
User talk:Aeusoes1: Difference between revisions
→Ref tag: new section |
Demonym |
||
| Line 682: | Line 682: | ||
[[User:Peter Isotalo|Peter]] <sup>[[User talk:Peter Isotalo|Isotalo]]</sup> 15:52, 16 June 2008 (UTC) |
[[User:Peter Isotalo|Peter]] <sup>[[User talk:Peter Isotalo|Isotalo]]</sup> 15:52, 16 June 2008 (UTC) |
||
== Changes to Demonym == |
|||
I've deleted the reference to Macedonia in this article, and explained my reasons in Discussion -- as I perhaps should have done in the first instance. |
|||
I'm concerned that this article's very interesting essentially non-political linguistic aspect not become buried in a wealth of politically-based (and often very transitory) group claims to special treatment, territory, self-governance and so on. The article is about what people chose to call themselves, and what others chose to call them. |
|||
The point that people choose to fight about it...well...people will fight about many things. That doesn't change the nature of the thing, itself. |
|||
[[Special:Contributions/24.130.19.207|24.130.19.207]] ([[User talk:24.130.19.207|talk]]) 22:43, 27 June 2008 (UTC) |
|||
Revision as of 22:43, 27 June 2008
IPA
Must you update all my words ?
--84.42.196.104 15:16, 2 December 2007 (UTC)
- Most of the pages that you've edited (those on consonants and vowels) have specific table guidelines. I monitor those pages to make sure that they keep with such guidelines. So it has very little to do with you and more to do with those pages. Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 20:37, 2 December 2007 (UTC)
- Why you erase my words ? --El Quebrado (talk) 15:30, 19 January 2008 (UTC)
Transliterations
Okay. I wasn't sure why a transcription was given for Chinese and Japanese, but not for Russian, Hindi, Arabic or Greek, so I added it. But I think you're right. I plan to review the example charts for all the other IPA characters in the close future and maybe also to add a few languages here and there. Thanks for telling me. — N-true 15:18, 3 December 2007 (UTC)
Cape Verdean Creole phonetics
Hi there, Aeusoes1! I’m sorry to revert your changes in Cape Verdean Creole, but it was necessary. I can even agree with those cool little stuff (like the {{IPA| }} and so on) that you can always insert again, but other things are just wrong:
- You have elliminated the [l]. That’s serious!
- You have changed the [w] from “labio-velar” to “velar”. A velar approximant is a different sound.
- You have put the dentals and the alveolars in the same collumn. They are not the same thing! You can check that in the Santiago dialect some of those consonants are alveolar, and not dental. O. K., you can always say that is a phonetic variation and not different phonemes, but still, the general phoneme in Cape Verdean Creole is dental, that’s why I've chosen to put “dental” in the table. Besides, if the strategy is to join collumns, one should be coherent. In the same way that the dentals and the alveolars were joined, the bilabials and the labiodentals could be put together also, the post-alveolars and the palatals could be put together, and so on. Either we specify or either we simplify!
- The tables were meant to show phones rather than phonemes. I can understand why you have put the sounds [r] and [ʁ] between brackets, but among Cape Verdean linguists the phoneme is generally represented by /ʀ/, not by /r/.
I’m not sure if each sound should link to the corresponding article, though. See you!
Ten Islands (talk) 05:59, 12 December 2007 (UTC)
- I see that you have chosen to simplify rather than specify. Perhaps you want to take a look in the corresponding article in the Portuguese Wikipedia. In the Cape Verdean Creole article I’ve taken the approach of Veiga (Diskrison Strutural di Lingua Kabuverdianu — 1982) in which he has a simplified table (also grouping plosives and affricates). But in the Cape Verdean Creole Phonology article I’ve chosen to take the approach of Tude (Fonética do crioulo cabo-verdiano — 1995) which is much more specified (if I remember correctly, his work is more about phonetics than phonology).
However, I still think that the phoneme /w/ should be grouped with the labials. At least that’s the interpretation of some Cape Verdean Creole schollars.
Ten Islands (talk) 13:09, 15 December 2007 (UTC)- Hmm. I'm really not a big fan of putting /w/ with labials because I see the labialization as secondary, but maybe that's my own bias. Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 19:28, 15 December 2007 (UTC)
IPA
Hey, You seem like an expert on the subject, so I've a question. Anyway that I can self-teach IPA? Regards, Kerem Özcan (talk) 11:58, 16 December 2007 (UTC)
- Thanks for the advices (and the quick reply) Regards, Kerem Özcan (talk) 21:05, 16 December 2007 (UTC)
Brazilian Portuguese
Hi. I see no reason why you couldn't add it to both the Brazilian Portuguese and the Portuguese phonology articles (and perhaps to Portuguese dialects, as well), in the External Links section. You could try to send me an e-mail, though I seem to be having problems with e-mails. I tried to e-mail another Wikipedian several times, but it doesn't seem to have got through... Thanks and happy holidays. FilipeS (talk) 17:59, 27 December 2007 (UTC)
just thought i'd ask
Hey I Don't know you, but somehow I came upon your user page (through reference desk, you answered a question in the language section). I noticed you are an English major. I am a senior in high school and I am writing my college essays. Would be interested in proofreading one of them (prompt: literature work that influenced you)? I would appreciate it, especially since this request is out of the blue. email me [email address removed]
--n1yaNt 00:41, 28 December 2007 (UTC)
Hi Aeusoes1, why did you delete Manner of articulation from retroflexes in the Sanskrit article? —Preceding unsigned comment added by Klimov (talk • contribs) 14:35, 2 January 2008 (UTC)
- Would you please look at the first 2 paragraphs of the following page: http://sanskritdocuments.org/learning_tutorial_wikner/P003.html. It seems to me, it clearly recommends to articulate the retroflexes as apical palatal and apical dental approximants.
- Do you think it's not correct?
- --Klimov (talk) 11:48, 3 January 2008 (UTC)
- Hmm... You don't like the source. That I do understand.
- I am curious why you don't like the introductory.
- Could you recommend a better one that describes in detail the Sanskrit manner of articulation?
- Also, why did you just delete the info and didn't change to what you consider to be correct?
- --Klimov (talk) 18:47, 4 January 2008 (UTC)
- It doesn't seem to be good enough reason to delete information solely based on the fact that articles on other languages don't contain something like that.
- You admitted that you don't know enough and you did not recommend another, more reliable source.
- It seems to me that your deletion borders on vandalism.
- Probably I will restore the information and take the discussion to the Sanskrit talk page.
- --Klimov (talk) 12:32, 5 January 2008 (UTC)
Merger
I'd have merged the other direction. International Phonetic Alphabet for English is actually laid out like an encyclopedia article and is fairly easy to read. IPA chart for English is very "table-y" and has largely been supplanted in its original function by Help:Pronunciation. —Angr If you've written a quality article... 08:56, 3 January 2008 (UTC)
Some comments
Dear Aeuoes1,
I saw you had reverted my edition on Spanish orthography article. I think it is not too correct linking articles from other language Wikipedias which are not about exactly the same topic. Spanish ortography are the academical rules for Spanish writing and not the alphabet and pronunciation. In Hungarian Wikipedia, a robot always puts a lot of wrong iw links into my article about Spanish ortography (because in the English version it's wrong) and they are linking to articles about "Spanish Alphabet" (but not Spanish orthography), while for "Spanish Alphabet" we have an own, separated article. That's why I always have to revert robot iw editions on my article in hu-wiki. Could you please help me how to solve the problem, then? Thank you very much in advance and happy new year. --TheMexican (talk) 19:29, 3 January 2008 (UTC)
- Thank you, let's see what will robots do now. One more pleasure, could you please add the other "Spanish alphabet" iw's to hu:Spanyol ábécé? Thank you. --TheMexican (talk) 20:05, 3 January 2008 (UTC)
I think we misunderstood each other, the Hungarian Spanish ortography has a part for the alphabet as well, but it has an own "main article", so you needn't double-link to the Hungarian iw :) What I asked you was to put the iw's related to the "Spanish alphabet" into the Hungarian "Spanyol ábécé" article, because I don't remember which they were. I'm sorry for making such trouble. --TheMexican (talk) 21:52, 3 January 2008 (UTC)
ligatures are not standard IPA practice
Is there no phonetic difference then between an affricate consonant and a plosive followed by a fricative? Dan Pelleg (talk) 21:06, 3 January 2008 (UTC)
- There is a difference, though not all languages make the distinction. If you want to be specific, you can use a tie bar [t͡s]. If you use Internet explorer like I do, then it's probably off a little but it's supposed to look like this:
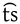 . Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 21:17, 3 January 2008 (UTC)
. Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 21:17, 3 January 2008 (UTC)
- Nope, it shows as [t□s] (IE7 on Windows XP Home Edition), which version / system do you use? I am actually unhappy with the way diphthongs are represented in Wikipedia, since using two vowels without a liaison implies two syllables, whereas diphthongs are monosyllabic (Hebrew ['bait] means "house" when it's disyllabic, "byte" when it's monosyllabic). So, are ligatures actually completely non standard in IPA, or just uncommon? Dan Pelleg (talk) 00:55, 4 January 2008 (UTC)
- I use Windows XP professional and it shows up but a bit crooked. As far as I know, the tie bar is standard IPA but is also often unnecessary (it's used more often in German dictionaries). If you want to show that it's two syllables, then you can use the syllable break "." so the two examples would be [ˈba.it] and [bait]. I'm not a fan of the ligature because it doesn't show up right (or at all apparantly) on IE, which is the most commonly used browser. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 20:07, 5 January 2008 (UTC)
- I see. The function of the syllable break is semantic, though, not phonetic (e.g. [ðɛn.stɑːɹ], for "then star" sounds exactly like [ðɛns.tɑːɹ], for "thence tar"), i.e., it has no phonetic significance, and strictly speaking, each symbol representing a vowel (vowels always being syllabic nuclei except when specifically specified) automatically represents a separate syllable. Which means, strictly speaking, [bait] is disyllabic, unless a liaison is added. I recommend the alternative notation [bajt], which is clearly monosyllabic and is just as precise a phonetic transcription (at least as far as Hebrew diphthongs are concerned). Dan Pelleg (talk) 01:39, 6 January 2008 (UTC)
- That works. Technically, "thence tar" is said with an aspirated /t/ and "then star" with an unaspirated one. That's the phonetic difference that reenforces the syllable barrier representation for the two phrases. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 02:23, 6 January 2008 (UTC)
- Aha! I tried to find an example which qualifies: does [hɹ̩.bɹæt] ("her brat") sound the same as [hɹ̩b.ɹæt] ("herb rat")? Dan Pelleg (talk) 16:36, 6 January 2008 (UTC)
- If you stress it right, they're the same. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 21:49, 6 January 2008 (UTC)
- Aha! I tried to find an example which qualifies: does [hɹ̩.bɹæt] ("her brat") sound the same as [hɹ̩b.ɹæt] ("herb rat")? Dan Pelleg (talk) 16:36, 6 January 2008 (UTC)
- That works. Technically, "thence tar" is said with an aspirated /t/ and "then star" with an unaspirated one. That's the phonetic difference that reenforces the syllable barrier representation for the two phrases. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 02:23, 6 January 2008 (UTC)
- I see. The function of the syllable break is semantic, though, not phonetic (e.g. [ðɛn.stɑːɹ], for "then star" sounds exactly like [ðɛns.tɑːɹ], for "thence tar"), i.e., it has no phonetic significance, and strictly speaking, each symbol representing a vowel (vowels always being syllabic nuclei except when specifically specified) automatically represents a separate syllable. Which means, strictly speaking, [bait] is disyllabic, unless a liaison is added. I recommend the alternative notation [bajt], which is clearly monosyllabic and is just as precise a phonetic transcription (at least as far as Hebrew diphthongs are concerned). Dan Pelleg (talk) 01:39, 6 January 2008 (UTC)
- I use Windows XP professional and it shows up but a bit crooked. As far as I know, the tie bar is standard IPA but is also often unnecessary (it's used more often in German dictionaries). If you want to show that it's two syllables, then you can use the syllable break "." so the two examples would be [ˈba.it] and [bait]. I'm not a fan of the ligature because it doesn't show up right (or at all apparantly) on IE, which is the most commonly used browser. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 20:07, 5 January 2008 (UTC)
- Nope, it shows as [t□s] (IE7 on Windows XP Home Edition), which version / system do you use? I am actually unhappy with the way diphthongs are represented in Wikipedia, since using two vowels without a liaison implies two syllables, whereas diphthongs are monosyllabic (Hebrew ['bait] means "house" when it's disyllabic, "byte" when it's monosyllabic). So, are ligatures actually completely non standard in IPA, or just uncommon? Dan Pelleg (talk) 00:55, 4 January 2008 (UTC)
General American
FYI, I consider ANY unwanted changes to the userspace with my name (since I can't say "my userspace") to be vandalism. Vandlism is against WIkipedia POLICY - it's not a guideline, so how did I bereka my own rules?? Idiot. I know we didn't start off on the right foot today, but I did aplogize for it. Yet you insisted on redacting my userspace, like I was a common vandal, wtihout even the courtesy to appraoch me first liek a real adult would. If the wiki-break notice is a personal attack on my paer, then I'm sorry your feelings were hurt. I've had it today with people protecting the real vandals and abusers, then going after me like I'm worse than the vandals. Well, I've had it with idoits like you. And you really are stupid for nominating the largest airlines list. THere, now THAT was a REAL personal attack. GO get me blocked if you wish, but I'm gone from WIkipedia anyway. THought I may come back as an IP, since they get more respect than regular users from the likes of morons like you! —Preceding unsigned comment added by 70.4.227.155 (talk) 22:07, 4 January 2008 (UTC)
- I can't really say that you've attacked me personally since it seems as though you have me confused with someone else. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 22:18, 4 January 2008 (UTC)
IPA chart for English
What have you guys done to the simple phonemic chart. It was simple and easy to read before you started fiddling with it. Now it's much harder to understand. Some of the Australian pronunciations are wrong, for example tore and tour DO NOT use the same vowel, they are not homophones. Tore is transcribed as /toː/ and tour as either /tʊə/ or /tʉə/. The consonant "r" is only pronounced when it is at the start of a syllable, not the end. --203.220.171.32 (talk) 03:27, 5 January 2008 (UTC)
- I believe you with the Australian tore/tour thing (Australian English phonology backs you up). I think you misunderstand the (r). We're trying to illustrate that that r only appears sometimes (that is, when the following word begins with a vowel. That can certainly be made more clear. Is there anything else that's harder to understand than before? — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 04:01, 5 January 2008 (UTC)
- But is it really necessary? Because some people have the linking-r whilst others do not and the linking-r is not universal in the dialects of Australia and New Zealand. As you are trying to illustrate this linking-r between vowels, then wouldn't it be a good idea to better explain this, so as confusion does not arise again.
- When I first looked at the page, I first said what's going on here? Then I looked at the /ɹ/'s in brackets and understood it could mean that these dialects that are non-rhotic are becoming rhotic, which I understand is not true, but could convey the wrong message to an ordinary user.
- Can't you leave the chart as a simple phonemic chart whilst perhaps going into more detail at International Phonetic Alphabet for English, that is why both were created in the first place, wasn't it? --203.220.171.32 (talk) 04:37, 5 January 2008 (UTC)
- Actually the content of International Phonetic Alphabet for English has been moved to English phonology and the page itself is now a redirect for IPA chart for English, but your point is well taken. We should still make IPA chart for English simple, straightforward, and accurate. This merger was very recent (yesterday) If you go to Talk:IPA chart for English you can possibly even make meaningful contributions to the discussion on how the page should be laid out since the issue is being discussed right now. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 04:43, 5 January 2008 (UTC)
- Oh, OK, I didn't realise that. OK, I've reverted my changes concerning the linking-r (for want of a better word), but I've left the changes I've made to the Australian English pronunciation of tore and tour as /toː(ɹ)/ and /tʉːə(ɹ)/ respectively, as these changes I made are correct, at least according to my Macquarie Dictionary. --203.220.171.32 (talk) 04:58, 5 January 2008 (UTC)
- Actually the content of International Phonetic Alphabet for English has been moved to English phonology and the page itself is now a redirect for IPA chart for English, but your point is well taken. We should still make IPA chart for English simple, straightforward, and accurate. This merger was very recent (yesterday) If you go to Talk:IPA chart for English you can possibly even make meaningful contributions to the discussion on how the page should be laid out since the issue is being discussed right now. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 04:43, 5 January 2008 (UTC)
Monomyth deletion.
Instead of simply idly deleting a section, perhaps you might undertake to do the work to add the references. The statements in this section are well-known and multi-sourced. I'll be adding more refs in the future. Please don't delete like this again. GiveItSomeThought (talk) 06:41, 7 January 2008 (UTC)
- You are right about the deletion spurring the references ... GiveItSomeThought (talk) 18:07, 7 January 2008 (UTC)
pidgin
If what is bothering you is the phrasing about their sharing no other language, I am sure we can come up with an alternative. In fact, I am satsified by manaus's compromise wording, if it is okay with you. I thought my singalling out grammar and usage made my objection plain - it had nothing to do with substance. My objection was to the phrase, "who do not share a common language" which is unacceptable in English. To share a language, and to have a language in common, mean precisely the same thing. To "share a language in common" is redundant, it is bad usage and sounds awful, and reflects sloppy use of language at best. You wouldn't write "after Kennedy was shot he was both dead and deceased." For the same reason one shouldn't write "shared a common ..." If they share it, it is by definition common. Slrubenstein | Talk 23:51, 7 January 2008 (UTC)
Re: Australian vowels
On my talk page you drew my attention to an article in JIPA about Australian English and queried the vowel charts on the AusE phonology page here. There are indeed some significant differences between Australian English as described on our page and in Cox and Palethorpe article (and not just phonetically!), some of which I briefly describe on my talk page. —Felix the Cassowary 05:06, 14 January 2008 (UTC)
IPA: g vs. ɡ
Hi. May I ask why you are replacing every IPA [ɡ] with *[g]? This letter does not exist in the official IPA. The difference becomes obvious in fonts like Times New Roman, where the normal "g" is inappropriate. — N-true (talk) 13:18, 22 January 2008 (UTC)
Spanish /uj/ vs. /wi/
Hey,
I made that edit based on the comments at Talk:Spanish phonology#Phonetic transcription of "muy". —kwami (talk) 02:38, 27 January 2008 (UTC)
- We should still find a source. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 03:25, 27 January 2008 (UTC)
variants of template:pronounced?
FYI. --Jtir (talk) 07:44, 4 February 2008 (UTC)
IPA transcriptions of Brasil
Hi, would you be able to make Portuguese IPA transcriptions of Brasil? (All the States of Brazil give a Brazilian and a European variant.) --Jtir (talk) 12:26, 4 February 2008 (UTC)
Portuguese /l/
Hi! About the Portuguese /l/, what sources?!? I’m not doubting of you, but I am seriously doubting of your sources. Isn’t it a misprint by any chance? See you. Ten Islands (talk) 18:35, 4 February 2008 (UTC)
Brazilian Portuguese
Sorry about the delay of my reply. I hadn't noticed your post yet. I don't really have sources with me at the moment, but here are the transcriptions I would use, as a startiung point if nothing else:
| Europe | Brazil | |
|---|---|---|
| anéis | /ɛi/ | /ɛi/ |
| sai | /ai/ | /ai/ |
| sei | /ɐi/ | /ei/ |
| mói | /ɔi/ | /ɔi/ |
| moita | /oi/ | /oi/ |
| anuis | /ui/ | /ui/ |
| viu | /iu/ | /iu/ |
| meu | /eu/ | /eu/ |
| véu | /ɛu/ | /ɛu/ |
| mau | /au/ | /au/ |
| cem | /ɐ̃ĩ/ | /ẽĩ/ |
| anões | /õĩ/ | /õĩ/ |
| muita | /ũĩ/ | /ũĩ/ |
| mão | /ɐ̃ũ/ | /ɐ̃ũ/ |
The table is missing one nasal diphthong of Brazilian Portuguese, /ɐ̃ĩ/.
One final remark: I think it's great that you're wanting to source the article better, but I don't like very much the fact that you've deleted a lot of stuff just because it wasn't in your source. As you can see, your source has some gaps in his knowledge, and anyway they deal only with Brazilian Portuguese -- and, I suspect, a very particular dialect of BP. Your recent changes to the article tend towards making it seem as though European Portuguese doesn't exist! FilipeS (talk) 03:20, 11 February 2008 (UTC)
- For example, mãe (mother), pronounced /mɐ̃ĩ/ in both EP and BP, though the Brazilian [ɐ̃] is a bit more open than the European one (as the vowel chart you've added to the phonology article shows). FilipeS (talk) 04:10, 11 February 2008 (UTC)
Non-native pronunciations of English
"that only indicates that <w> represents /v/, not that Germans will make spelling pronunciations"
- I didn't quite understand your comment. What's a "spelling pronunciation" supposed to be? - Comartinb (talk) 19:50, 11 February 2008 (UTC)
- Spelling pronunciation talks a bit about the phenomenon. In cases of second language learning, it has to do with speakers making an error in their target language based on the orthography rather than acoustic, phonological, or phonotactic reasons. It's why we pronounce llama with an /l/ even though the sound in Spanish is closer to [j] or [dʒ] or why speakers of Standard Russian pronounce Adolf Hitler's surname with a /g/ even though /x/ is acoustically closer to German's /h/. In the case of German, it's possible that they will have difficulty with English /w/ since German doesn't have that sound, but non-native pronunciations of English is an article that is undergoing a lot of scrutiny as people tend to want to add things without proper citations. Regards. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 22:01, 11 February 2008 (UTC)
orthographiless
You removed my wonderful table, which linked phonologic, phonetic and orthographic information. I gather this means you believe that an article titled "phonology" may solely impart phonological information. I believe that the information offered in that table was valuable and helpful. In which article would you recommend it appear? Dan Pelleg (talk) 23:12, 15 February 2008 (UTC)
- You're very perceptive on my motivations. I think that orthography can get in the way of discussing phonology. The table also doesn't look like most other consonant charts on Wikipedia. Don't worry, though. There's still information on that article detailing the phonemes that each character represents (another nice table). I haven't removed that. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 08:22, 16 February 2008 (UTC)
- I'm aware of the fact the table's innovative in its layout – innovations are often good, aren't they? Or we would all still be protozoa – but more to the point (as I mentioned), it concisely links phonologic, phonetic and orthographic information in an extremely coherent and intelligible fashion. Surely Wikipedia has a place for this kind of interlinked information. Your argument would suggest that, e.g., in Hebrew alphabet, the phonologic and phonetic information would be disruptive to the discussion of the orthography. So where else could we provide the information this table offers?
- Maybe this table does belong in this article after all, somewhere later, after the pure phonologic table is given, as an elaboration. Dan Pelleg (talk) 17:08, 16 February 2008 (UTC)
- Two consonant charts is, in my opinion, excessive. But there's still a table that links phononological and orthographic information (see the historical variation section). Looking back at the table you created, the "phonologic" information used non-IPA characters, which would be otherwise identical to the phonetic characters. The remaining table is more "concise" than your table was and has more information. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 19:08, 16 February 2008 (UTC)
- Yes, I used the symbols laid down by the Academy of the Hebrew Language for the transliteration of Hebrew into Latin letters, so actually the remaining table offers neither more nor more concise information, merely different information. Do I misunderstand the function of IPA, assuming it is, as its name suggests, a means of phonetic representation, not phonemic? I suppose it would therefore be correct to refer to these symbols as "Latin transliteration". Would this make the article Hebrew alphabet a good home for this table? Dan Pelleg (talk) 19:06, 17 February 2008 (UTC)
- I understand that you've put a lot of work into this table, but it doesn't add new information in any concise way and doesn't look like other consonant chart tables (being different isn't "innovative" it's only innovative if it's better) so I personally don't see any place for it. The transliteration scheme you've got, if it isn't already, can go on one or more of the series of tables about the Hebrew alphabet.
- As for the IPA, while it's name is "international phonetic alphabet" it is also used for phonemic transcriptions and using it for both is Wikipedia's policy on both phonetic and phonemic representation. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 20:13, 17 February 2008 (UTC)
- Yes, I used the symbols laid down by the Academy of the Hebrew Language for the transliteration of Hebrew into Latin letters, so actually the remaining table offers neither more nor more concise information, merely different information. Do I misunderstand the function of IPA, assuming it is, as its name suggests, a means of phonetic representation, not phonemic? I suppose it would therefore be correct to refer to these symbols as "Latin transliteration". Would this make the article Hebrew alphabet a good home for this table? Dan Pelleg (talk) 19:06, 17 February 2008 (UTC)
- Two consonant charts is, in my opinion, excessive. But there's still a table that links phononological and orthographic information (see the historical variation section). Looking back at the table you created, the "phonologic" information used non-IPA characters, which would be otherwise identical to the phonetic characters. The remaining table is more "concise" than your table was and has more information. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 19:08, 16 February 2008 (UTC)
- Maybe this table does belong in this article after all, somewhere later, after the pure phonologic table is given, as an elaboration. Dan Pelleg (talk) 17:08, 16 February 2008 (UTC)
Phonology of Polish
I was in the course of introducing a number of substantial improvements (including adding sources), when you undid my previous edit (I believe, within 1 hour of its introduction), which resulted in edition conflict and my work was lost. Perhaps it is not your fault, but I have not time to do it again. I am a professional linguist, specializing in the phonology of Polish. Wanted to contribute in my area of expertise ("The LINGUIST List" asked for it.), but have no time for this kind of, well, power games. Return to writing for professional journals. Have fun! Fon (talk) 21:03, 16 February 2008 (UTC)
Thank you for your answer. On the one hand, I suspected you meant well, so it's OK. On the other, this is a perfect example of how Wikipedia's strength may be at the same time one of its major weaknesses. I have fun editing - humbly - entries about e.g. Finnish history or Scottish songs, because it's not my field. But as a professional phonologist I feel responsible for what I edit, and when I see so much to be corrected in the entries on phonology, I try to stay away from them, so as not to get involved. Nevertheless, I sometimes yield to the temptation, but when I do I find my edits reverted by some well-meaning amateurs (e.g. see the comment of the guy who believed Polish word "kąt" is an example of a nasal vowel before a stop - confusing pronunciation with orthography). So, it is better to stay away.
About Polish phonology:
First, the whole question of how many phonemes there are and what is a separate phoneme and what is not is really relevant only within the, now historical, theory of phonemic phonology. We have had generative phonology since the late 1950s, and the Optimality Theory since the early 1990s, not to mention Government Phonology, Natural Phonology, etc.
Second, there is a lot of confusion about Polish "sz", "ż" "cz" "dż" - they are postalveolar, but recent work (e.g. Marzena Zygis in Germany) shows they are phonetically rather retroflex. I do not quite agree with this, and describing them as retroflex in a popular description, like here, gives an entirely wrong idea of what they sound like. I exchanged emails about it with late Peter Ladefoged a couple of years ago (he had represented them as retroflex in his chart in his web page). OTOH, I have occasionally heard some native speakers of Polish produce retroflex sounds there (e.g. Leszek Kołakowski, a philosopher from Oxford, obviously not a speaker of some obscure uneducated variety), but believe me, this is rather uncommon and non-standard and on those rare occasions when I heard it from someone--less distinguished--I had the impression the speaker had a kind of... lisp.
Third, Polish "ś, ź, ć, dź" are traditionally described as alveolo-palatal (as distinct from palato-alveolar English "sh", etc) but in e.g. Rubach, Jerzy (1984) From Cyclic to Lexical Phonology. The Structure of Polish, Dordrecht: Foris, page 21, they are described as "prepalatal" and I believe this is correct, or at least deserves a reference. To add to the confusion - they are transcribed with the IPA symbols that in 2005 IPA chart are labelled as "palatalized postalveolar". But in Polish they are not - what is more, in Polish there is a phonemic contrast between palatalized postalveolars and these sounds (i.e. one can find minimal pairs, at least across a word boundary)...
There is more...
I have put some of this into the entry today, including reference to Rubach (1984), but it got lost and I really have no time to do it again. Perhaps some time next year.
Finally - I have seen your user page. I am glad you are into linguistics, especially as it was not your major. 20 years ago I also had, at SUNY, students of, e.g., computer science taking my Introduction to Phonetics for distribution. I believe you are doing a good job with your IPA-related work. So - good luck! Fon (talk) 00:07, 17 February 2008 (UTC)
Edits of Help:IPA
Hi, why do you keep changing the tie-bar notation at Help:IPA? Does the no-width space make it look worse on your browser? What configuration do you have? I have IE6 with DejaVu Sans installed, and if the "space' is not there I see a "u" with an accent instead of "t"+tie-bar. I guess this is quite a common problem, since I've seen the no-width-space workaround used on other pages (including the IPA article I think), presumably for similar reasons.
I also don't know why you insist on changing the footnote number to a #. For me this makes a normal 1, not a footnote-style superscript 1 which is what we want. Again, does this somehow look different for you?--Kotniski (talk) 07:37, 17 February 2008 (UTC)
Fiction?
Whenever I make a turn at a phonology article, I come across your name in the history. I just noticed you indicate on your user page that you're studying fiction. Why not just study linguistics and get it over with? — Zerida ☥ 00:58, 18 February 2008 (UTC)
- So, why not study linguistics instead of fiction? — Zerida ☥ 04:47, 18 February 2008 (UTC)
- I agree. I am sort of in a similar situation, though both are structured. Lately I've been aiming to be more focused. Anyway, don't mind me, I was just curious. — Zerida ☥ 05:03, 18 February 2008 (UTC)
Yes I am having trouble citing them
Please cite all the references I put in the article. —Preceding unsigned comment added by Wikiaddict8962 (talk • contribs) 22:14, 20 February 2008 (UTC)
White Witch
You recently edited White Witch, where you have removed a long-standing carefully crafted compromise. Several posters to the Narnia articles have inferred a fascination on Lewis's part with Turkish, as several names from the series appear to reflect a knowledge of Turkish (or, more likely, if true at all, of how to use a Turkish dictionary, with no real understanding of the language or its pronunciation). I happen to believe this is over-stated, and that Jadis is French, but I have no sources to back this up. (See the section near the bottom of talk:White_Witch.)
While I was not entirely satisfied with the article before, I think you have inadvertently removed some key pieces:
- The emphasis that the final 's' in the French word is pronounced, specifically correcting previous claims (in support of the Turkish possibility) to the contrary.
- The English phonetic guide for viewers unfamiliar with IPA (i.e., the vast majority, for this article). wp:IPA indicates that supplementary pronunciation guides in addition to IPA are permissible. I added IPA for the French word, but could only guess for the Turkish, so waited for someone else with more knowledge.
- Part of the point of the English phonetic guide is to point out to viewers of the Disney movie that Disney got it wrong.
Also, you forgot to close template:IPA. I'd fix it, but as a combatant I don't want to be seen as encouraging the removal of the Turkish reference.
Elphion (talk) 18:23, 21 February 2008 (UTC)
- I don't know how Lewis pronounced it. Even though it's probably French, he might have clobbered it with Oxfordese, in which case Disney might not be too far off. I really don't know. It just irks, knowing that it is almost certainly French. (Double standard indeed!) It really boils down to sources -- and in any event the "definitive" pronunciation will now probably follow the movie.
- Also, I can't completely discount the Turkish theory, though in this particular case it seems far-fetched. Several examples have been proposed, more than chance would suggest. It's certainly possible that Lewis sprinkled in some Turkish words for color.
- I appreciate the value of IPA and agree that, other things being equal, it's a superior solution. But things are not always equal. There are of course the browser and font issues. (Even after installing several fonts to fix it, I find Firefox still reluctant to display all the characters correctly.) But beyond that, most US viewers are unfamiliar with IPA. If the examples stuck to "familiar" IPA symbols, people might get used to it. But of course for foreign words, unfamiliar symbols creep in. (Even in your note, you introduce an unstressed vowel that I had not seen before.) Most people find this confusing rather than enlightening, and many peple end up just ignoring the IPA -- or even (as I have seen one Wikipedian do) ripping it out of English-related articles.
- I agree that the English pronunciation guide for the cadı is awful (it's not mine), but I don't know Turkish, so can't really come up with a better one.
- You write, "You repeat arguments against use of the IPA ... " — but there are no arguments there against using IPA; indeed, I wish it were used more universally. I'm simply saying that in some situations (and I think this is one of them), it would be helpful to supply in addition an approximate guide as well. The most elegant tropes are naught but air if the audience fail to hear them. Elphion (talk) 21:08, 21 February 2008 (UTC)
Maltese language
The "Semitic Languages" template at the bottom of the pages lists Maltese as a subcategory of Siculo-Arabic, and there is enough written about it on the page itself to show that it is. Right? Crystalclearchanges (talk) 20:51, 24 February 2008 (UTC)
- Siculo-Arabic not a language family. More importantly, though, while the theory that Maltese comes from Siculo-Arabic is credible and well-established, my understanding is that it is one of several credible theories. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 22:17, 24 February 2008 (UTC)
- Why is Maltese included as a sub-part of Siculo-Arabic in the template? Oo Crystalclearchanges (talk) 17:15, 25 February 2008 (UTC)
- Oh I see what you're talking about now. I'd venture to guess that User:Toussaint felt that the theory was strong enough or was only exposed to that theory and not others. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 20:32, 25 February 2008 (UTC)
- Why is Maltese included as a sub-part of Siculo-Arabic in the template? Oo Crystalclearchanges (talk) 17:15, 25 February 2008 (UTC)
Hello
I tryed to reference the African American settler article but was sorely diasppointd it did not work. Please help cleanup. —Preceding unsigned comment added by Wikiaddict8962 (talk • contribs) 06:28, 25 February 2008 (UTC)
My references did not work
The references messed up the bottom part of the article. For some reason I have always had trouble referencing articles on wikipedia. —Preceding unsigned comment added by Wikiaddict8962 (talk • contribs) 06:50, 25 February 2008 (UTC)
About "separate aspirated/unaspirated examples" and etc
Hello. I've proposed something about the issue that may be worth looking into. See here for a detailed description and be welcomed to share your thoughts on it! Cheers Keith Galveston (talk) 14:50, 28 February 2008 (UTC)
Hey, so why is this necessary? It's fine by me either way; I just think it's more relevant for EA, since it's a significantly different pronunciation for Arabic. — Zerida ☥ 23:32, 29 February 2008 (UTC)
- Aeusoes, after reading your answer, I'm less convinced that it should stay that way. So what was the point of having the redirect to EA from Masri language, which I tried to eliminate? The "language-dialect" thing is really quite besides the point here. The example used, rāgel, is an Egyptian Arabic word. That's all I meant. Any basic phonetics/phonology textbook would simply point out next to the gloss that it's an example from Egyptian Arabic (though if the example had come from CA, it would be more generically "Arabic"). Alternatively, it would be perfectly acceptable to use an example from another dialect which has /g/ for historical /q/ instead of Egyptian. The [g] ~ [q] alternation is a far more salient feature of Arabic (lots of dialects) than the one mentioned, which is as you said restricted to Egyptian and maybe one or two other dialects. Also, the comparison with Occitan and Spanish is apples and oranges; Arabic, like Chinese, uses different vocabulary across dialects, among other things. By the way for consistency in the article, all the "g"s should be converted to the proper IPA symbol for the voiced velar stop /ɡ/. — Zerida ☥ 03:19, 1 March 2008 (UTC)
- I think what this boils down to is essentially the same topic that keeps coming up whenever we need to represent Arabic, except that we're back to square one. In fact, it's quite reminiscent of a similar conversation we had quite a while back when an editor created the Egyptian Arabic Swadesh list and you argued for the inclusion of all the so-called colloquial varieties of Arabic in addition to MSA/CA. There are also the numerous other discussions that have come up on the EA talk page. I don't think these need rehashing, but will point out again that the situation of English and Spanish dialectology is *not* analogous with that of Arabic. Similarly, I don't see any of the Chinese examples following that pattern? Unlike Spanish and English dialects, but like Chinese, the major varieties of Arabic are all ISO 639 languages. In my copy of Odden's Introducing Phonology under "Index of languages" are listed "Arabic", "Bedouin Hijazi Arabic", "Palestinian Arabic" and "Syrian Arabic", yet no varieties of English are listed besides "English" even though he mentions a few in the book. So unless the same pattern is followed for both Arabic and Chinese (e.g., Ladefoged & Maddieson), Arabic should follow the same pattern as Chinese, not English, Occitan or Spanish. Finally, I am not clear what you meant by finding words with "cognates" in CA. The EA example used descends from CA /radʒul/, which I believe survives in some conservative dialects. — Zerida ☥ 21:36, 1 March 2008 (UTC)
- Sounds good, though as I said in my first message I don't mind either way, as long as we are consistent. I disagree when I feel that Arabic alone (inc. Maltese) is being treated differently because of how some native speakers might feel about it. Their opinions don't trump WP:V. If there is enough consensus to group them together, that would be fine with me. — Zerida ☥ 22:00, 1 March 2008 (UTC)
- Well, it looks like there is consensus for your proposal in case you want to go ahead and make the change. I don't know how many other pages mention Arabic, but I think we would want to had a consistent representation for all the Arabic varieties. I hope that doesn't turn out to be too much of an undertaking. — Zerida ☥ 02:49, 11 March 2008 (UTC)
- Sounds good, though as I said in my first message I don't mind either way, as long as we are consistent. I disagree when I feel that Arabic alone (inc. Maltese) is being treated differently because of how some native speakers might feel about it. Their opinions don't trump WP:V. If there is enough consensus to group them together, that would be fine with me. — Zerida ☥ 22:00, 1 March 2008 (UTC)
- I think what this boils down to is essentially the same topic that keeps coming up whenever we need to represent Arabic, except that we're back to square one. In fact, it's quite reminiscent of a similar conversation we had quite a while back when an editor created the Egyptian Arabic Swadesh list and you argued for the inclusion of all the so-called colloquial varieties of Arabic in addition to MSA/CA. There are also the numerous other discussions that have come up on the EA talk page. I don't think these need rehashing, but will point out again that the situation of English and Spanish dialectology is *not* analogous with that of Arabic. Similarly, I don't see any of the Chinese examples following that pattern? Unlike Spanish and English dialects, but like Chinese, the major varieties of Arabic are all ISO 639 languages. In my copy of Odden's Introducing Phonology under "Index of languages" are listed "Arabic", "Bedouin Hijazi Arabic", "Palestinian Arabic" and "Syrian Arabic", yet no varieties of English are listed besides "English" even though he mentions a few in the book. So unless the same pattern is followed for both Arabic and Chinese (e.g., Ladefoged & Maddieson), Arabic should follow the same pattern as Chinese, not English, Occitan or Spanish. Finally, I am not clear what you meant by finding words with "cognates" in CA. The EA example used descends from CA /radʒul/, which I believe survives in some conservative dialects. — Zerida ☥ 21:36, 1 March 2008 (UTC)
Would you mind adding the full citation for Watson (2002) in that article? Also, where did you get the Yemeni form that you added to the table? The Yemeni dialect used by Watson is San'ani which has the postalveolar affricate. I couldn't find your form in the book in any event. — Zerida ☥ 03:13, 16 March 2008 (UTC)
- Absent of a native speaker of that dialect, we can't be sure if it's a mistake or not. It does however qualify as OR because we cannot reference it. For all we know, Yemeni could have an entirely different word for man, like Levantine for example, which has /zalamɛ/. We need a reference that specifically states what the form is in that dialect. — Zerida ☥ 05:06, 16 March 2008 (UTC)
- Hey, see my note regarding the tag you placed on Egyptian Arabic. Not to dwell on the velar stop article, but why not just use a Yemeni example where /g/ is a reflex of /q/ rather than the palatal stop/affricate? As I mentioned, this is much more common in Arabic, including non-standard dialects of Egyptian Arabic. There is no requirement that the example must be of a historical /dʒ/ becoming /g/ . — Zerida ☥ 20:43, 22 March 2008 (UTC)
- Oh, and maybe you could take a shot at the syntax section in EA as well? :-) — Zerida ☥ 20:45, 22 March 2008 (UTC)
- Hey, see my note regarding the tag you placed on Egyptian Arabic. Not to dwell on the velar stop article, but why not just use a Yemeni example where /g/ is a reflex of /q/ rather than the palatal stop/affricate? As I mentioned, this is much more common in Arabic, including non-standard dialects of Egyptian Arabic. There is no requirement that the example must be of a historical /dʒ/ becoming /g/ . — Zerida ☥ 20:43, 22 March 2008 (UTC)
Russian IPA chart
I am not an expert on IPA, remember? I can merely read it, but I did look at the article from the native speaker's viewpoint and made a few corrections along the way. If anything is missing from the table, I wouldn't have noticed it due to my limited knowledge of the subject. The corrections I made consist of mostly fixing minor formatting flaws and replacing "е" with "ё" where needed (also, in Russian, a stress mark over "ё" is normally omitted, because this letter is pretty much always stressed).
A few other things I noticed:
- I have no clue what "герь" or "юбда" are (perhaps some dialectal words?), so I replaced them with "гербарий" и "юла".
- In the word "сухой" the second syllable is stressed, not the first. I replaced the example with "пуля".
- I would never pronounce the word "зверь" with "з" palatalized—in fact, I need to make a conscious effort to pronounce this word that way. I think you mentioned once that such pronunciation is more common in Moscow (where they talk weird anyway :)), but perhaps a less ambiguous example would be more appropriate?
- I am also not so sure about "н" in "женщина" being a good example for plain "н". I find myself occasionally pronouncing this word with a palatalized "н" for no apparent reason—not sure if it's a phenomenon particular to the variation of Russian I speak or if it's a common occurence. "Блиндаж" is one replacement I can think of.
Hope this helps! Let me know if there is anything else I can do.—Ëzhiki (Igels Hérissonovich Ïzhakoff-Amursky) • (yo?); 15:47, 6 March 2008 (UTC)
Voiceless bilabial fricative
I have seen you reverted my edition in Voiceless bilabial fricative concerning the ocurrence of ɸ in southern dialectos of Spain. I had no time to adding the refereces, also I know about this because my family speaks a dialecto with such characteristics, but ... why do you revert this edition so quickly? --89.129.129.66 (talk) 22:40, 7 March 2008 (UTC)
- Hey, thanks for sourcing it! I'm trying to increase quality standards on these consonant pages one language at a time and Spanish is one language that I've sourced for all of the other consonant and vowel pages. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 00:28, 8 March 2008 (UTC)
Hi!
Hi Aeusoes! I’ve crossed with you three times, at this point you must think that I’m a real p… in the a…! I just dropped by to say that I haven’t anything against you, on the contrary, it’s nice to have someone with whom I can talk phonetics, for a change, even if I don’t agree with you in some matters. See you! Ten Islands (talk) 20:58, 8 March 2008 (UTC)
Emphatic - pharyngealized / velarized
What in your opinion would be a more desirable representation of emphatic consonants, e.g. for Semitic Teth / arabic Ṭāʼ: [tˁ], [tˤ] or [tˠ]? Dan Pelleg (talk) 15:09, 20 March 2008 (UTC)
- There isn't one IPA representation that would be appropriate for all Semitic languages. Proto-Semitic emphatics were probably ejective while pharyngealized is more accurate for languages like Arabic, Syriac, Aramaic, and (Biblical) Hebrew. The nice thing about historical linguistics is that it's common to deviate from IPA in transcription so that you could use the transcriptions system at our article on Proto-Semitic. But I guess it would depend on what you plan on doing. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 16:10, 20 March 2008 (UTC)
- Thanks – could you explain what exactly the IPA-symbol ˁ stands for? Does it generally stand for any kind of emphatic co-articulation, i.e. for both velarization and pharyngealization? Dan Pelleg (talk) 23:19, 20 March 2008 (UTC)
- ˁ or ˤ (if I understand correctly, the two are interchangeable) stands for pharyngealization. The character is a superscript version of the symbol for the voiced pharyngeal fricative/approximant ʕ. As Watson explains in The Phonology and Morphology of Arabic (2002) Arabic's emphatics have a secondary articulation of [+pharyngeal] (or [+guttural]), and that a non-primary feature tends to have less constriction and to involve more movement than a primary stricture. Thus, it differs from coarticulation as [w] has for many languages. Also, at least for Arabic, pharyngeal constriction in emphatics occurs in the upper pharynx while in the pharyngeals it is in the lower pharynx.
- If you want to represent velarization, there is ˠ, a superscript version of the symbol for the voiced velar fricative ɣ.
- If you want a diacritic that represents either velarization or pharyngealization (since there is little phonological difference), ̴, a tilde through the consonant is the official IPA diacritic, but I don't like it because it's hard to see on any consonant other than l. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 23:36, 20 March 2008 (UTC)
- Thanks again. Whereas I always encounter ˤ as indicating pharyngealization, when the ˁ symbol appears here it often seems to refer more vaguely to any emphatic co-articulation, which is kind of unsettling to my sense of precision. That's what made me wonder if it officially denoted any "emphatic-ness". But if it doesn't, I feel we should go for uniformity and prefer ˤ, since it more clearly resembles ʕ, and if several variants of co-articulation apply to one grapheme, they should all be accurately listed, e.g. if the emphatic Arabic Ṣad and Ṭāʼ are sometimes velarized and sometimes pharyngealized, then their pronunciations should respectively be given as"[sˤ] or [sˠ]" and "[tˤ] or [tˠ]". What do you think? Dan Pelleg (talk) 12:57, 21 March 2008 (UTC)
- I agree. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 17:28, 21 March 2008 (UTC)
- Thanks again. Whereas I always encounter ˤ as indicating pharyngealization, when the ˁ symbol appears here it often seems to refer more vaguely to any emphatic co-articulation, which is kind of unsettling to my sense of precision. That's what made me wonder if it officially denoted any "emphatic-ness". But if it doesn't, I feel we should go for uniformity and prefer ˤ, since it more clearly resembles ʕ, and if several variants of co-articulation apply to one grapheme, they should all be accurately listed, e.g. if the emphatic Arabic Ṣad and Ṭāʼ are sometimes velarized and sometimes pharyngealized, then their pronunciations should respectively be given as"[sˤ] or [sˠ]" and "[tˤ] or [tˠ]". What do you think? Dan Pelleg (talk) 12:57, 21 March 2008 (UTC)
- Thanks – could you explain what exactly the IPA-symbol ˁ stands for? Does it generally stand for any kind of emphatic co-articulation, i.e. for both velarization and pharyngealization? Dan Pelleg (talk) 23:19, 20 March 2008 (UTC)
Thanks for your comments. There is now a case that it is a professional nickname, so your previous arguments aren't so applicable. Perhaps it would be best to decide on what criteria we need for inclusion instead. I'll understand if you don't have the time to participate further.
AfD nomination of History of present-day nations and states

An editor has nominated History of present-day nations and states, an article on which you have worked or that you created, for deletion. We appreciate your contributions, but the nominator doesn't believe that the article satisfies Wikipedia's criteria for inclusion and has explained why in his/her nomination (see also "What Wikipedia is not").
Your opinions on whether the article meets inclusion criteria and what should be done with the article are welcome; please participate in the discussion by adding your comments at Wikipedia:Articles for deletion/History of present-day nations and states and please be sure to sign your comments with four tildes (~~~~).
You may also edit the article during the discussion to improve it but should not remove the articles for deletion template from the top of the article; such removal will not end the deletion debate. Thank you. BJBot (talk) 03:59, 24 March 2008 (UTC)
Catalan language
Hi, thanks for your interest in Catalan language.
I would revert all main varieties which you redirected, and I agree with you, references would be needed.
About the map:
Also, I noticed that you restored the use of this image at Catalan language but there are a number of problems with this map
{kind=link}
- I mostly did it because of Andorra, which was simply wrong. But a more diffuse-alike representation also depectis the linguistic reality better as well.
- Another clearer link about Andorra variety. In first page footnote: http://www.iecat.net/butlleti/pdf/106_butlleti_dialectal.pdf --Toniher (talk) 21:25, 24 March 2008 (UTC)
It cites no sources, making it unreferenced
- I suppose it's made up from text references, because copyrighted maps could not be used. But yes, you are right, there should be references in the image. I will try to help on it.
It is imprecise.
- Could you further explain?
What I have seen when looking up Catalan dialects (and I'll admit it's not much) contradicts what it presents as the presence of transitional zones as well as the border between North-Western Catalan and Valencian.
- Could you further explain? The transition between North-Western and Valencian is what is usually known as Ebrenc or Tortosí, and some would even consider it a distinctive group of its own.
--Toniher (talk) 20:48, 24 March 2008 (UTC)
Portuguese dialects map
Hi !
Here is a rough translation of the text from Cintra. Of course, it is not a full translation, I wouldn’t have the time for that. But at least I tried to filter out what is more important to build up a map.
The text talks about the proposal from Cintra for a new classification of European Portuguese dialects. Note that Cintra includes the Galician dialects in his proposal but I will not talk about Galician dialects here. This proposal appeared in the seventies and it is already in use in some books, by other linguists, and notably by the Instituto Camões.
The main criticism that Cintra makes to previous classifications (Vasconcelos, 1897; Vasconcelos, 1901; Vasconcelos, 1929; Paiva Boléo, 1959; Vázquez Cuesta & Mendes da Luz, 1961) is that they are made mainly departing from the traditional regional divisions of Portugal and not through distinct linguistic characteristics.
Going quickly to what matters, Cintra cites the following differentiating phonetic features (from North to South):
- The very archaic zone where there is still the difference between alveolar sibilants /s͇/ and /z͇/ (called ápicoalveolares by Cintra) written “s” and “ss”, and dental sibilants /s̪/ and /z̪/ (called predorsodentais by Cintra) written “ce,i”, “ç” and “z”. It corresponds to the thick oblique lines area in the map on page 17. In standard European Portuguese these four sibilants were merged into the two dental sibilants /s̪/ and /z̪/.
- The zone where there is still the difference between the postalveolar affricate /ʧ/ written “ch” and the postalveolar fricative /ʃ/ written “x”. It corresponds to the zone North-East of the dash-dot line in the map on page 16. In standard EP these two phonemes were merged into the postalveolar fricative /ʃ/.
- The zone where there is still the difference between the diphthong /ow/ written “ou” and the vowel /o/ written “o”. It corresponds to the zone North of the dash-double dot line in the map on page 16. In standard EP these two phonemes were merged into the vowel /o/.
- The zone where the apical sibilants are pronounced as alveolars /s͇/ and /z͇/ (called ápicoalveolares by Cintra). It corresponds to the zone North-East of the dashed line in the map on page 16. In standard EP these two phonemes are pronounced as dentals (called predorsodentais by Cintra) /s̪/ and /z̪/.
- The zone where there is not anymore the distinction between /v/ and /b/ (merged into /b/ with the [b] and [β] allophones). It corresponds to the zone North-West of the continuous line in the map on page 16. In standard EP there is still a distinction between /v/ and /b/.
- The zone where there is still the difference between the diphthong /ej/ written “ei” and the vowel /e/ written “e”. It corresponds to the zone North-West of the dash-triple dot line in the map on page 16. As it can be seen, Lisbon falls within the zone of /e/ instead of /ej/. But due to a phenomenon that occurred only in the Lisbon area, probably in the XIX century, the phoneme /e/ changed to /ɐ/ before palatal phonemes /ɲ/, /ʃ/, /ʒ/, /ʎ/ and /j/. This is important because this characteristic was incorporated in standard EP.
So, how does Cintra makes his dialectal division?
- First, he chooses the border between the alveolar sibilants /s͇/, /z͇/ and the dental sibilants /s̪/, /z̪/ to separate what he calls Dialectos portugueses setentrionais at North (oblique lines in the map on page 17) and what he calls Dialectos portugueses centro-meridionais at South (horizontal lines in the map on page 17).
- Second, he chooses the border between the conservated system of 4 sibilants /s͇/, /z͇/, /s̪/, /z̪/ and the “merged into aleveolars” system of 2 sibilants /s͇/, /z͇/ to separate what he calls Dialectos transmontanos e alto-minhotos at North-East (thick oblique lines in the map on page 17) and what he calls Dialectos baixo-minhotos–durienses–beirões at South-West (thin oblique lines in the map on page 17). He choses the borded between the conservated diphthong /ej/ and the monothonged /e/ to separate what he calls Dialectos do centro-litoral at North-West (thin horizontal lines in the map on page 17) and what he calls Dialectos do centro-interior e do Sul at South-East (thick horizontal lines in the map on page 17).
- Third, he points out three sub-dialectal areas that have some peculiar characteristics:
- What he calls the variety of Baixo-Minho e Douro Litoral where the tonic vowels /e/ and /o/ are diphthonged to /je/ and /wo/.
- What he calls the variety of Beira-baixa e Alto-Alentejo where occurs a phenomenon of palatalization of the back vowels in certain contexts: the tonic /u/ shifts to /y/; the diphthong /ow/ changes to /ø/; the tonic /a/ shifts to /æ/ when in the preceding syllable there is a front vowel (including the already shifted /y/).
- What he calls the variety of Western Algarve where occurs a phenomenon of vowel rotation of the tonic vowels: the /u/ shifts to /y/; the /o/ shifts to /u/; the /ɔ/ shifts to /o/; the /a/ shifts to /ɒ/; the /ɛ/ shifts to /æ/; the /e/ shifts to /e̞/; the diphthong /ow/ changes to /ø/.
Of course, one could make some criticism to this classification: it leaves out the Atlantic Islands, Azores and Madeira; it is based on the phonology only; there are other phonological dialect differences that are not mentioned; the vocabulary could show a different division; also some grammatical features could show a different division. But this is the most accepted dialectal division accepted today. If you could help me in making a map (that could be used in any language) I would appreciate it a lot.
That’s it for today. For another division of Portuguese dialects in Brazil I will talk later. See you! Ten Islands (talk) 10:14, 25 March 2008 (UTC)
Arabic on Near-open central vowel
For the life of me, I cannot find the translation for the word you added as [t̪afɑqɑˈtɐː]. Do you know what it means? My best guess for the original was تفقتا but I can't find that in any dictionary... Cheers! --Xyzzyva (talk) 00:20, 2 April 2008 (UTC)
Arabic /ɬˤ/
Hi,
I've always seen this as /dˤ/, and now a known jokester has added that it's still pronounced /ɬˤ/ in some traditions. Where does this come from?
Thanks, kwami (talk) 10:16, 5 April 2008 (UTC)
- Thanks. Do we have direct attestation somehow, or could this just be a Mehri substratum influence? kwami (talk) 19:32, 5 April 2008 (UTC)
You de-linked IPA
here, but why? Dan Pelleg (talk) 22:37, 6 April 2008 (UTC)
Ebonics again
A proposal to merge with AAVE. This time it seems well intended, but I think it's still myopic and worth opposing. Feel free to disagree with me though! -- Hoary (talk) 03:58, 13 April 2008 (UTC)
title
If you don't like the title "Anglophone pronunciation of foreign languages", why not "English accent in foreign languages"? I guess that could be understood to be "British accent", but it should be clear enough in context. It's also much more colloquial. kwami (talk) 02:33, 18 April 2008 (UTC)
- Not bad. "Would Non-native pronunciations of English" be renamed "Foreign accent in English"? — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 02:36, 18 April 2008 (UTC)
- Maybe "accents", plural? I don't know which titles people rejected or why. kwami (talk) 15:58, 18 April 2008 (UTC)
Awngi consonants
Just a few questions for clarification: What exactly prompted you to split up the symbols for the affricates in the Awngi language article? Is there some kind of policy that we all should follow? As I see it: The IPA has these symbols, Unicode provides these symbols, so why not use them? This will help to distinguish them from sequences of consonants. Then again, you re-arranged the phonological system, so that it follows strictly phonetic criteria. The way the table showed before it indicated the phonological relationships. The velar and palatal sounds form indeed a single place of articulation in Awngi (they undergo the same morphophonological processes), and therefore I would vote to keep it the way it was, even if it means using language-specific terminology to describe the phonological realities (palato-velar). I could agree with you in renaming z to dz; before I was just not bold enough to do this. Phonetically, this sound is always a fricative in today's Awngi, but it behaves as an affricate in morphophonemic processes. Landroving Linguist (talk) 07:42, 18 April 2008 (UTC)
- Thanks for your feedback. I would claim that every language phonology is language specific and might therefore call for language specific terminology. A table containing the phones of a language should instead follow the pure terminology of the IPA, which would make it look more like your recent change. The table provided, however, is a representation of the phonological system of Awngi. On the other hand I need to admit that the term palato-velar is not coined by Hetzron, but by myself, and since my Awngi phonology still awaits publication, it certainly constitutes a case of original research. The facts, however, are well laid out in Hetzron's writing. He just did not bother to arrange his phoneme chart to reflect the relationships. Anyway, as long as my article is not in the open, I will leave things the way you have done now. About the affricates: I am aware of the solution you indicated from Polish. This is the way I once learned to do it in IPA, but I never liked it much, it being rather cumbersome. So I was exited to find the ligature characters some time ago and chose to use those instead, because they give a nice visual distinction to a simple sequence of stop and fricative. It is not quite true that there are no such sequences in Awngi. The word sédza 'four' has /dz/ as a phonetic affricate. Since this contrasts with all cases of /z/, my interpretation is that this indeed constitutes a sequence of /d/ and /z/, not an affricate. But here, again, I am engaging in original research, and that's why this does not show up on the page yet. Landroving Linguist (talk) 19:50, 18 April 2008 (UTC)
- Again, what constitutes a particular sound in a language is language specific. In Awngi, the phonological affricate /dz/ is realized in all cases as the phonetic fricative [z], so much so that you have to study the system to see that it still functions as an affricate. And you see it from language history - Frank Palmer, who recorded the language in the 1950's, still heard the phonetic affricate with an older speaker in all cases. He also heard the affricate in /sédza/, and did not notice any difference (phonetically) to other instances of /dz/. The fact is that in the last 50 or 60 years all instances of /dz/ turned to [z], with the sole exception of /sédza/, where it still is an affricate (phonetically), that is a sequence of stop and fricative. This calls for an explanation - my modest attempt being so far that here is indeed a sequence of two segments, although this interpretation has problems, too. Maybe it is just a temporary idiosyncracy of the language. And you can observe right now that the language is developing a row of voiced fricatives at the labial, alveolar and palato-velar places of articulation. The sounds are already there phonetically, but still interpreted in different terms. Increasing systemic pressure is likely to establish this as a row in its own right in the near future. My whole point being: Just a look at the simple phonetics does not always tell you what sound you have in a language - a clearer picture you get from the phonological rules in the language and from a look at the system. It is this system that the table in the article was trying to represent. Landroving Linguist (talk) 20:26, 18 April 2008 (UTC)
Refdesk viragos
That was very funny. I wanted to make this a barnstar, but I couldn't find a suitable one. --Milkbreath (talk) 02:10, 22 April 2008 (UTC)
Arabic/Voiced pharyngeal fricative business
First off, I'll grant you that you're the expert (probably) and I'm not. All of what I'm about to say could be totally off.
However I am a native speaker of Arabic (sort of...it's a long story, but suffice it to say I've never not spoken it), and am currently studying Arabic. I visit a lot of Arabic-related articles and read a fair number of Arabic-related books and I find that all of them have ʕ for ع. So imagine my surprise when the symbol's article doesn't have Arabic there...
In any case, the summary of the article you give doesn't say why ʕ is not a realization of the letter `ain; the entire section is alternate (and, for the sake of argument at least, more common) realizations of the same sound. Perhaps the whole article explains why you can't find ʕ in Arabic, but if so we need to know that. Otherwise, I think we should bow to tradition a little in our representation of the sound, with the little caveat attached.
I apologize if I sound incoherent and/or stupid. Lockesdonkey (talk) 03:18, 23 April 2008 (UTC)
- If you don't mind me jumping in, Aeusoes ...
- There is a long tradition of transcribing ‘ain as ʕ. However, that's from the days before the articulation could actually be observed very well (with fiber optics and the like), and people were making a lot of assumptions which haven't always panned out. We're still woefully ignorant about how "pharyngeal" sounds are actually articulated, not just in Semitic languages but around the world. It's possible that there are Arabic dialects or registers which have true ʕ. However, AFAIK, the evidence to date has been negative. kwami (talk) 05:24, 23 April 2008 (UTC)
- Yes, Kwami is right. The distinction between a voiced pharyngeal fricative and a pharyngealized glottal stop or voiced epiglottal fricative is obviously very very subtle and I wouldn't be surprised if Arabic speakers don't notice such a distinction. Because the sources that make the case for these alternate articulations are corrective (making the case that what has been described as X is really Y), it makes all sources that say it's a pharyngeal fricative suspect. Basically, we'd need to find a reputable source that says "it's epiglottal for these people but pharyngeal for those people." It's a higher standard than normal but the situation requires it. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 06:00, 23 April 2008 (UTC)
rearranging consonant charts
hi.
I notice that you are rearranging consonant charts in lang articles. May I ask why? I assume that you are trying to make all consonant charts in wikipedia consistent in their arrangement, no? And you are following the IPA arrangement where nasal stops are above oral stops?
My comment on this positioning of nasal with respect to oral is that most descriptive phonologists (based on my reading of many grammars and grammatical sketches) place nasal stops after oral stops and fricatives (if any). This is because nasal stops are usually classified as sonorants/resonants and not as obstruents. It is true that nasal stops can be either obstruent or sonorant — they are kinda in-between — so you are not really wrong to reposition them as you are doing. (if youre following the IPA, the IPA has a more articulatory perspective is placing nasals next to oral stops, whereas the sonorant analysis is more from an acoustic or phonological perspective.) But, I just wanted you to know that your repositioning is actually a less common arrangement. – ishwar (speak) 12:30, 24 April 2008 (UTC)
- Yes, I'm putting it closer to the IPA arrangement. I've been doing this off and on for a while but in February, Angr undid one such rearrangement with the same argument that you've just mentioned; nasals are often analyzed phonologically with other sonorants (although in the tables I've seen most often in the Journal of the IPA, nasals seem to be most often organized with other stops even if they aren't first). At first, I wasn't sure how to proceed. Should I undo all the the instances that I've put nasals on the top? I decided that I'd continue the way I'd been doing it and if anybody opposed me on any particular article that I'd let them have their way. Other changes that I've been implementing:
- removing "liquid" as a category, usually by splitting the rhotic and lateral rows.
- combining "lateral" and "approximant" but only if there's no overlap. Languages with a palatal lateral and a central palatal approximant don't let me do this
- putting /w/ in the velar column. This is another one that people can fight me on since /w/ has language-specific nuances.
- removing ligatures. I've even put a justification for such a removal in my user page
- converting to class="wikitable" (or the cool new class="IPA wikitable"). Again, something I'll let people fight me on within reason.
- removing the plural from the manner of articulation column (nasals → nasal)
- changing "stop" to "plosive" especially when affricates have their own row.
- There is still going to be variation in layout (and in fanciness) and this is largely dependent on how the table is already laid out. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 17:28, 24 April 2008 (UTC)
- maybe the best answer is "it depends". IPA uses a mostly articulatory classification, which is why the put the nasals with the (oral) stops. So, they consistly adhere to that in their charts. But, many language clearly have nasals patterning with other sonorants (and not with stops). So, one would have to make choice between an articulation based chart guideline or a phonology based chart guideline. Personally, I would (along Angr) go with phonology based charts. And this is how most people chart their consonants in spite of how the IPA charts consonants. One could also have similar remarks about removing liquid from the charts. Again, you have to consider what information your chart is trying to convey to the reader. For /w/, the best choice would depend on the individual language. Sometimes, it may be best to put /w/ in both columns if /w/ behaves like velars in some situations and like labial in other situations. For a paper by John Ohala (who often thinks that phonologists say a lot BS) on this topic, enjoy: The Story of w.
- Reading about your rearranging of consonant charts, it appears to me that this is WP:OR. I think wp should stick to the original sources and their arrangements of phonemes. It is not the business of wikipedia to reanalyze phoneme inventories. For instance, Diyari language has a peculiar arrangement of the consonant table, and streamlining it to some kind of pseudo-standard will lose phonological generalizations which inspired this table in the first place.
- If no original sources are cited, I think that it is fine to re-arrange the charts the way you do. Jasy jatere (talk) 09:44, 20 May 2008 (UTC)
Macedonian Phonology
Hi. In this diff, the last section you added contained your signature. Was that just a mistake (adding four tildes) or was the section meant to go on the talk page? Cheers, BalkanFever 08:24, 26 April 2008 (UTC)
- Oops! that was a mistake. Thanks for noticing. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 18:22, 26 April 2008 (UTC)
Swedish /ɵ/
I assume this is in-rounded. Do you know? kwami (talk) 08:05, 2 May 2008 (UTC)
- Sorry I didn't respond more promptly. You mean with both labialization and rounding, as opposed to just protrusion or out-rounding that is just labialization, right? The only article I've got right now that makes such a distinction (Traunmüller & Öhrström in Journal of Phonetics 2007) seems to transcribe it as [ʉ] and pairs it with long [ʉː]. Judging by this, I'd also guess that it's in-rounded since /ʉ/ (representing both long and short) is marked as both rounded and labialized. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 08:24, 3 May 2008 (UTC)
The article mixes things in the vowels table; that's why I added distinctive colums for rounded/unrounded and nasal/oral as these vowels are clearly distinctive in French, even if English speakers can't pronounce correctly the rounded or nasal vowels.
Also what I wrote about the other disappearing distinctions in French is true. There are lots of references, including within MANY MANY audio records, TV shows, cinema, songs. This is asserted in famous French dictionnaries, and in the evolution of the orthography where some orthographic accents (acute vs. grave) are disappearing or VERY frequently mixed.
The evolution of "j’ai" (that was pronounced like /jé/) into /jè/ is now standard and this is also true for all conjugated verbs ending in "-ai" at the first person. See also "événement" that is now written "évènement" due to phonology.
Almost nobody now can hear a difference between open 'a' and close 'â', even if this persists orthographically...
My modifications were to make this clear: important things that are currently mixed as if they were equivalent, from an English auditor, but the article is not speaking about French phonology heard by native English speakers, but French as spoken, heard and understood by native French speakers.
verdy_p (talk) 18:45, 3 May 2008 (UTC)
- Note that you cannot claim this is "dobious change" as you're not even speaking the language or understanding it, not even at novice level !
- There's nothing in your profile that confirms your knowledge of French, or any contribution to French Wikipedia...
- I am French native, leaving in France. Your "dobious" comment is really unfair.
- My opinion is that you're contributing only as a theorist, but your sources about French are certainly old and do not reflect modern French (and notably "Parisian" French that is standard in France and gains larger support throughout the territory, and even abroad, with the progressive disparition of regional accents). verdy_p (talk) 19:42, 3 May 2008 (UTC)
- All right, you got me. I don't speak French. However, you cannot stand on your status as a native speaker (especially for claims about nuanced phonetic attributes of vowels). We need sources to back up claims. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 19:52, 3 May 2008 (UTC)
Although my first language is English, I have a sufficient degree of competency in French to say that Verdy's claims are overstating the extent to which conservative pronunciations have declined. Reading what Verdy writes, one would think that [ʒe] has been supplanted by [ʒɛ] for j'ai, or that [ɲ] is restricted to "some regions" and the standard pronunciation has become [nj]. In fact, if anything, it is [nj] which is still a socially marked pronunciation, in Paris or anywhere else. I think Aeusoes1 is absolutely correct in requesting sources. If they are provided, we will have to parse what they say carefully to avoid overstating things (for example, jumping from reading that a certain pronunciation has become common to concluding that the competing one is moribund), and it will still be worth checking those sources against other ones. Although Verdy P's status as a native speaker undoubtedly gives him a unique perspective, I am frequently struck by the propensity of some Parisians to overestimate the uniformity of French, even as it is spoken in Paris by (what could be called) good speakers. Joeldl (talk) 07:40, 4 May 2008 (UTC)
Voiceless glottal fricative
Hi, just saw your amends to my edit in Voiceless glottal fricative, and I became curious: what's wrong with "real" as an example? Greetings, Rsazevedo msg 17:18, 9 May 2008 (UTC)
- I see your point, I just thought the other way around -- I reckoned that using the same example for all of them could eventually confuse readers who are not familiar with the language and the existence of so many different variations in it. Rsazevedo msg 21:50, 9 May 2008 (UTC)
I edited your userpage
I hope it helps, as before, for some of the vowels, you couldn't actually see the small diacritics at the bottom and stuff. Well, anyway, if you don't like it, then sorry :S feel free to revert back. MagdelenaDiArco (talk) 19:37, 11 May 2008 (UTC)
Archiving
No No my acts were justified man. It doesn't matter how old they are . They were concluded discussions. Every discussion that i archived were concluded. I think the ones that you archived are actually a bit overzelous. You see those aren't concluded discussions. Please assume good faith in my work. What i did is only for the best interest of wikipedia.
IN fact whilst you moved everything to archive i was going to answer one of the sub sections that didn't have an answer (subsection ajn). I wrote an essay explaining everything and then i ended up with an edit conflict and lost everything for some reason or another. So no i guess you better see what you did yourself first.
Thanks
--Gian (talk) 17:35, 13 May 2008 (UTC)
This shows that you have no idea about Malta and the Maltese people (I suggest you read here Languages of Malta). English and Maltese are my native languages (and i speak italian too). So what you're trying to say that English is not my native language it's bullocks and rather insulting to be honest. Please refrain from doing such uncalled for assumptions. I must admit though that i'm a "new comer" (5 months as a user... 6 months as anonymous) to Wikipedia so another thing that i suggest is that you read this click here. That said something that i certainly learnt during these past months is that Wikipedia works with consensus. Now don't play the clever guy with me, i know that consensus is a synonym of agreement ;). However consensus is only reached with a ballot otherwise we always end up with a deadlock. In Maltese we have a saying "Mitt Persuna Mitt Fehma" meaning for one hundred people there are one hundred different opinions. Why do you think that in RFAs and stuff we always put up Support, Oppose and Neutral? If you think its not voting good luck for you. I certainly do think of it that way.Actually what you're calling my behaviour as unjustified i find it the other way round. I only archived 4 discussions that were plausibly closed. Even if they weren't plausibly closed. The assumption that you took to archive the rest was uncalled for. Your reasoning is unjustified and they were still up for discussion. What becomes apparent to you isn't apparent to others. Finally yes well done now you solved my problem by giving me a great solution to the edit conflict but that's certainly not my point. My point is that i was going to answer something relevant that you deem that it is closed. To conclude i suggest you don't point fingers at anyone. What i was trying to do was for the best interest to Wikipedia. Good Night. --Gian (talk) 21:24, 13 May 2008 (UTC)
- Regarding if I'm native or not native I guess I’ll leave it to your imagination since I have nothing to prove to you ;) Quite frankly I don’t care what you think about me.
- Thanks. That Fresno State English program must have paid off. Now that you realised the irony behind it. Now I guess you also concluded that I have a fair knowledge of the policies and that I’m not a newbie.
- Regarding WP:NOTDEMOCRACY I read that long time ago but it’s useless using it as a reference now. The fact is that the Maltese Language article is a disputed so to speak article. Consensus is only reached through polls in such exceptional cases. Such cases require voting (read between the lines).
- Revert as much as you want, I certainly won’t engage in a editing war. What I was doing was for the best interest for Wikipedia anyway. In fact it was in the header encouraging users to create sub pages for archiving. Anyway don’t worry next time we’ll wait for you to create the sub page since you seem to know how to go about it. Bye --Gian (talk) 01:26, 14 May 2008 (UTC)
Natural spoken languages only
Any rationale?201.82.32.151 (talk) 02:12, 18 May 2008 (UTC)
- Wikipedia talk:WikiProject Phonetics/Archive 2#Proposed style guidelines — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 02:42, 18 May 2008 (UTC)
Quebec stops
Hi Aeusoes1,
you removed my claim about coronal stops in Quebec French, which is fine, but you marked it as minor, which is surely not what you intended. Anyway, I will not put it back into the article until I find a good source for it. IIRC, the difference between dental/alveolar in Canada and France is the reason why English loanwords with /th/ are pronounced with [t] in Quebec ([tri]) but with [s] in France ([sri]). Quebeckers keep the place of articulation, but change the manner from fricative to stop, while Europeans keep the manner but change the place from dental to alveolar.
I also noticed that you changed the ligatures for ts and dz. Is this due to browser problems? Actually, the release of dental stops is only very slightly affricated, so that I would prefer sth like ts, ( t<sup>s</sup>, ), but rather in Unicode instead of superscript. This is also what is often used in the literature. What is your opinion on this? Jasy jatere (talk) 09:27, 20 May 2008 (UTC)
Old Church Slavonic IPA cleanup
Hi. You placed an IPA tag on the article, but it looks like all of the pronunciation is in IPA to me. Okay to remove it? Thanks. —Michael Z. 2008-05-30 06:04 z
- There are a few places that look like a transcription system but with brackets. I think I'm familiar enough with OCS to fix it myself, so yeah you can remove it. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 06:09, 30 May 2008 (UTC)
Dutch dark l
Hi, I suggest you put the remark about the Dutch velarised l you removed today back in. To me it is so obvious that I didn't even check the Dutch phonology article because I just couldn't believe the article would not mention this sound. For your information, the l is pronounced in Dutch very much the same as it is in English, ask any native speaker. You may put it back with a "citation needed" tag (not that I am fond of these, but if necessary, okay) while I look for a proper reference. Steinbach (fka Caesarion) 21:53, 1 June 2008 (UTC)
- I added a ref for this. (sorry for butting in.) – ishwar (speak) 22:28, 1 June 2008 (UTC)
- Thanks a lot. This l is not typically Belgian, though. On the contrary, the l is generally darker in Netherlands Dutch. In the Amsterdam dialect, the dark l even occurs in all instances, which seems also quite noteworthy to me. I will search on for more references. Steinbach (fka Caesarion) 08:02, 2 June 2008 (UTC)
- Ooh, if you can find a source for that, that would be great. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 13:32, 2 June 2008 (UTC)
- Thanks a lot. This l is not typically Belgian, though. On the contrary, the l is generally darker in Netherlands Dutch. In the Amsterdam dialect, the dark l even occurs in all instances, which seems also quite noteworthy to me. I will search on for more references. Steinbach (fka Caesarion) 08:02, 2 June 2008 (UTC)
John Titor - rv, unsourced speculation
The proper process to challenge an editor's well-meaning, but unsourced edit, is to request a source using the WP:FACT tag. I am going to undo your revert, place the fact tags next to the edits, and I will find suitable sources for you. Thank you for your understanding. --ž¥łǿχ (ŧäłķ | čøŋŧřīъ§) 13:43, 3 June 2008 (UTC)
- I have added four sources to different arguments being presented about Titor's Olympics predictions. For another example, feel free to visit the talk page discussion for this very article. Thank you, and happy editing. :) --ž¥łǿχ (ŧäłķ | čøŋŧřīъ§) 13:59, 3 June 2008 (UTC)
- While it's true that a {{fact}} tag can be placed to give editors time to source information, the Summer Olympics item had been disputed for a while before August 2007 when I began removing it completely. I've removed most of the links you provided as they pointed to the 2008 Olympics but didn't make the explicit claim that JT meant Summer Olympics and not Winter Olympics. Thanks for adding a reference, though. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 21:13, 7 June 2008 (UTC)
- Wow, you sure seem uncooperative, but whatever, WP:OWN away. --ž¥łǿχ (ŧäłķ | čøŋŧřīъ§) 13:34, 9 June 2008 (UTC)
- I fail to see how this is either uncooperative or owning. Perhaps I have higher standards regarding sourcing. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 01:49, 10 June 2008 (UTC)
- Wow, you sure seem uncooperative, but whatever, WP:OWN away. --ž¥łǿχ (ŧäłķ | čøŋŧřīъ§) 13:34, 9 June 2008 (UTC)
- While it's true that a {{fact}} tag can be placed to give editors time to source information, the Summer Olympics item had been disputed for a while before August 2007 when I began removing it completely. I've removed most of the links you provided as they pointed to the 2008 Olympics but didn't make the explicit claim that JT meant Summer Olympics and not Winter Olympics. Thanks for adding a reference, though. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 21:13, 7 June 2008 (UTC)
diphthongs
Hi Aeusoes,
With the Germanic languages you've worked on, do you know whether the diphthongs are rising or falling? I'm wondering how the < ̯> fits in with the length diacritic. kwami (talk) 20:59, 3 June 2008 (UTC)
Yiddish consonants
I notice you added a large number of consonants to the Yiddish consonant chart. I was wondering what your source for this is. Is it Kleine 2003? The previous chart seemed much more accurate. If you can, please provide examples for each phoneme from your source. Firespeaker (talk) 16:19, 4 June 2008 (UTC)
Based on some other comments on here, I'm going to say I suspect your source for the Yiddish consonants. If you can't provide examples of each consonant within a few days, I'm going to revert your changes to the chart, assuming that your source is questionable at best. If you could provide me with a copy of the relevant parts of your source, that might help too. Firespeaker (talk) 07:41, 5 June 2008 (UTC)
- Yikes! Is Kleine 2003 questionable? — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 13:13, 5 June 2008 (UTC)
- Well, it doesn't at all seem to correspond to my knowledge of Yiddish. I'm open to the possibility that it's somehow right, but I'm pretty sure I can find sources that contradict it (not right now, but when I have access to a Western library again, in August or September). What was there before was much more in line with my own knowledge of Yiddish. The main problems now are the inclusion of /ɣ/, the palatal affricates and fricatives, and possibly the inclusion of the palatalised alveolars. Also, shouldn't those be considered dental in Yiddish? I'd also say the default /r/ is /ʀ/, since that's the one often used in teaching the language and stuff these days, but the footnote suffices on this. Firespeaker (talk) 10:56, 6 June 2008 (UTC)
Okay, this is the list of examples for the consonants that Kleine has. I've provided the exact transcription he uses and shown how I've adjusted it on our article on Yiddish phonology. These alterations include the removal of the tie bar, ɜ → ə and changing superscript j to just regular j. Strangely, he uses ɣ in the consonant chart on the preceding page (which is why I used it) but then switches to ʀ (which is confusing as [ʀ] is a trill, not a fricative) and then back to ɣ again. He uses χ consistantly throughout, but places it and ɣ in the "velar" column of the consonant chart. He also puts an italicized (i.e. nonphonemic) ʀ in the glottal column.
| sound | example | modified transcription |
actual | gloss |
|---|---|---|---|---|
| p | ʃtup | ʃtup | ʃtup | push (1 sg) |
| b | ʃtub | ʃtub | ʃtub | house |
| t | ˈtalɜs | ˈtaləs | taləs | talith |
| d | ˈdalɜs | ˈdaləs | daləs | poverty |
| f | ɔ͡ɜfn̩ | ɔəfn̩ | ? | manner |
| v | ɔ͡ɜvn̩ | ɔəvn̩ | ɔɪ̯vn | oven |
| k | kɾa͡ɛz | kɾaɛz | kʀaɪ̯z | circle |
| g | gɾa͡ɛz | gɾaɛz | gʀaɪ̯z | mistake |
| l | ˈkalɜ | ˈkalə | kalə | bride |
| ʎ | ˈkaʎɜ | ˈkaʎə | kalʲə | spoiled (ruined) |
| s | saχ | saχ | saχ | plenty |
| z | zaχ | zaχ | zaχ | thing |
| ʃ | ˈʃabɜs | ˈʃabəs | ʃabəs | sabbath |
| ʒ | ˈʒabɜs | ˈʒabəs | ʒabəs | frogs |
| m | mɛs | mɛs | ? | corpse |
| n | nɛs | nɛs | nɛs | wonder (miracle) |
| χ | ˈχ͡aɛʲɜ | ˈχaɛjə | χa(ɪ̯)jə | animal (beast) |
| ʀ | ˈʀa͡ɛʲɜ | ˈɣaɛjə | ʀa(ɪ̯)jə | piece of evidence (proof) |
| ɾ | ˈmɔ͡ɜɾɜd | ˈmɔɜɾəd | mɔɪ̯ʀəd | rebel (rebelling) |
| h | hɜt | hət | hɛt | so far (far) |
| dz | hald͡z | haldz | haldz | neck |
| ts | halt͡s | halts | (halt)? | hold it! |
I imagine, though, that none of these are controversial to you. While he doesn't include affricates or palatalized postalveolars, he states
There is a series of affricates in Yiddish. They may occur voiceless as combinations of [t] and [s] or [t] and [ʃ], forming [t͡s] and [t͡ʃ], along with the corresponding palatalized variants [t͡sʲ] and [t͡ʃʲ], as well as voiced in the combinations [d] plus [z] and [d] plus [ʒ], forming [d͡z] and [d͡ʒ], along with the corresponding palatalized variants [d͡zʲ] and [d͡ʒʲ]
.
I hope it's clear why I changed e.g. [d͡ʒʲ] to [dʑ]. I don't recall why I added the palatalized ɕ ʑ to the chart and see no reason not to delete them. He doesn’t provide any example words for any of them, which is pretty moopy. You can see why I asked if Kleine 2003 was questionable. Perhaps you've got some sources to better feature Yiddish consonants? — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 05:31, 7 June 2008 (UTC)
- Okay, no other source is needed. I added the actual words in, save a few forms that I don't know / can't find with available resources, which happen to also be irrelevant for the most part. As it turns out, it's not that the source is questionable, but rather inconsistent enough that if you don't know any Yiddish, you're going to have problems figuring out what it's saying. I've seen this before in many a language material—they're written as if for people who don't know anything about the language, but actually can't be used fully unless they do know something about the language. So /ɣ/ = /ʀ/ = /ɾ/ = /r/ etc. The affricates /ts/, /dz/, /tʃ/, and /dʒ/ exist. The palatal versions of these are rare, and are entirely Slavic borrowings. I think they can be analysed just as easily as affricate + /j/ (which I believe they often are), which can be said of /nʲ/ as well. This isn't the case for /ʎ/, which this author seems to misunderstand—there's /ɫ/, /ʎ/, and /lʲ/ I believe. A good source for this is the preface to Vaynrayx (Weinreich)'s dictionary, which unfortunately I don't have access to right now. And the best source for any of this is the set of books comprising Vaynrayx's linguistic description of Yiddish, written in Yiddish by a native speaker of Yiddish. Also note that your quote says nothing about the *phonemic* status of these sounds, which is what's important for this article. I understand why you thought it might be a good idea to change e.g. /dʒʲ/ to /dʑ/, but this is very wrong: in Yiddish there is a noticeable /j/ sound after the affricate, and it doesn't have much of an effect on the quality of the rest of the affricate. I'm going to go clean up your chart now. Firespeaker (talk) 10:56, 7 June 2008 (UTC)
- I'm calling into question Kleine (2003) then, because you're contradicting him/her in a number of ways. I don't know Yiddish well enough to determine who's correct so I'm not going to undo your change to the chart unless I find something else to use as a source.
- I think you misunderstand what ʲ means in the IPA, it is to mark the palatalization of a consonant, not a palatal offglide after the consonant. The IPA is weird in a number of ways and one of those is that [dʒʲ] = [dʑ]. If you'd like a detailed reason why, you can ask User:Kwamikagami. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 19:02, 7 June 2008 (UTC)
Catalan dialects map

Hello. I have seen that you have drawn the map of Catalan dialects that is currently shown in Catalan phonology, this is, this one in the right. It has a clear mistake as the brown dialect (Northern Catalan or rossellonès) is not spoken in Andorra. The variety used in there is very similar to that of Lleida (it distinguishes [e] and [a] in unstressed syllables) and therefore should be painted in blue (North-Western Catalan). In addition, I think that it is a bit risky to say that Balear and Alguerese form the same dialect, but as I have heard this opinion before (with the name català insular) it may be correct. --SMP - talk (en) - talk (ca) 19:13, 5 June 2008 (UTC)
Regarding your deletions of info from the Spanish phonology article
Don't want to sound harsh, but for someone who claims to have only a passing knowledge of my native language, I find it too bold that you merrily started to delete tons of info bits from this article that you thought were somehow "dubious" information, obviously because of your very limited knowledge of the subject language and your not having read much of the extensive bibliography dealing with its phonology (the most important and reliable part of which is, of course, published in Spanish itself by native-speaker scholars, not in English or by non-natives). No native speaker (let alone any scholar of Spanish) would have ever considered the existence of such phonological phenomena as the dropping of the "d" from participle endings (especially from the first conjugation -ado) to have even the slightest degree of dubiousness, because this is in fact by far the most common pronunciation in normal spontaneous speech (and one that native speakers are very well aware of, with puns and jokes about its ultracorrection, such as bacalado de Bilbado —just google it—), the "d" being actually pronounced only in formal or careful speech (or by beginner non-natives). Hell, even Alejandro Sanz went as far as to title one of his most well-known songs as Corazón partío (from his 1997 international-hit album más), deliberately displaying the actual colloquial pronunciation to give the song a more intimate character. Another incredible deletion I've noticed was that of the info about the weakening and diphthongization of mid vowels in hiatus, another very well-known phenomenon (intimately related to the phenomena of synalœpha and synæresis, which are very characteristic and defining of Spanish connected speech) that any native speaker has easily noticed in the speech of (not very educated) people from certain parts of Latin America (who say things like "pior" instead of "peor"—just watch an episode of El chavo del ocho and you're likely to hear some instance of this and similar phenomena, since in that show they liked to poke fun at such kind of "uneducated" pronunciations, sometimes to quite comical effect). This article once had lots of valid info on allophonic variants (such as the fact that "ch" is not a domed postalveolar [ʧ] in the Castilian dialect, but at the very least a palatalized [ʨ] or even a palatal affricate—sometimes even likened to a kind of palatalized "t" in some sources, which would be an unthinkable phonetic description for a [ʧ]), and mentioned interesting facts such as that the palatals [ɲ] and [ʎ] can contrast phonemically with the sequences [nj] and [lj] in minimal pairs (huraño/uranio, ello/helio), a relevant piece of information since this contrast is not phonemic in every language that uses those sounds (in fact, it's rather rare). Most of it easily verifiable info (at least for people native or fluent in the language who can actually read relevant references published in Spanish), but much of it now gone thanks to your unwarranted scything edits. I politely ask you to refrain from making more unconstructive deletions to this article until you get a fairly good grasp of its topic matter to know what you're actually doing, instead of relying almost entirely on the interpretation choices (such as the highly disputable claim that the phoneme /ʝ/ is supposedly an "approximant", when neither the actual pronunciation in most dialects —which is clearly a fricative, either palatal [ʝ] or postalveolar [ʒ] or [ʃ], as stated in a previous version of the article— nor the very IPA symbol, support that interpretation) and the apparent glaring omissions made by one English-language source. I find it unbelievable that this article doesn't even mention the fundamental work on Spanish phonology published in Spanish by renowned philologists such as Menéndez Pidal or Alarcos Llorach. No mention whatever is made about the scholarly controversies surrounding the phonological characterization of the semivocalic phones [j] and [w], either. In fact, the currect article reads like a high-school level paper at best, because of its complete lack of scholarly coverage and depth on a subject which has tons of published materials detailing every aspect of it, enough to comfortably piece together a comprehensive collection of articles on Spanish phonology topics as extensive and detailed as the one already available on Wikipedia for English phonology topics, instead of merely a quick and shallow overview of a few paragraphs where even some of the most well-known phenomena of Spanish phonology (such as the colloquial dropping of the "d" from participial -ado and -ido) aren't mentioned. 213.37.6.23 (talk) 21:46, 5 June 2008 (UTC)
- Thank you for taking interest in Spanish phonology. I agree that it is problematic currently in its incorporation of scholarly research (I was not familiar with the "one source" tag and I agree with your placement of it)
- The dropping of -d in participle endings was removed because it was uncited, not because I believe it is dubious. A scholarly source would be good to allow for specificity of its distribution (both grammatically and geographically)
- This is what the {{uncited}} tag is for. Firespeaker (talk) 11:08, 7 June 2008 (UTC)
- We can't simply operate as though it's okay to have uncited information as long as it has a {{fact}} tag. After a sufficient period of time in which other editors have been given to provide references, tagged info can be removed. Time has been given and no one has answered the call for a source, so it's gone until sourcing is found. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 20:19, 7 June 2008 (UTC)
- This is what the {{uncited}} tag is for. Firespeaker (talk) 11:08, 7 June 2008 (UTC)
- I'm not sure what you mean by "weakening and diphthongization" The article states "during fast speech, sequences of vowels in hiatus become diphthongs wherein one becomes non-syllabic". An anonymous contributor has attempted to claim that nonsyllabic /e/ and /o/ become /j/ and /w/. This contradicts the (sourced) statement already there and implies that maestro is pronounced like maistro, which I doubt. If there's dialectal variation on this, further sourcing can indicate this.
- Regarding [tʃ] vs. [tɕ]: Source it. The one source used uses the former. In regards to /ʝ/, the dialect covered by the sources are specific about how this is an approximant despite the IPA symbol. Of course, dialects other than Castilian may be different but sourcing is needed to address this. In regards to other allophony, again source it all and it's appropriate to include it.
- I'm confused as to why you're targeting me and assuming that I'm solely responsible for the poor coverage of the article. this is how the article appeared before I reworked it. I consider my edits to be an improvement. By all means, if you feel you can add information from Spanish-language scholars please do so. Be sure to source them, though. I can certainly stand back from the article while you (or someone else) do this so as to not step on your toes, but you're asking me to simply not edit it because I'm adding information you disagree with or removing information I don't agree with. I'll not do this, especially when a certain untrustworthy anonymous user adds uncited information. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 01:27, 6 June 2008 (UTC)
Proto-East-Slavic
Obsolete and misleading terminology like "Proto-Russian" and "Proto-East-Slavic" should be not be used whenever there are less ambiguous alternatives available. The sentence that mentions "Proto-East-Slavic" is paradoxical by itself, because it's in the context of 2nd palatalization "Some dialects (such as Proto-East Slavic), allowed the second regressive palatalization.." - but we know that 2nd palatalization didn't occur in Old Novgorod dialect, so how can it be traced to some hypothetical "Proto-East-Slavic" stage..? ^_^ --Ivan Štambuk (talk) 14:55, 7 June 2008 (UTC)
- I didn't know that PES was an obsolete term. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 18:48, 7 June 2008 (UTC)
- Well, it's obsolete in a sense "highly misleading when there are more precise terms available". The wording with PES implies that there was a hypothetical stage between 6th-century Proto-Slavic and all later attested East Slavic dialects that represented a common development, which there wasn't. Old Novgorod dialect didn't exhibit 2nd p. of velars at all, but is still classified East Slavic dialect (South/West/East Slavic are just geographical notations, nothing else). There are lots of books and papers that use terminology such as "Proto-Russian", "Proto-Polish"... (I once read a book that used "Proto-Serbian" - prasrpski ^_^), but these are then strictly defined prior to actual usage; i.e. the term itself is irrelevant, but what is meant by it matters. In this particular case, the author was almost certainly referring to a dialect ancestral to Old East Slavic, but unfortunately used the misleading "Proto-East Slavic" term. --Ivan Štambuk (talk) 19:08, 8 June 2008 (UTC)
Please do not remove content.
RP is not clearcut as the "standard" dialect of the UK, and in fact, several sources claim that EE is more so. 78.149.202.250 (talk) 16:04, 9 June 2008 (UTC)
- In addition to a problem with that assertion (They're not publishing dictionaries with EE pronunciation any time soon), you're making changes to the table that I disagree with. Also, and most importantly, there is no one uniform "Estuary English" as our article on Estuary English demonstrates. — Ƶ§œš¹ [aɪm ˈfɻɛ̃ⁿdˡi] 01:19, 10 June 2008 (UTC)
cat shit
Hey, I used your catshit example at affricate. Without attribution or humor, of course. You might change the example if you don't want to traumatize Little Leaguers. kwami (talk) 10:15, 12 June 2008 (UTC)
Ref tag
Could you try specifying your request for more citations at Swedish phonology? I consider the facts fairly easily to reference with the literature mentioned, so I'd really appreciate some specifications instead of making wild guesses at what you think needs to be cited. Why not specify your request a bit on the talkpage?
Peter Isotalo 15:52, 16 June 2008 (UTC)
Changes to Demonym
I've deleted the reference to Macedonia in this article, and explained my reasons in Discussion -- as I perhaps should have done in the first instance.
I'm concerned that this article's very interesting essentially non-political linguistic aspect not become buried in a wealth of politically-based (and often very transitory) group claims to special treatment, territory, self-governance and so on. The article is about what people chose to call themselves, and what others chose to call them.
The point that people choose to fight about it...well...people will fight about many things. That doesn't change the nature of the thing, itself.