is insufficient information there, but it does contain a couple of links that might further your research. Dbfirs 17:59, 5 December 2015 (UTC)
The latest Firefox version changes attachment download functions
As of the latest Firefox update, email attachments no longer appear or function the same way, and it's not the email program because its tied to when I updated Firefox, and the change is the same when I look at yahoo mail attachments or gmail attachments.
They now appear as much larger icons than previously, and if you click them, they preview rather than downloading. When you put your cursor over them, s small download bar appears as part of the image, so they are giving you the option, but I can no longer just click and download. Anyone know a fix?--108.21.87.129 (talk) 23:36, 4 December 2015 (UTC)
- Do you mean in various webmail clients? I don't think many people use Firefox to access email programs, that's the whole point of them, they're standalone. Nil Einne (talk) 10:53, 5 December 2015 (UTC)
- BTW, if you do mean on webmail clients, I'm pretty sure you're mistaken. This is to do with the webmail client and not your browser. You can sort of tell this by the fact the way this is handled in different webmail clients is different. For example at least for me, Gmail will open a preview in the whole page with the email blacked out in the background. Yahoo will open a preview to the right of the email with the email still visible (you can see the preview in the whole page by clicking on the expand arrows).
Another sign this is coming from the email client is that Google will probably show a save to Google Drive icon, whereas Yahoo obviously doesn't. The third sign is that in Google, your URL will change to something with projector in it.
The fact you're seeing this on multiple webmail clients isn't exactly surprising, this popup/theater/projector style view is all the rage, used by Facebook and other social media and a number of news sites. Even the Wikimedia Foundation controversial introduced it to most of the wikis they manage.
As to why you're only seeing this after a browser upgrade this is more surprising. It could be that the feature requires a browser feature which your old browser didn't have but I'm pretty sure Gmail at least has had this popup preview on Firefox for at least a few versions and you didn't mention you were using a very old version like LTS or whatever, so I presume this isn't the case. Perhaps the more likely alternative is you have a plugin which used to disable this projector view which isn't working anymore.
As to how to change this, I couldn't find mention of a simple setting for Gmail. I'm sure you could find a ScriptMonkey script to disable it, or perhaps a specialised plugin.
Note there's no need to click the attachment to get the download link. When you however over the attachment before clicking, in both Gmail and Yahoo, there should be a download button. If you're using a touch screen device I think there's some way too, but I can't remember offhand.(Just noticed you already know that.)Nil Einne (talk) 13:48, 5 December 2015 (UTC)
- Actually, I guess what you're really complaining about is not so much the popup preview per se, but rather the way you have to hover over to get the download button. At least in Gmail, in the past, the preview was supported but you had to click on on the view button to get it [1] whereas nowadays you get [2] (click on desktop)[3] the larger thumbnails which require you to hover over to downloads instead.
However most of what I said above still applies albeit the specifics are a bit different. You can tell this is function of the webmail client because it's different between clients. On Gmail when you hover over you will generally get the save to Google Drive icon as well as the download one. Yahoo has the download and a somewhat hidden option to save to Dropbox. The thumbnails are also different. Google thumbnails are rectangular and larger than Yahoo ones which are square.
In addition, in Gmail at least the larger thumbnails which require you to hover over to download has I'm pretty sure been supported in a few versions of Firefox.
BTW, one alternative besides scripting to change this behaviour is to actually use a email program like Thunderbird, rather than rely on what the providers webmail client which you have limited control over.
- Actually, I guess what you're really complaining about is not so much the popup preview per se, but rather the way you have to hover over to get the download button. At least in Gmail, in the past, the preview was supported but you had to click on on the view button to get it [1] whereas nowadays you get [2] (click on desktop)[3] the larger thumbnails which require you to hover over to downloads instead.
- BTW, if you do mean on webmail clients, I'm pretty sure you're mistaken. This is to do with the webmail client and not your browser. You can sort of tell this by the fact the way this is handled in different webmail clients is different. For example at least for me, Gmail will open a preview in the whole page with the email blacked out in the background. Yahoo will open a preview to the right of the email with the email still visible (you can see the preview in the whole page by clicking on the expand arrows).
December 5
Are those 4k TVs or ultra hd TVs any good?
Would a 4k TV or ultra hd TV have a higher pixel density than TV broadcast, DVD or even Blue-Ray movies? If dpi bottle-neck is at the stored image, and not at the display, would it look better than full hd? --Scicurious (talk) 19:20, 5 December 2015 (UTC)
- Obviously the TV isn't going to give you more visual information than is in the signal. One nice thing about them, though, is that they can double up as very nice computer monitors. I'm using a 32" HP ENVY Quad-HD, and that way I can compute from my couch without eyestrain and plenty of screen real estate. Paid around $400 for it. That was almost a year ago; I think by now there are similar 4K monitors that are also affordable.
- If you go that way, though, there are a couple of things to look out for. Make sure it accepts a Display Port connection (otherwise it's just a TV and may not work well as a monitor).
- And whatever you do, don't get a "smart" TV. Whether you want to use it as a monitor or not. We have to kill that thing. That's like inviting the manufacturer to control the thing even after you paid for it. --Trovatore (talk) 19:48, 5 December 2015 (UTC)
- Well... from a purist point of view, a device can display more information than is in the signal - by adding new information, based on some heuristic model! Many modern televisions render more pixels than the source image; and nowadays, in 2015, it's very common for televisions to provide frame-rate doubling and similar technologies. This lets a television display 4K or 120 frames-per-second, even if the source data does not contain video at that resolution or frame-rate. The exact methods for upscaling or frame-interpolating vary; we have a section on standard methods in common use. The output on screen therefore can have more frames, more pixels, more "bits", more "entropy," than the input. Whether this causes the output image to have a higher visual quality is an altogether different question. I personally find TV framerate doublers very annoying and visually distracting - even the very "good" ones with fancy interpolation algorithms. But, good upscaling algorithms can make a huge impact. Most humans probably can't tell the difference between native resolution or an upscaled image from 4x or even 16x undersampled data (using modern technology).
- In the most trivial case, new pixels can be added by upscaling and interpolating. New frames can be added by the same general method - interpolating in the time domain, instead of in the spatial domain. If you study modern digital signal processing, you can see that these exact types of algorithms are among the most heavily-researched topics - especially as they apply to specific use-cases like "4K video." A few years ago, IEEE published A Tour of Modern Image Filtering, which briefed and reviewed a lot of the advances that have happened over the last decade. We have come a long way from the simple sinc filter; various techniques have blossomed as computers have gotten faster and more parallelizable; as analytical and subjective quality has been studied; and as commercial applications have proliferated.
- Nimur (talk) 21:17, 5 December 2015 (UTC)
- I do in fact know a little bit about digital signal processing, and yes, my answer was incomplete. Still, you aren't going to get a 4K experience from an HD signal; I'm reasonably confident about that. --Trovatore (talk) 21:21, 5 December 2015 (UTC)
- Well, I won't get a 4K experience by upscaling HD source data; perhaps you won't either... but we are outliers! A very large percentage of the population would experience these videos in the same way - because many people can't even tell HD from SD! You can find lots of statistics to back this up - something like 20% of the population will believe a display is showing HD content, even if the hardware is a standard-definition unit. (Shoot - 40% of the population has myopia and can't focus on the TV without using corrective lenses!) In other words, the quality delta between SD and HD is below the just-noticeable difference for a large segment of the bell-curve of consumers; between HD and 4K, the quality delta is imperceptible to even more users. Nimur (talk) 21:42, 5 December 2015 (UTC)
- OK, you may be right. So I'll fall back to quibbling that my original claim about information is still correct, unless the TV does something non-deterministic (and I doubt that there's any useful application for non-determinism), or unless it actually consumes pre-loaded entropy (which, again, seems unlikely to be useful). --Trovatore (talk) 21:47, 5 December 2015 (UTC)
- Yes, I think you are still correct from a pure, information-theory standpoint. Information, and entropy, doesn't come from nothing!
- As far as "usefulness" - one person's noise is another person's signal! Some algorithms intentionally inject noise into the output - e.g., shaped noise or noise-filling - because this can improve subjective perceptions of the image- or audio- quality. In fact, using shaped white noise as the primary input in digital signal synthesis - whether audio or video - is one way to create more psychologically-believable output signals. Go figure! The noise probably comes from a pseudorandom noise generator, so it's still usually deterministic, but it doesn't have to be.
- Here's a nice review paper on one particular image processing algorithm, Total Variation Regularization (surely there are thousands of other great papers on this topic, but this one happens to have lots of nice image examples). Personally, I think Lena looks better before de-noising - but her noise is Gaussian. The subjective trade-offs become very different if the noise spectrum is less random.
- The long and short of it is, your better quality televisions may have better algorithms - which can mean less visible block-artifacts, less color inaccuracy, and so on.
- Nimur (talk) 02:09, 6 December 2015 (UTC)
- Try reading the fine print on US TV ads for medication. I can currently read those in 1080, but some of the companies seem to have gotten wise to that and made the fine print even smaller, so I can't read them even there. (You also need the ability to freeze the screen, which on my TV doesn't work in 1080 mode ... I wonder if big pharma bribed them to make that happen.) StuRat (talk) 21:57, 5 December 2015 (UTC)
- OK, you may be right. So I'll fall back to quibbling that my original claim about information is still correct, unless the TV does something non-deterministic (and I doubt that there's any useful application for non-determinism), or unless it actually consumes pre-loaded entropy (which, again, seems unlikely to be useful). --Trovatore (talk) 21:47, 5 December 2015 (UTC)
- And just because you can hook a PC up to it doesn't mean you will get 4k resolution. The PC has to support it, the cables and connectors have to support it, and the TV has to support it. I've been burned by TVs with a high native resolution, but that only support a lower res when used as a monitor. StuRat (talk) 20:18, 5 December 2015 (UTC)
- I would suggest waiting until more 4k content is available. Hopefully the price of 4k TVs will also be significantly lower by then. Also, if the 4k makers were smart, they would allow you to watch four 1080 shows at once, and just turn the sound on for one at a time. Much better than picture-in-picture. StuRat (talk) 20:18, 5 December 2015 (UTC)
- I guess I'll point out that unless you sit unusually close to your TV and/or have unusually good vision, 4K won't look better than HD even with 4K source material (Optimum HDTV viewing distance#Human visual system limitation). -- BenRG (talk) 21:33, 5 December 2015 (UTC)
- Well it depends on how big your TV is.Dja1979 (talk) 15:46, 6 December 2015 (UTC)
- First, when you say "DPI" (dots per inch) you really mean "PPI" (pixels per inch). DPI is used to describe the quality of prints.
- Pixel density (PPI) is a function of the TV hardware. For example, a 30-inch 1080p TV would have a higher pixel density than a 40-inch 1080p TV simply because it's cramming the same amount of pixels into a smaller screen. When you're talking about the video content, terms like 1080p and 720p will simply refer to the size of the video frame. For example, a 1080p video frame measures 1080 pixels tall and 1920 pixels across.
- An HD TV will automatically up-sample any SD broadcast or DVD content so it fills the screen. However, it won't look any better because it's essentially just duplicating information onto more pixels, rather than adding detail to the picture. In addition, SD content is typically 480i, which has a 4:3 aspect ratio. So, each frame resembles a square in proportion. A 4k TV has a ratio of 16:9, which looks more like a rectangle. So, any SD content won't fill the entire screen and will have black areas to the side of the frames because the picture isn't wide enough to fill the whole screen.
- Broadcast HD content is typically 1080i or 720p. Until recently, Blu Ray content was limited to 1080p. Recently, there has been some "ultra HD Blu Ray" content released, which is 3840 by 2160. So, if you had a 4k TV, a new ultra HD Blu Ray player, and an ultra Blu Ray disk, you would be (mostly) taking full advantage of the TV. Most content online still tops out at 1080p, though.
- In the future, there will be a lot of UHD content online, on disk, and on TV. However, you'll need a large TV to notice the difference. Or, if you sit really close to smaller UHD TV, you might be able to tell, too. This chart shows the relationship between size, pixel dimensions, and distance: http://i.rtings.com/images/optimal-viewing-distance-television-graph-size.png.—Best Dog Ever (talk) 04:03, 6 December 2015 (UTC)
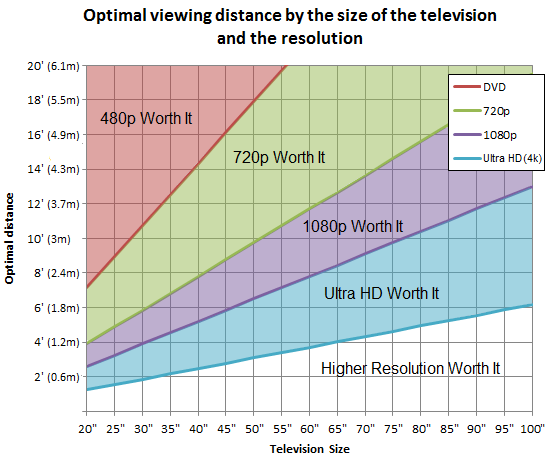{kind=link}
- They seem to have missed something in that chart. If you have a 100 inch TV, you can't view it from two feet away. Well, you could view a small portion of the screen from that far, but the rest will be much farther away. If it was curved into a hemisphere you could get your head a bit closer to the rest of the TV. Still, it would be intensely annoying to be so close to such a large TV. StuRat (talk) 17:04, 6 December 2015 (UTC)
- The chart recommends placing a 100-inch TV at least six feet away if it's an ultra-HD model.—Best Dog Ever (talk) 23:31, 6 December 2015 (UTC)
- But it also says you can buy a 100 inch TV in an even higher res that 4k and place it as close as you want. :-) StuRat (talk) 00:41, 7 December 2015 (UTC)
- Another question is whether more resolution is really better, even assuming that you can see the difference. With 1080 I now see lots of beard stubble, skin blemishes, wrinkles, etc., that I didn't see before, but does that make my viewing experience better or worse ? At 4k, I will probably be able to see every pore on their faces. Is this an improvement ? The one place I do appreciate the higher res is when trying to read tiny text, as you sometimes find in the credits for a movie. StuRat (talk) 17:08, 6 December 2015 (UTC)
- It depends on the type of content. If you watch sports, for example, you want as much detail as you can get. With higher detail, you can see if a player really did foul another player or did the ball really cross the line, etc.
- Also, I forgot to mention that ultra HD TV supports more colors than current TV standards. Current content has eight bits per channel, but UHD content has ten bits per channel. Different people can see different amounts of color, but for many, colors in UHD content will look more realistic.—Best Dog Ever (talk) 23:31, 6 December 2015 (UTC)
- For sports, I'm sure they will show a zoom replay that will make it clear. StuRat (talk) 00:43, 7 December 2015 (UTC)
December 6
Programmers, please see a semantic debate here
About Outliners. Ben-Yeudith (talk) 06:24, 6 December 2015 (UTC)
Carte blanche cookie consent
Some time ago a law was passed in Europe requiring all websites to obtain authorisation from the user to place cookies on their computer. I think this is irritating and would like to grant authorisation to place all the cookies on my computer that websites want to just like they did in the past without bothering me. Is there some browser extension or setting I can set to declare my authorisation so websites can stop with constant notifications every time I visit a new one? --78.148.111.75 (talk) 15:48, 6 December 2015 (UTC)
- As far as I know, there isn't any way to do what you want. The cookie consent forms and notices are implemented on a site-by-site basis, meaning there are many different implementations. For instance, here's one solution and another in the form of a WordPress plugin with completely different behaviors. I'm sure even more are written from scratch just for individual websites. Sorry. clpo13(talk) 00:58, 7 December 2015 (UTC)
December 7
.HTaccess-Drupal question
When I open the main .HTaccess file in a Drupal 8 installment I see 10 <ifmodule>(s) [And some other things]. On the contrary when I open the Apache modules list at WAMP, I see about 25 modules.
- I know that each <ifmodule> represents a reference to an Apache module (I hope this is assumption is true, ist it?).
- Why are only ten of the Apache modules (and most notably Rewrite_module) are referenced by the .HTaccess and not all of the modules I've seen at the Apache list? Thanks. Ben-Yeudith (talk) 07:02, 7 December 2015 (UTC)
- The .htaccess is a hidden file inside the Web content folders. Itself and its settings are essential for security to prevent readout secrets by direct accessing files located in a known folder structure drupal uses. --Hans Haase (有问题吗) 12:20, 7 December 2015 (UTC)
- I know this - I've edited the question. I need answers to the two questions I presented. In great plea, Ben-Yeudith (talk) 18:23, 7 December 2015 (UTC)
Which programming languages allow trailing commas?
- Question moved from WP:RD/L Tevildo (talk) 09:13, 7 December 2015 (UTC)
Is there any website that lists which programming languages allow trailing commas and which do not? Something like Comparison of programming languages.
Googling "LANGAUGE_X trailing comma" helps, but it's would be too tedious for dozens of languages, plus it can't be automated; for example the Google results page for "fortran trailing comma" doesn't have the answer on any of the excerpts, so you would need actually visit and read each of the result links.
There's a redirect trailing comma on WP, but sadly that's no longer working.
To keep things simple, let's restrict things to the 50 most popular (by some arbitrary standard) languages [4] out there. 731Butai (talk) 07:50, 7 December 2015 (UTC)
- @731Butai: That redirect should be redirecting to b:Computer Programming/Coding Style#Lists. The last version at Wikipedia, that included that section is here. Maybe that helps. --Edgars2007 (talk/contribs) 09:41, 7 December 2015 (UTC)
- It isn't simply a matter of allowing trailing commas. You also need to know when you can have a trailing comma and what the trailing comma specifically means. 209.149.113.52 (talk) 17:31, 7 December 2015 (UTC)
Varying PDF file sizes
If you create a PDF of an A4 page directly from Acrobat, you get a file size of about 1MB per page. However if you activate your scanner via NAPS2 (not anithere pdf scanner) software or similatr packages, you get about 100kB per page. What is happening here. What is the extra data that NAPS2 discards?--178.110.28.209 (talk) 11:20, 7 December 2015 (UTC)
- PDF Versions habe specified picture formats. PDF Exprot filters have settigs to specifiy the export and the PDF compatibility to older versions and sometimes you can restrict picture compression settings. When the older JPG standar is spcified, a newer could not be decoded by the pdf viewer. A recencoding of the embedded pictures is performed by the PDF export. --Hans Haase (有问题吗) 12:14, 7 December 2015 (UTC)
- I created a blank PDF in Adobe Acrobat Professional 9.4 by going to File → Create PDF → From blank page and saved the file. The page was roughly A4 in size. The file was only 6 KB. So, there must be something in that A4 page that you didn't mention -- maybe a high-resolution photo? When you scan a page using NAPS2, you must be scanning it at a low resolution or using high compression. If you need to reduce the file size of a PDF in Adobe Acrobat Professional, you can go to Document → Reduce File Size.—Best Dog Ever (talk) 00:59, 8 December 2015 (UTC)
- Yeah well the A4 page did have some music notation on it. Im trying to reduce it from around 1M to around 100k.--178.110.28.209 (talk) 02:31, 8 December 2015 (UTC)
- Ideally you should preserve the content as vector data rather than raster which will normally give the smallest file size provided it isn't too complex and you use ZIP compression. But this isn't possible if your source is a printed page or scan. (You'd need to OCR it and I don't know if there are good OCR programs for OCRing sheet music.) In that case, if the sheet is black and white (1 bit/monochrome, not gray scale), converting it to such with either JBIG2 or CCITT group 4 compression should work well. If you're using black and white, you shouldn't generally make resolution too low. Nil Einne (talk) 19:35, 8 December 2015 (UTC)
- Yeah well the A4 page did have some music notation on it. Im trying to reduce it from around 1M to around 100k.--178.110.28.209 (talk) 02:31, 8 December 2015 (UTC)
Computer battery
Hello,
How do I find out what battery I need to buy i.e. the same as the one I currently possess? Its a Toshiba company PC; Laptop. -- Space Ghost (talk) 19:56, 7 December 2015 (UTC)
- Toshiba has done battery recalls, so they have a good web page showing how to identify your battery here. 209.149.113.52 (talk) 20:19, 7 December 2015 (UTC)
- You can either buy a genuine battery for your laptop model, or a generic battery. In both cases, the battery is advertised as compatible with a series of models. --Denidi (talk) 13:53, 8 December 2015 (UTC)
I don't know what to say... This is what I found after viewing the battery, C33101713BLA KC2012.03 - the first bit is on the left and the second bit is on the right, a barcode is at the top of it.
I'm incapable of buying it from the internet, I do wish to view the costing so that I can bargain here where I'm with the shopkeeper(s).
I've inserted the embolden info in google, nothing came up...
Space Ghost (talk) 19:56, 8 December 2015 (UTC)
- If you the laptop's model number then you can search for "Toshiba <model> battery"; sites that sell replacement batteries will list them both by battery number and model number. LongHairedFop (talk) 20:11, 8 December 2015 (UTC)
- How do I search for that? I only have the laptop. No receipt of purchase, no cover box of it either. -- Space Ghost (talk) 06:54, 9 December 2015 (UTC)
- Turn your laptop over and look for a sticker similar to the one shown on this web page. I'll use that sticker as an example, although you probably have a different model.
- For this purpose, I would ignore the "part no.", even though that web page identifies it as a "model-part number". I'd note the TECRA A11-S3531 above the part no., and do a Google search for tecra a11-s3531 battery.
- That search gives these results, listing various places to buy a compatible replacement battery for a Toshiba Tecra A11-S3531 laptop.
- Wherever you buy the battery, triple-check that it is compatible with your model before you pay, or you may be stuck with an expensive paperweight. ―Mandruss ☎ 08:26, 9 December 2015 (UTC)
- Got the idea and found it too. I know the price now. Thank you very much.
 -- Space Ghost (talk) 18:57, 9 December 2015 (UTC)
-- Space Ghost (talk) 18:57, 9 December 2015 (UTC)
- How do I search for that? I only have the laptop. No receipt of purchase, no cover box of it either. -- Space Ghost (talk) 06:54, 9 December 2015 (UTC)
Thanks all. ![]() -- Space Ghost (talk) 18:57, 9 December 2015 (UTC)
-- Space Ghost (talk) 18:57, 9 December 2015 (UTC)
Please view this and this, the difference between the two is, first one is 4800mAh and the second one is 5200mAh, does it mean more battery power storage capacity? Current one i.e. 4800mAh gave 4 and half hours - now its giving 15 mins btw - the more capacity the better of course. How do I analyse this? Does it even matter? -- Space Ghost (talk) 18:57, 9 December 2015 (UTC)
- Actually the first one says 4200mAh, not 4800mAh. In theory, the second one should last about 24% longer between charges. I lack enough first-hand experience to judge the reliability of those numbers, however. There's also the question of quality, and I suspect there are unacceptably cheap laptop batteries like anything else. I also lack the first-hand experience to judge that, so I usually depend on Amazon.com and their buyer reviews to take care of me. If you can't order online, I can't be of much help in that area. ―Mandruss ☎ 22:04, 9 December 2015 (UTC)
OCR-A characters intended use
What were the characters listed at Dedicated OCR-A characters meant for? Did they ever serve a purpose? — Sebastian 22:27, 7 December 2015 (UTC)
| Name | Glyph | Unicode |
|---|---|---|
| OCR Hook | U+2440 | |
| OCR Chair | U+2441 | |
| OCR Fork | U+2442 | |
| OCR Inverted fork | ⑃ | U+2443 |
| OCR Belt buckle | ⑄ | U+2444 |
| OCR Bow tie | ⑅ | U+2445 |
- Those are command characters. They can be used for whatever you really want them to be used for. You often see them on material designed specifically to be scanned by a computer. So, assume I am designing a new parking ticket to be read by a computer. I might use the hook character followed by the time of the ticket. The computer knows that the hook means "the time follows." I might then use the bow tie followed by the date, so the computer knows that after the bow tie (actually, I call it the ocr asterisk) is the date. If you look at a bank check, you will likely see OCR command characters at the bottom to identify the start of the routing number and start of the account number. 209.149.113.52 (talk) 13:34, 8 December 2015 (UTC)
- I think the characters on checks are Magnetic_ink_character_recognition fonts, which seem very similar but a little different to OCR-A. See short description here [5]. Probably we could use an article on E13-B font, rather than just a redirect to MICR. SemanticMantis (talk) 14:16, 8 December 2015 (UTC)
- Thanks to both of you. I'll bring up the suggestion to split the article at Talk:Magnetic ink character recognition. — Sebastian 20:18, 8 December 2015 (UTC)
- I think the characters on checks are Magnetic_ink_character_recognition fonts, which seem very similar but a little different to OCR-A. See short description here [5]. Probably we could use an article on E13-B font, rather than just a redirect to MICR. SemanticMantis (talk) 14:16, 8 December 2015 (UTC)
December 9
android 5 standby low battery notifier
hey! Can you point me to the software for android that can notify you (beeping or by other sound means) when your battery plunges under a certain percentage level, there are a few on goole play, but none of those that I've tried do it while the phone is in sleep(standby) only when you are active...
thanks — Preceding unsigned comment added by 37.200.78.45 (talk) 05:27, 9 December 2015 (UTC)
Auto-copy the content of a sub-document into the master-document? (MS Office)
I have created an MS Word master-document that contains a piece of content imported from a sub-document, but I have a problem --- Each time I close and reopen the document the text no longer appear there and a blue link to the sub-document's path appears instead so to make it appear again I need to go to View > Outline, and there click "Expand subdocument". I need to do this manually each time anew.
Maybe there is a way to force coping the text from the sub-document or at least make it more permanent, so it won't be collapsed at all? It is extremely important for me for cases when I send this document to others --- I can't expect anyone receiving it to do these steps... It's madness... Ben-Yeudith (talk) 09:04, 9 December 2015 (UTC)
Is Google's D-Wave 2X Quantum Computer, as it is called, really a quantum computer with qubits inside?
131.131.64.210 (talk) 14:23, 9 December 2015 (UTC)
- The D-Wave does have qubits. However, it is less a computer and more a specialized calculation device. In other words, it is not what we call a "general" computer or a "universal" computer. It handles quantum annealing problems. If you want to work on those, it will do it very quickly. If, instead, you want to calculate correlations between two columns of data, it won't help (unless you can turn that into an optimization problem). The goal is to make a quantum universal computer at sometime in the future. 209.149.113.52 (talk) 14:33, 9 December 2015 (UTC)
- The topic of defining a "qubit" was also discussed on the reference desk in May 2014. I think you will find that "qubit" is so weakly defined that nearly anything can be called a qubit. For example, a violin string may either be silent or vibrating - it can exist in two states (a ground state and an excited state), approximating two energy levels of a non-ideal oscillator system. Because a violin string is pretty strongly resonant, the preferred oscillation frequencies are quantized. Because the individual strings can resonate and supply energy to each other, these four "qubits" can be called "coupled" and some equation can be written to describe how weakly or strongly they effect state-changes in each other. These facts satisfy the (unreferenced) definitions of a qubit as explained in our encyclopedia article. So: is a violin a 4-qubit system? What external circuitry would you need to attach to it in order to call it a "4-qubit computer"? How functional would that "external circuitry" remain if you then proceeded to remove the violin from the computing machine?
- The trouble with D-Wave is that it is not obvious how much of the "computer" is inside their refrigerated physics experiment that they call the "quantum" part, and how much of the computation is actually performed by the conventional computer that is attached to that device. I would put forward that their "device" is more similar to a thermal noise generator - similar to the devices sometimes used to generate entropy for secure computing applications. As such, the device might be useful for some experiments - like simulated annealing or monte carlo method computer algorithms. However, I'm not convinced that it's particularly novel - certainly not worth its cost.
- Nimur (talk) 16:26, 9 December 2015 (UTC)
- A violin supercomputer definitely sounds like something out of a Douglas Adams novel :) 131.131.64.210 (talk) 17:13, 9 December 2015 (UTC)
- D-Wave doesn't hide their technology. They are using niobium qubits. They make it very clear that it is not a general purpose computer. It is lacking logic gates. It only does optimization of multivariable equations. Further, it doesn't have error correction. They claim that because it works in low energy states, they don't need it. I don't think the issue is "Do they have qubits?" It is "How can we step from this specialized device to a general computing device?" 209.149.113.52 (talk) 17:15, 9 December 2015 (UTC)
- Well, do their sales team ever have an answer for you! Your algorithm, written in MATLAB or Mathematica or Python or FORTRAN (... or just, whatever) simply runs through their software stack, which handles all the hard parts by way of a Quantum Meta Machine. This software - especially the MATLAB interface - definitely exists* - or at least is in a superposition of existing and non-existing. (*Under Development)... since 2009).
- Here is their software architecture overview. When I watched their tutorial video on Map Coloring, I was intrigued at first... but after watching to the end, I can only conclude that this product is aimed at people who have an absurd misunderstanding of computer science.
- For example, they describe the quantum annealing solution as an alternative to "random solution-guessing." This is a straw man fallacy! It is very true that randomly guessing solutions to the map coloring of the United States would be inefficient. But this is not how we design actual graph-coloring algorithms! If I wanted to write a for loop to iterate over a variable i from one to six... I would not roll a dice six times and hope that statistically I get an ordered sequence! If I did use this method, a quantum computer would beat my algorithm... in exactly the same way that D-Wave correctly found a "needle in haystack" solution. A "randomized" effort to generate a for-loop for i=1 to i=6 would have a one-in-46,656 chance of being right - which is statistically harder than finding a random four-color solution for the map of Canada by random-guesses! We could replace "i" with six qubits; construct, and then solve a constraint-equation so that the objective function is minimized only when bit bn is larger than bit bn-1; then program that into the D-Wave and let that solution anneal... this method would, in fact, yield better results than randomly guessing i six times in a row. But it's not better than a real, actual conventional for-loop.
- The point here is that the quantum computer is "outperforming" an absurdly-designed, altogether implausible version of a "conventional" algorithm that we would never actually use.
- And this is to say nothing of the conventional optimization algorithm that must be performed to set up the "qubit" connectivity. This optimization problem is a complex one - and it needs to be performed for each qubit, as described in D-Wave's marketing literature. This is the same logical fallacy that I described in 2013 when we discussed why a "spaghetti sort" is not actually, truthfully scalable. If you casually neglect every part of the computation that is difficult to scale, the algorithm sure does appear to be infinitely scalable in constant time! D-Wave even has to serialize its quantum operations - so, that makes its runtime O(n) - linear at best (and probably much much worse for large, complex, or densely-interconnected graphs)! This is exactly a refutation of the supposed benefits of quantum computing. The dream they've been selling is that "super-large" problems could be solved with magic massively-parallel qubit entanglement - except they forgot to emphasize the annoying part where you have to split the problem into n tiny sub-problems and iterate them sequentially. Video, at 10m50s. They leave that annoying part out of the sales pitch, but it snuck into the technical tutorials!
- Have you noticed that D-Wave customers have been very reluctant to provide wall-clock times on any of their benchmarks?
- I've seen my share of "weird" computers, and this one is way more snake-oil-y than most.
- Nimur (talk) 03:55, 10 December 2015 (UTC)
- D-Wave doesn't hide their technology. They are using niobium qubits. They make it very clear that it is not a general purpose computer. It is lacking logic gates. It only does optimization of multivariable equations. Further, it doesn't have error correction. They claim that because it works in low energy states, they don't need it. I don't think the issue is "Do they have qubits?" It is "How can we step from this specialized device to a general computing device?" 209.149.113.52 (talk) 17:15, 9 December 2015 (UTC)
{kind=link}
- Nimur, do you know anything about quantum computing? Why do you think you're qualified to talk about this? Most of the text in this thread is by you, but the only useful responses were by 209.149.113.52, who clearly does know what he/she is talking about.
- When you say the runtime is linear at best, you seem to be confusing the size of the output with the size of the search space. If the solution is n bits long, there are 2n possible solutions, and a machine that could find the global optimum in O(n) time, or any low-degree polynomial in n, would revolutionize the world. So needing O(n) time to touch all qubits is not a problem.
- The theory behind what they're trying to do is described in the article quantum annealing, which is actually pretty readable. It's similar to classical simulated annealing, but there are known problems for which it's asymptotically faster; in at least one case the speedup is quadratic (the same as the speedup of Grover's algorithm over classical brute-force search). Unfortunately, it's not known to be asymptotically faster than classical Monte Carlo simulation of quantum annealing. So this doesn't seem to be a case of a quantum computation offering an asymptotic speedup over the best known classical algorithm. At best it could be faster the way GPUs are faster than CPUs for some tasks. It's expensive now but so were GPUs at one time.
- All of this is explained the the preprint that seems to have spawned the current media cycle. Scott Aaronson also has a blog post about it. -- BenRG (talk) 08:11, 10 December 2015 (UTC)
- BenRG, it seems that you are directly questioning my "qualifications" as if you'd like to establish my credentials before I contribute to the encyclopedia. This is not how Wikipedia works. If I am wrong or mistaken, please correct me where I err. That standard applies, irrespective of my credentials or experience. I'm tempted to return the question tu quoque, except that I don't really judge your correctness by your academic degrees. I have met many well-credentialed people who were also wrong.
- For example, you are wrong when you write "needing O(n) time to touch all qubits is not a problem." It seems that you failed to notice that for each qubit, an optimization problem must be computed: so that's not O(n) over n qubits - it's n iterations of an optimization problem. This is as-documented in the video tutorial I linked. This wrongness is independent of whether you are "qualified" to write on this topic.
- By all means, buy yourself a D-Wave - rather, attach yourself to an organization that already has one - and experience the machine first-hand. I am very curious to see how you would respond after using one.
- Nimur (talk) 14:59, 10 December 2015 (UTC)
- The issue here is defining and measuring quantum speedup. So, we are currently in a semantic argument. The data doesn't change. Quantum annealing devices can be faster than conventional silicon devices in solving specific problems. However, if I throw more and more silicon at the problem, the silicon solution will eventually be faster than the quantum solution. 209.149.113.52 (talk) 15:47, 10 December 2015 (UTC)
What user-experience do non-Linux, non-Windows, non-Mac OSs have?
Does any "exotic" OS give a good user-experience? I mean Plan 9 or OpenBSD and any one you could think about. Are they any good from the user-experience perspective? --Scicurious (talk) 16:53, 9 December 2015 (UTC)
- "Good" is a matter of opinion. We don't do matters of opinion here. --76.69.45.64 (talk) 16:56, 9 December 2015 (UTC)
- I dispute both of your claims. Many aspects of quality can be measured. And there are lots of people around here posting their opinion. --Denidi (talk) 18:40, 9 December 2015 (UTC)
- Both Plan 9 and OpenBSD are POSIX-compatible. Therefore, they run POSIX applications, such as KDE and GNOME. The user (assuming you are referring to the meat-filled skin sack sitting in front of the computer screen) commonly uses a GUI interface. For POSIX, KDE and GNOME are the the most popular. In the end, the usability of any POSIX-compatible operating system is going to be roughly the same as any other. It is not worthwhile to make a distinction for "users". 209.149.113.52 (talk) 17:08, 9 December 2015 (UTC)
- And what makes so many more users choose Linux, and not another POSIX-compabitle OS, as their distribution? What tips the balance? --Scicurious (talk) 18:09, 9 December 2015 (UTC)
- Freedom and availability have made Linux popular. 209.149.113.52 (talk) 18:59, 9 December 2015 (UTC)
- Software range, software availability and software price (ZERO DOLLARS). By software I mean gnuplot and other applications. 175.45.116.66 (talk) 01:25, 10 December 2015 (UTC)
- This deserves a more detailed answer. A lot of software, including your example of Gnuplot, is written for POSIX, which means it will run unmodified on any POSIX-compatible system. It is true that some big proprietary programs like Oracle Database often support Linux but not other Unix family members (Oracle runs on some of the big proprietary Unixes, but not BSD). Apart from said proprietary programs, I would say the main factors behind Linux's popularity are its hardware support and the bandwagon effect. And the hardware support is itself largely a result of the bandwagon effect; if anyone is going to write device drivers for platforms other than Windows and OS X, they're probably going to pick Linux as the other platform, because it has the next largest user share. To understand why, it's useful to understand the history; Linux rapidly attracted support in the 1990s as the free Unix-like for commodity PC hardware while BSD was under the cloud of copyright infringement lawsuits, and also various community conflicts and forks. Linux avoided these potential copyright issues, being written from scratch, and avoided any large forks splitting the community. See History of Unix, History of free software, Unix wars, and I highly recommend The Art of Unix Programming for a more detailed history. --71.119.131.184 (talk) 02:53, 10 December 2015 (UTC)
- There are also lots of special purpose operating systems for applications like avionics and industrial controllers. Many of these systems present a user interface or otherwise provide "user experience." Are you interested in such single-purpose computers?
- For example, here is AVWeb's review of the user interface on the GNS530, a navigation computer designed for small airplanes. Garmin doesn't publicize the implementation of the operating system on their higher-end products (for all we know, it could be Linux-like, although that'd be hard to get certified). However, here's an article from Mentor stating that the Nucleus RTOS would be used on the Garmin CNX80, a different product. One might surmise that all of Garmin's products are built on top of similar RTOSes that are quite different from your personal computer software.
- Nimur (talk) 02:05, 10 December 2015 (UTC)
December 31, 4700
I see December 31, 4700 used as a "NULL" value for dates in databases rather often. However, it isn't a numeric limitation that I know of (that takes place in 2038, if I remember correctly). So, I just googled and I didn't find any reason to pick that particular year. Does anyone here know the reason? 209.149.113.52 (talk) 20:16, 9 December 2015 (UTC)
- December 31, 4712 AD is the highest value for a DATE field in Oracle 7: see this table. Later versions of Oracle go up to December 31, 9999. Tevildo (talk) 22:07, 9 December 2015 (UTC)
Are certificates installed in Firefox safe?
In the certificates settings I have Your Certificates, People, Servers, Authorities, Others. 1 in Your..., none in People or Servers, a full list of Authorities, and in Others I have yahoo, google, skype, addons of firefox.
Is it a security risk to install certificates here? How can I know that the certs are all OK? If a user installs a certificate from an attacker, what could the attacker do?--Denidi (talk) 23:31, 9 December 2015 (UTC)
- We need to carefully distinguish between regular certificates and root certificates. A root certificate can be used to authorize a different certificate. A malicious attacker who successfully installs a root certificate could proceed to successfully phish you: your web browser would trust any website that the attacker wanted you to trust.
- You can add new certficate authority (i.e. a new root certificate) in Firefox. This is a security risk - but only if you cannot trust the certificate you are adding.
- The other category - "regular" certificates - are in some sense less dangerous, because they don't cascade the risk down an entire chain of trust. However, if (somehow) one single certificate is compromised by an attacker, then you will trust that one attacker on that one website.
- So, what is the "risk"? Well, when your browser trusts an attacker's certificate - or, trusts a certificate signed by a compromised root authority - then your browser willingly will send encrypted data to that attacker. What data? Any data you send - like your passwords, your bank credentials, or anything else you enter on a web form when you access that specific site. The gotcha is that some web traffic also happens invisibly (without displaying any UI to you). In particular, if you have configured Firefox to save credentials, or if a website relays information to some other website in the background, or if a browser extension or software bug causes sensitive data to be sent... then the attacker could see that data.
- Certificates exist in your browser as proof that you trust something. Every time you trust anything, you are exposing yourself to some risk.
- Nimur (talk) 02:16, 10 December 2015 (UTC)