
Code page
In computing, a code page is a character encoding and as such it is a specific association of a set of printable characters and control characters with unique numbers. Typically each number represents the binary value in a single byte. (In some contexts these terms are used more precisely; see Character encoding § Terminology.)
The term "code page" originated from IBM's EBCDIC-based mainframe systems,[1] but Microsoft, SAP,[2] and Oracle Corporation[3] are among the vendors that use this term. The majority of vendors identify their own character sets by a name. In the case when there is a plethora of character sets (like in IBM), identifying character sets through a number is a convenient way to distinguish them. Originally, the code page numbers referred to the page numbers in the IBM standard character set manual,[4][5][6] a condition which has not held for a long time. Vendors that use a code page system allocate their own code page number to a character encoding, even if it is better known by another name; for example, UTF-8 has been assigned page numbers 1208 at IBM, 65001 at Microsoft, and 4110 at SAP.
Hewlett-Packard uses a similar concept in its HP-UX operating system and its Printer Command Language[7] (PCL) protocol for printers (either for HP printers or not). The terminology, however, is different: What others call a character set, HP calls a symbol set, and what IBM or Microsoft call a code page, HP calls a symbol set code. HP developed a series of symbol sets,[8][9] each with an associated symbol set code, to encode both its own character sets and other vendors’ character sets.
The multitude of character sets leads many vendors to recommend Unicode.
The code page numbering system
IBM introduced the concept of systematically assigning a small, but globally unique, 16 bit number to each character encoding that a computer system or collection of computer systems might encounter. The IBM origin of the numbering scheme is reflected in the fact that the smallest (first) numbers are assigned to variations of IBM's EBCDIC encoding and slightly larger numbers refer to variations of IBM's extended ASCII encoding as used in its PC hardware.
With the release of PC DOS version 3.3 (and the near identical MS-DOS 3.3) IBM introduced the code page numbering system to regular PC users, as the code page numbers (and the phrase "code page") were used in new commands to allow the character encoding used by all parts of the OS to be set in a systematic way.[10]

After IBM and Microsoft ceased to cooperate in the 1990s, the two companies have maintained the list of assigned code page numbers independently from each other, resulting in some conflicting assignments. At least one third-party vendor (Oracle) also has its own different list of numeric assignments.[3] IBM's current assignments are listed in their CCSID repository, while Microsoft's assignments are documented within the MSDN.[11] Additionally, a list of the names and approximate IANA (Internet Assigned Numbers Authority) abbreviations for the installed code pages on any given Windows machine can be found in the Registry on that machine (this information is used by Microsoft programs such as Internet Explorer).
Most well-known code pages, excluding those for the CJK languages and Vietnamese, fit all their code-points into eight bits and do not involve anything more than mapping each code-point to a single character; furthermore, techniques such as combining characters, complex scripts, etc., are not involved.
The text mode of standard (VGA-compatible) PC graphics hardware is built around using an 8-bit code page, though it is possible to use two at once with some color depth sacrifice, and up to eight may be stored in the display adapter for easy switching.[12] There was a selection of third-party code page fonts that could be loaded into such hardware. However, it is now commonplace for operating system vendors to provide their own character encoding and rendering systems that run in a graphics mode and bypass this hardware limitation entirely. However the system of referring to character encodings by a code page number remains applicable, as an efficient alternative to string identifiers such as those specified by the IETF and IANA for use in various protocols such as e-mail and web pages.
Relationship to ASCII
The majority of code pages in current use are supersets of ASCII, a 7-bit code representing 128 control codes and printable characters. In the distant past, 8-bit implementations of the ASCII code set the top bit to zero or used it as a parity bit in network data transmissions. When the top bit was made available for representing character data, a total of 256 characters and control codes could be represented. Most vendors (including IBM) used this extended range to encode characters used by various languages and graphical elements that allowed the imitation of primitive graphics on text-only output devices. No formal standard existed for these "extended ASCII character sets" and vendors referred to the variants as code pages, as IBM had always done for variants of EBCDIC encodings.
Relationship to Unicode
Unicode is an effort to include all characters from all currently and historically used human languages into single character enumeration (effectively one large single code page), removing the need to distinguish between different code pages when handling digitally stored text. Unicode tries to retain backwards compatibility with many legacy code pages, copying some code pages 1:1 in the design process. An explicit design goal of Unicode was to allow round-trip conversion between all common legacy code pages, although this goal has not always been achieved. Some vendors, namely IBM and Microsoft, have anachronistically assigned code page numbers to Unicode encodings. This convention allows code page numbers to be used as metadata to identify the correct decoding algorithm when encountering binary stored data.
IBM code pages
EBCDIC-based code pages
These code pages are used by IBM in its EBCDIC character sets for mainframe computers.[13]
- 1 – USA WP, Original
- 2 – USA
- 3 – USA Accounting, Version A
- 4 – USA
- 5 – USA
- 6 – Latin America
- 7 – Germany F.R. / Austria
- 8 – Germany F.R.
- 9 – France, Belgium
- 10 – Canada (English)
- 11 – Canada (French)
- 12 – Italy
- 13 – Netherlands
- 14 –
- 15 – Switzerland (French)
- 16 – Switzerland (French / German)
- 17 – Switzerland (German)
- 18 – Sweden / Finland
- 19 – Sweden / Finland WP, version 2
- 20 – Denmark/Norway
- 21 – Brazil
- 22 – Portugal
- 23 – United Kingdom
- 24 – United Kingdom
- 25 – Japan (Latin)
- 26 – Japan (Latin)
- 27 – Greece (Latin)
- 28 –
- 29 – Iceland
- 30 – Turkey
- 31 – South Africa
- 32 – Czechoslovakia (Czech / Slovak)
- 33 – Czechoslovakia
- 34 – Czechoslovakia
- 35 – Romania
- 36 – Romania
- 37 – USA/Canada - CECP (same with euro: 1140)
- 37-2 – The real 3279 APL codepage, as used by C/370. This is very close to 1047, except for caret and not-sign inverted. It is not officially recognized by IBM, even though SHARE has pointed out its existence.[14]
- 38 – USA ASCII
- 39 – United Kingdom / Israel
- 40 – United Kingdom
- 251 – China
- 252 – Poland
- 254 – Hungary
- 256 – International #1 (superseded by 500)
- 257 – International #2
- 258 – International #3
- 259 – Symbols, Set 7
- 260 – Canadian French - 116
- 264 – Print Train & Text processing extended
- 273 – Germany F.R./Austria - CECP (same with euro: 1141)
- 274 – Old Belgium Code Page
- 275 – Brazil - CECP
- 276 – Canada (French) - 94
- 277 – Denmark, Norway - CECP (same with euro: 1142)
- 278 – Finland, Sweden - CECP (same with euro: 1143)
- 279 – French - 94[14]
- 280 – Italy - CECP (same with euro: 1144)
- 281 – Japan (Latin) - CECP
- 282 – Portugal - CECP
- 283 – Spain - 190[14]
- 284 – Spain/Latin America - CECP (same with euro: 1145)
- 285 – United Kingdom - CECP (same with euro: 1146)
- 286 – Austria / Germany F.R. Alternate
- 287 – Denmark / Norway Alternate
- 288 – Finland / Sweden Alternate
- 289 – Spain Alternate
- 290 – Japanese (Katakana) Extended
- 293 – APL
- 297 – France (same with euro: 1147)[14]
- 298 – Japan (Katakana)
- 300 – Japan (Kanji) DBCS (For JIS X 0213)
- 310 – Graphic Escape APL/TN
- 320 – Hungary
- 321 – Yugoslavia
- 322 – Turkey
- 330 – International #4
- 351 – GDDM default
- 352 – Printing and publishing option
- 353 – BCDIC-A
- 355 – PTTC/BCD standard option
- 357 – PTTC/BCD H option
- 358 – PTTC/BCD Correspondence option
- 359 – PTTC/BCD Monocase option
- 360 – PTTC/BCD Duocase option
- 361 – EBCDIC Publishing International
- 363 – Symbols, set 8
- 382 – EBCDIC Publishing Austria, Germany F.R. Alternate
- 383 – EBCDIC Publishing Belgium
- 384 – EBCDIC Publishing Brazil
- 385 – EBCDIC Publishing Canada (French)
- 386 – EBCDIC Publishing Denmark, Norway
- 387 – EBCDIC Publishing Finland, Sweden
- 388 – EBCDIC Publishing France
- 389 – EBCDIC Publishing Italy
- 390 – EBCDIC Publishing Japan (Latin)
- 391 – EBCDIC Publishing Portugal
- 392 – EBCDIC Publishing Spain, Philippines
- 393 – EBCDIC Publishing Latin America (Spanish Speaking)
- 394 – EBCDIC Publishing China (Hong Kong), UK, Ireland
- 395 – EBCDIC Publishing Australia, New Zealand, USA, Canada (English)
- 410 – Cyrillic (revisions: 880, 1025, 1154)
- 420 – Arabic
- 421 – Maghreb/French
- 423 – Greek (superseded by 875)
- 424 – Hebrew (Bulletin Code)
- 425 – Arabic / Latin for OS/390 Open Edition
- 435 – Teletext Isomorphic
- 500 – International #5 (ECECP; supersedes 256) (same with euro: 1148)
- 803 – Hebrew Character Set A (Old Code)
- 829 – Host Math Symbols- Publishing
- 833 – Korean Extended (SBCS)
- 834 – Korean Hangul (KSC5601; DBCS with UDCs)
- 835 – Traditional Chinese DBCS
- 836 – Simplified Chinese Extended
- 837 – Simplified Chinese DBCS
- 838 – Thai with Low Marks & Accented Characters (same with euro: 1160)
- 839 – Thai DBCS
- 870 – Latin 2 (same with euro: 1153) (revision: 1110)
- 871 – Iceland (same with euro: 1149)[14]
- 875 – Greek (supersedes 423)
- 880 – Cyrillic (revision of 410) (revisions: 1025, 1154)
- 881 – United States - 5080 Graphics System
- 882 – United Kingdom - 5080 Graphics System
- 883 – Sweden - 5080 Graphics System
- 884 – Germany - 5080 Graphics System
- 885 – France - 5080 Graphics System
- 886 – Italy - 5080 Graphics System
- 887 – Japan - 5080 Graphics System
- 888 – France AZERTY - 5080 Graphics System
- 889 – Thailand
- 890 – Yugoslavia
- 892 – EBCDIC, OCR A
- 893 – EBCDIC, OCR B
- 905 – Latin 3
- 918 – Urdu Bilingual
- 924 – Latin 9
- 930 – Japan MIX (290 + 300) (same with euro: 1390)
- 931 – Japan MIX (37 + 300)
- 933 – Korea MIX (833 + 834) (same with euro: 1364)
- 935 – Simplified Chinese MIX (836 + 837) (same with euro: 1388)
- 937 – Traditional Chinese MIX (37 + 835) (same with euro: 1371)
- 939 – Japan MIX (1027 + 300) (same with euro: 1399)
- 1001 – MICR
- 1002 – EBCDIC DCF Release 2 Compatibility
- 1003 – EBCDIC DCF, US Text subset
- 1005 – EBCDIC Isomorphic Text Communication
- 1007 – EBCDIC Arabic (XCOM2)
- 1024 – EBCDIC T.61
- 1025 – Cyrillic, Multilingual (same with euro: 1154) (Revision of 880)
- 1026 – EBCDIC Turkey (Latin 5) (same with euro: 1155) (supersedes 905 in that country)
- 1027 – Japanese (Latin) Extended (JIS X 0201 Extended)
- 1028 – EBCDIC Publishing Hebrew
- 1030 – Japanese (Katakana) Extended
- 1031 – Japanese (Latin) Extended
- 1032 – MICR, E13-B Combined
- 1033 – MICR, CMC-7 Combined
- 1037 – Korea - 5080/6090 Graphics System
- 1039 – GML Compatibility
- 1047 – Latin 1/Open Systems[14]
- 1068 – DCF Compatibility
- 1069 – Latin 4
- 1070 – USA / Canada Version 0 (Code page 37 Version 0)
- 1071 – Germany F.R. / Austria (Code page 273 Version 0)
- 1072 – Belgium (Code page 274 Version 0)
- 1073 – Brazil (Code page 275 Version 0)
- 1074 – Denmark, Norway (Code page 277 Version 0)
- 1075 – Finland, Sweden (Code page 278 Version 0)
- 1076 – Italy (Code page 280 Version 0)
- 1077 – Japan (Latin) (Code page 281 Version 0)
- 1078 – Portugal (Code page 282 Version 0)
- 1079 – Spain / Latin America Version 0 (Code page 284 Version 0)
- 1080 – United Kingdom (Code page 285 Version 0)
- 1081 – France Version 0 (Code page 297 Version 0)
- 1082 – Israel (Hebrew)
- 1083 – Israel (Hebrew)
- 1084 – International#5 Version 0 (Code page 500 Version 0)
- 1085 – Iceland (Code page 871 Version 0)
- 1087 – Symbol Set
- 1091 – Modified Symbols, Set 7
- 1093 – IBM Logo[15]
- 1097 – Farsi Bilingual
- 1110 – Latin 2 (Revision of 870)
- 1112 – Baltic Multilingual (same with euro: 1156)
- 1113 – Latin 6
- 1122 – Estonia (same with euro: 1157)
- 1123 – Cyrillic, Ukraine (same with euro: 1158)
- 1130 – Vietnamese (same with euro: 1164)
- 1132 – Lao EBCDIC
- 1136 – Hitachi Katakana
- 1137 – Devanagari EBCDIC
- 1140 – USA, Canada, etc. ECECP (same without euro: 37) (Traditional Chinese version: 1159)
- 1141 – Austria, Germany ECECP (same without euro: 273)
- 1142 – Denmark, Norway ECECP (same without euro: 277)
- 1143 – Finland, Sweden ECECP (same without euro: 278)
- 1144 – Italy ECECP (same without euro: 280)
- 1145 – Spain, Latin America (Spanish) ECECP (same without euro: 284)
- 1146 – UK ECECP (same without euro: 285)
- 1147 – France ECECP with euro (same without euro: 297)
- 1148 – International ECECP with euro (same without euro: 500)
- 1149 – Icelandic ECECP with euro (same without euro: 871)
- 1150 – Korean Extended with box characters
- 1151 – Simplified Chinese Extended with box characters
- 1152 – Traditional Chinese Extended with box characters
- 1153 – Latin 2 Multilingual with euro (same without euro: 870)
- 1154 – Cyrillic, Multilingual with euro (same without euro: 1025; an older version is * 1166)
- 1155 – Turkey with euro (same without euro: 1026)
- 1156 – Baltic Multi with euro (same without euro: 1112)
- 1157 – Estonia with euro (same without euro: 1122)
- 1158 – Cyrillic, Ukraine with euro (same without euro: 1123)
- 1159 – T-Chinese EBCDIC (Traditional Chinese euro update of * 1140)
- 1160 – Thai with Low Marks & Accented Characters with euro (same without euro: 838)
- 1164 – Vietnamese with euro (same without euro: 1130)
- 1165 – Latin 2/Open Systems
- 1166 – Cyrillic Kazakh
- 1278 – EBCDIC Adobe (PostScript) Standard Encoding
- 1279 – Hitachi Japanese Katakana Host[6]
- 1303 – EBCDIC Bar Code
- 1364 – Korea MIX (833 + 834 + euro) (same without euro: 933)
- 1371 – Traditional Chinese MIX (1159 + 835) (same without euro: 937)
- 1376 – Traditional Chinese DBCS Host extension for HKSCS
- 1377 – Mixed Host HKSCS Growing (37 + 1376)
- 1388 – Simplified Chinese MIX (same without euro: 935) (836 + 837 + euro)
- 1390 – Simplified Chinese MIX Japan MIX (same without euro: 930) (290 + 300 + euro)
- 1399 – Japan MIX (1027 + 300 + euro) (same without euro: 939)
DOS code pages
These code pages are used by IBM in its PC DOS operating system. These code pages were originally embedded directly in the text mode hardware of the graphic adapters used with the IBM PC and its clones, including the original MDA and CGA adapters whose character sets could only be changed by physically replacing a ROM chip that contained the font. The interface of those adapters (emulated by all later adapters such as VGA) was typically limited to single byte character sets with only 256 characters in each font/encoding (although VGA added partial support for slightly larger character sets).
- 301 – IBM-PC Japan (Kanji) DBCS
- 437 – Original IBM PC hardware code page
- 720 – Arabic (Transparent ASMO)
- 737 – Greek
- 775 – Latin-7
- 808 – Russian with euro (same without euro: 866)
- 848 – Ukrainian with euro (same without euro: 1125)
- 849 – Belarusian with euro (same without euro: 1131)
- 850 – Latin-1
- 851 – Greek
- 852 – Latin-2
- 853 – Latin-3
- 855 – Cyrillic (same with euro: 872)
- 856 – Hebrew
- 857 – Latin-5
- 858 – Latin-1 with euro symbol
- 859 – Latin-9
- 860 – Portuguese
- 861 – Icelandic
- 862 – Hebrew
- 863 – Canadian French
- 864 – Arabic
- 865 – Danish/Norwegian
- 866 – Belarusian, Russian, Ukrainian (same with euro: 808)
- 867 – Hebrew + euro (based on CP862) (conflictive ID: NEC Czech (Kamenický), which was created before this codepage)
- 868 – Urdu
- 869 – Greek
- 872 – Cyrillic with euro (same without euro: 855)
- 874 – Thai with Low Tone Marks & Ancient Chars (conflictive ID with Windows 874; version with euro: 1161 Windows version: is IBM 1162)
- 876 – OCR A
- 877 – OCR B
- 878 – KOI8-R
- 891 – Korean PC SBCS
- 898 – IBM-PC WP Multilingual
- 899 – IBM-PC Symbol
- 903 – Simplified Chinese PC SBCS
- 904 – Traditional Chinese PC SBCS
- 906 – International Set #5 3812/3820
- 907 – ASCII APL (3812)
- 909 – IBM-PC APL2 Extended
- 910 – IBM-PC APL2
- 911 – IBM-PC Japan #1
- 926 – Korean PC DBCS
- 927 – Traditional Chinese PC DBCS
- 928 – Simplified Chinese PC DBCS
- 929 – Thai PC DBCS
- 932 – IBM-PC Japan MIX (DOS/V) (DBCS) (897 + 301) (conflictive ID with Windows 932; Windows version is IBM 943)
- 934 – IBM-PC Korea MIX (DOS/V) (DBCS) (891 + 926)
- 936 – IBM-PC Simplified Chinese MIX (gb2312) (DOS/V) (DBCS) (903 + 928) (conflictive ID with Windows 936; Windows version is IBM 1386)
- 938 – IBM-PC Traditional Chinese MIX (DOS/V, OS/2) (904 + 927)
- 942 – IBM-PC Japan MIX (Japanese SAA (OS/2)) (1041 + 301)
- 943 – IBM-PC Japan OPEN (897 + 941) (Windows CP 932)
- 944 – IBM-PC Korea MIX (Korean SAA (OS/2)) (1040 + 926)
- 946 – IBM-PC Simplified Chinese (Simplified Chinese SAA (OS/2)) (1042 + 928)
- 948 – IBM-PC Traditional Chinese (Traditional Chinese SAA (OS/2)) (1043 + 927)
- 949 – Korean (Extended Wansung (ks_c_5601-1987)) (1088 + 951) (conflictive ID with Windows 949 (Unified Hangul Code); Windows version is IBM 1363)
- 951 – Korean DBCS (IBM KS Code) (conflictive ID with Windows 951, a hack of Windows 950 with Unicode mappings for some PUA Unicode characters found in HKSCS, based on the file name)
- 1034 – Printer Application - Shipping Label, Set #2
- 1040 – Korean Extended
- 1041 – Japanese Extended (JIS X 0201 Extended)
- 1042 – Simplified Chinese Extended
- 1043 – Traditional Chinese Extended
- 1044 – Printer Application - Shipping Label, Set #1
- 1086 – IBM-PC Japan #1
- 1088 – Revised Korean (SBCS)
- 1092 – IBM-PC Modified Symbols
- 1098 – Farsi
- 1108 – DITROFF Base Compatibility
- 1109 – DITROFF Specials Compatibility
- 1115 – IBM-PC People's Republic of China
- 1116 – Estonian
- 1117 – Latvian
- 1118 – Lithuanian (IBM's implementation of Lika's code page 774)
- 1119 – Lithuanian and Russian (IBM's implementation of Lika's code page 772)
- 1125 – Cyrillic, Ukrainian (same with euro: 848) (IBM modification of RUSCII)
- 1127 – IBM-PC Arabic / French
- 1131 – IBM-PC Data, Cyrillic, Belarusian (same with euro: 849)
- 1139 – Japan Alphanumeric Katakana
- 1161 – Thai with Low Tone Marks & Ancient Chars with euro (same without euro: 874)
- 1167 – KOI8-RU
- 1168 – KOI8-U
- 1300 – ANSI [PTS-DOS 6.70, not 6.51]
- 1370 – Traditional Chinese MIX (Big5 encoding) (1114 + 947 + euro) (same without euro: 950)
- 1380 – IBM-PC Simplified Chinese GB PC-DATA (DBCS PC IBM GB 2312-80)
- 1381 – IBM-PC Simplified Chinese (1115 + 1380)
- 1393 – Japanese JIS X 0213 DBCS
- 1394 – IBM-PC Japan (JIS X 0213) (897 + 1393)
When dealing with older hardware, protocols and file formats, it is often necessary to support these code pages, but newer encoding systems, in particular Unicode, are encouraged for new designs.
DOS code pages are typically stored in .CPI files.[16][17][18][19][20]
IBM AIX code pages
These code pages are used by IBM in its AIX operating system. They emulate several character sets, namely those ones designed to be used accordingly to ISO, such as UNIX-like operating systems.
- 367 – 7-bit US-ASCII
- 371 – 7-bit US-ASCII APL
- 806 – ISCII
- 813 – ISO 8859-7
- 819 – ISO 8859-1
- 895 – 7-bit Japan Latin
- 896 – 7-bit Japan Katakana Extended
- 901 – Extension of ISO 8859-13 with euro (same without euro: 921)
- 902 – ISO Estonian with euro (same without euro: 922)
- 912 – Extension of ISO 8859-2
- 913 – ISO 8859-3
- 914 – ISO 8859-4
- 915 – Extension of ISO 8859-5
- 916 – ISO 8859-8
- 919 – ISO 8859-10
- 920 – ISO 8859-9
- 921 – Extension of ISO 8859-13 (same with euro: 901)
- 922 – ISO Estonian (same with euro: 902)
- 923 – ISO 8859-15
- 952 – EUC Japanese for JIS X 0208
- 953 – EUC Japanese for JIS X 0212
- 954 – EUC Japanese (895 + 952 + 896 + 953)
- 955 – TCP Japanese, JIS X 0208-1978
- 956 – TCP Japanese (895 + 952 + 896 + 953)
- 957 – TCP Japanese (895 + 955 + 896 + 953)
- 958 – TCP Japanese (367 + 952 + 896 + 953)
- 959 – TCP Japanese (367 + 955 + 896 + 953)
- 960 – Traditional Chinese DBCS-EUC SICGCC Primary Set (1st plane)
- 961 – Traditional Chinese DBCS-EUC SICGCC Full Set + IBM Select + UDC
- 963 – Traditional Chinese TCP, CNS 11643 plane 2 only
- 964 – EUC Traditional Chinese (367 + 960 + 961)
- 965 – TCP Traditional Chinese (367 + 960 + 963)
- 970 – EUC Korean (367 + 971)
- 971 – EUC Korean DBCS (G1, KSC 5601 1989 (including 188 UDC))
- 1006 – ISO 8-bit Urdu
- 1008 – ISO 8-bit Arabic
- 1009 – 7-bit ISO IRV
- 1010 – 7-bit France
- 1011 – 7-bit Germany F.R.
- 1012 – 7-bit Italy
- 1013 – 7-bit United Kingdom
- 1014 – 7-bit Spain
- 1015 – 7-bit Portugal
- 1016 – 7-bit Norway
- 1017 – 7-bit Denmark
- 1018 – 7-bit Finland/Sweden
- 1019 – 7-bit Netherlands
- 1029 – Arabic Extended
- 1036 – CCITT T.61
- 1046 – Arabic Extended (Euro)
- 1089 – ISO 8859-6
- 1111 – ISO 8859-2
- 1124 – ISO Ukrainian, similar to ISO 8859-5
- 1129 – ISO Vietnamese (same with euro: 1163)
- 1133 – ISO Lao
- 1163 – ISO Vietnamese with euro (same without euro: 1129)
- 1350 – EUC Japanese (JISeucJP) (367 + 952 + 896 + 953)
- 1382 – EUC Simplified Chinese (DBCS PC GB 2312-80)
- 1383 – EUC Simplified Chinese (367 + 1382)
Code page 819 is identical to Latin-1, ISO/IEC 8859-1, and with slightly-modified commands, permits MS-DOS machines to use that encoding. It was used with IBM AS/400 minicomputers.
IBM OS/2 code pages
These code pages are used by IBM in its OS/2 operating system.
Windows emulation code pages
These code pages are used by IBM when emulating the Microsoft Windows character sets. Most of these code pages have the same number as Microsoft code pages, although they are not exactly identical. Some code pages, though, are new from IBM, not devised by Microsoft.
- 897 – IBM-PC SBCS Japanese (JIS X 0201-1976)
- 941 – IBM-PC Japanese DBCS for Open environment
- 947 – IBM-PC DBCS for (Big5 encoding)
- 950 – Traditional Chinese MIX (Big5 encoding) (1114 + 947) (same with euro: 1370)
- 1114 – IBM-PC SBCS (Simplified Chinese; GBK; Traditional Chinese; Big5 encoding)
- 1126 – IBM-PC Korean SBCS
- 1162 – Windows Thai (Extension of 874; but still called that in Windows)
- 1169 – Windows Cyrillic Asian
- 1174 – Windows Kazakh[22]
- 1250 – Windows Central Europe
- 1251 – Windows Cyrillic
- 1252 – Windows Western
- 1253 – Windows Greek
- 1254 – Windows Turkish
- 1255 – Windows Hebrew
- 1256 – Windows Arabic
- 1257 – Windows Baltic
- 1258 – Windows Vietnamese
- 1361 – Korean (JOHAB)
- 1362 – Korean Hangul DBCS
- 1363 – Windows Korean (1126 + 1362) (Windows CP 949)
- 1372 – IBM-PC MS T Chinese Big5 encoding (Special for DB2)
- 1373 – Windows Traditional Chinese (extension of 950)
- 1374 – IBM-PC DB Big5 encoding extension for HKSCS
- 1375 – Mixed Big5 encoding extension for HKSCS (intended to match 950)
- 1385 – IBM-PC Simplified Chinese DBCS (Growing CS for GB18030, also used for GBK PC-DATA.)
- 1386 – IBM-PC Simplified Chinese GBK (1114 + 1385) (Windows CP 936)
- 1391 – Simplified Chinese 4 Byte (Growing CS for GB18030, also used for GBK PC-DATA.)
- 1392 – IBM-PC Simplified Chinese MIX (1252 + 1385 + 1391)
Macintosh emulation code pages
These code pages are used by IBM when emulating the Apple Macintosh character sets.
Adobe emulation code pages
These code pages are used by IBM when emulating the Adobe character sets.
HP emulation code pages
These code pages are used by IBM when emulating the HP character sets.
- 1050 – HP Roman Extension
- 1051 – HP Roman-8
- 1052 – HP Gothic Legal
- 1053 – HP Gothic-1 (almost the same as ISO 8859-1)
- 1054 – HP ASCII
- 1055 – HP PC-Line
- 1056 – HP Line Draw
- 1057 – HP PC-8 (almost the same as code page 437)
- 1058 – HP PC-8DN (not the same as code page 865)
- 1351 – Japanese DBCS HP character set
- 5039 – Japanese MIX (1041 + 1351)
DEC emulation code pages
These code pages are used by IBM when emulating the DEC character sets.
- 1020 – 7-bit Canadian (French) NRC Set
- 1021 – 7-bit Switzerland NRC Set
- 1023 – 7-bit Spanish NRC Set
- 1090 – Special Characters and Line Drawing Set
- 1100 – DEC Multinational
- 1101 – 7-bit British NRC Set
- 1102 – 7-bit Dutch NRC Set
- 1103 – 7-bit Finnish NRC Set
- 1104 – 7-bit French NRC Set
- 1105 – 7-bit Norwegian/Danish NRC Set
- 1106 – 7-bit Swedish NRC Set
- 1107 – 7-bit Norwegian/Danish NRC Alternate
- 1287 – DEC Greek
- 1288 – DEC Turkish
IBM Unicode code pages
- 1200 – UTF-16BE Unicode (big-endian) with IBM Private Use Area (PUA)[23]
- 1201 – UTF-16BE Unicode (big-endian)[23]
- 1202 – UTF-16LE Unicode (little-endian) with IBM PUA[23]
- 1203 – UTF-16LE Unicode (little-endian)[23]
- 1208 – UTF-8 Unicode with IBM PUA[23]
- 1209 – UTF-8 Unicode[23]
- 1400 – ISO 10646 UCS-BMP (Based on Unicode 6.0)[23]
- 1401 – ISO 10646 UCS-SMP (Based on Unicode 6.0)[23]
- 1402 – ISO 10646 UCS-SIP (Based on Unicode 6.0)[23]
- 1414 – ISO 10646 UCS-SSP (Based on Unicode 4.0)[23]
- 1445 – IBM AFP PUA No. 1
- 1446 – ISO 10646 UCS-PUP15 (Based on Unicode 4.0)[23]
- 1447 – ISO 10646 UCS-PUP16 (Based on Unicode 4.0)[23]
- 1448 – UCS-BMP (Generic UDC)
- 1449 – IBM default PUA
Microsoft code pages
Windows code pages
These code pages are used by Microsoft in its own Windows operating system. Microsoft defined a number of code pages known as the ANSI code pages (as the first one, 1252 was based on an apocryphal ANSI draft of what became ISO 8859-1). Code page 1252 is built on ISO 8859-1 but uses the range 0x80-0x9F for extra printable characters rather than the C1 control codes from ISO 6429 mentioned by ISO 8859-1.[24] Some of the others are based in part on other parts of ISO 8859 but often rearranged to make them closer to 1252.
Microsoft recommends new applications use UTF-8 or UCS-2/UTF-16 instead of these code pages.[25]
DBCS code pages
These code pages represent DBCS character encodings for various CJK languages. In Microsoft operating systems, these are used as both the "OEM" and "Windows" code page for the applicable locale.
MS-DOS code pages
These code pages are used by Microsoft in its MS-DOS operating system. Microsoft refers to these as the OEM code pages because they were defined by the original equipment manufacturers who licensed MS-DOS for distribution with their hardware, not by Microsoft or a standards organization. Most of these code pages have the same number as the equivalent IBM code pages, although some are not exactly identical.[26]
- 708 – Arabic (ASMO 708)
- 709 – Arabic (ASMO 449+/BCON V4)
- 710 – Arabic (Transparent Arabic)
- 720 – Arabic (Transparent ASMO)
- 737 – Greek
- 850 – Latin-1
- 851 – Greek
- 852 – Latin-2
- 855 – Cyrillic
- 857 – Latin-5
- 858 – Latin-1 with euro symbol
- 859 – Latin-9
- 860 – Portuguese
- 861 – Icelandic
- 862 – Hebrew
- 863 – Canadian French
- 864 – Arabic
- 865 – Danish/Norwegian
- 866 – Belarusian, Russian, Ukrainian
- 869 – Greek
Macintosh emulation code pages
These code pages are used by Microsoft when emulating the Apple Macintosh character sets.
- 10000 - Apple Macintosh Roman
- 10001 - Apple Japanese
- 10002 - Apple Traditional Chinese (Big5)
- 10003 - Apple Korean
- 10004 - Apple Arabic
- 10005 - Apple Hebrew
- 10006 - Apple Greek
- 10007 - Apple Macintosh Cyrillic
- 10008 - Apple Simplified Chinese (GB 2312)
- 10010 - Apple Romanian
- 10017 - Apple Ukrainian
- 10021 - Apple Thai
- 10029 - Apple Macintosh Central Europe
- 10079 - Apple Icelandic
- 10081 - Apple Turkish
- 10082 - Apple Croatian
Various other Microsoft code pages
The following code page numbers are specific to Microsoft Windows. IBM may use different numbers for these code pages. They emulate several character sets, namely those ones designed to be used accordingly to ISO,[clarification needed] such as UNIX-like operating systems.
- 20000 – Traditional Chinese CNS
- 20001 – Traditional Chinese TCA
- 20002 – Traditional Chinese ETEN
- 20003 – Traditional Chinese IBM5500
- 20004 – Traditional Chinese TeleText
- 20005 – Traditional Chinese Wang
- 20105 – 7-bit IA5 IRV[27][28][29] (CP 1009)
- 20106 – 7-bit IA5 German (DIN 66003)[27][28][30]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[27][28][31]
- 20108 - 7-bit IA5 Norwegian (NS 4551-2)[27][28][32]
- 20127 – 7-bit US-ASCII[27][28][33]
- 20261 – CCITT T.61
- 20269 – ISO 6937
- 20273
- 20277
- 20278
- 20284
- 20285
- 20290 - Japanese language in EBCDIC
- 20297
- 20420
- 20423
- 20424
- 20833
- 20838
- 20866 – KOI8-R
- 20871
- 20880 – EBCDIC Cyrillic (880)
- 20905
- 20924
- 20932 - EUC-JP
- 20936
- 20949
- 21025 – EBCDIC Cyrillic (1025)
- 21027
- 21866 – KOI8-U
- 28591 – ISO-8859-1
- 28592 – ISO-8859-2
- 28593 – ISO-8859-3
- 28594 – ISO-8859-4
- 28595 – ISO-8859-5
- 28596 – ISO-8859-6
- 28597 – ISO-8859-7
- 28598 – ISO-8859-8
- 28599 – ISO-8859-9
- 28600 – ISO-8859-10
- 28601 – ISO-8859-11
- 28602 – not used (reserved for ISO-8859-12)
- 28603 – ISO-8859-13
- 28604 – ISO-8859-14
- 28605 – ISO-8859-15
- 28606 – ISO-8859-16
- 38596 – ISO-8859-6
- 38598 – ISO-8859-8
Microsoft Unicode code pages
- 1200 – UTF-16LE Unicode (little-endian)
- 1201 – UTF-16BE Unicode (big-endian)
- 12000 – UTF-32LE Unicode (little-endian)
- 12001 – UTF-32BE Unicode (big-endian)
- 65000 – UTF-7 Unicode
- 65001 – UTF-8 Unicode
- 65520 – Empty Unicode Plane
HP Symbol Sets
HP developed a series of Symbol Sets (each with its associated Symbol Set Code) to encode either its own character sets or other vendors’ character sets. They are normally 7-bit character sets which, when moved to the higher part and associated with the ASCII character set, make up 8-bit character sets.
HP own Symbol Sets
- Symbol Set 0E — HP Roman Extension — 7-bit character set with accented letters (coded by IBM as code page 1050)
- Symbol Set 0G — HP 7-bit German
- Symbol Set 0L — HP 7-bit PC Line (coded by IBM as code page 1055)
- Symbol Set 0M — HP Math-7
- Symbol Set 0T — HP Thai-8
- Symbol Set 1S — HP 7-bit Spanish
- Symbol Set 1U — HP 7-bit Gothic Legal (coded by IBM as code page 1052)
- Symbol Set 4Q — HP Line Draw (coded by IBM as code page 1056)
- Symbol Set 4U — HP Roman-9 — Roman-8 + €
- Symbol Set 7J — HP Desktop
- Symbol Set 7S — HP 7-bit European Spanish
- Symbol Set 8E — HP East-8
- Symbol Set 8G — HP Greek-8 (based on IR 088; not on ELOT 927)
- Symbol Set 8H — HP Hebrew-8
- Symbol Set 8I — MS LineDraw (ASCII + HP PC Line)
- Symbol Set 8K — HP Kana-8 (ASCII + Japanese Katakana)
- Symbol Set 8L — HP LineDraw (ASCII + HP Line Draw)
- Symbol Set 8M — HP Math-8 (ASCII + HP Math-8)
- Symbol Set 8R — HP Cyrillic-8
- Symbol Set 8S — HP 7-bit Latin American Spanish
- Symbol Set 8T — HP Turkish-8
- Symbol Set 8U — HP Roman-8 (ASCII + HP Roman Extension; coded by IBM as code page 1051)
- Symbol Set 8V — HP Arabic-8
- Symbol Set 9K — HP Korean-8
- Symbol Set 9T — PC 8T (also known as Code Page 437-T; this is not code page 857)
- Symbol Set 9V — Latin / Arabic for Windows (this is not code page 1256)
- Symbol Set 11U — PC 8D/N (also known as Code Page 437-N; coded by IBM as code page 1058; this is not code page 865)
- Symbol set 14G — PC-8 Greek Alternate (also known as Code Page 437-G; almost the same as code page 737)
- Symbol Set 18K —
- Symbol Set 18T —
- Symbol Set 19C —
- Symbol Set 19K —
Symbol Sets from other vendors
- Symbol Set 0D — ISO 60: 7-bit Norwegian
- Symbol Set 0F — ISO 25: 7-bit French
- Symbol Set 0H — HP 7-bit Hebrew — Practically the same as Israeli Standard SI 960
- Symbol Set 0I — ISO 15: 7-bit Italian
- Symbol Set 0K — ISO 14: 7-bit Japanese Katakana
- Symbol Set 0N — ISO 8859-1 Latin 1 (Initially called "Gothic-1"; coded by IBM as code page 1053)
- Symbol Set 0R — ISO 8859-5 Latin/Cyrillic (1986 version — IR 111)
- Symbol Set 0S — ISO 11: 7-bit Swedish
- Symbol Set 0U — ISO 6: 7-bit U.S.
- Symbol Set 0V — Arabic
- Symbol Set 1D — ISO 61: 7-bit Norwegian
- Symbol Set 1E — ISO 4: 7-bit U. K.
- Symbol Set 1F — ISO 69: 7-bit French
- Symbol Set 1G — ISO 21: 7-bit German
- Symbol Set 1K — ISO 13: 7-bit Japanese Latin
- Symbol Set 1T — Windows Thai (Practically the same as 874)
- Symbol Set 2K — ISO 57: 7-bit Simplified Chinese Latin
- Symbol Set 2N — ISO 8859-2 Latin 2
- Symbol Set 2S — ISO 17: 7-bit Spanish
- Symbol Set 2U — ISO 2: 7-bit International Reference Version
- Symbol Set 3N — ISO 8859-3 Latin 3
- Symbol Set 3R — PC-866 Russia (Practically the same as code page 866)
- Symbol Set 3S — ISO 10: 7-bit Swedish
- Symbol Set 4N — ISO 8859-4 Latin 4
- Symbol Set 4S — ISO 16: 7-bit Portuguese
- Symbol Set 5M — PS Math Symbol (Practically the same as Adobe Symbols)
- Symbol Set 5N — ISO 8859-9 Latin 5
- Symbol Set 5S — ISO 84: 7-bit Portuguese
- Symbol Set 5T — Windows 3.1 Latin-5 (Practically the same as code page 1254)
- Symbol Set 6J — Microsoft Publishing
- Symbol Set 6M — Ventura Math
- Symbol Set 6N — ISO 8859-10 Latin 6
- Symbol Set 6S — ISO 85: 7-bit Spanish
- Symbol Set 7H — ISO 8859-8 Latin/Hebrew
- Symbol Set 9E — Windows 3.1 Latin 2 (Practically the same as code page 1250)
- Symbol Set 9G — Windows 98 Greek (Practically the same as code page 1253)
- Symbol Set 9J — PC 1004
- Symbol Set 9L — Ventura ITC Zapf Dingbats
- Symbol Set 9N — ISO 8859-15 Latin 9
- Symbol Set 9R — Windows 98 Cyrillic (Practically the same as code page 1251)
- Symbol Set 9U — Windows 3.0
- Symbol Set 10G — PC-851 Latin/Greek (Practically the same as code page 851)
- Symbol Set 10J — PS Text (Practically the same as Adobe Standard)
- Symbol Set 10L — PS ITC Zapf Dingbats (Practically the same as Adobe Dingbats)
- Symbol Set 10N — ISO 8859-5 Latin/Cyrillic (1988 version — IR 144)
- Symbol Set 10R — PC-855 Cyrillic (Practically the same as code page 855)
- Symbol Set 10T — Teletex
- Symbol Set 10U — PC-8 (Practically the same as code page 437; coded by IBM as code page 1057)
- Symbol Set 10V — CP-864 (Practically the same as code page 864)
- Symbol Set 11G — CP-869 (Practically the same as code page 869)
- Symbol Set 11J — PS ISO Latin-1 (Practically the same as Adobe Latin-1)
- Symbol Set 11N — ISO 8859-6 Latin/Arabic
- Symbol Set 12G — PC Latin/Greek (Practically the same as code page 737)
- Symbol Set 12J — MC Text (Practically the same as Macintosh Roman)
- Symbol Set 12N — ISO 8859-7 Latin/Greek
- Symbol Set 12R — PC Gost (Practically the same as PC GOST Main)
- Symbol Set 12U — PC-850 Latin 1 (Practically the same as code page 850)
- Symbol Set 13J — Ventura International
- Symbol Set 13R — PC Bulgarian (Practically the same as MIK)
- Symbol Set 13U — PC-858 Latin 1 + € (Practically the same as code page 858)
- Symbol Set 14J — Ventura U. S.
- Symbol Set 14L — Windows Dingbats
- Symbol Set 14P — ABICOMP International (Practically the same as ABICOMP)
- Symbol Set 14R — PC Ukrainian (Practically the same as RUSCII)
- Symbol Set 15H — PC-862 Israel (Practically the same as code page 862)
- Symbol Set 16U — PC-857 Latin 5 (Practically the same as code page 857)
- Symbol Set 17U — PC-852 Latin 2 (Practically the same as code page 852)
- Symbol Set 18N — UTF-8
- Symbol Set 18U — PC-853 Latin 3 (Practically the same as code page 853)
- Symbol Set 19L — Windows 98 Baltic (Practically the same as code page 1257)
- Symbol Set 19M — Windows Symbol
- Symbol Set 19U — Windows 3.1 Latin 1 (Practically the same as code page 1252)
- Symbol Set 20U — PC-860 Portugal (Practically the same as code page 860)
- Symbol Set 21U — PC-861 Iceland (Practically the same as code page 861)
- Symbol Set 23U — PC-863 Canada - French (Practically the same as code page 863)
- Symbol Set 24Q — PC-Polish Mazowia (Practically the same as Mazovia encoding)
- Symbol Set 25U — PC-865 Denmark/Norway (Practically the same as code page 865)
- Symbol Set 26U — PC-775 Latin 7 (Practically the same as code page 775)
- Symbol Set 27Q — PC-8 PC Nova (Practically the same as PC Nova)
- Symbol Set 27U — PC Latvian Russian (also known as 866-Latvian)
- Symbol Set 28U — PC Lithuanian/Russian (Practically the same as code page 774)
- Symbol Set 29U — PC-772 Lithuanian/Russian (Practically the same as code page 772)
Code pages from other vendors
These code pages are independent assignments by third party vendors. Since the original IBM PC code page (number 437) was not really designed for international use, several partially compatible country or region specific variants emerged.
These code pages number assignments are not official neither by IBM, neither by Microsoft and almost none of them is referred as a usable character set by IANA. The numbers assigned to these code pages are arbitrary and may clash to registered numbers in use by IBM or Microsoft. Some of them may predate codepage switching being added in DOS 3.3.
- 100 – DOS Hebrew hardware fontpage (Not from IBM; HDOS)[34]
- 111 – DOS Greek (Not from IBM; AST Premium Exec DOS 5.0[35][36][37])
- 112 – DOS Turkish (Not from IBM; AST Premium Exec DOS 5.0[35][36][37])
- 113 – DOS Yugoslavian (Not from IBM; AST Premium Exec DOS 5.0[35][36][37])
- 151 – DOS Nafitha Arabic (Not from IBM; ADOS)
- 152 – DOS Nafitha Arabic (Not from IBM; ADOS)
- 161 – DOS Arabic (Not from IBM; ADOS)[34]
- 162 – DOS Arabic (Not from IBM; ADOS)
- 163 – DOS Arabic (Not from IBM; ADOS)[34]
- 164 – DOS Arabic (Not from IBM; ADOS)
- 165 – DOS Arabic (Not from IBM; ADOS)[34]
- 166 – IBM Arabic PC (ADOS)[34]
- 190 – DEC DOS German (appears to be identical to Code page 437)
- 210 – DEC DOS Greek (NEC Jetmate printers)
- 220 – DEC DOS Spanish (Not from IBM)
- 489 – Czechoslovakian [OCR software 1993]
- 620 – DOS Polish (Mazovia) (Not from IBM)
- 667 – DOS Polish (Mazovia) (Not from IBM)
- 668 – DOS Polish (Not from IBM)
- 706 – MS-DOS Server Arabic Sakhr (Not from IBM; Sakhr Software from MSX Computers)
- 707 – MS-DOS Arabic Sakhr (Not from IBM; Sakhr Software from MSX Computers)
- 711 – MS-DOS Arabic Nafitha Enhanced (Not from IBM)
- 714 – MS-DOS Arabic Sakr (Not from IBM)
- 715 – MS-DOS Arabic APTEC (Not from IBM)
- 721 – MS-DOS Arabic Nafitha International (Not from IBM)
- 768 – Arabic Al-Arabi (Not from IBM)
- 770 – DOS Estonian, Latvian, Lithuanian[38] (From Lithuanian Lika Software;[39] Lithuanian RST 1095-89 National Standard)
- 771 – DOS Lithuanian/Cyrillic — KBL[40] (From Lithuanian Lika Software[39])
- 772 – DOS Lithuanian/Cyrillic[41] (From Lithuanian Lika Software;[39] Lithuanian LST 1284:1993 National Standard; adopted by IBM as code page 1119)
- 773 – DOS Latin-7 — KBL (From Lithuanian Lika Software)
- 774 – DOS Lithuanian[42] (From Lithuanian Lika Software;[39] Lithuanian LST 1283:1993 National Standard; adopted by IBM as code page 1118)
- 775 – DOS Latin-7 Baltic Rim (From Lithuanian Lika Software;[39] Lithuanian LST 1590-1 National Standard; adopted by IBM and Microsoft as code page 775)
- 776 – DOS Lithuanian (extended CP770)[43] (From Lithuanian Lika Software[39])
- 777 – DOS Accented Lithuanian (old) (extended CP773) — KBL[43] (From Lithuanian Lika Software[39])
- 778 – DOS Accented Lithuanian (extended CP775)[43] (From Lithuanian Lika Software[39])
- 790 – DOS Polish (Mazovia)
- 854 – Spanish[44][6]
- 881 – Latin 1 (Not from IBM; AST Premium Exec DOS 5.0[35][36][37]) (conflictive ID with IBM EBCDIC 881)
- 882 – Latin 2 (ISO 8859-2) (Not from IBM; same as Code page 912; AST Premium Exec DOS 5.0[35][36][37]) (conflictive ID with IBM EBCDIC 882)
- 883 – Latin 3 (Not from IBM; AST Premium Exec DOS 5.0[35][36][37]) (conflictive ID with IBM EBCDIC 883)
- 884 – Latin 4 (Not from IBM; AST Premium Exec DOS 5.0[35][36][37]) (conflictive ID with IBM EBCDIC 884)
- 885 – Latin 5 (Not from IBM; AST Premium Exec DOS 5.0[35][36][37]) (conflictive ID with IBM EBCDIC 885)
- 895 – Czech (Kamenický), (Not from IBM; conflictive ID with IBM CP895 — 7-bit EUC Japanese Roman)
- 896 – DOS Polish (Mazovia) (Not from IBM; conflictive ID with IBM CP896 — 7-bit EUC Japanese Katakana)
- 900 – DOS Russian (Russian MS-DOS 5.0 LCD.CPI)
- 928 – Greek (on Star[45] printers); same as Greek National Standard ELOT 928 (Not from IBM; conflictive ID with IBM CP928 — Simplified Chinese PC DBCS)
- 966 – Saudi Arabian (Not from IBM)
- 991 – DOS Polish (Mazovia) (Not from IBM)
- 999 – DOS Serbo-Croatian I (Not from IBM); also known as PC Nova and CroSCII; lower part is JUSI.B1.002, upper part is code page 437; supports Slovenian and Serbo-Croatian (Latin script)
- 1001 – Arabic (on Star[45] printers) (Not from IBM; conflictive ID with IBM CP1001 — MICR)
- 1261 – Windows Korean IBM-1261 LMBCS-17, similar to 1363
- 1270 – Windows Sámi
- 2001 – Lithuanian KBL (on Star[45] printers); same as code page 771
- 3001 – Estonian 1 (on Star[45] printers); same as code page 1116
- 3002 – Estonian 2 (on Star[45] printers); same as code page 922
- 3011 – Latvian 1 (on Star[45] printers); same as code page 437-Latvian
- 3012 – Latvian-2 (on Star[45] printers); same as code page 866-Latvian (Latvian RST 1040-90 National Standard)
- 3021 – Bulgarian (on Star[45] printers); same as MIK
- 3031 – Hebrew (on Star[45] printers); same as code page 862
- 3041 – Maltese (on Star[45] printers); same as ISO 646 Maltese
- 3840 – IBM-Russian (on Star[45] printers); nearly the same as CP 866
- 3841 – Gost-Russian (on Star[45] printers); GOST 13052 plus characters for Central Asian languages
- 3843 – Polish (on Star[45] printers); same as Mazovia
- 3844 – CS2 (on Star[45] printers); same as Kamenický
- 3845 – Hungarian (on Star[45] printers); same as CWI
- 3846 – Turkish (on Star[45] printers); same as PC-8 Turkish + old Turkish Lira sign (Tʟ) at code point A8
- 3847 – Brazil-ABNT (on Star[45] printers); same as the Brazilian National Standard NBR-9614:1986
- 3848 – Brazil-ABICOMP (on Star[45] printers); same as ABICOMP
- 3850 – Standard KU (on Star[45] printers); variation of the Kasetsart University encoding for Thai
- 3860 – Rajvitee KU (on Star[45] printers); variation of the Kasetsart University encoding for Thai
- 3861 – Microwiz KU (on Star[45] printers); variation of the Kasetsart University encoding for Thai
- 3863 – STD988 TIS (on Star[45] printers); variation of the TIS 620 encoding for Thai
- 3864 – Popular TIS (on Star[45] printers); variation of the TIS 620 encoding for Thai
- 3865 – Newsic TIS (on Star[45] printers); variation of the TIS 620 encoding for Thai
- 28799 – FOCAL (on Star[45] printers); same as FOCAL character set
- 28800 – HP RPL (on Star[45] printers); same as RPL
- (number missing) – CWI-2 (for DOS) supports Hungarian
- (number missing) – MIK (for DOS) supports Bulgarian
- (number missing) – DOS Serbo-Croatian II; supports Slovenian and Serbo-Croatian (Latin script)
- (number missing) — Russian Alternative code page (for DOS); this is the origin for IBM CP 866
List of code page assignments
List of known code page assignments (incomplete):
| ID | Names | Description | Origin | Platform | DOS | OS/2 | Windows | Mac | Else | Encoding | Comment |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | N/A | Reserved | IBM, Microsoft | N/A | 3.3+ | 1.0+ | ? | ? | ? | Internal OS use[34] | |
| 437 | CP437, IBM437 | PC US | IBM[46] | IBM PC | 3.3+ | 1.0+ | Yes | ? | Yes | 8-bit SBCS | |
| 57344 - 61439 | N/A | Private use derivations | IBM | N/A | N/A | N/A | N/A | N/A | N/A | various | Private use code page derivations (E000h-EFFFh) |
| 65280 - 65533 | N/A | Private use definitions | IBM | N/A | N/A | N/A | N/A | N/A | N/A | various | Private use code page definitions (FF00h-FFFDh) |
| 65534 | N/A | Reserved | IBM, Microsoft | N/A | ? | ? | ? | ? | ? | various | Internal OS use (FFFEh) |
| 65535 | N/A | Reserved | IBM, Microsoft | N/A | 3.3+ | 1.0+ | ? | ? | ? | various | Internal OS use (FFFFh)[34] |
Criticism
Many older character encodings (unlike Unicode) suffer from several problems. Some vendors insufficiently document the meaning of all code point values in their code pages, which decreases the reliability of handling textual data consistently through various computer systems. Some vendors add proprietary extensions to established code pages, to add or change certain code point values: for example, byte 0x5C in Shift JIS can represent either a back slash or a yen currency symbol depending on the platform. Finally, in order to support several languages in a program that does not use Unicode, the code page used for each string/document needs to be stored.
Applications may also mislabel text in Windows-1252 as ISO-8859-1. The only difference between these code pages is that the code point values in the range 0x80–0x9F, used by ISO-8859-1 for control characters, are instead used as additional printable characters in Windows-1252 – notably for quotation marks, the euro sign and the trademark symbol among others. Browsers on non-Windows platforms would tend to show empty boxes or question marks for these characters, making the text hard to read. Most browsers fixed this by ignoring the character set and interpreting as Windows-1252 to look acceptable. In HTML5, treating ISO-8859-1 as Windows-1252 is even codified as a W3C standard.[47] Although browsers were typically programmed to deal with this behaviour, this was not always true of other software. Consequently, when receiving a file transfer from a Windows system, non-Windows platforms would either ignore these characters or treat them as a standard control characters and attempt to take the specified control action accordingly.
Due to Unicode's extensive documentation, vast repertoire of characters and stability policy of characters, the problems listed above are rarely a concern for Unicode. UTF-8 (which can encode over one million codepoints) has replaced the code-page method in terms of popularity on the Internet.[48][49]
Private code pages
When, early in the history of personal computers, users did not find their character encoding requirements met, private or local code pages were created using terminate-and-stay-resident utilities or by re-programming BIOS EPROMs. In some cases, unofficial code page numbers were invented (e.g. CP895).
When more diverse character set support became available most of those code pages fell into disuse, with some exceptions such as the Kamenický or KEYBCS2 encoding for the Czech and Slovak alphabets. Another character set is Iran System encoding standard that was created by Iran System corporation for Persian language support. This standard was in use in Iran in DOS-based programs and after introduction of Microsoft code page 1256 this standard became obsolete. However some Windows and DOS programs using this encoding are still in use and some Windows fonts with this encoding exist.
In order to overcome such problems, the IBM Character Data Representation Architecture level 2 specifically reserves ranges of code page IDs for user-definable and private-use assignments. Whenever such code page IDs are used, the user must not assume that the same functionality and appearance can be reproduced in another system configuration or on another device or system unless the user takes care of this specifically. The code page range 57344-61439 (E000h-EFFFh) is officially reserved for user-definable code pages (or actually CCSIDs in the context of IBM CDRA), whereas the range 65280-65533 (FF00h-FFFDh) is reserved for any user-definable "private use" assignments. For example, a non-registered custom variant of code page 437 (1B5h) or 28591 (6FAF) could become 57781 (E1B5h) or 61359 (EFAFh), respectively, in order to avoid potential conflicts with other assignments and maintain the sometimes existing internal numerical logic in the assignments of the original code pages. An unregistered private code page not based on an existing code page, a device specific code page like a printer font, which just needs a logical handle to become addressable for the system, a frequently changing download font, or a code page number with a symbolic meaning in the local environment could have an assignment in the private range like 65280 (FF00h).
The code page IDs 0, 65534 (FFFEh) and 65535 (FFFFh) are reserved for internal use by operating systems such as DOS and must not be assigned to any specific code pages.
See also
- Windows code page
- Character encoding
- CCSID IBM's official "code page" definitions and assignments
- Charset detection
- Unicode
References
- ^ "Contents". www.ibm.com.
- ^ "Code Page". sap.com. Archived from the original on 2009-11-14. Retrieved 2009-08-08.
- ^ a b "Glossary". oracle.com. Archived from the original on 2011-09-30. Retrieved 2009-08-08.
- ^ "VT510 Video Terminal Programmer Information". Digital Equipment Corporation (DEC). 7.1. Character Sets - Overview. Archived from the original on 2016-01-26. Retrieved 2017-02-15.
In addition to traditional DEC and ISO character sets, which conform to the structure and rules of ISO 2022, the VT510 supports a number of IBM PC code pages (page numbers in IBM's standard character set manual) in PCTerm mode to emulate the console terminal of industry-standard PCs.
- ^ "7.1. Character Sets - Overview". VT520/VT525 Video Terminal Programmer Information (PDF). Digital Equipment Corporation (DEC). July 1994. p. 7-1. EK-VT520-RM. A01. Archived (PDF) from the original on 2017-02-15. Retrieved 2017-02-15.
In addition to traditional DEC and ISO character sets the VT520 supports a number of IBM PC code pages (which refer to page numbers in IBM's standard character set manual) in PCTerm mode to emulate the console terminal of industry-standard PCs.
- ^ a b c Paul, Matthias R. (2001-06-10) [1995]. "Overview on DOS, OS/2, and Windows codepages" (CODEPAGE.LST file) (1.59 preliminary ed.). Archived from the original on 2016-04-20. Retrieved 2016-08-20.
- ^ "Printer Command Language Symbol Sets". www.pclviewer.com. Archived from the original on 2020-07-31. Retrieved 2021-05-25.
- ^ "HP Symbol Sets". pclhelp.com. Archived from the original on 2015-02-19. Retrieved 2017-02-20.
- ^ "PCL5 Camparison Guide" (PDF). Archived (PDF) from the original on 2017-02-21. Retrieved 2017-02-20.
- ^ Zbikowski, Mark; Allen, Paul; Ballmer, Steve; Borman, Reuben; Borman, Rob; Butler, John; Carroll, Chuck; Chamberlain, Mark; Chell, David; Colee, Mike; Courtney, Mike; Dryfoos, Mike; Duncan, Rachel; Eckhardt, Kurt; Evans, Eric; Farmer, Rick; Gates, Bill; Geary, Michael; Griffin, Bob; Hogarth, Doug; Johnson, James W.; Kermaani, Kaamel; King, Adrian; Koch, Reed; Landowski, James; Larson, Chris; Lennon, Thomas; Lipkie, Dan; McDonald, Marc; McKinney, Bruce; Martin, Pascal; Mathers, Estelle; Matthews, Bob; Melin, David; Mergentime, Charles; Nevin, Randy; Newell, Dan; Newell, Tani; Norris, David; O'Leary, Mike; O'Rear, Bob; Olsson, Mike; Osterman, Larry; Ostling, Ridge; Pai, Sunil; Paterson, Tim; Perez, Gary; Peters, Chris; Petzold, Charles; Pollock, John; Reynolds, Aaron; Rubin, Darryl; Ryan, Ralph; Schulmeisters, Karl; Shah, Rajen; Shaw, Barry; Short, Anthony; Slivka, Ben; Smirl, Jon; Stillmaker, Betty; Stoddard, John; Tillman, Dennis; Whitten, Greg; Yount, Natalie; Zeck, Steve (1988). "Technical advisors". The MS-DOS Encyclopedia: versions 1.0 through 3.2. By Duncan, Ray; Bostwick, Steve; Burgoyne, Keith; Byers, Robert A.; Hogan, Thom; Kyle, Jim; Letwin, Gordon; Petzold, Charles; Rabinowitz, Chip; Tomlin, Jim; Wilton, Richard; Wolverton, Van; Wong, William; Woodcock, JoAnne (Completely reworked ed.). Redmond, Washington, USA: Microsoft Press. ISBN 1-55615-049-0. LCCN 87-21452. OCLC 16581341. [1] Archived 2018-10-14 at the Wayback Machine (xix+1570 pages; 26 cm) (NB. This edition was published in 1988 after extensive rework of the withdrawn 1986 first edition by a different team of authors.)
- ^ "Code Page Identifiers". microsoft.com. Microsoft. Archived from the original on 2014-10-27. Retrieved 2014-10-27.
- ^ "VGA/SVGA Video Programming--VGA Text Mode Operation". osdever.net. Archived from the original on 2010-09-01. Retrieved 2006-09-23.
- ^ "IBM i Globalization: Code Pages". IBM. Archived from the original on 2012-07-16.
- ^ a b c d e f xlate - Transliterate Contents of Records, IBM Corporation, 2010 [1986], archived from the original on 2019-06-16, retrieved 2016-10-18
- ^ "Code Page CPGID 01093 (pdf)" (PDF). Archived from the original (PDF) on 2015-07-08.
- ^ Paul, Matthias R. (2001-06-10) [1995]. "Format description of DOS, OS/2, and Windows NT .CPI, and Linux .CP files" (CPI.LST file) (1.30 ed.). Archived from the original on 2016-04-20. Retrieved 2016-08-20.
- ^ Elliott, John C. (2006-10-14). "CPI file format". Seasip.info. Archived from the original on 2016-09-22. Retrieved 2016-09-22.
- ^ Brouwer, Andries Evert (2001-02-10). "CPI fonts". 0.2. Archived from the original on 2016-09-22. Retrieved 2016-09-22.
- ^ Haralambous, Yannis (September 2007). Fonts & Encodings. Translated by Horne, P. Scott (1 ed.). Sebastopol, California, USA: O'Reilly Media, Inc. pp. 601–602, 611. ISBN 978-0-596-10242-5.
- ^ MS-DOS Programmer's Reference. Microsoft Press. 1991. ISBN 1-55615-329-5.
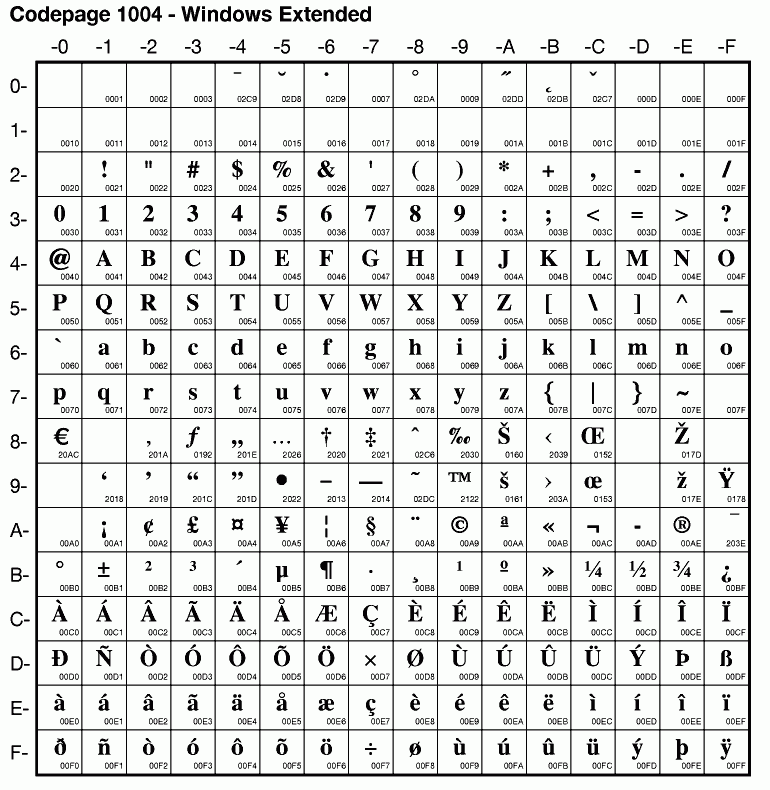
- ^ "Codepage 1004 - Windows Extended". IBM. 2001. Archived from the original on 2018-05-13. Retrieved 2018-05-13.
- ^ "Character Data Representation Architecture". IBM. Archived from the original on 2019-06-23. Retrieved 2019-10-12.
- ^ a b c d e f g h i j k l "IBM Coded Character Set Identifier (CCSID)". IBM. Archived from the original on 2009-11-26.
- ^ ISO/IEC 8859-1:1998(E). ISO. 1998-04-15. p. 1. Archived from the original on 2020-10-30. Retrieved 2020-10-30.
The coded characters in this set may be used in conjunction with coded control functions selected from ISO/IEC 6429.
- ^ "Code Pages". microsoft.com. Microsoft. Archived from the original on 2011-02-27. Retrieved 2010-12-21.
- ^ "pentaho/pentaho-reporting". GitHub. Archived from the original on 2019-06-16. Retrieved 2017-02-20.
- ^ a b c d e "Code Page Identifiers". Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e "Web Encodings - Internet Explorer - Encodings". WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Western European (IA5) encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "German (IA5) encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Swedish (IA5) encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "Norwegian (IA5) encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. "US-ASCII encoding - Windows charsets". WUtils.com - Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ a b c d e f g Paul, Matthias R. (2002-09-05), Technical info on undocumented DOS country info for LCASE, ARAMODE and CCTORC records, FreeDOS development list fd-dev at Topica, archived from the original on 2016-05-27, retrieved 2016-05-26
- ^ a b c d e f g h Brown, Ralf D. (2002-12-29). The x86 Interrupt List. 61.
- ^ a b c d e f g h Paul, Matthias R. (1997-07-30). NWDOS-TIPs — Tips & Tricks rund um Novell DOS 7, mit Blick auf undokumentierte Details, Bugs und Workarounds. MPDOSTIP (in German) (3 ed.). Archived from the original on 2016-05-22. Retrieved 2012-01-11. (NB. NWDOSTIP.TXT is a comprehensive work on Novell DOS 7 and OpenDOS 7.01, including the description of many undocumented features and internals. It is part of the author's yet larger MPDOSTIP.ZIP collection maintained up to 2001 and distributed on many sites at the time. The provided link points to a HTML-converted older version of the NWDOSTIP.TXT file.)
- ^ a b c d e f g h Paul, Matthias R. (2001-04-09). NWDOS-TIPs — Tips & Tricks rund um Novell DOS 7, mit Blick auf undokumentierte Details, Bugs und Workarounds. MPDOSTIP (in German) (3 ed.).
- ^ "770". Archived from the original on 2017-02-26. Retrieved 2017-02-25. From Lithuanian Lika Software
- ^ a b c d e f g h "LIKIT". www.likit.lt. Archived from the original on 2017-04-19. Retrieved 2017-02-25.
- ^ "771". Archived from the original on 2017-02-26. Retrieved 2017-02-25. From Lithuanian Lika Software
- ^ "772". Archived from the original on 2017-02-26. Retrieved 2017-02-25. From Lithuanian Lika Software
- ^ "774". Archived from the original on 2017-02-26. Retrieved 2017-02-25. From Lithuanian Lika Software
- ^ a b c "lietuvybė.lt - Rašmenų koduotės" [lietuvybė.lt - Character encodings] (in Lithuanian). Archived from the original on 2019-08-28. Retrieved 2019-08-28.
- ^ Hogan, Thom (1992). Die PC-Referenz für Programmierer (in German) (2 ed.). Systhema Verlag GmbH. ISBN 3-89390-272-4. (NB. This book is the German translation of "The Programmer's PC Sourcebook" by Microsoft Press. It mentions the code page ID 854 for Spain.)
- ^ a b c d e f g h i j k l m n o p q r s t u v w x y z "Star LC 8021 User's Manual" (PDF). Archived (PDF) from the original on 2020-09-29. Retrieved 2017-02-20.
- ^ IBM. "SBCS code page information document - CPGID 00437". Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ "Encoding". WHATWG. 2015-01-27. sec. 4.2 Names and labels. Archived from the original on 2015-02-04. Retrieved 2015-02-04.
- ^ "Usage Statistics of Character Encodings for Websites, (updated daily)". w3techs.com. Retrieved 2015-08-06.
- ^ "UTF-8 Usage Statistics". trends.builtwith.com. Archived from the original on 2011-03-24. Retrieved 2011-03-28.
{kind=link}
{kind=link}
External links
- IBM CDRA glossary
- IBM code pages at the Wayback Machine (archived 2016-02-05)
- IBM code pages by encoding scheme at the Wayback Machine (archived 2009-09-06)
- IBM/ICU Charset Information
- Microsoft Code Page Identifiers (Microsoft's list contains only code pages actively used by normal apps on Windows. See also Torsten Mohrin's list for the full list of supported code pages)
- Shorter Microsoft list containing only the ANSI and OEM code pages but with links to more detail on each at the Wayback Machine (archived 2012-10-23)
- Character Sets And Code Pages At The Push Of A Button
- Microsoft Chcp command: Display and set the console active code page
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |