
Wikipedia:Reference desk/Computing
![]()
of the Wikipedia reference desk.
Main page: Help searching Wikipedia
How can I get my question answered?
- Select the section of the desk that best fits the general topic of your question (see the navigation column to the right).
- Post your question to only one section, providing a short header that gives the topic of your question.
- Type '~~~~' (that is, four tilde characters) at the end – this signs and dates your contribution so we know who wrote what and when.
- Don't post personal contact information – it will be removed. Any answers will be provided here.
- Please be as specific as possible, and include all relevant context – the usefulness of answers may depend on the context.
- Note:
- We don't answer (and may remove) questions that require medical diagnosis or legal advice.
- We don't answer requests for opinions, predictions or debate.
- We don't do your homework for you, though we'll help you past the stuck point.
- We don't conduct original research or provide a free source of ideas, but we'll help you find information you need.
How do I answer a question?
Main page: Wikipedia:Reference desk/Guidelines
- The best answers address the question directly, and back up facts with wikilinks and links to sources. Do not edit others' comments and do not give any medical or legal advice.
December 5
Answers.com
Hello. Why does Internet Explorer display "false" when I go to answers.com? How can I fix that? Thanks in advance. --Mayfare (talk) 03:39, 5 December 2010 (UTC)
- What, exactly, displays "false" when you go to that site? Dismas|(talk) 03:46, 5 December 2010 (UTC)
A white webpage with false in Times New Roman at the upper left corner --Mayfare (talk) 04:07, 5 December 2010 (UTC)
- I'm guessing that you are a using are old browser ( Chrome 9 didn't play up), so go to Firefox, a newer IE version or Chrome. General Rommel (talk) 10:13, 5 December 2010 (UTC)
Very messy, ambiguous naming
Hi, I cant seem to find out the name of my HTC smartphone. the network sold it as a HTC Snap (no further qualification). another network in the same country (canada) sells an identical phone as HTC Maple (no further qualification) and a third network sells a clearly different HTC Snap, so i think the one i bought it from are calling the Maple a Snap. the back of the phone under the battery also says MAPL100 which i beleive is a model number indicating which HTC Maple it is, not Snap! when i plug it in the computer, i get the name HTC Maple S520
googleing all those names just made me more confused because there is a host of other names american and european networks have tacked onto this device. so how the hell do i figure it out... can i find it from looking up the IMEI number?
current candidates i beleive it might be are HTC Maple 100, HTC Maple S520 or HTC Snap S520.
why does HTC make so many very similar but different devices anyway? and why do networks like to call them by their own stupid names?
Roberto75780 (talk) 05:12, 5 December 2010 (UTC)
- The HTC Maple (code name), HTC Snap (release name), HTC S520, HTC S521, HTC S522, HTC S523 AND the T-Mobile Dash 3G are all exactly the same phone. The only differences will be any customisations the operators make (this might be a physical change to the colour of casing/logos or software branding/applications), hardware wise they're identical. As for why they all call them by their own names... this I can't really answer I'm afraid. All HTC Devices have a codename whilst it's in development and a different name for actual release (often the code name still shows up in the software of the phone), but this isn't new and has been standard practice for as long as I can remember. ZX81 talk 05:45, 5 December 2010 (UTC)
okay, so maple would be like Longhorn is to Windows Vista, and the other names are just netwok assigned nicknames?? —Preceding unsigned comment added by Roberto75780 (talk • contribs) 22:19, 5 December 2010 (UTC)
Apostrophes in Inkscape
Hi. In, say, Microsoft Word and Photoshop, apostrophes and quotation marks are automatically converted into the appropriate ‘ “ ” ’ direction, from ' and "
Does anyone know if there's any way one can achieve this in other programmes such as Notepad and/or Inkscape without just copy-pasting the correct glyph in? Thanks! ╟─TreasuryTag►Regent─╢ 09:24, 5 December 2010 (UTC)
- Universal ways that can work in all applications, no. But you can paste these “smart quotes“ quickly from the Character Map. Or you can write your documents in "straight quotes" then post-process the documents with some kind of script. 118.96.165.219 (talk) 14:00, 5 December 2010 (UTC)
- One of my least favorite aspects about Inkscape — and one of the reasons that as a part-time designer I can't quite call it a professional application — is that is has exceptionally underdeveloped text support. (Bug reports filed on this and many other related usability issues usually get put under low priority, in preference to very odd and specific technical things that the programmers think a designer should care about.) Anyway, the only way to do this in Inkscape that I know of is either pasting in the glyphs or memorizing how they can be entered in manually with your operating system. --Mr.98 (talk) 16:01, 5 December 2010 (UTC)
- Or you can use a "keyboard remapper" or "keyboard macro" application to program two least used keys (or key combinations) to enter the quotes. 118.96.165.219 (talk) 16:26, 5 December 2010 (UTC)
- I would not recommend copying and pasting from Word or other Office products because you may end up with something like this: "This isn?t right!". Use the character map and make sure that the encoding is set correctly (as a general rule, use UTF-8 everywhere unless there's good reason to use something else). As for Notepad, you may want to use WordPad instead (it's "smarter" in many areas, including encoding). --NYKevin @213, i.e. 04:07, 9 December 2010 (UTC)
Term for an easy computer to hack
What term do hackers use to refer to an easy target? 169.231.15.25 (talk) 09:58, 5 December 2010 (UTC)
- A honeypot? 118.96.165.219 (talk) 14:00, 5 December 2010 (UTC)
- A honeypot is something else entirely. --Mr.98 (talk) 18:05, 5 December 2010 (UTC)
- Vulnerable, exploitable 82.44.55.25 (talk) 15:19, 5 December 2010 (UTC)
- Windows, Apple. ¦ Reisio (talk) 15:42, 5 December 2010 (UTC)
- Simply hilarious. Thanks for that. — Waterfox ~talk~ 18:28, 5 December 2010 (UTC)
- I would say a vulnerable target. — Waterfox ~talk~ 18:28, 5 December 2010 (UTC)
- It is rare that hackers hack anymore. The "easy target" is called a "user". Just promise something like an image of boobs and the user will install anything you ask. -- kainaw™ 17:43, 6 December 2010 (UTC)
- Does that mean female computer users never install viruses? —Preceding unsigned comment added by 88.134.16.73 (talk) 17:50, 6 December 2010 (UTC)
- No, for female users, you promise software that will help them _show_ boobs. ¦ Reisio (talk) 07:36, 7 December 2010 (UTC)
- Kainaw's brusque post was meant to illustrate the importance of social engineering in surreptitiously deploying malware. Different methods of social-engineering are effective against different kinds of targets. See also, scareware, ransomware, "moralityware", and so on. I think it's a fair and accurate statement to say that at present, the overwhelming majority of trojan software uses pornography as the bait; in second place is malware that uses promises to aid or provide access to pirated music or videos as bait. Nimur (talk) 19:16, 6 December 2010 (UTC)
- Does that mean female computer users never install viruses? —Preceding unsigned comment added by 88.134.16.73 (talk) 17:50, 6 December 2010 (UTC)
Scope of CSE subjects in the present world
Pls tell me the scope of each branches(networking, programming etc.) under computer science engineering? —Preceding unsigned comment added by 117.207.162.21 (talk) 10:22, 5 December 2010 (UTC)
- Vast. --Sean 18:26, 6 December 2010 (UTC)
- Consider reading out outline of computer science and the articles linked from there. Nimur (talk) 19:17, 6 December 2010 (UTC)
Excel graph... help?!
I'm struggling with one of my graphs. I'll post an image below so you know what I'm talking about.
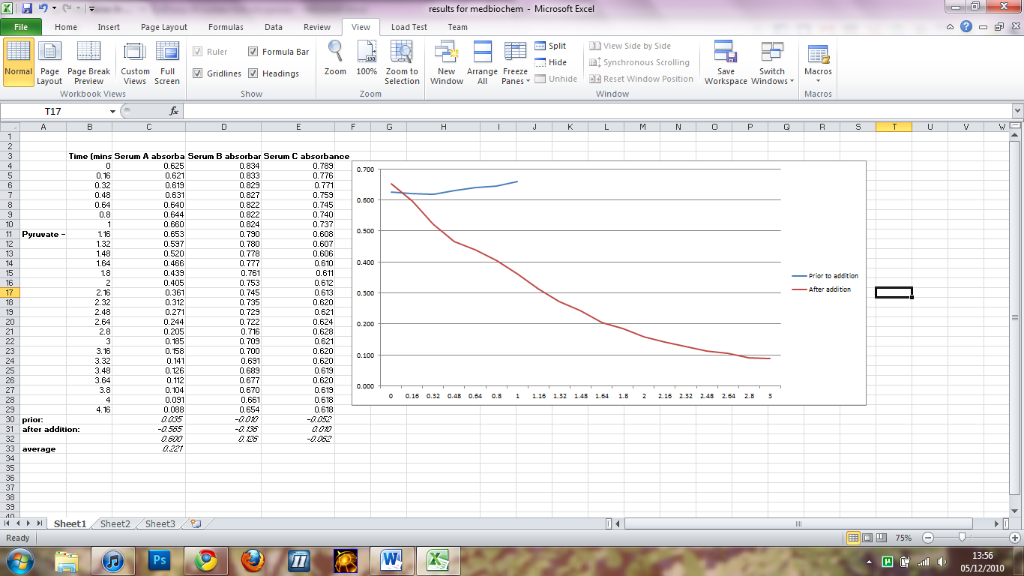{kind=link}
I have two data series, one called 'prior to addition' of a substance and one after. I am trying to link this to my X-axis which is time in minutes (in decimal form i.e. 1, 1.16, 1.32 etc). The prior to addition should start at time zero and the after should start at time=1 on the X-axis.
When I add these data series to my graph and select the time frame as my horizontal axis, for some reason, both start from time=0. This is very frustrating as I need the two lines separate on the graph.
Can anyone tell me what I'm doing wrong here? Thanks! Regards, --—Cyclonenim | Chat 14:07, 5 December 2010 (UTC)
- If I understand correctly, you have graphed the column headed "Serum A absorba" in two data series. The first series covers the timeperiod 0-1 (ie. Excel cells C4:C10), and is coloured blue. The second series covers the remaining time intervals, 1-4.16 minutes (ie. Excel cells C10:C29), and is coloured red. Unfortunately, while it seems obvious to us that they are time series and therefore one should follow the other, Excel doesn't know that the two data series should start from different places. The x-axis labels are just that... labels only and Excel make no assumption that they are anything to do with time.
- An easy solution is to create empty cells in both data series to represent the full time range. Copy the results to another column, relabel the original column as "Prior to addition" and label the copied column as "After addition". Blank out the parts of each column which does not apply to the situation and then graph both complete columns against the time labels. See this image for an example of what I mean). Astronaut (talk) 00:55, 6 December 2010 (UTC)
- You, sir, are a life saver! Thank you. 146.87.0.73 (talk) 11:09, 6 December 2010 (UTC)
- An alternative would be to try a Scatter Chart as the type of graph being used.--86.133.83.252 (talk) 15:40, 6 December 2010 (UTC)
{kind=link}
Why isnt the browser the boss?
When a browser connects with a website, as far as I am aware the browser sends the website some information about what software etc is installed on the user's computer (eg Java, Flash etc). The website then picks and chooses what content to provide the browser with.
Why isnt this done the other way around - the website sends the browser details of what the website can provide, and then the browser picks and chooses what it will take.
Wouldnt doing it this way provide greater privacy for the user? Thanks 92.15.1.139 (talk) 14:53, 5 December 2010 (UTC)
- I think websites still use your plugins in privacy mode, so that won't make a difference for this question.
- Web pages contain tags (<embed> and <object>) which mark where the flash, java, images (with <img>) should go. The browser makes the choice of whether to fetch the flash content. Normally it does so automatically, although installing an extension like Flashblock or NoScript to Firefox will make it ask you first.
- If flash isn't installed, the web page may provide an alternative version, eg: a text description. Web sites which follow the WAI guidelines will do this, but most don't provide a fallback.
- I've noticed that Internet Explorer sends extra information about what's installed (eg: the Windows Media Center version). This is included in a HTTP header. But if you're worried about privacy, you won't be using that anyway. --h2g2bob (talk) 17:15, 5 December 2010 (UTC)
- Browsers send information about themselves for convenience -- there's no point in a website sending information that the browser can't handle. Regarding the website sending the browser details of what the website can provide, that's actually what often happens, except that the information is used by the user rather than the browser itself -- it's what happens when you are on a navigation page. As the previous answer says, though, there are instances where the browser makes the decision -- for example, if you have images disable in your browser, it will choose to display a text description rather than download images. Looie496 (talk) 17:42, 5 December 2010 (UTC)
- It's worth asking whether things like whether you have Java, Flash, etc. really impinge on a notion of "privacy." How does a website knowing whether you have Flash installed or not affect your privacy? It is not personally identifiable information. The only personally identifiable information sent is generally an IP address, which is required if the site in question is going to know how to "reply" to the browser's request for information (it is the return address, to use a physical metaphor). --Mr.98 (talk) 18:00, 5 December 2010 (UTC)
- Actually, according to the Electronic Frontier Foundation, the amount of information a browser sends about itself, in totality, is normally enough to uniquely identify an individual installation, and thus the user (but not by name). The EFF have a test site at https://panopticlick.eff.org/. CS Miller (talk) 18:31, 5 December 2010 (UTC)
- Yes but that much information is generally sent in the form of the IP anyway. If you are concerned enough to hide your IP (e.g. via tor) presumably you are concerned enough to use a privacy mode or something similar, no? --Mr.98 (talk) 19:23, 5 December 2010 (UTC)
- Using privacy mode does not stop the above working; and I like to record my history. 92.15.31.223 (talk) 19:28, 5 December 2010 (UTC)
- Even if you don't feel the need to use TOR, panoptclick shows a browser can be tracked through open wifi points, forcing a DHCP IP number change, etc. CS Miller (talk) 19:34, 5 December 2010 (UTC)
- Yes but that much information is generally sent in the form of the IP anyway. If you are concerned enough to hide your IP (e.g. via tor) presumably you are concerned enough to use a privacy mode or something similar, no? --Mr.98 (talk) 19:23, 5 December 2010 (UTC)
- Actually, according to the Electronic Frontier Foundation, the amount of information a browser sends about itself, in totality, is normally enough to uniquely identify an individual installation, and thus the user (but not by name). The EFF have a test site at https://panopticlick.eff.org/. CS Miller (talk) 18:31, 5 December 2010 (UTC)
- A functionally correct answer might also be that the internet, the web, and HTTP, etc. were not designed with privacy in mind. (Or security, or spam, or a million other things that plague us.) --Mr.98 (talk) 19:25, 5 December 2010 (UTC)
- The browser is the boss: every single piece of content that is downloaded is the result of a browser-initiated HTTP GET. It is not possible for a server to send content that the browser did not ask for. Whether the user is in control of the browser is a whole other story: how technically proficient is the user? Does the user understand the details of using client-side scripts, browser-plugins, and other web features? (These delegate decision-making about transactions and server-requests to scripts and programs that are not typically under the direct control of the user). If the user wants to guarantee that there is no web-traffic that is not the direct consequence of a user-action, then they must disable client-side scriping (JavaScript, usually), and disable all browser plugins (Adobe Flash, Java, and so forth). They should also consider disabling any browser-enhancing add-ons; turn off any automatic content requests (like RSS feed readers); and really, consider using a different environment (such as wget, lynx, or operating a tightly-controlled proxy-server to control all HTTP transactions. WGET will never talk to a server, or receive content from it, unless the user specifically asks for it; once a page is downloaded, a user could render it with a standard browser like Internet Explorer or Firefox that is configured to work "offline" (with no network connection). Nimur (talk) 19:23, 6 December 2010 (UTC)
- As I understand it, that's sort of misleading. Every transaction starts with a request from the client, true, but after that in principle the server can send any sort of stream of data to the browser that it wants to. Looie496 (talk) 00:54, 7 December 2010 (UTC)
- The server may send exactly one stream of arbitrary data of arbitrary length in response to one HTTP GET request. If your browser chooses to interpret that stream (for example, by processing an HTML <image> or <embed> tag), the browser makes another HTTP GET request for each image/link it chooses to load. If the server sends HTML that offers a JavaScript script, the browser may also choose to execute that script (and the script may initiate additional server-transactions). Similarly, if the server sends binary data for a plugin, the plugin may make have the option to execute further transactions (or run arbitrary code, depending on the plugin). But if you use wget, and do not specify to download links, there will be exactly one server-to-client transaction. In any case, the server can not send data unless the client opens a socket first (typically by performing an HTTP GET request; but also by running JavaScript or binary plugin code that opens a socket). Again, the confusion comes because the OP asked if the browser or the server is in control of the transaction: in fact, it's always the browser; even if the user may not be directly controlling the browser's actions. Nimur (talk) 02:14, 7 December 2010 (UTC)
- As I understand it, that's sort of misleading. Every transaction starts with a request from the client, true, but after that in principle the server can send any sort of stream of data to the browser that it wants to. Looie496 (talk) 00:54, 7 December 2010 (UTC)
how do I start a billion-dollar company with an unemployed bay area programmer?
Hi,
I would like to start a billion-dollar company with an unemployed but engenius bay area programmer. My idea is that perhaps I could find one who has no real personal project portfolio (just stuff he worked on for companies, nothing tied closely to his name), then he would do the work as long as he is convinced that it will look good on his portfolio and land him a really golden job when he's done*. I don't expect him, or anyone, to agree with me that it is a bilion-dollar idea. In fact, I expect people to disagree with me even when the market valuates the resulting company at a billion dollars -- I expect them to say the market is being delusional. So be it. My question is how I get the cooperation in the first place. I've had a programmer say "yes, yes!" and then completely disappear out of contact. I'm based in Europe, so how do I do what I'm trying to do? I am looking for someone really engenius who would be highly motivated by equity, not someone I can just rent for anywhere between 8 and 80 dollars per hour, depending on what I'm looking for. Again, the idea is that the person is out of work and doesn't happen to have a great project portfolio, sees that putting the work into the project in question (even if it is worthless), because it is interesting and will be highly visible, is by far the best investment he can make of his time for the next couple of weeks (because of his name in it), he will not have direct costs on the project (he will just be sitting at his computer at home, doing this instead of surfing reddit and slashdot), and, due to being out of work, very low opportunity cost. Can I do it? How? Thank you very much for any help you have on this question! 82.98.48.252 (talk) 20:35, 5 December 2010 (UTC)
'* little will he realize at that point that he will not want to work as a for-hire programmer when he's finished, since he will be worth so much he won't have to! He will realize this later, of course... 82.98.48.252 (talk) 20:41, 5 December 2010 (UTC)
- You need to think big if you're going to succeed. Aim at starting a zillion dollar business.--Aspro (talk) 21:05, 5 December 2010 (UTC)
- Why not just pay him/her some money, and impress them by spelling ingenious correctly. 92.15.8.71 (talk) 22:50, 5 December 2010 (UTC)
- Searching for an ingenuous programmer makes more sense here. Trustinchaos (talk) 23:39, 5 December 2010 (UTC)
- Please check out this related discussion. 84.93.178.188 (talk) 23:18, 5 December 2010 (UTC)
- If you're so certain you can make a fortune, why not pay the guy? Take out a loan. Mortgage your house, heck even get an advance on your credit card!
- Sure, taking on debt to start a business is a risk, but so what? Asking the programmer to take a risk that you're not willing to take yourself will not inspire confidence or attract volunteers! APL (talk) 00:58, 6 December 2010 (UTC)
- Indeed it's not entirely certain what the OP is providing the programmer out of this deal Nil Einne (talk) 05:02, 6 December 2010 (UTC)
- Something else programmers like is recognition. So put his name right on top of the credits, maybe even make him VP of the company. StuRat (talk) 04:03, 6 December 2010 (UTC)
- Unemployment among programmers, especially good programmers, is not very high. The same absurd profitability of the software business that makes get-rich-in-a-couple-weeks ideas like the above seem plausible (even though it doesn't really work like that) is the reason that many software companies are perpetually interviewing people. Paul (Stansifer) 15:28, 6 December 2010 (UTC)
- This post ("I Just Need a Programmer" by CS professor Eugene Wallingford is both timely and apt. Apt! -- 16:06, 6 December 2010 (UTC)
- Avoid saying anything like "Here's $50. Now program something that will make me billions". You have to have a good idea of what you want. Why not study computing and write it yourself? 92.29.120.120 (talk) 18:40, 6 December 2010 (UTC)
- Do you understand how much a qualified programmer can earn in the Bay Area? More than most doctors and lawyers' starting salaries. You will really have to entice a qualified programmer to give up their career prospects by offering them a little bit more than "an idea that might be worth billions." If you're seeking an unqualified programmer, you might want to re-think your business idea. Nimur (talk) 19:31, 6 December 2010 (UTC)
- Though, I would note, if you're just trying to get something together that will look like it can work, you need not necessarily have a genius programmer. Facebook in its full form needs some very bright people involved to take care of the strains that come with scaling up to crazy degrees, but Facebook in its first incarnation really did not need more than a couple fairly competent programmers. Depending on the software in question, that may or may not be an option (obviously if your software involves doing something brilliant — like having exceptionally clever visual analysis algorithms — you can't do a "dumb" version). But anyway, I agree with the general sentiment that if the OP is confident that the idea is worth a billion dollars, he or she should be able to find a way to just pay the damn programmer. --Mr.98 (talk) 21:43, 6 December 2010 (UTC)
op here. geez' you guys want me to be a capitalist exploiter so bad!
My skills are as a manager. What you guys want me to do, is use the fact that I was born into better means than the Californian programmer, learned French starting at a young age, live in Paris, and so on, in short, the things that allowed me to come by some not insubstantial amount of capital, and use it to buy the product of the programmer. See, the programmer produces something, under my direction, that will be worth considerable money. We both provide labor: I, the management labor (did Napolean personally conquer North Africa), he the programming labor. The end result is worth whatever it is worth. Let's say it is worth 0.05% of what I think it will be worth. That's $500,000. You want me to be a capitalist exploiter, and take nearly all of the $500,000 produced by our joint labor, giving the poor programmer only $50,000 for his 1000 hours of time, keeping $450,000 for my time, however little it may have been? Do you think that's really fair??? I'm trying to see your point of view here, but since I don't believe in capitalist exploitation, I really can't. This is why I would like an equity-based solution, where I can contribute my management skills and the programmer can contribute his coding skills on a percentage-of-the-project basis. Is it really that hard to see? Do you really just want me to exploit someone? 82.234.207.120 (talk) 22:12, 6 December 2010 (UTC)
- If you are looking for a single programer that programer is not looking for a manager. You don't need, or even want, a manager in a two man team. The "capitalist exploiter" usually provides venture capital. Taemyr (talk) 22:25, 6 December 2010 (UTC)
- India is well-known by their outsourcing oriented IT industry. And believe me, if you pay these guys $1,000/month they won't be feeling exploited. I don't know that living in Paris and speaking French has to do in this discussion. Mr.K. (talk) 23:26, 6 December 2010 (UTC)
- You can create a privately-held company and offer a compensation package, in the form of stock, equity, or so forth. It doesn't really matter, though. You're trying to undercut the market-value of a quality programmer by under-compensating him/her. Programmers can receive stock (equity in the company) at any small, medium, or large enterprise, on top of a salary. Nimur (talk) 00:38, 7 December 2010 (UTC)
- Let me also suggest, as someone who does not have a lot of money at the moment, that belief in the future success of a company does not pay the bills of today. Your scheme is actually very exploitive — you're asking for labor which is unpaid except on the condition that the company is a success, and there can be plenty of reasons that it might not be a success even if the idea is indeed a good one. You could, for example, be hit by a bus when 75% of the work is done, and then what would the poor programmer be able to do without your management skills there to guide him? --Mr.98 (talk) 01:01, 7 December 2010 (UTC)
- Yes, It is very exploitative to say "Make me rich, and if and when it works I'll give you part of it." (You might as well ask the programmer to buy you lotto tickets.)
- If you want to be non-exploitative about it, start a company and give the guy salary and stock. You may very well be able to find people who will take a somewhat below-market salary in exchange for stock, but you will have a very difficult time finding someone who will wager their entire salary. APL (talk) 02:04, 8 December 2010 (UTC)
- Indeed it's not clear whether the OP planned to give the programmer equal shares, which is seemed deserved at a minimum (given that it's still not really clear what the OP brings to the table some would question whether the OP really deserves equal shares) in this partnership. Even if the OP planned to give equal shares the OP doesn't seem to appreciate that because of their advantages, they can perhaps afford to take a risk on this project since it sounds like even if it goes south, they'll still have something or someone who they can turn to support them. Many people don't really have this luxury, quite a few won't even be able to survive that well during the time you're taking the risk and so you can't expect them to be willing to take the same risks and indeed it's likely to be offensive if you act like you are on equal footing. (Some people even have dependents and others they support so it's not even just themselves that will be in major strife.) Nil Einne (talk) 16:42, 9 December 2010 (UTC)
- Let me also suggest, as someone who does not have a lot of money at the moment, that belief in the future success of a company does not pay the bills of today. Your scheme is actually very exploitive — you're asking for labor which is unpaid except on the condition that the company is a success, and there can be plenty of reasons that it might not be a success even if the idea is indeed a good one. You could, for example, be hit by a bus when 75% of the work is done, and then what would the poor programmer be able to do without your management skills there to guide him? --Mr.98 (talk) 01:01, 7 December 2010 (UTC)
- You can create a privately-held company and offer a compensation package, in the form of stock, equity, or so forth. It doesn't really matter, though. You're trying to undercut the market-value of a quality programmer by under-compensating him/her. Programmers can receive stock (equity in the company) at any small, medium, or large enterprise, on top of a salary. Nimur (talk) 00:38, 7 December 2010 (UTC)
- India is well-known by their outsourcing oriented IT industry. And believe me, if you pay these guys $1,000/month they won't be feeling exploited. I don't know that living in Paris and speaking French has to do in this discussion. Mr.K. (talk) 23:26, 6 December 2010 (UTC)
- This letter is relevant. (Not safe for some workplaces due to occasional vulgar language and one illustration.) "If the deal goes ahead there will be some good money in it for you." Comet Tuttle (talk) 01:37, 7 December 2010 (UTC)
- No, we want you to have a realistic understanding of what you bring to the table. Most programmers already have a number of ideas that they believe "could" become the Next Big Thing. If a programmer has a couple of months off to work on a project, why would they buy an idea from you? So they will place next to no value on your idea.
- Next you bring "managment" to the table. That's great, but it's not really applicable in the early stages of this sort of endeavor. The programmer could hire managers if and when they become necessary. "Management" is no less a commodity than "Programming".
- (Many programmers have started The Next Big Website on their own without a manager, how many managers have done so without a programmer?)
- To recap: To start a zillion dollar, Next Big Thing, website you will need a programmer most, a graphic artist second, a marketing expert third, a manager/businessman fourth, and an "Idea Person" least of all. (And of course, a lot of luck.) APL (talk) 02:04, 8 December 2010 (UTC)
- (P.S. If I was a soldier for Napoleon, I would expect to get paid regardless of whether or not Napoleon conquered the known world.) APL (talk) 02:06, 8 December 2010 (UTC)
Java Out of Memory Error
How can I have Java use more memory for handling large ArrayLists of ArrayLists so that it doesn't give me an Out of Memory Error? --70.134.49.69 (talk) 21:08, 5 December 2010 (UTC)
- If you're using the Sun/Oracle Java runtime, the -Xmx option lets you set the maximum heap size. This is a nonstandard option, so other Java runtimes may use different options. -- Finlay McWalter ☻ Talk 23:26, 5 December 2010 (UTC)
December 6
Transferring files from PC to iMac
My brand spanking new iMac will be arriving in a few days (I can't wait) (27" Intel Core i7 4gb). My piece of shit Dell Dimension 2400 has a lot of files on it I am going to want to transfer before setting it on fire. The Dell has an ethernet port and two USB ports (I think). Can anyone walk me through how and what I will need for the transfer? Any special cables? Any special adaptors for the cables the iMac will come with? I would do it all by emailing the files to myself, but first I have many video files that are too large for my free email services to attach, and anyway, it would take a huge amount of time even if the Dell worked right, but its internet connection is screwed up and its upload speed... it would take about an hour to attach even a 20 MB files (though more likely I would get an error about halfway through the upload). I know you get a lot of questions from IPs who don't bother to check back but I will be watching for responses. Thanks so much.--162.84.137.228 (talk) 05:59, 6 December 2010 (UTC)
- I think this is the link you want: PC to Mac Migration. If you have any questions, post them here or email me. You will be so much happier with a mac I can't even begin to tell you. congratulations!. Lugwigs, please sign, thanks, User:General Rommel
- Thanks for the link. Looks perfect.--162.84.137.228 (talk) 13:16, 6 December 2010 (UTC)
Download
For downloading millions of links in a site, what is the best program? Wget and httrack both crash past about 200,000 links. I'm on Windows 7 82.44.55.25 (talk) 12:04, 6 December 2010 (UTC)
- P.S. They also have Portable Offline Browser, in case you want to download a site in a restricted computer :-) 118.96.162.25 (talk) 14:49, 6 December 2010 (UTC)
- When you say "wget and httrack both crash", are you sure that you don't mean that your computer ran out of memory? If so, it won't matter what program you use; you will have to implement a staged download, where you only download a few tens of thousands of items at a time, and then start downloading the next batch. Nimur (talk) 20:42, 6 December 2010 (UTC)
- Surely it matters what program the original poster uses; the programs he or she mentioned might use RAM very inefficiently, while a more defensively-written program might write stuff out to hard disk a lot, minimize the use of RAM, and handle far larger websites. Comet Tuttle (talk) 21:53, 6 December 2010 (UTC)
Dell Studio 1555 Only sometimes start up now
I had a one-year old Dell Studio 1555 laptop with Windows 7 running.
Recently, I've been having troubles starting up the computer. Usually, I just hold the "power" button on the side for about a second and the computer starts up. But now, I could be pressing the button many times and for various lengths of time and it wouldn't start up and then, all of a sudden, I press power again and it starts up and runs as usual.
EDIT: When it won't turn on, I mean that when I press the power button, there is no reaction whatsoever from the computer, it won't even go to the BIOS or anything, screen doesn't change, makes no sounds, etc... The battery is fully charged and the power cord works.
Furthermore, recently, it's been making these really loud sounds reminiscent of a 1990's computer processing sound. It's like that tick-tick sound that the computer makes when it's processing a heavy load.
I don't think it's an overheating problem because the fan isn't stressed and I successfully de-dusted. What could be the problem? Is this likely a sign of imminent all-out failure? Could a jumper switch have been dislodged from the circuit board? If so, how difficult is it to replace it myself?Acceptable (talk) 21:53, 6 December 2010 (UTC)
- I'm not sure, but is it a faulty connection at the power button? General Rommel (talk) 06:46, 7 December 2010 (UTC)
Number of characters in file path limit?
The entry on filename mentions specific character length limits on individual filenames. But what are the limits (if any) on a file's entire absolute path? --70.167.58.6 (talk) 23:05, 6 December 2010 (UTC)
- Which OS are you interested in? The answer will vary depending on your answer. Comet Tuttle (talk) 23:07, 6 December 2010 (UTC)
- It's not quite standard:
- These are all in these platforms' respective C language APIs; they may not be available (or perhaps even meaningful) in non-C wrappers of the same functionality. -- Finlay McWalter ☻ Talk 23:18, 6 December 2010 (UTC)
- Note that, for Windows, it's a bit more complex than just MAX_PATH. As the docs for CreateFile note, MAX_PATH is for ANSI filenames. To get Unicode filenames (which NTFS limits at 32,767 unicode chars) you need to prepend the path with a UNC "\\?\ prefix. -- Finlay McWalter ☻ Talk 00:06, 7 December 2010 (UTC)
- Further, posix defines a function pathconf which (if I understand what it's supposed to do) allows you to get the max path length for files on a given filesystem (as some filesystems impose very different limits). But, on my Linux system, it returns the same for every filesystem I try it on (ext3, iso9660, udf, fat32, procfs, sysfs, tmpfs), a value that's == PATH_MAX (4096). I'd be interested in what folks get on OS-X and in particular on a system with ZFS.
| test program |
|---|
| The following discussion has been closed. Please do not modify it. |
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <unistd.h>
int main(int argc, char** argv){
if(argc!=2){
fprintf(stderr, "usage:\n %s filename\n", argv[0]);
exit(EXIT_FAILURE);
}
printf ("MAX_PATH is %d\n", PATH_MAX);
printf ("_PC_PATH_MAX (for %s) is %ld\n",
argv[1],
pathconf(argv[1], _PC_PATH_MAX));
return 0;
}
|
- Above are the operating system's limits. As I alluded to, the relevant file system also sets limits - these are shown in a column of the table at Comparison of file systems#Limits. Many file systems have theoretically unlimited path lengths, as subdirectories are just a link, and sub-sub directories can be linked essentially forever (until the storage is exhausted). In practice you have to work with the lower of the OS' limit and the FS' limit. -- Finlay McWalter ☻ Talk 00:18, 7 December 2010 (UTC)
- The NT kernel (the actual OS of modern versions of Windows) works with length-prefixed UTF-16 strings. They are limited to 32,767 UTF-16 words because the length is 16 bits and counts bytes rather than words. It's not a limit of NTFS as such, just a limit of the NT driver, though that does make it a de facto limitation of NTFS. The MAX_PATH (=260) limit comes from the user-mode Win32 library, which you aren't obliged to use (though nearly everyone does). One application/system that bypasses it is Cygwin 1.7, which lets you use path lengths up to the NT limit (and also filenames containing some of the characters that the filesystem article currently claims, incorrectly, are forbidden). -- BenRG (talk) 00:34, 7 December 2010 (UTC)
- So 260 characters is the most common max limit of Windows paths. (I'm assuming most app developers stick with this to ensure compatibility with other apps?) How about Mac OS X's max limit? --70.167.58.6 (talk) 17:00, 7 December 2010 (UTC)
- Unlimited at the filesystem level, apparently, but the above caveats apply. --Sean 20:13, 7 December 2010 (UTC)
- So 260 characters is the most common max limit of Windows paths. (I'm assuming most app developers stick with this to ensure compatibility with other apps?) How about Mac OS X's max limit? --70.167.58.6 (talk) 17:00, 7 December 2010 (UTC)
installation of windows98 on oracle vm virtual .box
I have windows xp and core2 due process.i have installed recently windows 98 on Oracle VM virtual box.But when I have tried to play some games on it, they donot work prperly,for example character in dave 1 moves very fast .How can i fix this problem. —Preceding unsigned comment added by True path finder (talk • contribs) 23:38, 6 December 2010 (UTC)
- Do the games require DirectX? VirtualBox DirectX support isn't great, I suspect that is probably the problem. 82.44.55.25 (talk) 23:56, 6 December 2010 (UTC)
- Take a look at DOSBox and see if that fixes the problem. I tried playing X-COM on a Pentium 4 at one point and all went well except the scrolling was so fast the game was unplayable. Comet Tuttle (talk) 01:34, 7 December 2010 (UTC)
fifa 98
I have installed Fifa 1998 on windows xp .which works only when i m online .otherwise a message appears as ," insufficient memory ..............", what should be the reason. —Preceding unsigned comment added by True path finder (talk • contribs) 23:52, 6 December 2010 (UTC)
- Is is designed for Windows XP? If not, try to put it under compatability mode. General Rommel (talk) 21:23, 7 December 2010 (UTC)
Problems with sound card in Linux: no sound
When I type lspci I get, among other things:
00:1f.5 Multimedia audio controller: Intel Corporation 82801DB/DBL/DBM (ICH4/ICH4-L/ICH4-M) AC'97 Audio Controller (rev 03)
So, the sound card is there, but it's not being used. How can I tell the computer to use it? Or what can I do to make it work? Mr.K. (talk) 23:57, 6 December 2010 (UTC)
- If your distribution uses PulseAudio, open the PulseAudio Volume Control (in Ubuntu it's in the applications->sound_and_video menu; I do not mean the little sound slider in the Gnome panel beside the clock) and make sure all the volume sliders are up, and that the output for the program you're trying to play sound from (e.g. VLC) is sent to the correct audio output (so start VLC playing a movie first, so it appears in the Volume Control application). -- Finlay McWalter ☻ Talk 00:23, 7 December 2010 (UTC)
You should seek real-time help: irc://irc.freenode.net/linux ¦ Reisio (talk) 07:39, 7 December 2010 (UTC)
December 7
Rexx versus Python
I used BASIC years ago, now I'd like to learn a more modern language. Most people say that Python is the one to go for, but I've just found out about Rexx. Rexx only has 23 instructions, so should be quick to learn.
Is there some disadvantage to Rexx that I've overlooked, that means I should spend the time learning some other language? Thanks. 92.15.18.168 (talk) 00:11, 7 December 2010 (UTC)
- Why are you learning it? If you want a language people actually use in real life, you want Python over Rexx. Marnanel (talk) 00:46, 7 December 2010 (UTC)
- The difficulty of a language is not related to the number of instructions. PHP has hundreds of possible functions, but it is actually a very easy language to learn, because its syntax is straightforward, extensible, and one is not expected to memorize the functions. There are only a dozen or so core "control structures" in PHP, for example, and the rest of the functions you just look up when you need them. (PHP is just an example I am familiar with; I am not lobbying for it over, say, Python.)
- Looking at the Rexx specs (spexx?), it strikes me that its lack of arrays and existing array functions would make a lot of things quite difficult (you'd have to develop workarounds that you would not need to in other languages), and its lack of easy ability to integrate external libraries means you'll have a harder time with code reuse (thus reinventing the wheel more than you ought to). All of this is aside from the fact that a less-used language is going to have fewer community resources (shared code, communities to ask questions of, functions developed that can do more "modern" things like interface with graphics or the web or etc.), totally non-transferrable code syntax (you're learning something that can basically only be used with itself, and cannot be a base for learning other languages), and is not very "modern" without having to use specific implementations which may or may not have their own buggy incompatibilities. Not to mention that if you did learn Rexx and its particular and peculiar ways of doing things, they would in many cases not be transferrable skills at all to other programming tasks (e.g. the way it handles "stems" is very non-standard). --Mr.98 (talk) 00:55, 7 December 2010 (UTC)
- It depends which Programming paradigm you want to learn.Smallman12q (talk) 02:29, 7 December 2010 (UTC)
- Another example of fewer functions not making a language easier is Brainfuck. 8 commands, but, as implied, more-or-less impossible to work with. KyuubiSeal (talk) 02:30, 7 December 2010 (UTC)
- If you need to chose one of them you should definitely chose Python, it has a easy syntax, good user manual/help pages/community, good development tools, a comprehensive standard library with many functions and a large set of third party libraries. So unless you going to use it in a special context were REXX is widely used/available chose Python. Python programs are easy to read yet the code are very compact so you get much done with little code to write. The main drawback is the execution speed it is about 30 times slower than a C or C++ program but I think REXX is even slower.--Gr8xoz (talk) 02:55, 7 December 2010 (UTC)
Why is Rexx available for many different OSs, and be put to so many uses, if its not very good? As it says somewhere "It’s as easy as Basic Yet about as powerful as Perl". It appears to be able to manipulate other programs eg spreadsheets or the OS easily. 92.15.11.224 (talk) 13:20, 7 December 2010 (UTC)
- What do you mean by "good"? Nobody here has said or implied that Rexx isn't powerful. Marnanel (talk) 13:22, 7 December 2010 (UTC)
- Huh? You're being disingenuous? Dosnt powerful imply good for programming languages? 92.15.11.224 (talk) 13:50, 7 December 2010 (UTC)
- Powerful is a pretty subjective term. It usually means either "you can do a lot with a little" or "this language can be used for many different tasks." There are plenty of "powerful" languages. As for why Rexx is widely used as a macro language, it's probably just because the tools for adding a Rexx interpreter into your program are straightforward. Anyway, nobody is trying to rank the languages objectively. But if you're going to learn ONE more language other than BASIC, Rexx is a very odd choice. --Mr.98 (talk) 14:38, 7 December 2010 (UTC)
- Just like human languages, there are loads of reasons to learn a computer program language. Maybe you want to expand your mind or think about things differently. Maybe you want to commuicate to a community who speaks that language. Maybe you have no choice, because your work requires you to communicate this way. I would say, as a rough analogy, that learning Rexx after Basic would be like learning Faroese after English. It's neat, and has a lot of unique cultural and historical significance; and if you happen to have a job which for some reason requires you to speak Faroese, there's not much of a choice. Because of similarity, with a little extra work, you might be able to port your Faroese skills to Norwegian, or Icelandic; but not as easily as you might hope. It will be hard to find good language training resources, because few people study Faroese. And when you're done, you'll find almost nobody else will be able to communicate in the language you have just invested so much effort to learn. Most of the world doesn't even know Faroese exists. That doesn't mean it wasn't worth learning - but keep all these counterpoints in mind. If you spend a lot of effort learning Rexx, you might be able to port some of those skills to Python or Perl; you might have a specific job that requires this programming skill; but mostly, you'll be engaging in a difficult intellectual exercise, with little practical use, in a subject that interests very few people. I won't even try tell you that's a bad thing. Nimur (talk) 16:16, 7 December 2010 (UTC)
- Its worth learning Faroese if a) it takes 10% (or whatever) of the time to learn another language, b) it is understood by everyone (ie its got interpreters for every OS), c) you can do all sorts of things with it that you cannot easily do in other languages, d) it is more concise than flowery other languages, e) the listeners/readers (ie the interpreter) does all the hard work, not the speaker. 92.29.123.221 (talk) 13:03, 8 December 2010 (UTC)
- In practical terms only, your premises b and c are false. For significant projects, you do not merely need the interpreter to understand you, but also other people to do so. Additionally, significant projects often already exist and it is much more practical to extend them in the language they are already using (which is almost certainly a mainstream language and not Rexx). Finally, because popular languages (let's say Python) have more libraries written for (or ported to) them, many useful things are trivial to do that would require a lot of effort in unpopular, less well supported languages (like Rexx). When you are just learning, none of these points seem relevant, because you aren't yet able to work on significant projects, and the programs you're writing are closer to hello world than to httpd. But unless you confine yourself to trivial work, these points will be relevant. --Tardis (talk) 15:47, 8 December 2010 (UTC)
- Its obvious from the question asked that the OP is not going to be doing this for a living but just some occassional hobby use now and again. I don't agree with your assertions. 92.29.113.166 (talk) 23:07, 8 December 2010 (UTC)
- In practical terms only, your premises b and c are false. For significant projects, you do not merely need the interpreter to understand you, but also other people to do so. Additionally, significant projects often already exist and it is much more practical to extend them in the language they are already using (which is almost certainly a mainstream language and not Rexx). Finally, because popular languages (let's say Python) have more libraries written for (or ported to) them, many useful things are trivial to do that would require a lot of effort in unpopular, less well supported languages (like Rexx). When you are just learning, none of these points seem relevant, because you aren't yet able to work on significant projects, and the programs you're writing are closer to hello world than to httpd. But unless you confine yourself to trivial work, these points will be relevant. --Tardis (talk) 15:47, 8 December 2010 (UTC)
- Its worth learning Faroese if a) it takes 10% (or whatever) of the time to learn another language, b) it is understood by everyone (ie its got interpreters for every OS), c) you can do all sorts of things with it that you cannot easily do in other languages, d) it is more concise than flowery other languages, e) the listeners/readers (ie the interpreter) does all the hard work, not the speaker. 92.29.123.221 (talk) 13:03, 8 December 2010 (UTC)
- An excellent analogy, great job. --Mr.98 (talk) 19:08, 7 December 2010 (UTC)
- Just like human languages, there are loads of reasons to learn a computer program language. Maybe you want to expand your mind or think about things differently. Maybe you want to commuicate to a community who speaks that language. Maybe you have no choice, because your work requires you to communicate this way. I would say, as a rough analogy, that learning Rexx after Basic would be like learning Faroese after English. It's neat, and has a lot of unique cultural and historical significance; and if you happen to have a job which for some reason requires you to speak Faroese, there's not much of a choice. Because of similarity, with a little extra work, you might be able to port your Faroese skills to Norwegian, or Icelandic; but not as easily as you might hope. It will be hard to find good language training resources, because few people study Faroese. And when you're done, you'll find almost nobody else will be able to communicate in the language you have just invested so much effort to learn. Most of the world doesn't even know Faroese exists. That doesn't mean it wasn't worth learning - but keep all these counterpoints in mind. If you spend a lot of effort learning Rexx, you might be able to port some of those skills to Python or Perl; you might have a specific job that requires this programming skill; but mostly, you'll be engaging in a difficult intellectual exercise, with little practical use, in a subject that interests very few people. I won't even try tell you that's a bad thing. Nimur (talk) 16:16, 7 December 2010 (UTC)
- Powerful is a pretty subjective term. It usually means either "you can do a lot with a little" or "this language can be used for many different tasks." There are plenty of "powerful" languages. As for why Rexx is widely used as a macro language, it's probably just because the tools for adding a Rexx interpreter into your program are straightforward. Anyway, nobody is trying to rank the languages objectively. But if you're going to learn ONE more language other than BASIC, Rexx is a very odd choice. --Mr.98 (talk) 14:38, 7 December 2010 (UTC)
- Huh? You're being disingenuous? Dosnt powerful imply good for programming languages? 92.15.11.224 (talk) 13:50, 7 December 2010 (UTC)
- I would say, no, "powerful" does not just equal "good". Assembly language is very powerful, but it's the worst choice for 99% of programming tasks. I mean, I am not going to sit here and write "assembly language is not good", following that logic; but it's a poor choice, in almost all situations. Despite the macho BS from many coders about how awesome they are at it. By the way, Nimur's analogy is excellent. Comet Tuttle (talk) 17:49, 7 December 2010 (UTC)
- I believe assembly is not at all powerful - it takes pages of code to do what one line in a higher level language would do. 92.24.176.134 (talk) 19:23, 7 December 2010 (UTC)
- I would say, no, "powerful" does not just equal "good". Assembly language is very powerful, but it's the worst choice for 99% of programming tasks. I mean, I am not going to sit here and write "assembly language is not good", following that logic; but it's a poor choice, in almost all situations. Despite the macho BS from many coders about how awesome they are at it. By the way, Nimur's analogy is excellent. Comet Tuttle (talk) 17:49, 7 December 2010 (UTC)
- It depends on how you define "powerful". There are things you can do in assembly that you cannot do in higher level languages. As a real-world example, John Carmack (of Id Software) explained that the reason they got high frame rates in their 3D engines was because he went in and tweaked the assembly code after it was compiled as optimal as possible from C/C++. The adjustments made simply couldn't be done in any high level language. -- kainaw™ 14:40, 8 December 2010 (UTC)
If you compare the Rexx and the Python (programming language) articles, then Rexx wins. Because 1) it does not have all the difficult to understand clutter that the Python article has, 2) the range of use and number of interpreters is greater for Rexx than Python, 3) the number of links and lists of books are longer for Rexx than Python. Its like me saying "I'd like to wear some blue jeans" and you're saying "No, purple nylon flares are what everyone's wearing now!" If it takes 20% of the learning effort to get 80% of the functionality, then its a good deal. 92.24.176.134 (talk) 19:23, 7 December 2010 (UTC)
- I exhausted my verbosity above, so this will be a short response. I will never try to tell anyone that they should not program in Rexx. I will also never pay anyone to program in Rexx. Nimur (talk) 19:30, 7 December 2010 (UTC)
- Few will: Rexx jobs, Python jobs. --Sean 20:22, 7 December 2010 (UTC)
- I exhausted my verbosity above, so this will be a short response. I will never try to tell anyone that they should not program in Rexx. I will also never pay anyone to program in Rexx. Nimur (talk) 19:30, 7 December 2010 (UTC)
- It's your life, do what you want with it. You asked for opinions, and you got plenty of them. It's of note, though, that your methodology is flawed. There are far more books on Python than Rexx. The fact that you can probably list every book on Rexx onto a page without it being overly cluttered is actually a sign of how relatively unimportant it is. There are at least 80 books on Python at my university library, some 40 of them published in the last 3 years alone. That's a sign of a pretty healthy language. My university library carries exactly one book devoted to Rexx, and it got it as part of a general online subscription. That's a sign of an irrelevant language. It's your choice if you want to pick the irrelevant pick, but don't be fooled by the articles into thinking Rexx is something that is isn't. --Mr.98 (talk) 21:42, 7 December 2010 (UTC)
- I actually know REXX and would only recommend it if you have to use it in its native environment: proprietary IBM systems. Languages have network effects which overwhelm their inherent power. --Sean 17:57, 8 December 2010 (UTC)
You could repeat the above criticism for Freebasic. The big attractions of Rexx are that you can do lots of different things with it, and its quick to learn. Clearly programmers do not like it when some languages lower the barriers to entry of programming and would prefer something that takes a lot of time and effort and nerdiness to learn. 92.24.190.135 (talk) 20:00, 10 December 2010 (UTC)
Windows Mobile 6.5
In Windows Mobile 6.1 / 6.5 default email program, can you designate which IMAP folder names to use for "Sent" and "Deleted", so that sent and deleted messages show up in the right folders when you open your email from your computer? Right now, if your servers doesn't use those same names, you will either end up with a new folder with that name being created for Sent/Deleted items, or not have those messages at all. Can't you just "tell the program" which of your existing IMAP folders to use for placing Sent/Deleted messages in? Roberto75780 (talk) 03:09, 7 December 2010 (UTC)
- Not with the default client, sorry. WM email was mainly designed to work with Exchange (and in turn Outlook) and that uses the same folder names as on the device. If you're running the IMAP server on a Linux style box I've heard of people using symbolic links with the folder names as workarounds, but I've never personally tried that (I use Exchange). Sorry! ZX81 talk 03:58, 7 December 2010 (UTC)
Use cases
Explain how use cases can be used in construction of data flow diagrams —Preceding unsigned comment added by 41.204.170.50 (talk) 07:36, 7 December 2010 (UTC)
- Section header added for this question. Comet Tuttle (talk) 07:40, 7 December 2010 (UTC)
- Sounds like a homework question. Try looking at use case, then if you want to ask a specific question, rather than your homework, perhaps people can help you. Shadowjams (talk) 10:19, 7 December 2010 (UTC)
Is backing up gmail important?
I'm a strong believer in backing up the data on my computer, but is backing up something like your gmail messages helpful? I assume Google backs these up itself. ike9898 (talk) 14:17, 7 December 2010 (UTC)
- It all depends on how much you trust Gmail to do it for you. Also consider the possibility that someone hacks your Gmail accounts and deletes them. Not impossible. Probably not likely. But all of these kinds of considerations are a balance between the inconvenience of doing something and the possibility that it might be worthwhile to have done it. --Mr.98 (talk) 14:32, 7 December 2010 (UTC)
Backups are always good, and with programs like gmail-backup very easy. 82.44.55.25 (talk) 15:07, 7 December 2010 (UTC)
- Is there any Hotmail backup program please? 92.15.11.224 (talk) 15:23, 7 December 2010 (UTC)
- If you need to save emails to disk, my recommendation is to set up a program like Mozilla Thunderbird (which can work with Gmail, Hotmail, and any other POP- or IMAP-capable email system. Then use the Thunderbird Backup to save your settings, and Offline Folders to save your mail to disk. Nimur (talk) 17:58, 7 December 2010 (UTC)
- Would setting up Thunderbird require supplying it with several mysterious numbers, or does it do that sort of thing automatically? Can I use Thunderbird and use Hotmail in the same way as previously? Thanks 92.24.176.134 (talk) 19:29, 7 December 2010 (UTC)
- When I tried Thunderbird a while ago it just asked for the email address, and from that it worked out all the ports and other info to use. If you mean can you still access Hotmail via the web interface after setting up Thunderbird, yes you can. 82.44.55.25 (talk) 19:46, 7 December 2010 (UTC)
- I had difficulty finding this earlier, but here are the official settings for Hotmail's servers. Nimur (talk) 21:48, 7 December 2010 (UTC)
- Would setting up Thunderbird require supplying it with several mysterious numbers, or does it do that sort of thing automatically? Can I use Thunderbird and use Hotmail in the same way as previously? Thanks 92.24.176.134 (talk) 19:29, 7 December 2010 (UTC)
- If you need to save emails to disk, my recommendation is to set up a program like Mozilla Thunderbird (which can work with Gmail, Hotmail, and any other POP- or IMAP-capable email system. Then use the Thunderbird Backup to save your settings, and Offline Folders to save your mail to disk. Nimur (talk) 17:58, 7 December 2010 (UTC)
Nancy Drew games
can you till me how to play nancy drew games for xp on my windows 7 64bit —Preceding unsigned comment added by 92.8.25.132 (talk) 15:20, 7 December 2010 (UTC)
- Tell us what happens when you just try to play the game normally. If that doesn't work — and I have not played any of these games — then first install the game on your hard disk, then locate the game folder, which is probably in "C:\Program Files\" and then in its own directory. Find the .exe file — that is, the file that ends in ".exe". If you don't see any, then go to Control Panel -> Folder Options -> View and uncheck "Hide extensions for known file types". Right-click that .exe file and click the Compatibility tab. There you can choose to have Windows 7 run the game in "compatibility mode", where Windows 7 tries as much as possible to pretend that it's Windows 98, or Windows 95, or whatever your game says it should be running under. Comet Tuttle (talk) 17:23, 7 December 2010 (UTC)
- Also worth trying is right clicking on the shortcut or icon and selecting the "Run as Administrator" option. Older games often need permissions to run correctly which Windows 7 disables on normal running of applications as a security feature. Edit - obviously only do this if you are running a genuine legit copy rather than a pirate or crack. Scan the executable with antivirus first! Exxolon (talk) 20:23, 7 December 2010 (UTC)
can a windows binary do anything in between when you click "allow administrative privileges" or is it not executed at all?
So, I know this internet cafe computer was infected, and I made sure the USB I transferred nonbinary files (just text files) onto my laptop with had no autorun (put it in without autorun and checked for any autorun files but there were none). I was trying to navigate into a folder on it when, too late, I clicked on that only LOOKED like a folder (it had the folder icon) but was an executable file! I realized it was executable because Windows told me it needed admin privileges, which naturally I said no to. My question: could the virus have done anything anyway, without admin privileges? Or, does the executable not get run in any way in this situation? (ie windows knows it's an admin type .exe, and asks you first when you double-clicking, without so much as running it in any way). Thanks! 82.234.207.120 (talk) 23:02, 7 December 2010 (UTC)
- Which version of Windows? If you use Vista or Windows 7, the application can not even start to run unless you grant it privileges. This Microsoft TechNet article has this control-flow diagram which explains the situation well: the application
terminatesdoes not even launch if you don't grant permission. I'm still investigating whether an application could, say, put all privilege-requiring code in a DLL file; and start running as a normal, unprivileged program, and then load the DLL ... thus, not raise the Elevated Privileges prompt until it starts doing something administrative-y. But so far, that doesn't even seem possible, and if it were, it still doesn't seem like it could breach the UAC security layer. Nimur (talk) 23:27, 7 December 2010 (UTC)- User Account Control Best Practices says it also depends on your User Account Control settings. Nimur (talk) 23:38, 7 December 2010 (UTC)
- whew, thanks for the quick answer! I feel relieved :). windows 7 by the way. thanks again. 82.234.207.120 (talk) 01:00, 8 December 2010 (UTC)
- User Account Control Best Practices says it also depends on your User Account Control settings. Nimur (talk) 23:38, 7 December 2010 (UTC)
{kind=link}
Wikileaks insurance file encryption key length
There are a number of reliable sources stating that the insurance file by wikileaks is encrypted with a 256 digit key. Are they confusing 256 digit with 256 bit (key size)? Technical literacy isn't improving.Smallman12q (talk) 23:42, 7 December 2010 (UTC)
- We could charitably suppose that they mean binary digits. --Tagishsimon (talk) 23:45, 7 December 2010 (UTC)
- PCMag and The Register both say the file is called insurance.aes256, which certainly strongly suggests it's encrypted with AES in 256 bit mode. Strictly, absent the key to decode it, there's no way to know that it's really AES-256 at all; for all we know it could be encrypted with a different cryptosystem(s) instead, and calling it aes256 could just be intended to misdirect any TLA with a team of mathematicians and a giant compute farm to run it through the wrong cracking infrastructure. -- Finlay McWalter ☻ Talk 00:01, 8 December 2010 (UTC)
- It may even be gibberish, an elaborate bluff. APL (talk) 02:28, 8 December 2010 (UTC)
- I feel I should point out that there's no such thing as "a file encrypted with AES-256". The Advanced Encryption Standard only defines a way of encrypting 128-bit blocks, and there are many different (incompatible) ways of building on that to encrypt larger amounts of data. They might have used an encryption product that happens to (somewhat inaccurately) use the .aes256 extension. But I think it's more likely that ".aes256", like "insurance", is there simply to impress the easily impressed. That's not to say it's not a genuine encrypted file. It could be a TrueCrypt container, for example. TrueCrypt offers AES-256 in XTS mode as one of its encryption options. XTS uses two different keys, so there are actually 512 bits of key material used to encrypt the bulk of the data. Those 512 bits are stored at the beginning of the file encrypted with a different 512-bit pair of keys, which are derived from a user-entered passphrase which may be of any length. So even though one could say that the file is encrypted with AES-256 in this case, it's not accurate to say that it's encrypted with a 256-bit (or 256-digit) key. The de facto key (lock) is the passphrase of unknown length. -- BenRG (talk) 04:21, 8 December 2010 (UTC)
- Not to quibble, but I think that the AES standard actually does include 256 bit key implementations... Rinjidel itself was technically only 128... if I remember right. I personally use ROT13 because I think its security level is clear. Shadowjams (talk) 11:24, 8 December 2010 (UTC)
- AES supports key sizes of 128, 192 and 256 bits and the block size is fixed at 128 bits. Rijndael supports other block and key sizes. When I said "128-bit" above I was talking about block size, not key size. -- BenRG (talk) 12:39, 8 December 2010 (UTC)
- Not to quibble, but I think that the AES standard actually does include 256 bit key implementations... Rinjidel itself was technically only 128... if I remember right. I personally use ROT13 because I think its security level is clear. Shadowjams (talk) 11:24, 8 December 2010 (UTC)
December 8
php.ini
Having recently installed xampp I am trying to integrate a form in a web page that will send me an email when sent.
Currently I have the form but I am stumped at what to change in the php.ini file to allow me to do this.
I've found the part:
[mail funtion]
- For Win32 only.
- http://php.net/smtp
SMTP = localhost
smtp_port = 25
What do I change to enable my send button to allow the form through?
Also how do you get IE to open .php web pages rather than open or save them?
Many thanks in advance :) 93.186.31.240 (talk) 14:34, 8 December 2010 (UTC)
- For windows, you need to set your smtp server and "from" email address. The settings in php.ini will look like:
- SMTP = your.ip.provider.smtp.server.com
- sendmail_from = your@email.com
- Of course, you'll want to restart to ensure the new php.ini changes are loaded. As for loading the php page in IE, I assume you are trying to use "file - open" to open the PHP page. That will not work. You have to use IE to load the page through the webserver on your computer. So, you will load the pages with a URL like http://localhost/my_test.php. That means you have to save the files in the proper directory for your local webserver and ensure the local webserver is running. -- kainaw™ 14:49, 8 December 2010 (UTC)
- Currently I'm just running the server off my memory stick so I'm moving around with it. Is there anything I can put in the php.ini file to reflect this?
- In regards to the internet provider where do I find this. (This way I can test it on my home computer) sorry I'm new at smtp 93.186.31.239 (talk) 14:58, 8 December 2010 (UTC)
- Currently I'm just running the server off my memory stick so I'm moving around with it. Is there anything I can put in the php.ini file to reflect this?
- What SMTP server are you using in your email program? That is the SMTP server you will want to use. An alternative is to download and run an SMTP server on your local machine. However, your ISP may block traffic from a local SMTP server since 99% of the time home-run SMTP servers are used just to send spam. -- kainaw™ 15:31, 8 December 2010 (UTC)
- Indeed. Furthermore, reputable e-mail providers will probably refuse messages sent from your computer (and most other computers) anyway. Setting up a SMTP server that can actually send messages is, apparently, pretty complicated. 118.96.154.36 (talk) 02:27, 9 December 2010 (UTC)
- It seems to me that this is too much effort to go to for an assignment and is something to look into in the future when I don't have to stick to a tight deadline. Your point about ISPs blocking the traffic is a good one and that coupled with the very useful blog link is probably just as useful to me now, as actually getting it working. Assignments are boring if they all read the same and this will give me something to explore when talking about php.ini and the difficulty of passing forms through to email. Thanks you both so much for your time :) 195.49.180.89 (talk) 14:11, 9 December 2010 (UTC)
Why is necroing forum threads a bad idea?
There were some unanswered questions / unsolved issues that I sought to solve through forum threads over 5 years ago so I made replies to seek follow-ups. Therefore, I made the first replies in over 5 years on some threads at MMORPG.com.
I got some follow-up answers and updates, and felt kinda satisfied from them. I was once even told, "Nice necro." and took it as a compliment. Then I found some kind of thrill in necromancing threads so I kept doing it to a total of 15-20 threads.
Several days later, an admin emailed me personally asking me to please stop necroing threads, and that I'd be permabanned the next time I committed a similar offense. Much to my consternation, he deleted all the threads that I necromanced. I had to copy them from the Google Cache and re-paste them onto my blogsite in order to recover some of my posting history. I only had the energy and willingness to salvage some of them, as they would altogether be too many to salvage.
So really, why is it a bad idea to necromance years-old forum threads on various forums? --129.130.33.179 (talk) 16:05, 8 December 2010 (UTC)
- Preemption: Yes, but why is it annoying to some? --129.130.33.179 (talk) 16:07, 8 December 2010 (UTC)
- I don't know if it's similar to here or not, but I will comment on why replying to Ref Desk Q's in the archives which no longer appear on the front page is a bad idea:
- 1) The original poster is unlikely to see the answer provided.
- 2) Other people who might refute an incorrect post don't notice a post in the archives, so incorrect answers can stand, as if they were correct.
- 3) People reading through the archives might be confused with an answer that seems out of step with the others, such as "What's the cost of a 4 Gb flash drive ?". The answers from a couple years ago might be quite different from recent answers.
- Some of these issues could be addressed by bringing the archive back to the active page. StuRat (talk) 17:32, 8 December 2010 (UTC)
- Forum threads are basically extended discussions. While they do last longer than a normal "live" conversation, they do die after a while when nobody posts to them. After a certain amount of time (many forums will specify 6 months, a year, or even just a few weeks depending on activity), the thread might be considered dead and bringing it back up without a very good reason is considered rude. The active members of a forum also might change over time, so the original people discussing the topic very well might not be active anymore so a more productive way to bring that topic up again might be to start a new topic that will include whatever members are active at the moment. StuRat's points for wikipedia are valid for forums as well. Many forums I've been to with rules specific to thread necromancy say that the best way to bring a dead topic back is to post a new thread and refer to specific posts in the dead topic via links or quotes. 206.131.39.6 (talk) 18:04, 8 December 2010 (UTC)
- 1) People don't look at dates, they assume that the front page of a forum will be full of recent conversations. If a six-page conversation appears that wasn't there when they checked the forum two days ago, they assume they've missed a flurry of conversation.
- 2) People no longer remember the conversation, so to make an informed reply they have to read the whole damn thing to avoid looking like an idiot. All 30 pages of it. 99% of which will be a waste of time anyway. Better to start fresh.
- 3) Depending on the topic, the factual information in the thread may now be out of date, but bringing it up top makes it "look" newly posted to the casual observer.
- 4) A forum thread is an analog for an in-person conversation. You don't walk up to your neighbor whom you haven't seen in a week and say "That's only partially true, the situation in Iraq has changed significantly since Obama was elected.", No, you walk up and say "I've been doing some reading about what you said last week about withdrawing our troops from the middle east." That is to say, you start a new conversation that only references the old one.
- The moderator probably deleted your threads because his moderation tools didn't provide an easy way to re-bury the thread.
- (Oh, and the guy that said "Nice Necro" was being sarcastic. He was making fun of you by pointing out your faux pas.)APL (talk) 05:52, 9 December 2010 (UTC)
- I think it depends entirely on the rules and culture of the particular board. Some places disapprove of it for the above reasons, others actively encourage it, and it's not even possible to speculate on which one is right without knowing anything about the community. I think it's more likely that the community is being inconsistent than that "Nice Necro" was sarcastic. Very few places have as well-defined rules as Wikipedia, and Wikipedia culture can only barely be called "consistent". And where Wikipedia's rules are ill-defined, it is often by good design. WP:ENGVAR is a victory for style! Wikipedia:Ignore All Rules is a victory for the rule of law!! Long live rough consensus and working prose!
- Uh, sorry, I may have gotten carried away there. But policy differs from place to place. Paul (Stansifer) 04:22, 10 December 2010 (UTC)
Join a Facebook network: confirmation email
I tried to join my new employer's Facebook network last night. You have to provide your official email address (so they can verify the domain-name) and then click the link when they send you a message. But when I got into work there was no message.
Does it usually take 24+ hours for these things to arrive? Or (plausible!) is it possible that my employer automatically filters out Facebook emails? In which case, what can I do? Thanks, ╟─TreasuryTag►inspectorate─╢ 16:56, 8 December 2010 (UTC)
- Confirmation emails normally go out right away, but there could be a delay if they have a problem. If the filter is the problem, use another email address. If you don't have another, you can get a free one from Google and many other sites. One possibility you haven't mentioned is that you could have written the email address down wrong when you signed up. They normally make you type it twice, to make this less likely, but some people just cut and paste the first one to the 2nd spot, thus disabling this safeguard. StuRat (talk) 17:25, 8 December 2010 (UTC)
- No. You seem to have misread my question. I tried to join my new employer's Facebook network last night. You have to provide your official email address (so they can verify the domain-name) and then click the link when they send you a message. But when I got into work there was no message. Does it usually take 24+ hours for these things to arrive? Or (plausible!) is it possible that my employer automatically filters out Facebook emails? In which case, what can I do? ╟─TreasuryTag►senator─╢ 17:46, 8 December 2010 (UTC)
- Are you saying it must be your employer's email address, as the won't give you access if you use another ? If so, then you'd better check with computer security at your company and have that site white listed. StuRat (talk) 00:44, 9 December 2010 (UTC)
- You can talk to the sys-admin of the company, if there is one. Or talk to your boss? These things are normally sent out immediately, but I guess there might be a possibility that there's a human factor in the chain - perhaps checking the email address is not automated? Still. Sounds like you have a problem only the firm can fix. --Tagishsimon (talk) 18:59, 8 December 2010 (UTC)
- Does Facebook run approval-only networks? If so, facebook might be waiting for someone (probably HR or IT) to respond to your join-request email. CS Miller (talk) 20:34, 8 December 2010 (UTC)
- It's not approval only. If, say, I wanted to join the Microsoft employees' network, I'd have to prove via a email address "click-this-link-to-confirm" thingy that I had a @microsoft.com account. There's no human element in it. ╟─TreasuryTag►Chancellor of the Duchy of Lancaster─╢ 20:54, 8 December 2010 (UTC)
Chrome notebook pilot program
Anyone know if/when Google are planning to extend their Chrome notebook pilot program outside the US (specifically, to the UK)? Or what is the best route to contact Google about this? the wub "?!" 17:15, 8 December 2010 (UTC)
Assembly dereferencing using ()'s
Hi,
I'm not sure how to use parenthesis () in assembly. I heard an explanation say that parenthesis dereferences the pointer contained in a register, eg. (eax) == *eax. where the * is like a star used before a variable in c to dereference.
I'm still not sure when this would be necessary or how it is used. Could someone explain this? Thanks. — Preceding unsigned comment added by Legolas52 (talk • contribs) 23:33, 8 December 2010 (UTC)
- It depends on the assembler syntax, and yes, in some assemblers (eax) means the same thing as *eax. The parenthesis notation is useful when you have indexed addresses like 8(esp), since 8*esp looks like multiplication. 67.117.130.143 (talk) 23:46, 8 December 2010 (UTC)
- I assume you're writing x86 assembly in AT&T syntax since only x86 has a register named "eax" and only AT&T syntax uses parentheses for this purpose. Some assembly language instructions interpret a register as an integer or a string of bits, for example, while others interpret it as a memory address and do something with the data at that address. The parentheses are used to distinguish between those cases. For example, addl %eax, %ebx adds the number in eax to the number in ebx, while addl (%eax), %ebx reads a number from the memory address given by eax and adds that to the number in ebx, and addl %eax, (%ebx) adds the number in eax to the number at the memory address given by ebx. The fourth combination, addl (%eax), (%ebx) is not allowed, not because it wouldn't make sense but because there happens to be no single machine instruction that does that. Likewise, you can't write ((%eax)) to double-dereference a pointer because there's no machine instruction that supports that addressing mode. -- BenRG (talk) 05:49, 9 December 2010 (UTC)
December 9
Web designing software
Are there any free software like Adobe Dreamweaver that can be easily used to design web pages? —Preceding unsigned comment added by 202.124.190.218 (talk) 02:05, 9 December 2010 (UTC)
- Please see our comparison of HTML editors article. 118.96.154.36 (talk) 02:31, 9 December 2010 (UTC)
kompozer —Preceding unsigned comment added by 82.44.55.25 (talk) 14:23, 9 December 2010 (UTC)
Free classic science fiction game?
A colleague of mine is teaching a course on science fiction to college undergraduates, and would love to include a video game of some sort in some way. He had originally thought about Deus Ex, but I pointed out to him that though the game had some interesting cyberpunk aspects, it would be a difficult one to use because 1. it takes forever to really get to the very science fiction aspects (I played it years ago and remembered it taking a few hours to get to the stage where you learn about the nanobots and genetic engineering and etc.), and 2. it wasn't free and wasn't going to be supported on many modern systems without lots of hassle. (I seem to recall installing it being a hassle even on a system of its era.)
I'd been trying to think of something that could be used in its place. Ideally it would be something that could be truly easily cross platform and currently free yet still "classic" enough that it would be indicative of its time and "deep" enough to have science fiction themes that could be discussed (e.g. in comparison with Gibson's works or whatever).
I'd hoped that the source for System Shock had been released but such is apparently not the case. I seem to recall seeing Quake 2 (whose source has been released) having been ported to play in a browser window which seems like a good solution except for the fact that Quake 2 is, if I recall, pretty shallow in terms of plot. Combing through Category:Commercial video games with freely available source code didn't turn up anything obvious that fit the bill.
Abandonware is not a permissible option (too much liability to get in trouble with the school administration). It might be possible to set up a paid-for game on a commonly accessible computer or something so that the students could play for a few hours. A boring approach might involve playing the game while students watched, or resorting to YouTube videos.
Maybe some kind of old school text parser, like Zork, but science fiction? I don't know.
Any better suggestions? --140.247.11.242 (talk) 03:13, 9 December 2010 (UTC)
- Well, if you're open to using Infocom games (and I don't know if you are since you mentioned Zork but also said no abandonware (Perhaps you could use The Lost Treasures of Infocom?)), you might try A Mind Forever Voyaging. If you want something free, you might browse [1], but such games may be less "classic" as they may be newer and/or less well-known. For very old things (Not modern interactive fiction, which can be run under Frotz or Glulx) you can use Dosbox. --NYKevin @205, i.e. 03:55, 9 December 2010 (UTC)
- Geez - I have a dim memory of a text-parser game where you had to figure out (first) that you were a disembodied brain controlling an entire complex of some sort, then (second) how to control all of the functions of the complex before you (in one of a number of different ways) killed everyone in the complex including yourself. I have no idea what it was called, though - it's back from the height of the Zork era. (which was before my time, really, but I've always been a bit old-school
 ). --Ludwigs2 04:10, 9 December 2010 (UTC)
). --Ludwigs2 04:10, 9 December 2010 (UTC)
- Geez - I have a dim memory of a text-parser game where you had to figure out (first) that you were a disembodied brain controlling an entire complex of some sort, then (second) how to control all of the functions of the complex before you (in one of a number of different ways) killed everyone in the complex including yourself. I have no idea what it was called, though - it's back from the height of the Zork era. (which was before my time, really, but I've always been a bit old-school
- The white chamber is free and pretty good, but it's recent (2005) and more horror than science fiction. In interactive fiction, Adam Cadre's games are uniformly excellent, and Narcolepsy, Photopia, and Shrapnel have science fiction elements. Likewise Emily Short. Some other possibilities from the 1990s are Babel, Delusions, Erehwon, For a Change, Glowgrass, Jigsaw, and Spider and Web. I'm not sure these are quite the sort of thing you're looking for, probably because I'm not entirely sure what science fiction actually is... -- BenRG (talk) 04:57, 9 December 2010 (UTC)
- Here's a list of free games ordered by year from MobyGames. I don't know of any way to restrict the list to science fiction. Two games that jumped out at me are The Hitchhiker's Guide to the Galaxy (computer game) (most Infocom games aren't free, but this one apparently is) and Beneath a Steel Sky (works on modern computers via ScummVM). -- BenRG (talk) 05:34, 9 December 2010 (UTC)
- The white chamber is free and pretty good, but it's recent (2005) and more horror than science fiction. In interactive fiction, Adam Cadre's games are uniformly excellent, and Narcolepsy, Photopia, and Shrapnel have science fiction elements. Likewise Emily Short. Some other possibilities from the 1990s are Babel, Delusions, Erehwon, For a Change, Glowgrass, Jigsaw, and Spider and Web. I'm not sure these are quite the sort of thing you're looking for, probably because I'm not entirely sure what science fiction actually is... -- BenRG (talk) 04:57, 9 December 2010 (UTC)
- I see that there's an open source remake of UFO: Enemy Unknown here: [3]. As a frequent visitor to the interactive fiction archives, I'm in a position to say that text adventures are all awfully dull and you should avoid them. 213.122.59.245 (talk) 06:04, 9 December 2010 (UTC)
- Personally, I'm much more bored by strategy games than text adventures. It is, unfortunately, probably true that any game will bore some fraction of the students. -- BenRG (talk) 22:21, 9 December 2010 (UTC)
- To paraphrase what somebody once said about golf, an adventure game is a good story, ruined. 81.131.43.12 (talk) 23:57, 9 December 2010 (UTC)
- Personally, I'm much more bored by strategy games than text adventures. It is, unfortunately, probably true that any game will bore some fraction of the students. -- BenRG (talk) 22:21, 9 December 2010 (UTC)
- For a pure sci-fi plot with aliens and star systems and artifacts and progenitors of our species etc... I absolutely loved the Star Control series... but check out Star Control 3. You should be able to get it for cheap because it was released in 1996. The series was fun to play, and contained a great deal of sci-fi text. It also did not take long to get into the nitty gritty of the game. In terms of pure cyberpunk I don't think there's too much (Category:Cyberpunk_video_games) but there's a new Tron (2010) available... not sure about the price though. Sandman30s (talk) 12:57, 9 December 2010 (UTC)
- Star Control II is free software under the name The Ur-Quan Masters, which is community-maintained and cross-platform. I think the changes from the original version are slight, and mainly about usability or cosmetics or something, but I haven't played it much, and I never played the original. (Interestingly, Adam Cadre, mentioned above considers SC II to be "perfection".) Paul (Stansifer) 16:23, 9 December 2010 (UTC)
IT jobs in 2013
what will be the job oopurtunities in IT field in the year 2013 — Preceding unsigned comment added by Josephite.m (talk • contribs) 04:14, 9 December 2010 (UTC)
- WP:NOTCRYSTAL --LarryMac | Talk 13:15, 9 December 2010 (UTC)
- If you use your favorite Search engine to search for "long term job forecast", or similar search terms, you will get a hodgepodge of extended forecasts, often for individual states. In Florida, for example, it's predicted that "job gains in new information technology sectors are muted by job losses in the more established information technology sectors of this industry" (this is the forecast for through 2017). Moody's will sell you very detailed job histories and predictions for different states. Looking at their free sample (For New York, from 2003, so take the data with a huge grain of salt), it looks like the number of IT jobs (under "Internet Service Providers, Web Search Portals, & Data Processing Services") will continue to grow, though fairly slowly. If you want up to date predictions, you can by a single report for 235 USD, or a yearly subscription (with 12 issues) for 2175 USD. I would say that in general, the information technology field is a fairly safe field to go into; there's likely to be jobs available for a long time, and they tend to pay pretty well. Buddy431 (talk) 21:54, 9 December 2010 (UTC)
Firefox remote functionality
I am curious about what is actually happening in the following scenario. I assume that this functionality is called "remote" because it is turned off with the option "-no-remote". The steps to produce this functionality are:
- Login to a Linux computer (call this computer "local").
- Run Firefox on the local computer.
- SSH with X-tunnel to a remote Linux machine (call this computer "remote").
- Run Firefox on the remote computer.
What I expect to see is two Firefox windows on the local machine, one running on the local machine and one running on the remote machine. What I actually see is two windows on the local machine, both running on the local machine. Instead of launching Firefox on the remote machine, it simply tells Firefox on the local machine to spawn a new window. So, how does that happen? (Please be very technical - I'm looking for the exact inter-process communications being used between the remote and local computers that allow the remote computer to know that I'm running Firefox on the local computer without asking permission to monitor processes on the local computer.) -- kainaw™ 14:17, 9 December 2010 (UTC)
- As a guess, firefox uses Inter-Client Communication (ICCCM) which is part of the X-Window protocol. On start-up firefox will attempt to register itself (unless -no-remote is used), if this fails then an instance of firefox is already running. On failure, the second firefox uses ICCCM to send a message to the first firefox with the URL(s) it was asked to open, and then exits. The first firefox then opens those URL(s). As long as both firefoxes are being shown on the same display, they will interact. Neither needs to be actually running on the same machine as each other, or the display's machine. CS Miller (talk) 14:28, 9 December 2010 (UTC)
- 000:<:0007: 24: Request(16): InternAtom only-if-exists=false(0x00) name='_MOZILLA_VERSION'
- 000:<:0008: 24: Request(16): InternAtom only-if-exists=false(0x00) name='_MOZILLA_LOCK'
- 000:<:0009: 24: Request(16): InternAtom only-if-exists=false(0x00) name='_MOZILLA_COMMAND'
- 000:<:000a: 28: Request(16): InternAtom only-if-exists=false(0x00) name='_MOZILLA_RESPONSE'
- 000:<:000b: 16: Request(16): InternAtom only-if-exists=false(0x00) name='WM_STATE'
- 000:<:000c: 24: Request(16): InternAtom only-if-exists=false(0x00) name='_MOZILLA_USER'
- 000:<:000d: 24: Request(16): InternAtom only-if-exists=false(0x00) name='_MOZILLA_PROFILE'
- 000:<:000e: 24: Request(16): InternAtom only-if-exists=false(0x00) name='_MOZILLA_PROGRAM'
- 000:<:000f: 28: Request(16): InternAtom only-if-exists=false(0x00) name='_MOZILLA_COMMANDLINE'
- I didn't think ICCCM could work because it allows communication on the same X server. I am running these on two different X servers. Atoms, on the other hand, are used by the displaying X server. If I run firefox on two different remote computers without -no-remote, I see one set of -MOZILLA variables in xlsatoms. If I run them with -no-remote, I see two sets of -MOZILLA variables. So, it appears that they are sort of abusing atoms as a means of communicating with one another. -- kainaw™ 16:18, 9 December 2010 (UTC)
- How are you running them on two separate X servers? Your "SSH with X-tunnel" means you're reusing the local one. --Tardis (talk) 16:52, 9 December 2010 (UTC)
- I didn't think ICCCM could work because it allows communication on the same X server. I am running these on two different X servers. Atoms, on the other hand, are used by the displaying X server. If I run firefox on two different remote computers without -no-remote, I see one set of -MOZILLA variables in xlsatoms. If I run them with -no-remote, I see two sets of -MOZILLA variables. So, it appears that they are sort of abusing atoms as a means of communicating with one another. -- kainaw™ 16:18, 9 December 2010 (UTC)
- Sorry for not being detailed about the second experiment I did. I used ssh -X into one machine. For the other, I didn't ssh into it at all. I just exported the display from the computer itself to make it show up on another machine. I was looking for a difference. What I found is that firefox sees and communicates with every other firefox session on the computer on which it is displayed. -- kainaw™ 16:55, 9 December 2010 (UTC)
- "The computer on which it is displayed" is the X server, not the one on which the executable is running. --Sean 19:46, 9 December 2010 (UTC)
- Sorry for not being detailed about the second experiment I did. I used ssh -X into one machine. For the other, I didn't ssh into it at all. I just exported the display from the computer itself to make it show up on another machine. I was looking for a difference. What I found is that firefox sees and communicates with every other firefox session on the computer on which it is displayed. -- kainaw™ 16:55, 9 December 2010 (UTC)
- It may do it with atoms rather than ICCCM. — This is meaningless. The ICCCM is a set of standards about how X clients communicate, which they do (amongst other things) by means of atoms. Marnanel (talk) 22:46, 9 December 2010 (UTC)
- I'll note the following: when I start Firefox through an SSH session, it's typically because I want to appear to be using the remote IP address. (For example, if I'm at home and I log in to a university computer, I have access to the subscription journal websites). But if the Firefox actuates a Remote mode, there is no proxying - I do not have access to the subscription sites. From this, I gather that Firefox is not running anything on the sshd server side. When I log in to the SSH server and start Firefox, I assume that ssh sends a command back to my local computer to run Firefox entirely locally (or open a new tab in a currently-running local Firefox). It seems that the mechanism for this is that the firefox command actually runs a shell script - which delegates to another script, run-mozilla.sh. It is this script, which executes a local command. (I'm not sure if this is a capability of SSH: can you force a command to be run on the client machine)? I am still looking up what exact procedure that involves - but I suspect it's a matter of sending the correct escape-key(s) to SSH. (Possibly ^Z). Nimur (talk) 21:06, 9 December 2010 (UTC)
- Though, this post indicates that Firefox actually does launch remotely, and then hacks up the X11 protocol to send an inter-process communication over to a Firefox running on the client-side. I can't confirm that behavior independently, but it seems more plausible than SSH itself allowing code to execute on the local machine. The question now becomes, "can X11 merely send a message to a firefox process already running on my local computer, or can X11 actually cause execution of arbitrary code on my local computer?" Nimur (talk) 21:20, 9 December 2010 (UTC)
- The relevant communication is done by XRemoteClient::DoSendCommand in XRemoteClient.cpp, which uses XChangeProperty to manipulate MOZILLA_COMMAND_PROP, one of the atoms I mentioned above (it looks like they use MOZILLA_RESPONSE_PROP for the response). I don't know how durable this protocol would be if there were lots of
usersinstances banging out requests and responses, but for the occasional use it actually gets, this seems fair enough. -- Finlay McWalter ☻ Talk 21:49, 9 December 2010 (UTC)- But that still doesn't explain how the a Firefox process can be started on the local machine, if it was not already running. Can X11 initiate remote code execution? Nimur (talk) 22:21, 9 December 2010 (UTC)
- Nobody has said that a Firefox process will be started on the local machine if one isn't already running. X will not kick off a new process just because you changed some root window properties. Marnanel (talk) 22:38, 9 December 2010 (UTC)
- Right, that's my understanding, and how it behaves for me when I try it out. If I have two machines local and remote, where I'm sitting at the X display on local and there's nothing but an sshd running on remote. If, at in a terminal window on local I write ssh -X remote firefox http://foo.com, what happens depends on whether I have a firefox instance already running on local. If there is a local firefox, the ssh command runs a remote firefox, it does the X atom thing above (which it can because of the X forwarding), sends the message, and closes, and http://foo.com opens (in a new tab) in the local firefox instance. If there isn't a firefox running on local, that atom procedure fails, so the remote firefox on remote runs, creates its own X window (which ssh forward back to local). In the former case the remote firefox session only runs for a fraction of a section before terminating (and exiting the ssh connection), whereas the latter case the remote firefox process persists as long as I use it (or the ssh connection survives). I don't see any remote execution beyond what you'd expect ssh to do. -- Finlay McWalter ☻ Talk 22:47, 9 December 2010 (UTC)
- Nobody has said that a Firefox process will be started on the local machine if one isn't already running. X will not kick off a new process just because you changed some root window properties. Marnanel (talk) 22:38, 9 December 2010 (UTC)
- But that still doesn't explain how the a Firefox process can be started on the local machine, if it was not already running. Can X11 initiate remote code execution? Nimur (talk) 22:21, 9 December 2010 (UTC)
- The relevant communication is done by XRemoteClient::DoSendCommand in XRemoteClient.cpp, which uses XChangeProperty to manipulate MOZILLA_COMMAND_PROP, one of the atoms I mentioned above (it looks like they use MOZILLA_RESPONSE_PROP for the response). I don't know how durable this protocol would be if there were lots of
- Though, this post indicates that Firefox actually does launch remotely, and then hacks up the X11 protocol to send an inter-process communication over to a Firefox running on the client-side. I can't confirm that behavior independently, but it seems more plausible than SSH itself allowing code to execute on the local machine. The question now becomes, "can X11 merely send a message to a firefox process already running on my local computer, or can X11 actually cause execution of arbitrary code on my local computer?" Nimur (talk) 21:20, 9 December 2010 (UTC)
- I'll note the following: when I start Firefox through an SSH session, it's typically because I want to appear to be using the remote IP address. (For example, if I'm at home and I log in to a university computer, I have access to the subscription journal websites). But if the Firefox actuates a Remote mode, there is no proxying - I do not have access to the subscription sites. From this, I gather that Firefox is not running anything on the sshd server side. When I log in to the SSH server and start Firefox, I assume that ssh sends a command back to my local computer to run Firefox entirely locally (or open a new tab in a currently-running local Firefox). It seems that the mechanism for this is that the firefox command actually runs a shell script - which delegates to another script, run-mozilla.sh. It is this script, which executes a local command. (I'm not sure if this is a capability of SSH: can you force a command to be run on the client machine)? I am still looking up what exact procedure that involves - but I suspect it's a matter of sending the correct escape-key(s) to SSH. (Possibly ^Z). Nimur (talk) 21:06, 9 December 2010 (UTC)
If all 13 root nameservers were simultaneously down
Would every attempt by a computer user using a browser to go to www.example.com (where you replace 'example' with a real website) result in a "server not found" error? Would it be crippling, or is the degree to which the caches of local nameservers who know nameservers who know where such and such website is statistically good enough that a lot of people would still be OK? 20.137.18.50 (talk) 18:06, 9 December 2010 (UTC)
- It depends on your ISP's name-server caching policy. Most of them probably update their cache every few hours, and some of them might use wacky "smart" caching (i.e. if they can't get a connection to a canonical server, they might drop the record, or they might keep the old version). Now that DNS servers are running software implementations, the possibilities are pretty much infinite in terms of what they could do. But most probably, they would keep their records (because there's a critical difference between "can't connect to a canonical name-server to look up example.com" and "canonical nameserver no longer has a record for example.com"). Depending on the size of their cache, some users would never notice anything; but the "long tail effect" seems worth mentioning, and many users would immediately see DNS resolution problems (by trying to visit sites that are not in the local cache). And it would be a pretty big problem when IP/dns-name mappings started changing. You can read about BIND, a very common DNS server software. In fact, an entire book exists, DNS and BIND, published by O'Reilly, and containing several chapters about the caching algorithm(s) it uses. Particularly, note that the net-ops engineer can configure the Master / Slave relationship in any way he or she wants; and can configure DNS zones in any way they see fit; presumably, they might hand-tweak this sort of stuff, or they may run analytics and auto-generate configurations. If a specific ISP sets up a master server with a huge database, they are almost entirely independent from the root nameservers (except that they will never know about new, deleted, and changed IP/dns records). It is probable that your ISP uses BIND for its DNS server, but the only way to be sure is to ask someone in your ISP's network engineering / operations group. Nimur (talk) 19:31, 9 December 2010 (UTC)
- I have to add that there's a hell of a lot more than 13 nameservers. There can't be more than 13 addresses for them, but anycast means that multiple servers can share an address. In fact there are currently 243 root nameservers. All of them going down at once is rather unlikely. Marnanel (talk) 22:35, 9 December 2010 (UTC)
- honestly, "all 243 servers" going down at once is about as likely as "all 13 servers" going down a once (and not because the probability is 0). 82.234.207.120 (talk) 07:38, 10 December 2010 (UTC)
- I have to add that there's a hell of a lot more than 13 nameservers. There can't be more than 13 addresses for them, but anycast means that multiple servers can share an address. In fact there are currently 243 root nameservers. All of them going down at once is rather unlikely. Marnanel (talk) 22:35, 9 December 2010 (UTC)
Samsung TVs with DLNA are being fussy with h264 media
I've tried a couple different 2010 Samsung TV's with their "allnet" DLNA media playback feature. Every single h264 .mp4/m4v refuses to play on it. I get a "Not supported file format" error. These files shared over DLNA play just fine on a PS3 and WDTV box. And the TV manuals clearly state h264 is supported up to 1080p and 10mbit/sec (which these media files are). Is there something I can do on my end to get these movies into whatever strict specification the Samsung TVs are expecting? --70.167.58.6 (talk) 20:55, 9 December 2010 (UTC)
Declarations and definitions
I'm fairly confident that I know what these are (having read The C Programming Language carefully), and that the article Declaration (computer science) doesn't, quite. I left a comment to this effect on its talk page back in April, but nobody reacted. I've just discovered, to my disgust, that Definition (disambiguation) links to the Declaration article, and calls a definition "A statement declaring ...". So am I being too much of a K&R fanboy, and failing to get with the modern world in which declarations and definitions are the same thing, or is this all a mess? 81.131.43.12 (talk) 23:53, 9 December 2010 (UTC)
- If it says that, I'd declare the definition wrong... I'll take a look, and see if I can make any sense of it. AndyTheGrump (talk) 00:10, 10 December 2010 (UTC)
- Wait, actually, I think a couple of people have improved the article in recent months (without saying anything on the talk page) and possibly fixed it. I wonder what I should do with the disambiguation, though. A definition blatantly isn't a declaration, yet "declaration" is the right article to link to. Maybe I'll just rephrase the disambig page a bit.
- ...Done. (Ugh, that "and/or" is a bit ugly.) Thank you for your moral support. 81.131.43.12 (talk) 00:14, 10 December 2010 (UTC)
- Yeah, the Declaration (computer science) article looks about right, though it could do with clarifying the distinction between definition and initialization for variables: they aren't necessarily the same thing in some languages. The disambiguation still needs a little work, it needs to refer to functions as well as variables.
- I wonder if the article should be called Declaration and definition(computer science)? I know Wikipedia practice is to avoid 'and' in article titles, but the two concepts are so closely interlinked it might make more sense that way. We'd need disambiguations for both 'declaration' and 'definition' though. Any thoughts? AndyTheGrump (talk) 00:31, 10 December 2010 (UTC)
- Well, it might be that declaration is the broader concept. The "variables" section of the article talks about languages which allow (or require) implicit declarations. This is a common phrase; so far as I know, "implicit definitions" isn't, even though, technically, this is what's being talked about in that section of the article as well. All the examples in that section are testing to see if x and y can be implicitly defined as well as implicitly declared; and most of the error messages say "x not defined", but the concept is still called "implicit declaration". Searching for that takes me to the page Undefined variable, where I read "An undefined variable in the source code of a computer program is a variable that is accessed in the code but has not been previously declared by that code." Argh! So maybe I am being overly fussy about a fine distinction. 81.131.43.12 (talk) 01:03, 10 December 2010 (UTC)
- I think you are right about the distinction being real enough (in most languages), but part of the problem is that different terminology is used for the same thing in different languages etc. Fortunately, I doubt many people try to learn computer programming from Wikipedia articles (at least, I hope not). AndyTheGrump (talk)
- Well, it might be that declaration is the broader concept. The "variables" section of the article talks about languages which allow (or require) implicit declarations. This is a common phrase; so far as I know, "implicit definitions" isn't, even though, technically, this is what's being talked about in that section of the article as well. All the examples in that section are testing to see if x and y can be implicitly defined as well as implicitly declared; and most of the error messages say "x not defined", but the concept is still called "implicit declaration". Searching for that takes me to the page Undefined variable, where I read "An undefined variable in the source code of a computer program is a variable that is accessed in the code but has not been previously declared by that code." Argh! So maybe I am being overly fussy about a fine distinction. 81.131.43.12 (talk) 01:03, 10 December 2010 (UTC)
- Every definition is a declaration; see WG14/N1124 section 6.7. I edited Definition (disambiguation) to agree more or less with that definition of "definition". -- BenRG (talk) 04:55, 10 December 2010 (UTC)
Spyware/virus protection for mac
I had always heard in the past that macs were basically immune to viruses. I have no idea if this is true or if it was true but is not any longer. My brand new iMac should be arriving tomorrowish and I have a few questions. Does it need any virus and/or spyware protection? If so, what do you recommend? (I'd prefer free, though I am willing to pay if it's really the better route). On that front, I will be transferring all manner of files from my soon-to-be-defunct PC over the the mac. I would not be at all surprised if this computer is infected (despite having Norton running continuously for years), as I have a lot of problems that I think may be the result of a virus. But I just can't abandon my files; hundreds of pictures, videos, word docs, pdfs, and so on. If you tell me I need antivirus, will I immunize myself (for the most part) if I first install that software and and only then do the file transfer—will it scan them as they're being transferred and block the transfer of infected files? If you tell me I don't need any antivirus software, how can I protect myself to do this transfer or do I need to at all? Thanks in advance.--162.84.137.228 (talk) 23:57, 9 December 2010 (UTC)
- It it not so much "immune" as in "irrelevant" to viruses. (It also helps that they aren't logged in as administrators by default, are running a pretty rigorous Unix back-end, and lack the standard Windows vectors like MS Outlook or MS Office or Internet Explorer. MS Office exists on the Mac but its scripting limitations are pretty high, and the most recent Mac versions have eliminated scripting altogether. Which is actually irritating, but whatever, in this context it is positive.) Anyway, I have been using a Mac for 6 years now without the need for any virus or malware protection. (And I monitor things pretty well and would know if something was on there that shouldn't be.) So I really wouldn't worry about it. There is just no real threat. As for the PC viruses, they won't run on a Mac, so it doesn't really matter from the standpoint of protecting the Mac. --Mr.98 (talk) 00:00, 10 December 2010 (UTC)
- Apple's official Mac OS X security page explains the built-in protections. The protection is almost identical to the protection that Windows offers: the operating system will ask you for permission to run any unfamiliar program. If you choose to run a program, and it turns out to have malicious intent, it doesn't matter what operating system you have. Here's a pretty decent listing of malware known to run on Mac computers. Especially take note of malware that attacks a browser or browser plugin - in this case, the malware is operating-system and hardware-agnostic. Nimur (talk) 00:07, 10 December 2010 (UTC)
- That page notwithstanding — I know lots and lots of people who use Macs who I would call non-techy. None of them to my knowledge have ever had any trouble with malware. All of the people I know with PCs who are non-techy have endless malware issues. I just don't think there's enough of a community of Macs and Mac viruses to sustain any serious infections to the degree that there are on Windows machines. That could change, of course. But I don't think it's worth the performance hit of antivirus, personally, in terms of a risk tradeoff. --Mr.98 (talk) 01:48, 10 December 2010 (UTC)
- Okay, so I guess I won't worry about it too much. Thanks for the tips.--162.84.137.228 (talk) 01:49, 10 December 2010 (UTC)
- One more question. I read the security information page Nimur linked. It seems some of the protection is geared towards using Safari. I am partial to Firefox. Am I asking for trouble by staying with it? Regarding "risk tradeoff" I have always thought of my antispyware and antivirus programs as almost viruses in and of themselves. A necessary evil but quite, quite evil; a constant system messing, crash inducing, resource robbing plague.--162.84.137.228 (talk) 01:55, 10 December 2010 (UTC)
- I don't use antivirus or antispyware software on Windows and have never had any problem. I think that the people who do get malware get it mainly from warez, stupid dancing frog animations, or visiting dodgy websites with an unpatched browser. I only download software that doesn't suck and I keep my network apps updated, and that strategy seems to work. I also use Firefox with NoScript, but I don't know if it's ever protected me from anything. -- BenRG (talk) 04:37, 10 December 2010 (UTC)
- One more question. I read the security information page Nimur linked. It seems some of the protection is geared towards using Safari. I am partial to Firefox. Am I asking for trouble by staying with it? Regarding "risk tradeoff" I have always thought of my antispyware and antivirus programs as almost viruses in and of themselves. A necessary evil but quite, quite evil; a constant system messing, crash inducing, resource robbing plague.--162.84.137.228 (talk) 01:55, 10 December 2010 (UTC)
- Okay, so I guess I won't worry about it too much. Thanks for the tips.--162.84.137.228 (talk) 01:49, 10 December 2010 (UTC)
- That page notwithstanding — I know lots and lots of people who use Macs who I would call non-techy. None of them to my knowledge have ever had any trouble with malware. All of the people I know with PCs who are non-techy have endless malware issues. I just don't think there's enough of a community of Macs and Mac viruses to sustain any serious infections to the degree that there are on Windows machines. That could change, of course. But I don't think it's worth the performance hit of antivirus, personally, in terms of a risk tradeoff. --Mr.98 (talk) 01:48, 10 December 2010 (UTC)
- Apple's official Mac OS X security page explains the built-in protections. The protection is almost identical to the protection that Windows offers: the operating system will ask you for permission to run any unfamiliar program. If you choose to run a program, and it turns out to have malicious intent, it doesn't matter what operating system you have. Here's a pretty decent listing of malware known to run on Mac computers. Especially take note of malware that attacks a browser or browser plugin - in this case, the malware is operating-system and hardware-agnostic. Nimur (talk) 00:07, 10 December 2010 (UTC)
Strings
Currently, I am taking lesson on "Strings". I couldn't run the following program. Got an alert signal on line 13:if ( strcmp ( name, "Nahid" ) == 0 ) // Equal strings
#include <iostream> // For cout
#include <iostream> // For the string functions
using namespace std;
int main()
{
char name[50];
char lastname[50];
char fullname[100]; // Big enough to hold both name and lastname
cout<<"Please enter your name: ";
cin.getline ( name, 50 );
if ( strcmp ( name, "Nahid" ) == 0 ) // Equal strings
cout<<"That's my name too.\n";
else
cout<<"That's not my name.\n";
// Find the length of your name
cout<<"Your name is "<< strlen ( name ) <<" letters long\n";
cout<<"Enter your last name: ";
cin.getline ( lastname, 50 );
fullname[0] = '\0'; // strcat searches for '\0' to cat after
strcat ( full name, name ); // Copy name into full name
strcat ( full name, " "); // We want to separate the name by a space
strcat ( fullname, lastname ); // Copy lastname onto the end of fullname
cout<<"Your full name is "<< fullname <<"\n";
cin.get();
}
How could I fix that? Thanks--NAHID 00:08, 10 December 2010 (UTC)
- What alert did you get? Nimur (talk) 00:12, 10 December 2010 (UTC)
- Could it be that you got "undefined identifier: strcmp"? Because you didn't
#include<cstring>, but iostream twice. --Tardis (talk) 00:23, 10 December 2010 (UTC)- Visual C++ auto-included that header. I got an error on full name - which probably should be fullname. Nimur (talk) 00:31, 10 December 2010 (UTC)
- The alert shows a square shaped red box, but it did not explain anything to me. It only disappears if the sentence is fixed. I checked and wrote that line (13) again but it seems that problem did not go away. The box is still popping up.--NAHID 10:21, 10 December 2010 (UTC)
Running WCII on a CF48
Whenever I try to run Warcraft II on my laptop (an old Panasonic Toughbook), I get the opening cinematic, but when the main menu comes up, it just shows as a blank screen. Alt-tabbing nets me a screen with blue lines running down it. I have no idea why it's acting like this (and yes, I do have the CD in the drive); any ideas?
For the sake of having the most complete info, this laptop is running Windows XP Pro (SP3), has a clock speed of 896 MHz, and has a total of 256 MB RAM. —Jeremy (v^_^v Hyper Combo K.O.!) 05:08, 10 December 2010 (UTC)
torrent download
i recently downlaoded a torrent file and started the download, it went smoothly for about 2 hours, and i switched off the computer and when i switched it on again, the download doesn't continue. i mean, it shows downloading under the status tab, but there's no speed under the speed tab, remaining time is infinity. it's never happened with me before... is it a bad torrent??? can i do anything about it????
thanx —Preceding unsigned comment added by 117.197.240.5 (talk) 09:39, 10 December 2010 (UTC)
- It could mean some of the people (or even just one person) you were downloading from also turned their computers off for a while. How many seeds and peers are showing for the download? Probably if you just leave the download going all the time it will catch when the other people reenter the swarm and start downloading again. There's nothing more you can do at your end but wait. 82.44.55.25 (talk) 10:34, 10 December 2010 (UTC)
usb ports
I plug an external hd (one partition, 250 GB): At first the pc (xp home, centrino) recognize it, after some minutes it behaves as I had unplugged it.. t.i.a. --217.194.34.103 (talk) 10:36, 10 December 2010 (UTC)