
Wikipedia:Reference desk/Computing
![]()
of the Wikipedia reference desk.
Main page: Help searching Wikipedia
How can I get my question answered?
- Select the section of the desk that best fits the general topic of your question (see the navigation column to the right).
- Post your question to only one section, providing a short header that gives the topic of your question.
- Type '~~~~' (that is, four tilde characters) at the end – this signs and dates your contribution so we know who wrote what and when.
- Don't post personal contact information – it will be removed. Any answers will be provided here.
- Please be as specific as possible, and include all relevant context – the usefulness of answers may depend on the context.
- Note:
- We don't answer (and may remove) questions that require medical diagnosis or legal advice.
- We don't answer requests for opinions, predictions or debate.
- We don't do your homework for you, though we'll help you past the stuck point.
- We don't conduct original research or provide a free source of ideas, but we'll help you find information you need.
How do I answer a question?
Main page: Wikipedia:Reference desk/Guidelines
- The best answers address the question directly, and back up facts with wikilinks and links to sources. Do not edit others' comments and do not give any medical or legal advice.
July 9
66 years old and going soft in the head - I should have asked my 13 years old Grandson.
I recently signed a 3 year contract with T-Mobile/EE for an Android Smartphone (Samsung S3 Galaxy). It's brilliant - no complaints. I then went and bought for cash, an Apple iPad4. And now all the new info is coming home to roost and I have discovered that my 2 new toys are incompatible when it comes to putting all my PC Music in the iCloud because they operate on different platforms, plus I can't swap Bluetooth stuff without a cable instead of back to back. I don't want to let go of either piece of kit for at least a couple of years if at all possible, but don't want to wake up at 70 years of age and find once again I am an even older dinosaur than presently. Any advice will be gratefully received. Thanks in anticipation.80.6.13.178 (talk) 14:57, 9 July 2013 (UTC)
- Is there a question in there? 64.201.173.145 (talk) 15:53, 9 July 2013 (UTC)
- Backup your files with iTunes on the PC, then transfer them from the PC to the android via Bluetooth. Bluetooth for Apple devices only works between Apple devices. Alternatively, you could use something like Dropbox. I use this for work, because for most of my work I need to travel around (I'm an interpreter). KägeTorä - (影虎) (TALK) 16:08, 9 July 2013 (UTC)
Lisp is a programmable programming language
What does it mean when people say that? Aren't all languages like that? (in the sense that they can be expanded. OsmanRF34 (talk) 17:41, 9 July 2013 (UTC)
- Lisp typically relies much more on metaprogramming and macros than other languages do. So a lot of the things that are fixed by the language designer in other programing languages are available to the lisp programmer to modify and manipulate. -- 205.175.116.72 (talk) 17:56, 9 July 2013 (UTC)
- Indeed. The classical view of LISP development is "extending the interpreter", not writing a separate program that runs on the interpreter. --Stephan Schulz (talk) 18:16, 9 July 2013 (UTC)
- It has been a long time, but I think a LISP program can change itself. LISP works on lists, where a list is a list of objects enclosed by parentheses. A LISP program itself is a list. Bubba73 You talkin' to me? 03:37, 10 July 2013 (UTC)
- Yes, LISP programs can modify themselves. LISP is not unique in that way -- see Reflection (computer programming). But LISP makes it very easy to do (because the structure of a program is so simple, and because of eval). Among current languages, Python comes close (indeed, if you look under the hood, Python is very much an OO LISP dialect with beginner-friendly syntax). --Stephan Schulz (talk) 06:40, 10 July 2013 (UTC)
- It has been a long time, but I think a LISP program can change itself. LISP works on lists, where a list is a list of objects enclosed by parentheses. A LISP program itself is a list. Bubba73 You talkin' to me? 03:37, 10 July 2013 (UTC)
RAM for 2006 first-gen Mac Pro
I'm still trying to upgrade my 2006 first-generation Mac Pro to Win7, and seeing that not even Apple Support can tell me (insisting that no such thing as a "2006 first-generation Mac Pro" would be even known to them, see my original odyssee), I'd like to ask here what type of RAM I need to expand it. I've been told that even just a slight alteration in the specs either wouldn't fit mechanically or due to electronical incompatibility would roast my whole machine once I'd turn it on.
An IT tech told me something of "DDR2", and the specs in the article Mac Pro say that what I originally got this machine with are 667 MHz DDR2 ECC DIMMs and they require heat sinks each. Googling and using Amazon, what I often see are 800MHz rather than 667MHz RAM stacks of that type, would they be compatible or even recommendable? What else do I need to look out for? --37.80.190.4 (talk) 19:04, 9 July 2013 (UTC)
- I don't know what type of machine you actually have - because I'm not there looking at it - but assuming that you have correctly identified your device as a 2006 device, you have a seven-year-old Vintage or Obsolete Product. Special service providers may be able to help you with service, but Apple has "discontinued hardware service for vintage products." For the most part, this means that nobody makes compatible parts; you won't even be able to order such parts. There is no reason you should assume that the upgrade you are looking for is even possible; but the product is probably no longer covered by Apple Support. Most probably, you will have to pay a third party for any help you need with that device. If you get very lucky, some small shop may have a cache of old, compatible hardware parts.
- Regarding installation of Windows 7: it seems self-evident - your machine does not satisfy the minimum system requirements to run Windows 7. Microsoft asserts: "Product functionality ...may vary based on your system configuration." You could talk to Microsoft Support if you have any questions about their minimum system requirements. Nimur (talk) 21:08, 9 July 2013 (UTC)
- Uhhh...I can't see anything from that table which says that my Mac Pro wouldn't qualify.
- 1GHz or faster 32-bit processor: Check! It's actually a 2.66GHZ 64-bit QuadCore.
- 2GB RAM: Check! It's exactly what's in there right now, but in order to run Adobe Creative Cloud on it, I wanna upgrade to at least 8GB.
- 20GB system HDD: Check!
- The rest I either don't need or (in the case of drivers) is supplied by BootCamp. Must be why Microsoft's own compatibility checking tool tells me my machine is fit for it, as does the article Mac Pro.
- As for the RAM, I never expected Apple to sell me the pieces by now. All I'm trying to find out is what to buy from Amazon or any other place. There's plenty of RAM on Amazon which reads "667 MHz DDR2 ECC DIMM" (still sealed, some ads even saying that it's "Mac Pro-compatible", but I'd rather make sure somehow), as does the Wikipedia article Mac Pro for the 2006 version.
- Also, it can't be "vintage", as it can't have been discontinued any earlier than 2008 at the earliest (which was when the second-generation Mac Pro was first introduced). In order to be defined as "vintage" by Apple, it must be discontinued for more than five years. --37.80.190.4 (talk) 01:08, 10 July 2013 (UTC)
- Further proof: This[1] Windows7 update, right from Apple, for the NVIDIA GeForce 7300 GT or Quadro FX 4500 graphics card on the Mac Pro, that were *EXCLUSIVELY* shipped with the original 2006 first-generation Mac Pro, as you can see at Mac Pro. The only reason why Apple does not "officially" support Windows7 on the original 2006 first-gen Mac Pro is because the minimum RAM that it was shipped with was only 512MB, and Win7 64-bit requires 2GB RAM, a RAM size easily supported by this machine which could be shipped with up to 16GB RAM from Apple directly, and can *STILL* be expanded up to 32GB RAM. --37.80.190.4 (talk) 02:34, 10 July 2013 (UTC)
- It's quite doubtful that you need RAM with heatsinks or heatspreaders, this depends entirely on the manufacturer of the RAM. That said, you should stick with ECC RAM if that is what's used, there's no guarantee non ECC is supported and if you are using the computer for professional purposes you may want ECC anyway. 800mhz RAM would probably work presuming it has SPD settings for 667mhz which it probably does, but there are no guarantees. (I'm presuming your mobo/chipset isn't capable of using 800mhz RAM which I don't lnow for sure.) But there are no guarantees particularly with such old hardware, sometimes weird stuff happens, e.g. I know of someone who had major problems getting single sided (well single ranked) 4GB DDR3 sticks to work even though double sided ones alleged work fine. And random compatibility problems can happen even with stuff which you would expect to work. And it may or may not be worse with ECC, I have insufficient exprience to say. Both computer or mobo manufacturers and RAM manufacturers generally publish RAM-mobo compatibility lists, but such lists are often very limited. Nil Einne (talk) 10:34, 10 July 2013 (UTC)
- BTW, I'm pretty sure the 7300GT is not exclusive to the Mac Pro though the update you linked to appears to be for one which was. Also all cards listed as options for the Mac Pro are very weak, they will likely be sufficient for Aero but if you are using Creative Studio tools or other tools capable of using the GPU, you may want to consider a GPU upgrade as well, although I don't know what will work with Mac OS X. (I presume your mobo just has a standard 16x PCI express port.) Also you may want to make sure you can actually use Windows 7 x64, while your CPU is x64, the linked article suggests it has EFI32 and uses a 32 bit Mac OS X kernel and I don't know how Boot Camp works. Windows 7 x32 doesn't support more than 4GB, actually it doesn't support 4GB entirely either. And even if you uses 32 bit version of Windows with PAE, I'm pretty sure the 32 bit versions of the apps can't use more than 4GB. Nil Einne (talk) 12:45, 10 July 2013 (UTC)
- Forgot to mention you shold also determine if your computer uses registered or unbufferred RAM. Nil Einne (talk) 03:04, 16 July 2013 (UTC)
- BTW, I'm pretty sure the 7300GT is not exclusive to the Mac Pro though the update you linked to appears to be for one which was. Also all cards listed as options for the Mac Pro are very weak, they will likely be sufficient for Aero but if you are using Creative Studio tools or other tools capable of using the GPU, you may want to consider a GPU upgrade as well, although I don't know what will work with Mac OS X. (I presume your mobo just has a standard 16x PCI express port.) Also you may want to make sure you can actually use Windows 7 x64, while your CPU is x64, the linked article suggests it has EFI32 and uses a 32 bit Mac OS X kernel and I don't know how Boot Camp works. Windows 7 x32 doesn't support more than 4GB, actually it doesn't support 4GB entirely either. And even if you uses 32 bit version of Windows with PAE, I'm pretty sure the 32 bit versions of the apps can't use more than 4GB. Nil Einne (talk) 12:45, 10 July 2013 (UTC)
- It's quite doubtful that you need RAM with heatsinks or heatspreaders, this depends entirely on the manufacturer of the RAM. That said, you should stick with ECC RAM if that is what's used, there's no guarantee non ECC is supported and if you are using the computer for professional purposes you may want ECC anyway. 800mhz RAM would probably work presuming it has SPD settings for 667mhz which it probably does, but there are no guarantees. (I'm presuming your mobo/chipset isn't capable of using 800mhz RAM which I don't lnow for sure.) But there are no guarantees particularly with such old hardware, sometimes weird stuff happens, e.g. I know of someone who had major problems getting single sided (well single ranked) 4GB DDR3 sticks to work even though double sided ones alleged work fine. And random compatibility problems can happen even with stuff which you would expect to work. And it may or may not be worse with ECC, I have insufficient exprience to say. Both computer or mobo manufacturers and RAM manufacturers generally publish RAM-mobo compatibility lists, but such lists are often very limited. Nil Einne (talk) 10:34, 10 July 2013 (UTC)
- Further proof: This[1] Windows7 update, right from Apple, for the NVIDIA GeForce 7300 GT or Quadro FX 4500 graphics card on the Mac Pro, that were *EXCLUSIVELY* shipped with the original 2006 first-generation Mac Pro, as you can see at Mac Pro. The only reason why Apple does not "officially" support Windows7 on the original 2006 first-gen Mac Pro is because the minimum RAM that it was shipped with was only 512MB, and Win7 64-bit requires 2GB RAM, a RAM size easily supported by this machine which could be shipped with up to 16GB RAM from Apple directly, and can *STILL* be expanded up to 32GB RAM. --37.80.190.4 (talk) 02:34, 10 July 2013 (UTC)
- I would expect the 800MHz ECC memory you found to work. If you want something known to work, try this: [2]. It is a link to Crucial's RAM finder tool. I have a feeling the stuff on Amazon is much cheaper than what Crucial wants to sell you. 209.131.76.183 (talk) 11:50, 10 July 2013 (UTC)
July 10
Using SSL with a Server without a DNS Domain Name
Is there a standard way of using SSL with a server on a private network that has no real DNS domain name? The clients in this case are software systems that know the server by a private IP address. I can think of some ways to make SSL work but I wonder what the standard practice is, or if there is one. 173.49.12.2 (talk) 04:25, 10 July 2013 (UTC)
- You can use self signed certificate, or run your won certificate authority and sign your own certificates. Import your authority certificate into your web browsers. Graeme Bartlett (talk) 10:04, 10 July 2013 (UTC)
- But what do you use as the subject (the CN in particular) in the cert for the server? The name should be one by which the clients know the server. I guess you can use the server's (private) IP address, but it feels "wrong" and it's not clear whether the (non-browser) clients will support it. Another possibility is to give the server some private domain name (perhaps a .local one) and make the clients use that instead of an IP address. The name can be resolved using a local DNS service or hosts files. What is the standard practice, if there's one? --173.49.12.2 (talk) 12:33, 10 July 2013 (UTC)
- I don't know about "standard" but many larger companies use a local DNS (or sometimes WINS) for secure sites within their organisations. They often don't use self-signed certificates directly, but a self-signed signing certificate. That way the one certificate can be added to the organisation's browsers and it can then verify multiple internal sites. In effect it is a local Certificate Authority. -- Q Chris (talk) 07:53, 11 July 2013 (UTC)
- But what do you use as the subject (the CN in particular) in the cert for the server? The name should be one by which the clients know the server. I guess you can use the server's (private) IP address, but it feels "wrong" and it's not clear whether the (non-browser) clients will support it. Another possibility is to give the server some private domain name (perhaps a .local one) and make the clients use that instead of an IP address. The name can be resolved using a local DNS service or hosts files. What is the standard practice, if there's one? --173.49.12.2 (talk) 12:33, 10 July 2013 (UTC)
Coding and Minecraft
I have tried to view webpages and watch videos about learning to use Java, but it appears to be too difficult to remember and use. How can I learn Java online without forgetting or finding it too difficult?
Also, how do create new mobs and blocks for Minecraft, again the stuff I looked at appears to be too difficult for me?
Please assist. 92.0.111.155 (talk) 05:13, 10 July 2013 (UTC)
- Don't expect to learn programming by reading and viewing only. You need to actually do it. I would suggest to start with a friendlier language than Java - check out Python and in particular, try to work your way through the Python tutorial. Once you got the knack of programming in general, moving to another language in the same paradigm is fairly easy. Learning a new paradigm is not, but is very satisfying ;-). Good luck! --Stephan Schulz (talk) 14:16, 10 July 2013 (UTC)
- For your Minecraft question here's a tutorial which claims to be easy for beginners - I can't verify though because I don't play Minecraft... --Yellow1996 (talk) 16:04, 10 July 2013 (UTC)
- I cannot get that to download 92.0.111.155 (talk) 21:47, 10 July 2013 (UTC)
- Oh - sorry about that, the page must be old because one of the links is to Megaupload, a service which ceased to exist over a year and a half ago. This is the Minecraft wiki's page for mod creating, though it says it requires some knowledge of Java. I guess you'll need to learn the basics of that language before you do any modding. Good luck! --Yellow1996 (talk) 00:53, 11 July 2013 (UTC)
- I don't have anything Minecraft specific (never played it), but I do a lot of modding and amateur game development. Reading about the theory of programming and what's actually going on (and the right way to do it) is useful; but what really helped solidify concepts for me was taking existing programs/mods, reading through them, then coming up with small changes, trying them, and seeing if they conformed to what I thought. Sometimes doing things this way can help you with difficult ideas since if you aren't advanced enough yourself to implement them, you can't play with them; whereas modding someoneelse's implementation can give you immediate and visible feedback on what the components do.Phoenixia1177 (talk) 07:41, 13 July 2013 (UTC)
Why do computers have such a hard time when it comes down to simple tasks?
Why exactly can computers make beds? Or change diapers and such? The less intelligent humans that I know can do it without any mental effort. If we let the computer extra time, like some hours, would it manage to make a bed? OsmanRF34 (talk) 16:30, 10 July 2013 (UTC)
- Why do we continue to let Osman ask questions like this? Shadowjams (talk) 06:56, 11 July 2013 (UTC)
- Why not? If no one wanted to answer it, they wouldn't. It may be bordering the "we do not answer predictions" clause in the posting guidelines, but I largely interpret that to mean "go away trolls". This seems a legitimate question based on trying to understand the operation of a very complex, modern technology. -Amordea (talk) 17:03, 11 July 2013 (UTC)
- Why do we continue to let Osman ask questions like this? Shadowjams (talk) 06:56, 11 July 2013 (UTC)
- It's not the computers' fault, it's the people's :) A less intelligent human may indeed make beds easily, but it takes lots and lots of intelligence to be able to write a set of instructions on how exactly to do it (step by step, outlining every step in meticulous detail). And don't forget the instructions on how to deal with various situations that may arise in the process. Try creating a list of all the things that can go wrong when you are making the bed and you'll appreciate the enormity of the task! All computers do is follow the instructions, and if the instructions are lousy, so is the outcome.—Ëzhiki (Igels Hérissonovich Ïzhakoff-Amursky) • (yo?); July 10, 2013; 16:39 (UTC)
- Well, do computers need to know exactly? Machine learning and such can deal with many not well-defined cases, and the bed is a 'closed' system (in the sense that you know how many sheet are there, it's not like driving, when lots of things can happen). Add to it that you could put RFID tags to help the computer know where the sheets are. OsmanRF34 (talk) 16:44, 10 July 2013 (UTC)
- But they do need to know exactly; that's the nature of computers. Everything they do boils down to zeroes and ones, choices between on and off. Any operation a computer/robot perform is the result of following a set of instructions in an applicable situation. If the situation is not ideal (say, a pillow fell on the floor, and the robot can't see it), then the fall-back instructions are followed to rectify it, but, of course, someone needs to anticipate this kind of problem and to write a set of instructions to deal with it. Machine learning can deal with many ill-defined cases, but once again, someone needs to tell the machine how to deal with them (and to anticipate the problems in the first place).—Ëzhiki (Igels Hérissonovich Ïzhakoff-Amursky) • (yo?); July 10, 2013; 16:51 (UTC)
- Well, do computers need to know exactly? Machine learning and such can deal with many not well-defined cases, and the bed is a 'closed' system (in the sense that you know how many sheet are there, it's not like driving, when lots of things can happen). Add to it that you could put RFID tags to help the computer know where the sheets are. OsmanRF34 (talk) 16:44, 10 July 2013 (UTC)
- (edit conflict) It's because the computers have no understanding of the real world - save that which we tell them. You couldn't just throw a computer into a situation and expect it to figure it out without some prior information. The closest to real learning is machine learning but that still takes human intervention. We could program a computer to operate a robot which could make a bed; but as for a computer which learns the method of how to make one itself from nowhere, I don't think that's possible (yet...) Also, something I found when I searched "computer that makes your bed" on Google: [3] --Yellow1996 (talk) 16:42, 10 July 2013 (UTC)
- Yes, computers have no understanding of the real world, but what makes it so difficult to deal with a sheet? You could model it as a mesh of points (distance about half an inch each). There are not many variables there. OsmanRF34 (talk) 16:46, 10 July 2013 (UTC)
- Well as long as you tell it what to do with the sheet, it shouldn't be a problem. However, as Ëzhiki points out above, you need to account for many variables so that the computer knows what to do when there's a problem. I assume that nobody has really taken the time to do this (besides a few models of beds which can make themselves - but that's a little different) because making the bed is not a very complicated and time consuming task. --Yellow1996 (talk) 17:02, 10 July 2013 (UTC)
- While there are many tasks that are genuinely hard for a computer, making a bed should not be among them. The reason they cannot do it is that there is no demand for it. And there is no demand because even in highly developed countries it is cheaper to do it yourself or hire human help than to have a complex robot specialized for just one or a few tasks. The major problem with making a bed is not the algorithmic part - take 10 grad students, give them enough gear, food, caffeine, 1 year of time and a price of a million dollars per person if they figure it out, and they will figure it out. The hard part is to provide the mechanical parts within a reasonable budget (and "the mechanical parts" would probably include making the room larger so that the robot can vanish into a discrete locker when not in use).--Stephan Schulz (talk) 17:21, 10 July 2013 (UTC)
- Computers can't make beds or change diapers because they don't have arms and hands -- or eyes, for that matter. Looie496 (talk) 03:10, 11 July 2013 (UTC)
- You could design a computer that makes a bed or change a diaper. I'm sure we will someday. It's just too expensive to design and build one at the moment and the price of obtaining one would outweigh the cost of hiring someone to do it. Electronic parts are getting cheaper and more powerful all the time, though. Also, as mentioned, computers are actually quite stupid. Our programming languages are very inadequate for anything other than telling them to do low-level functions like addition and data transfer. So, the language we use to interact with computers needs to evolve, as well. We need to abstract more functions away from the programmer with more libraries that do the dirty work in the background. So, the workers you mention that make beds for a living are actually much more intelligent than any computer. They can program themselves, regulate their heartbeat and breathing without effort, process super high-definition 74-megapixel video at 12 FPS with their eyes, and process touch and very high-definition audio simultaneously. They can make the bed without any effort after training and simultaneously daydream about other things while doing so. They store 2.5 petabytes of information in their brains and that far exceeds most computers made today. Computers are slowly getting smarter. It will happen, eventually.—Best Dog Ever (talk) 04:34, 11 July 2013 (UTC)
- It's very likely the fact that computers don't have world knowledge, even the lowest intelligence people have spent their entire life accumulating experience in the real world with brains, and sensory systems, tailor suited to that task by evolution. You may be interested in the following articles: Cyc, Knowledge base, Artificial intelligence, SHRDLU, Expert system, Open Mind Common Sense, and Mindpixel.Phoenixia1177 (talk) 07:48, 13 July 2013 (UTC)
Problems with FireFox on Linux
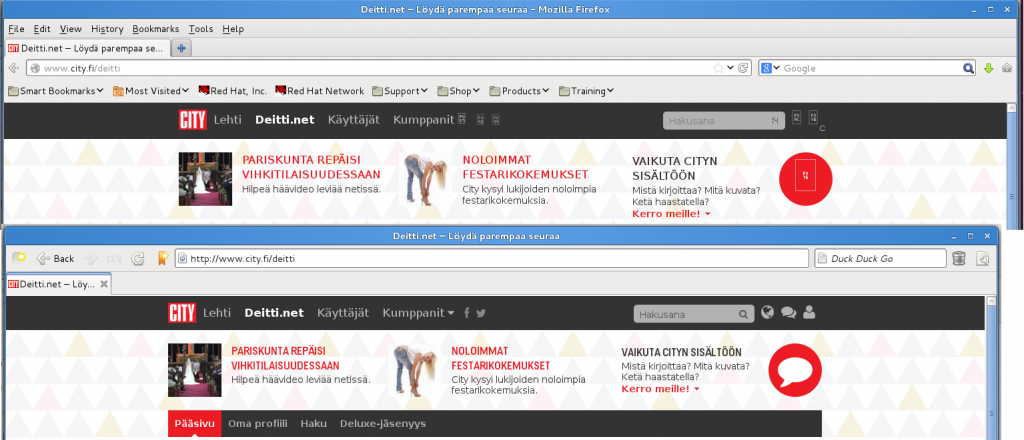
Have a look at this picture I took of an on-line dating site: http://i1291.photobucket.com/albums/b552/foobar16/Deitti_zpsbd7b73f6.png
{kind=link}
Both screenshots are from the same computer, running Fedora 17 Linux. The screenshot above is from FireFox 22.0, the screenshot below is from Midori 0.4.6.
Notice the problem? FireFox displays weird characters in the place of universally recognisable symbols, whereas Midori displays them all OK. Even better than that! At work, where I am forced to use Windows 7, FireFox has no problem displaying the symbols all correctly.
Actually, even getting to upload the picture was a hassle. FireFox wouldn't let me go past entering my sign-up information. With Midori, signing up was a doddle. Does all this mean FireFox 22.0 is hopelessly broken on Linux and I should switch to Midori instead? JIP | Talk 18:21, 10 July 2013 (UTC)
- The top one appears to be displaying unknown unicode characters, the bottom one is displaying an image. Is the top one a 2x2 grid of the numbers 0-9 and A-F? I suspect that, instead of using an actual image, the website is using a custom font with the images in it. Midori is respecting this, but Firefox isn't. As how to fix it, I don't know… CS Miller (talk) 18:43, 10 July 2013 (UTC)
- The Facebook and Twitter icons are characters in the unicode private use area (U+f098 and U+f099), rendered in the good version with the Font-Awesome icon font. In the bad case, for whatever reason, the browser has failed to load FontAwesome and is defaulting to its default sans font, which doesn't have glyphs for those codepoints (hence the hex-box fallback glyphs). I don't know why your Firefox 22 does that; on my Ubuntu box, Firefox 22 loads and renders the font icons fine. As with all problems Firefox, run in safe mode to see if one of your extensions is breaking it. -- Finlay McWalterჷTalk 18:55, 10 July 2013 (UTC)
- No, running in safe mode didn't help. JIP | Talk 04:29, 11 July 2013 (UTC)
Filling the inside of a polygon defined by vertex coordinates in Java.
I am looking at a problem i have in Java. There is a command i believe, whereby one can fill the area of any polygon with some color on an image buffer. The shape is defined by an array of coordinate pairs defining the vertexes of the shape. This is one of the fairly common graphics commands, i think its something like fillPoly.
My problem is thus:
I wish to make an algorithm so that two different polygons are filled with yellow. If any pixel is part of both polygons, that pixel will be orange instead of yellow when the second polygon is filled in. Furthermore, drawing a third polygon, if a pixel inside the area of this third polygon was yellow prior, it would be orange. If it was orange prior, it will now be red. The idea is to lay down consecutive polygons, with an algorithm in mind for however many shapes overlapping a pixel determining that pixel's color.
I do have a general idea for this, as i have done something similar. I can keep track of every pixel of the X*Y image buffer, with an X*Y two-dimensional array. The value of the location in the array shows how many polygons overlap there, and consequently tells what color the pixel should be when drawing a new polygon. The PROBLEM with this approach is, i would have to know given the definition of the shape as a vertex list, whether every pixel in the image is inside or outside the shape. If it is inside the shape, read that pixels current value in the array and modify the color and array as appropriate.
However, i have NO IDEA how to tell if a pixel is in a shape or not! I also fear that there may be a more elegant solution than what i am thinking of.... i was taught in programming classes to look for those elegant solutions.
Does anyone know the solution to this issue? PLEASE let me know if there is a more simple way to think of this as well, as id rather not bang my head against the wall if a better answer could stare me in the face. :)
Thank you very much in advance! 216.173.145.47 (talk) 21:20, 10 July 2013 (UTC)
- The general article about determining whether a point is in a polygon is point in polygon. You might find it easier to transform the way you store polygons to a list of triangles (see polygon triangulation) as the test for "is this point in this triangle" is straightforward. To avoid keeping a track per-pixel, you may find algorithms like the Weiler–Atherton clipping algorithm useful, where you can track the results of polygon intersections mathematically rather than brute-forcing per-pixel. As you're using Java, you can try JTS Topology Suite (but I'd encourage you to give doing it yourself a go first). Most generally, this falls within the ambit of the general topic of computational geometry. -- Finlay McWalterჷTalk 21:37, 10 July 2013 (UTC)
- It wouldn't be efficient or elegant, but if you want a simple to implement (and understand) solution, you could use the built in fillpoly method you mentioned. If it supports transparency, then you can just layer all the polygons with transparency. Anywhere that overlaps will have a different intensity than where they don't overlap. Then you can go through the pixels and remap the colors to match what you want. A geometric solution would certainly be faster and more elegant, and implemented well it would just as easy to read and understand (keeping the math abstracted away). 209.131.76.183 (talk) 14:13, 11 July 2013 (UTC)
I confess i do much like this more simple way of soing it. However, one thing i dont like about it is i think every shape needs to be laid down before the coloring scheme can be applied. I would prefer a method that will work for laying down the shapes one by one. Perhaps i can lay down a gray color for each shape and have an array of colors that are the combo of the gray shape with the underlaying other shapes, and that could be detected and fiddled with. 216.173.145.47 (talk) 16:05, 12 July 2013 (UTC)
Mail on Darwin Unix
I am a Unix novice (trying valiantly to learn on Mac OS X though) and one thing I would like is the ability to use the mail command in the shell. I can't readily find any information about setting it properly on the web though (or, at least, not any that is readily recognisable or intelligible to me), so I wondered if anyone here might know where I could find a suitable set of instructions, or, if it's not too demanding, even walk me through it? Thanks. meromorphic [talk to me] 22:59, 10 July 2013 (UTC)
- Does this thread help? If not, one of our Unix masters will probably be able to assist you better! --Yellow1996 (talk) 01:00, 11 July 2013 (UTC)
- You probably want a full-blown mail client - like Alpine. Alpine is free software but it's not easy to set up if you're a total novice. Instructions are available for Building and Installation.
- If you really are on a Mac, you can also use mail - the mail utility: x-man-page://mail (You can copy that URL to your browser!) It's the official man page that's built in to your system, documenting the command-line mail command. Nimur (talk) 02:29, 11 July 2013 (UTC)
July 11
How to delete floppy disk stuff from BIOS (http://www.gigabyte.com/products/product-page.aspx?pid=3610)
I have searched around inside the BIOS, I have flashed them to the newest version, but it seems I cannot find the command to disable floppy disk anywhere. I need to do this so I could use GParted to partition my drive so I could dual boot linux into that — Preceding unsigned comment added by 140.0.229.26 (talk) 00:01, 11 July 2013 (UTC)
- You shouldn't need to disable the floppy disk in the BIOS. With GParted, you can select which device it is working on - the control for that is in the upper right of this image. If you really, really must disable the drive, why not open the case and try disconnecting the cable. Astronaut (talk) 16:15, 11 July 2013 (UTC)
{kind=link}
- I haven't make this clear but I don't have any floppy drive, who use that today? And if I didn't disable the floppy drive it stuck at scanning devices 140.0.229.26 (talk) 13:41, 12 July 2013 (UTC)
- The reason why you can't disable the floppy disk in your BIOS is probaly because your mobo has no native support for a floppy disk. This is clearly visible in both the images and and the specs of the link you provided, as well as the manual [4]. I don't know what problem you are having but I don't see any reason to think it has anything to do with a floppy disk particularly if you haven't attached an addin card to that provides a FDD port, and you didn't explain why you believe it's the cause of your problem either. It would be helpful if you better explain where exactly you are having problems and what, if any, error messages you get after waiting a resonable length of time (say 15-20 minutes), what you've tried to do to resolve the problem (e.g. if you have multiple devices did you try disconnecting all but the one you want to work with) and more info on your set up etc etc. Your first post was entirely unclear, you second post only clarified very slightly. I presume GParted getting stuck somewhere, probably at startup, but other then that I don't know much else and as I said it's entirely unclear why you think the problem related to a floppy drive. Nil Einne (talk) 16:25, 13 July 2013 (UTC)
Mouse scrolling making BROWSER problems...
I have this EXTREMELY annoying bug... I CAN'T get rid of.
It started a while ago, I don't even know how, just started, one day.
when I scroll on pages, mostly UP, it turns into the normal scroll-up icon and when I press other tabs in google chrome it CLOSES them... and the START BAR won't work either... it's like frosen and when I press back on pages after having SCROLLED, it creates a new with the same page... WTF is going on.. why is MOUSE SCROLLING causing computer problems AND browser problems? This comp is 3 months old............. — Preceding unsigned comment added by 212.30.207.211 (talk) 02:50, 11 July 2013 (UTC)
- I doubt it's your computer - it's probably Chrome's doing. Have you installed any new addons recently? Disable those one by one and see if the problem stops. If that doesn't work you could try reinstalling Chrome. --Yellow1996 (talk) 16:18, 11 July 2013 (UTC)
- For the record, pressing the scroll wheel down (this is referred to as clicking the middle mouse button) while pointing at a tab will close the tab. It's meant to do that. That's how browsers are programmed, it's just a short cut. I'm not sure about the rest. Falastur2 Talk 21:24, 11 July 2013 (UTC)
Point and shoot cameras
Does the amount of megapixels significantly affect image quality in a point and shoot camera? I ask as I find that a 4 megapixel point and shoot camera can take photos with better image quality than an 8 megapixel smartphone camera. — Preceding unsigned comment added by Clover345 (talk • contribs) 12:01, 11 July 2013 (UTC)
- That's the usual situation. Megapixel is often mistakenly used as a figure of merit. See Digital_camera#Image_sensors. Pixel count can make a difference, but I often get better results from an old 2 Megapixel camera than a new 14 Mpx one. Jim.henderson (talk) 12:22, 11 July 2013 (UTC)
- Megapixels will make a difference on print quality, and more megapixels lets you print on larger surfaces. About 8 megapixels allows you to print at a good quality level on a 8.5" per 11" sheet of paper (~300 Dots per inch), so more megapixels than that will generally not be very useful. Digital displays need even fewer megapixels - 1080 HD is only about 2.1 megapixels. More megapixels reputedly allow for more flexibility in post-processing. 64.201.173.145 (talk) 14:24, 11 July 2013 (UTC)
- It depends. All other things being equal, a higher number of pixels allows a better depiction of fine details. On the other hand, for any given camera design, a higher resolution on a sensor of the same size means that the ccd elements are smaller, and thus more susceptible to (thermal) noise, so that the image often looks more washed out. Also, for most applications there is a useful limit to the number of pixels - your pixel resolution does not need to be better than your optical resolution, or your print/display resolution. Finally, all other things usually aren't equal. Better optics, image stabilization, and even such a trivial thing as ergonomic shape of the camera body will have an influence on the quality of the image. Not to mention the skill of the photographer in picking and arranging motives and knowing about good and bad lighting conditions. I've seen Japanese tourists trying to light up St. Peter's Basilica with the Flashcubes of their Instamatics. Small negative size was not the major problem with those photos ;-).--Stephan Schulz (talk) 14:43, 11 July 2013 (UTC)
- Yeah. For smart photographers with high end hardware, Megapixels can make a difference. When the rest of us point our little P&S, the part that spoils the picture we put in Wikipedia is under our hat. Jim.henderson (talk) 15:05, 11 July 2013 (UTC)
- Sometimes turning down the resolution on a camera can help get better shots. The camera will still capture at the full resolution, but combine adjacent pixels. This can help smooth out noise or let you get away with a shorter shutter time in low light situations. Your point-and-shoot also probably has a much better lens than your phone. 209.131.76.183 (talk) 15:29, 11 July 2013 (UTC)
- Probably 8 magapixels is no better than 4 megapixels on a camera like that. Those cameras have really low-quality lenses and everything else. Bubba73 You talkin' to me? 01:06, 12 July 2013 (UTC)
computer infected by virus
My net book is badly infected by a virus."registry editor is disabled by administrator" message appear when ever try to edit reg ,I can not open taskManager ,it is also disabled by admin appears.every computer folder has a subfolder with same name ,I am not able to delete them manually.Run command is missing from start menu,It does not allow me to download antiviruses on line .It does not allow me to download acrobat reader from internet. Is their any online solution or other ,otherwise I have to re install windows xp again, — Preceding unsigned comment added by 182.187.77.255 (talk) 23:18, 11 July 2013 (UTC)
- Go to C:\WINDOWS\system32\drivers\etc and you should see a file called "hosts". Open it in Notepad, blank it completely and set it to read-only, then reboot your computer. Can you access antivirus websites after that, or does the virus recreate the file? Post back here, thanks. Ginsuloft (talk) 23:22, 11 July 2013 (UTC)
- And if it does recreate the hosts file then you can transfer an AV software via USB stick since it won't let you download one directly on the computer. --Yellow1996 (talk) 01:18, 12 July 2013 (UTC)
- Just my two bits, but I'd go with the wipe and reload. You can fight with the virus if you so choose, but you have no idea how long you will be battling it or how extensive the infection is or if it will still be lurking on your system after you think you've gotten rid of it, only to manifest itself again at a later time. When you wipe and reload, only then can you be certain it's gone.
- When you reinstall Windows, get ALL of the security updates before you surf the web on that computer again. Also use a different browser than Internet Explorer. And consider switching to a new operating system soon; support for Windows XP ends on April 8, 2014, which means no more security updates.
- If you need to transfer data from the old install to the new, ensure that AutoRun is turned off before inserting potentially virus-tainted media on your fresh install. Transfer no executable files if you can avoid doing so. Images and documents are fine.
- Good luck! -Amordea (talk) 03:35, 12 July 2013 (UTC)
- For the taskmanager, try going to C:\Windows\System32\, copy the taskmgr.exe file to somewhere else, rename it winlogon, then try to open it. A lot of malware will let programs named winlogon run since it's required to get windows going. You might also try the same thing with the registry editor (if you're brave). If you can, via this or other, get a copy of hijack this running, if you want to post the logfile on my talk page, I'd be willing to take a look and help you figure out what's gong on.Phoenixia1177 (talk) 03:53, 12 July 2013 (UTC)
- You can also try the following: get a version of linux you can boot from usb, like [5]; boot from it; clean up any obvious garbage; try booting from windows. If you still can't get windows to work: there is a folder on XP, somewhere in the Windows directory, that contains clean versions of your registry files (it's called repair, or recovery, or some such); swap those out with your actual registry; boot in windows; open regedit; load your actual hives; clean them up (I'm guessing you know how from referencing regedit); reboot from linux; swap them again; try windows.Phoenixia1177 (talk) 12:39, 12 July 2013 (UTC)
July 12
Bugged by design Microsoft vs HIPAA
Now that M$ baked in insecurity has been leaked...
http://www.guardian.co.uk/world/2013/jul/11/microsoft-nsa-collaboration-user-data
Isn't it a violation of the Health Insurance Portability and Accountability Act to use any M$ spyware in any doctor's office, hospital or insurance company? Hcobb (talk) 00:49, 12 July 2013 (UTC)
- The reference desk isn't able to decide what is legal and what is illegal - that would be providing legal advice.
- My position is twofold: first, the media is sensationalizing a "breaking story" about something that is actually very commonplace, and has been commonplace for decades, in many forms, technological and otherwise. Various media providers may have a vested interest in all this mudslinging; newspaper articles like the Guardian article you linked are not doing a great job of providing a neutral point of view.
- Secondly, just because something is morally objectionable (to some people) - like massive government surveillance and corporate collusion - it is not necessarily illegal. Law is so complicated that attorneys spend years studying it. Even then, lawyers rarely agree with each others' interpretations. It is very probable that the various parties involved took great care to ensure that they were totally complying with relevant laws. For example, this press release Statement to the NSA/CSS workforce, states clearly: "Through four years of oversight, the committee has not identified a single case in which a government official engaged in willful effort to circumvent or violate the law." Nimur (talk) 01:32, 12 July 2013 (UTC)
- The article doesn't seem to be describing MS illegally forcing records on the NSA, it sounds like the NSA legally obtaining records from MS with their cooperation (Apple, Google, etc. were mentioned too). I'm pretty positive if everybody suddenly quit using Google, MS, etc. because of NSA and CIA surveillance, that they would use their authority to monitor whatever service everyone switched to. The issue isn't MS, the issue is the NSA, CIA, and FBI (if you have an issue), you can always consult a lawyer and see about challenging them...but I doubt that would go anywhere.Phoenixia1177 (talk) 04:08, 12 July 2013 (UTC)
- HIPPA has all sorts of carve outs for legally authorized disclosures, and even if it didn't, it'd be hard to argue that you couldn't, for instance, obtain certain information in a criminal defense. Armchair lawyering like this tends to go from conclusion to reason, and rarely holds up to an even cursory reading of the law. On that point, I've got zero inclination to do the latter. Shadowjams (talk) 06:36, 13 July 2013 (UTC)
- Were you responding to me or the op?Phoenixia1177 (talk) 07:27, 13 July 2013 (UTC)
CPU clock discrepancy
When I ran CPU-Z with my Core i7 2600K at factory settings, which include FSB at 100.0 MHz, CPU-Z reported the front-bus speed as actually 99.77 MHz, and a CPU clock speed consistent with that slightly slower FSB. I've since changed my FSB setting in BIOS to 100.3 MHz, and CPU-Z reports 100.10 MHz. Does this mean the CPU clock is running slower than the real-time clock? If so, which one is likely to measure a second more accurately? (I bought the CPU and motherboard at the same time.) NeonMerlin 13:10, 12 July 2013 (UTC)
- Late reply but...
- Because an early (as in "running too fast") real-time clock would be wrong by 8.64 seconds per day if it were only 0.01% faster than a perfect cock, it is safe to assume that your bus is actually a bit on the slow side.
- However, I'd ask you if your PC is actually doing a solid hour of I/O per day? If it is, the slow bus would result in a 7.9 second penalty compared to the "perfect motherboard" - not really worth correcting for speed reasons.
- IIRC, the bus tolerances are 1.5% - i.e. there could be seven times the deviation your bus clock exhibits before you'd run a risk of into any signal corruption.
- But if you want to get it right for rightness's sake, "100.3" (that is, 100.07 MHz) is certainly a closer fit than 99.77 MHz. Just don't expect any significant speed or reliability increase from it. - ¡Ouch! (hurt me / more pain) 07:14, 16 July 2013 (UTC)
- *clock. Damn, Google's gonna give us a lot of traffic for this one...- ¡Ouch! (hurt me / more pain) 07:25, 16 July 2013 (UTC)
Error debug
Hey there! I was working with nested switch case in C++ language. The code i developed gives 0 error and 0 warning. But it does not execute any of the switch. It just exit. Can any one please tell me where the mistake is . I have got stuck. Any help will be highly appreciated. Thanks
C++ code
|
|---|
# include <iostream>
# include <math.h>
# include <conio.h>
using namespace std;
int main()
{
int option; // variable for option for the type of photo
int op; // option for size of photo
int np; // option for number of photos
int cop; // cost of photo
cop= 10; // price of one photo
int cost_photo;
cout<<"\nEnter the option number from following for the type of photo you need";
cout<< "\n1. coloured photograph" ;
cout<<" \n2. Black & White photograph";
cout<< "\n3. sketch " <<endl ;
cin>> option ;
switch (option)
{
case '1':
cout<< " \n1.Passport size photograph"<<endl;
cout<<"\n 2.9 x 4 photograph";
cout<<"\n 3.5 x 11 photograph";
cout<< "\nplease enter the photo size option fron above options\n";
cin>> op; // takes the option as input for size of photo
switch (op)
{
case '1':
cout<< "\nHow many photgraphs are required\n";
cin>>np;
cost_photo= (cop*np)+5;
cout<< " Your total bill is "<<cost_photo<<endl ;
break;
case '2':
cout<< "\nHow many photgraphs are required\n";
cin>>np;
cost_photo= (cop*np)+10;
cout<< " Your total bill is "<<cost_photo<<endl ;
break;
case '3' :
cout<< "\nHow many photgraphs are required\n";
cin>>np;
cost_photo= (cop*np)+15;
cout<< " Your total bill is "<<cost_photo<<endl ;
break;
default:
cout<<"Please enter the correct option";
}
break;
case '2':
cout<< " \n1.Passport size photograph";
cout<<"\n2.'9 x 4' photograph";
cout<<"\n3.'5x11' photograph";
cout<< "\nplease enter the size option\n";
cin>>op; // takes the option as input for size of photo
switch (op)
{
case '1':
cout<< "\nHow many photgraphs are required\n";
cin>>np;
cost_photo= (cop*np)+20;
cout<< " \nyour total bill is "<<cost_photo ;
break;
case '2':
cout<< "\nHow many photgraphs are required\n";
cin>>np;
cost_photo= (cop*np)+30;
cout<< "\n your total bill is "<<cost_photo ;
break;
case '3':
cout<< "\nHow many photgraphs are required";
cin>>np;
cost_photo= (cop*np)+45;
cout<< " Your total bill is "<<cost_photo<<endl ;
break;
default:
cout<<"Please enter the correct option";
}
break;
case '3':
cout<< " \n1.Pencil sketch";
cout<<"\n2.'charcoal sketch";
cout<< "\nplease enter the sketch type option\n";
cin>>op; // takes the option as input for size of photo
switch (op)
{
case '1':
cout<< "\nHow many photgraphs are required";
cin>>np;
cost_photo= (cop*np)+20;
cout<< " Your total bill is "<<cost_photo<<endl ;
break;
case '2':
cout<< "\nHow many photgraphs are required";
cin>> np;
cost_photo= (cop*np)+30;
cout<< " Your total bill is "<<cost_photo<<endl ;
break;
default:
cout<<"Please enter the correct option";
}
break;
}
getch();
return 0;
}
|
Mike robert (talk) 15:29, 12 July 2013 (UTC)
- You're doing what amounts to:
int option;
cin >> option;
if (option == '1') ...
- so in that last line you're comparing the int option with the char '1' (which, because it's ascii, is 49, not 1). You probably just want case 1: not case '1'
- -- Finlay McWalterჷTalk 16:58, 12 July 2013 (UTC)
- Thankyou so much. I didnt notice that. Now it's working. :)Mike robert (talk) 17:08, 12 July 2013 (UTC)
Is there a frexp function for JavaScript
The frexp function found in the standard c library exists as a function in JavaScript? I've looked everywhere but I've found nothing. Where can I find it? 181.50.178.92 (talk) 23:42, 12 July 2013 (UTC)
- Unless you are using an exotic JavaScript interpreter, there is no frexp function built in. You can compose the same mathematical functionality using Math.log (and related functions), part of the standard Math object; or by writing your own function - it might be a good exercise in practical applications of recursion!
- If you want to live dangerously, you can attempt to implement a constant-time algorithm (instead of an O(log(n)) time algorithm by directly inspecting the binary representation of the floating point numeral - chances are very good that it's stored as a IEEE 754 numeral (on any sane JavaScript implementation). But if you walk down this dangerous road, you will soon realize that JavaScript doesn't make this style of programming very easy - for one thing, type punning is not defined, because JavaScript is type safe and dynamically typed. Nimur (talk) 01:25, 13 July 2013 (UTC)
- This should get the internal representation of a float (which on my nodejs build is a single precision IEEE 754 float) as an int:
function float_as_int(fl){
var ab = new ArrayBuffer(4);
var fa = new Float32Array(ab);
fa[0] = fl;
return new Uint32Array(ab)[0];
}
console.log(float_as_int(3.1415));
- That's essentially what in C would be:
float pi = 3.1415;
printf ("pi as an integer:%d\n", *(uint32_t*)&pi);
- A C implementation of frexp which uses the internal representation (it uses doubles) is here. That entails extracting the exp and fraction part of the IEEE number (the C code does it in macros), which (I haven't tested it) should be:
var num = float_as_int(3.1415);
var exponent = (num & 0x7f800000) >> 23;
var fraction = num & 0x7fffff;
- then I guess you normalise per that code.
- -- Finlay McWalterჷTalk 02:35, 13 July 2013 (UTC)
- Since we're doing things the hard way, and I've already implemented this code, I may as well share it... in Python, the math object in the standard library implements frexp, but I wrote a function myself just to be sure I could.
#!/usr/bin/python
import math
x = -4271.437 # example input
exp=0;
while (2**exp < abs(x)):
exp += 1
fr = x / 2**exp
result = (fr, exp)
print (result)
print (math.frexp(x)) # sanity check against the math.frexp version
<HTML>
<BODY>
<!--
<SCRIPT language="javascript">
var x = 4271.437;
var exp = 0;
while(Math.pow(2,exp) < Math.abs(x))
{
exp += 1;
}
var fr = x / Math.pow(2,exp);
document.write("<br/>FR=");
document.write(fr);
document.write("<br/>EXP=");
document.write(exp);
</SCRIPT>
//-->
</BODY>
</HTML>
- The real meat of this algorithm is only a few lines of code, and did not require recursion. You could trivially convert this to JavaScript. In principle, it should be safer - and slower - than Finlay's version; but that depends on your exact needs and use-case. You might also want to check the behavior on weird floating-point inputs like NaN and negative zero.
- Also, I'm impressed that Finlay found a way to type-pun in JavaScript. His code works! But that sort of hackery should probably be avoided if you're deploying your script via the web - you never know how it might break on weird clients! Supposing somebody's running your JavaScript in Netscape on a really old SPARC or an IBM 390, or a VAX? In all seriousness, it's really unlikely JavaScript will ever run on a machine whose floating-point format is not IEEE 754, but it's still not a good idea to make assumptions about endianness or binary formats. Nimur (talk) 06:03, 13 July 2013 (UTC)
July 13
Windows 7 Administrator
I am running windows 7 on my PC. When I try to do a scan with my anti-virus software, it says I am not an Administrator. I am the only one who uses this computer and have no idea how to elevate myself to becoming an Administrator. Any help would be appreciated. 99.250.103.117 (talk) 00:42, 13 July 2013 (UTC)
- If you have the only account on your computer, then you should be an admin already. You can read more about admin rights in Windows 7 here (how to change an account's status, etc.) Hope this helps! --Yellow1996 (talk) 01:21, 13 July 2013 (UTC)
- When you open it, instead of double clicking: right click, select run as administrator, it will ask if you are sure, say yes. If this doesn't resolve it, you may have malware (or some other unwanted situation); if you do, I'd be willing to work with you to see about fixing things up.Phoenixia1177 (talk) 05:15, 13 July 2013 (UTC)
VisualSubSync Help
I am doing a subtitling job at the moment, and I am not entirely familiar with the software I have been requested to use. I have done a minute or so of this (short) video, but I would like to test it, to see if the subtitles are in the right place. Can anyone tell me how? KägeTorä - (影虎) (TALK) 09:38, 13 July 2013 (UTC)
- It looks like VisualSubSync will let you display the video in the editor (in the View menu, select Show/Hide Video), but I think it might only work if Windows can understand the video codec. Try it and see if the video shows up. If not, here are some ideas that might get it to work:
- Re-encode your video. When I tested an example video in VisualSubSync, the Show/Hide Video command didn't do anything. I used ffmpeg to re-encode the video to mpeg1, then VisualSubSync could display it. If your video is short (a few minutes), re-encoding might be reasonable. If your video is long, then re-encoding might take a long time.
- Install a codec? If your video doesn't show up in VisualSubSync, maybe installing a codec would help it display the video? In VLC Media Player, you can go to Tools, Codec Information to get information about the codec it's using, then perhaps you could search online for a matching Windows codec. Be aware, my understanding is that malicious codecs can contain malware, so carefully evaluate if you trust a codec source before installing it.
- Additional: In the VisualSubSync menu bar, I went to ?, Help, Codecs installation, and it went to Installing codecs, which appears to have similar advice. --Bavi H (talk) 18:03, 13 July 2013 (UTC)
July 14
wikipedia from 50 years ago
I am trying to link to wikipedia from 50 years ago. However I want to do this dynamically, so that on july 12 2013 I want to provide a link to July 12 1963 on August 1 2013 I want to link to August 1 1963. I have a reunion website that I'm trying to show this info - we have a count down till the reunion and a formula that shows each day how many days left. I can change that link to any date I want...so I can use the counter to link to wikipedia; just don't know how to reflect the correct wikipedia link So July 12th is http://en.wikipedia.org/wiki/July_1963#July_12.2C_1963_.28Friday.29 and I want to figure out how to grab that page dynaamically and have it change each day. Thanks Dick — Preceding unsigned comment added by RLR170 (talk • contribs) 04:27, 14 July 2013 (UTC)
- Depending on how your site is written, it's possible. You could prepare the link in a language such as PHP, and that would allow you to alter its contents to suit the day. As far as the actual code for that goes, it'd look something like this:
$year = date('Y')-50;
$month = date('F');
$day = date('j');
$weekday = date("l", mktime(0, 0, 0, date('n'), $day, $year));
echo "<a href='http://en.wikipedia.org/wiki/" . $month . "_" . $year . "#" . $month . "_" . $day . ".2C_" . $year . "_.28" . $weekday . ".29'>LINK TEXT HERE</a>";
- That should result in the correct date being provided in link form. I hope this helps! drewmunn talk 07:39, 15 July 2013 (UTC)
- (Second thoughts: this may not work as expected, as it is before the UTC creation threshold. If there is a way to link directly to a date without needing the day of the week, then that would be ideal) drewmunn talk 07:45, 15 July 2013 (UTC)
- And it will act funny on Feb 29, 2012 if you make it 1962. Not sure if it's gonna be undefined, but I'd convert the date to Julian date, then subtract 50*365+13 (or 12, depends on which date you want to match exactly) days, then convert back into normal "YYYY-MM-DD" date.
- I hope that's the way you want it to work. - ¡Ouch! (hurt me / more pain) 12:49, 16 July 2013 (UTC)
what sthe point of classes
How are you supposed to use classes?
When developing your own applciation, what's the point of a class hierarchy, I don't really get it. For example if I have an app that reads from the keyboard and the web cam as well, are these supposed to be different classes? Why?
The way I program now is I just put it all into one file with just Main() and some functions, some global variables. I don't really see a problem with the way Im doing it now --89.132.116.35 (talk) 12:53, 14 July 2013 (UTC)
- Have you read Class or object oriented programming? Dismas|(talk) 12:58, 14 July 2013 (UTC)
- The first one has a very short Benefits section that I can't apply to the example above. It says "Computer programs usually model aspects of some real or abstract world (the Domain). Because each class models a concept, classes provide a more natural way to create such models." I don't see why it's any more natural than simply including 5 global variables in the file for each aspect of the system. There's nothing 'naturally' divided into classes in the whole system, I would have to add on this abstraction after the fact. I'm open to how this helps. But to be clear, without the class, I can do everything. What do I get out of applying a class structure to it? The second article you link has no Benefits section but does have a section Criticisms, which is far longer than the benefits section of the first article. I'm not trying to argue - I'd like to see how for me and my example, why I should try to do make classes out of this system, and how I would do so. --89.132.116.35 (talk) 13:23, 14 July 2013 (UTC)
- Why should anyone attempt to demonstrate why it is better for "you" or "your example"? And why should it be? Generally it's much better to keep an organized file cabinet inside of an organized office, and if you're running a business, you're almost doomed to fail not doing this; on the other hand, if someone can get by tossing all their paperwork in a drawer, does this somehow make arbitrary the filing system used at giant corporations? Personally, I find it easier to think in terms of classes; I think it makes code more readable since it gives a general framework so you know what to expect; most things do break down into classes; and class structuring does scale well, while it's very hard to be certain random programmer Joe's structure will. Not to mention, going back to the general framework, it does make it easier to collaborate since it provides natural ways to divide up projects and layers of abstraction. However, all of that aside, if you can get by with your own personal system, no one's going to stop you. Finally, is their something specific that you would lose by using classes, do you see some large cost it imposes on what you're doing?Phoenixia1177 (talk) 14:03, 14 July 2013 (UTC)
- Three examples from my own life. Last year I made a really laughable ray tracer, inheritance was really useful when it came dealing with various shapes; I think it would've been a nightmare to deal with it differently. I wrote a piece of image processing software that analyzed batches of input images and applied filters according to its logic; the end result was about 45,000 lines of code, being able to hide away chunks of code dedicated to reading files and sorting batches made everything a lot more manageable (since those things aren't really related to images). Finally, a few years back, my friend made some graphics and we ripped off Final Fantasy Tactics and remade the battle engine ourselves (it was more fun than chess); being able to logically organize things on the basis of if they were game data, or graphics data, or etc. and how they all fit together made natural sense when viewed as objects; I don't think that project would have ever gotten off the ground if we didn't have a simple, and clear, way to translate the abstract components into code components. You may disagree and not see the merit in any of this, and that's fine, but it is a useful system for many.Phoenixia1177 (talk) 14:25, 14 July 2013 (UTC)
- You never need classes, just as you never need functions, or useful variable names, or types - these are all conveniences that allow you to fit a complicated program into your head, and to communicate it with other programmers. Simple examples of why classes are useful can be hard to come by, as simple programs are easy enough to fit into your head without breaking stuff up into classes. Instead of your keyboard+webcam app, let's say you were writing Robot Attack, a game where lots of robots live in a spaceship and kill foolish human interlopers. You'd probably have a big list of robots, and each tick of the game you check what each robot should do, and perform that action. Call each individual robot an instance. In a full featured game, there's a kinds of different robots: maintenance robots, patrol, security, battle, cargo transport, etc. Each kind (a class) has special behaviours (only patrol, battle, and security can fight, only cargo can move boxes, only maintenance can fix other robots that are damaged). But you notice that they all have some things in common - they can all pathfind around the spaceship, they can all open doors. So rather than replicating the movement and door code for each, you factor out that into a base class "robot". Now all the individual classes of robot are subclasses of that base class; and the code for the maintenance robot class only has the specialisation to do with specifically doing maintenance things (finding broken robots, fixing them, fleeing if it's attacked). We might look again at our simple class heirarchy of robots and decide that the fighting robots have common behaviour (they look for enemies and move to a firing position), so rather than repeating that code in the patrol, security, and battle robots we factor that out into an intermediate class. Now our class heirarchy looks like this:
class Robot :: class FightingRobot :: class PatrolRobot
:: class SecurityRobot
:: class BattleRobot
:: class MaintenanceRobot
:: class CargoRobot
- Now we can construct instances (specific robots) of a given class, and we need only specify the class to get all the behaviour associated with that class, e.g.:
Robot nigel = new PatrolRobot(name="Nigel", health="low", patrolRoute="room1;room3;room5;room1")
- ...and the "nigel" bot will have all the characteristics of a PatrolRobot, and because all PatrolRobots are FightingRobots, he gets those characteristics and behaviours too, and because that class is in turn a subclass of Robot, he gets the basic movement stuff that's implemented there too. In addition to behaviour, each class can have attributes (data). So say all robot instances have a "model" attribute, which is the little 3d model to use when drawing that robot. Subclasses can override these attributes (so PatrolRobots get a different model than a generic FightingRobot). And individual instances (specific named robots) can override these too. So you might create the spaceship's guardroom like this:
// create a couple of generic battle robots with the default settings Robot battle1 = new BattleRobot() Robot battle2 = new BattleRobot() // and the boss Robot boss = new BattleRobot(name="Evil Boss", model="evil_boss.model", health="hellatoomuch")
- What we've done in deciding this class heirarchy is the crux of your question. We've a) analysed all the things in the program, b) identified common behavior and attributes between classes of things, and c) structured our code to abstract commonality to baser classes and special characteristics to "leaf" classes or to instances. For real programs that's often a complex task, as it involves understanding all of what's going on. And there's usually multiple ways to do it. Looking for a "benefits" and "criticisms" section in some text is beside the point; classes are like the bolts and girders an engineer uses to build a bridge - the engineer has to understand the problem he's solving and understand the characteristics of the components he has available to build it. -- Finlay McWalterჷTalk 14:38, 14 July 2013 (UTC)
Fast direct access and SSDs
This is a three-part question.
The problem: I have several large files that I need to access directly to get a small amount of data each time. This will be done many times, so access time is very important. The files are too big to hold in the computer's RAM and a hard drive is too slow.
1. Because access time is very important, I think the way to go is with a SSD. Is this the best way to go?
2. Reading about SSDs, the ones using RAM have much better access times than ones using flash memory, right? (It is OK if it is volatile memory because I can reload the files from HD if needed.)
3. Hardware issues. The target computer is a Windows desktop with USB3, eSATA, an extra 5.25" SATA-2, and extra PCI slots. The RAM SSDs I've seen are 2.5" form factor instead of USB3. Are there any USB3 RAM SSD? Is there an adapter to put them in a 5.25" place? Are there any for eSATA? There also seem to be mSATA which look like they plug into PCI, but they say that they need to connect to the SATA data, and they look like they are for laptops - will that work?
TIA. Bubba73 You talkin' to me? 17:17, 14 July 2013 (UTC)
- 1. If you only care about read times, probably yes.
- 2. If a drive contains RAM and a non-volatile store, the RAM is a cache. RAM doesn't get cheaper because it's in a hard disk - if you can't afford to buy system RAM big enough to hold these files, you can't afford to buy a drive with that same RAM in it either.
- 3. If you really care about performance, a PCI-express SSD, which cuts out the translation to a bus like USB or SATA, is what you want. But those are darn expensive. Regarding 2.5" SSDs: most consumer SSDs are this size, even those that go into desktops (because flash is so dense, and there's no need for motors and arms and stuff, that form factor is plenty big enough). -- Finlay McWalterჷTalk 17:35, 14 July 2013 (UTC)
- Thank you, #1 - yes, direct access read time is the crucial factor. #2 - the computer is already maxed out at 16GB, which isn't enough for the files. #3 - I'll look for PCI ones. Bubba73 You talkin' to me? 17:54, 14 July 2013 (UTC)
- I've been looking at the PCIe SSDs - I didn't know about those until you told me. It looks like a 120GB one of those is the way to go for my needs. Thank you! Bubba73 You talkin' to me? 20:05, 14 July 2013 (UTC)
- Make sure the one you choose has a driver for your version of Windows; some only have drivers for Windows Server. -- Finlay McWalterჷTalk 21:19, 14 July 2013 (UTC)
- I'm looking at some by OCZ, and someone said that it didn't work with their Linux system but it did with W8, which is what I have.
- There are some very fast ones out there, but they are very expensive. Bubba73 You talkin' to me? 01:48, 15 July 2013 (UTC)
IOPS and RAM
IOPS has some good example data for hard drives and SSDs. Roughly what is a comparible number for RAM? Bubba73 You talkin' to me? 23:56, 14 July 2013 (UTC)
- Memory speeds depend on more factors than most people want to be bothered with; modern DRAM is really really complicated. In the aggregate, you can average the data transfer speed; a table is included as part of our article on CAS latency, section Memory Timing. Surprisingly, the performance of modern RAM technology actually depends on the cadence and timing of data access; and it also depends on what data addresses are accessed; in other words, the "random access" in RAM is not a very apt descriptive term. Just like hard disk drives, RAM data access is faster if you make use of spatial locality. Nimur (talk) 01:11, 15 July 2013 (UTC)
- Spatial locality is a factor because it increases the cache hit rate, not because of any "seek time" inherent in the RAM. Pentium-class machines cache 16 bytes at a time, even if you only read one. Bobmath (talk) 16:05, 15 July 2013 (UTC)
- Of course caches external to the RAM are also improved by spatial locality. But, because of the way that RAM works, spatial locality is a factor in the RAM itself: because column-addressed DRAM returns (e.g.) 8 words nearly as fast as it returns one word. If you don't need the latter seven words, you wasted a column select control signal; you've already spent that time to query those data, and they're available on the data out port. Have a read at control signals for SDRAM. Few people use the term "seek time" to describe RAM, but it is actually a very apt description. Nimur (talk) 18:34, 15 July 2013 (UTC)
- Spatial locality is a factor because it increases the cache hit rate, not because of any "seek time" inherent in the RAM. Pentium-class machines cache 16 bytes at a time, even if you only read one. Bobmath (talk) 16:05, 15 July 2013 (UTC)
- I'm wondering about the time to get 50-100 continuous bytes from memory on a modern Windows desktop, using DDR2 or DDR3, when the information is almost certainly not in the cache. Bubba73 You talkin' to me? 01:41, 16 July 2013 (UTC)
- The answer to that question - in isolation from all other details - is "less than a microsecond" - counting round-trip time to the RAM, plus all the control signal "details." Accessing data in main memory - with something modern like DDR3 SDRAM - requires on the order of tens of nanoseconds per transaction - as fast as cache memory was, just a few years ago! This is why all the ugly details matter: when you are reading only 50 or 100 bytes from memory, your total time is not dominated by the average performance of the RAM, because your statistical sample is so small. If you are only reading 100 bytes, your total execution time is probably dominated by when the operating system chooses to schedule your program. Nimur (talk) 13:42, 16 July 2013 (UTC)
- I'm wondering about the time to get 50-100 continuous bytes from memory on a modern Windows desktop, using DDR2 or DDR3, when the information is almost certainly not in the cache. Bubba73 You talkin' to me? 01:41, 16 July 2013 (UTC)
July 15
facebook names
I recently created one of these 'facebook accounts' but being silly, thought it'd be fun to make up an amusing nickname rather than using my real name. a couple of days later, I regret that, and have avoided using the site since, so I'm wondering, is it possible to change from that to my real name instead, or would I have to close that account and create a new one?
213.104.128.16 (talk) 16:51, 15 July 2013 (UTC)
- Check out this page. Hope this helps! --Yellow1996 (talk) 17:24, 15 July 2013 (UTC)
What's the Apple equivalent to MS Paint ?
StuRat (talk) 20:08, 15 July 2013 (UTC)
- There hasn't been a direct equivalent since MacPaint was discontinued in 1989. WikiPuppies bark dig 20:54, 15 July 2013 (UTC)
- Anything close then ? StuRat (talk) 21:06, 15 July 2013 (UTC)
WinRAR safe from PRISM?
Dear Wikipedians:
Are WinRAR encrypted archives safe from PRISM?
Thanks,
76.75.148.30 (talk) 20:59, 15 July 2013 (UTC)
- And also TrueCrypt?--128.237.207.243 (talk) 21:29, 15 July 2013 (UTC)
- Maybe. Firstly the ciphers they use, such as AES are strong; used properly, it's impractical for anyone in the public cryptography community to break them. But NSA/GCHQ have an impressive number of mathematicians working on this kind of thing, and vast compute infrastructure - in the past they've been years ahead of public (that is, academic and commercial) cryptographic researchers. We don't know whether they've got a tractable means of breaking ciphers like AES; you can bet your life they're trying hard to acquire one. Secondly is the whole cryptosystem - how the ciphers are used, the keys managed, entropy generated, and so on. That's often more involved, less standard, and with a bigger attack surface; add the fact that these systems then need to be reduced to practice (actually written as software code running on a real system) means there's lots more opportunities for things to be invisibly defective. As Stuxnet shows us, governments actively research security vulnerabilities which aren't public knowledge (and keep them secret until they have need of them); it's optimistic to imagine that WinRAR and TrueCrypt don't have such vulnerabilities. Whether they're enough for a breach, again who knows. Surely any kind of encryption will go some way to frustrate the mass trawl for data that PRISM is claimed to do; but detecting encrypted data is easy, so it's not unreasonable to imagine using cryptography might lead PRISM to pay special attention. Lastly, particularly for anyone being specifically targeted, breaking the cryptography is far from the most obvious thing a security service would do - there's any number of ways to avoid needing to (virus on your machine, tap your keyboard, revolver-to-the-forehead). -- Finlay McWalterჷTalk 22:11, 15 July 2013 (UTC)
- PRISM only captures data sent over the Internet, so a RAR archive or TrueCrypt volume would only be visible if you sent it as an email attachment, for example.
- The current versions of RAR encryption and the TrueCrypt format have no known cryptographic weaknesses. It's impossible to prove that the NSA doesn't have a secret attack, but most academic cryptographers think it's unlikely, and if they do have one it would be an extremely valuable and closely guarded secret and they wouldn't risk exposure by using it against people like you. All major governments are certainly sitting on large collections of publicly unknown software vulnerabilities, perhaps even including vulnerabilities in the WinRAR or TrueCrypt software, but a practical attack on the file formats is another matter—that would very likely extend to other similar cryptosystems, including those used by banks and such to protect information that really needs protection. -- BenRG (talk) 00:29, 16 July 2013 (UTC)
- Attacks on RNG systems are apparently the most fun, and as the debian openssl fiasco proved, these vulnerabilities can go on unnoticed for quite a while. Who knows if the NSA has some hack for AES; it seems almost unnecessary. Shadowjams (talk) 06:26, 16 July 2013 (UTC)
- You're right, an RNG-related attack is plausible. I actually looked at TrueCrypt's entropy generation and it seemed okay, but I could miss a bug like the Debian OpenSSL one that would make the whole thing moot. WinRAR is closed source and I have no idea what it's doing (but there's no particular reason not to trust it). -- BenRG (talk) 16:07, 16 July 2013 (UTC)
- Attacks on RNG systems are apparently the most fun, and as the debian openssl fiasco proved, these vulnerabilities can go on unnoticed for quite a while. Who knows if the NSA has some hack for AES; it seems almost unnecessary. Shadowjams (talk) 06:26, 16 July 2013 (UTC)
How can I google the earliest something?
For example, I want to know where on internet did some text first appear. I see there are some option to filter results by time like the past day/hour/week, but are there an option of findind earliest instances? --128.237.207.243 (talk) 21:27, 15 July 2013 (UTC)
I don't think you can do this with google's regular web search web searches but you can with books and news searches (and you can assume that the earliest in print of most things will be from books or newspapers anyway). Both are available from the "advanced" search options of each of them, at the bottom of the page. For books you just choose a date range, so you can put in 1700 to 1850, and then narrow if that brings up too many. For example, [3 results for "flintlock" from 1700 to 1750 http://www.google.com/search?tbo=p&tbm=bks&q=flintlock&tbs=,cdr:1,cd_min:Jan+1_2+1700,cd_max:Dec+31_2+1750&num=10]. For google news you have to choose the "archive" from advanced and then can do the same thing.I missed the part about the search being about the first to appear on the Internet.--108.46.106.40 (talk) 01:42, 16 July 2013 (UTC)- [ec] search tool are you using? Presuming you are using Google, when you set the filter for a specific time range, it theoretically gives you the results that were published within that range. However, it depends on what you are looking for. Google hasn't always existed (well less than have the lifespan of the internet and maybe about have of the life of the web), so the earliest instances of whatever you are looking for might not be in their archives. Mingmingla (talk) 01:44, 16 July 2013 (UTC)
- That filter only goes back one year, though; and I bet the OP is looking for entries older than that... I don't think this is possible. --Yellow1996 (talk) 16:10, 16 July 2013 (UTC)
- If you have narrowed it down to a few pages you suspect may be the original you can check them on the Wayback Machine: [6]. It will let you see how a site has changed over time, so you can see when the text was added. 209.131.76.183 (talk) 17:12, 16 July 2013 (UTC)
July 16
Recommendation for a fast disk burner?
My external burner just went kaput. I now want to get a new one, but wanted to know if anyone can recommend one that will be faster. Willing to spend extra for the speed. The one that just died was an LG Portable Super Multi Drive, model GP10NB20 and I bought it randomly off the Internet (not complaining; it was a workhorse, I used it a ton, and it was very cheap). But I want something really fast. Must work with a mac, which is what I have. Any ideas?--108.46.106.40 (talk) 01:29, 16 July 2013 (UTC)
- The GP10NB20 appears to be a DVD writer and DVD writer speed is basically irrelevant nowadays for internal burners. I suspect it's the same for external ones. I would worry more about writing quality and media compatibility (of course if you always use specific media like MCC004 or something, only compatibility with that media matters) than anything else although the relative unpopularity amongst experienced users and extreme commodity nature of burners nowadays means from what I say last time I looked, actual data on these is far harder to come by nowadays. Nil Einne (talk) 02:42, 16 July 2013 (UTC)
Regular expression to convert C code braces to indentation
Is is possible to convert C code braces to indentation using regular expressions? Czech is Cyrillized (talk) 03:17, 16 July 2013 (UTC)
- Yes, depending on the nesting, it could be quite simple. If you could define the C code brace standard you're talking about that'd be a start. Most C code has a rough formality to it, but not to the point where you oculd assume there's some universal method. Shadowjams (talk) 06:23, 16 July 2013 (UTC)
- I presume you are looking to pretty up C code by fixing the indentation. Many integrated development environments you might use to develop your code, includes tools to tidy up the code indentation. If this is the purpose, it could be considerably easier then trying to write your own code tidy-er. Astronaut (talk) 11:30, 16 July 2013 (UTC)
How to hide watched YouTube videos from search results?
Hi, every few days I'm searching for videos on a certain topic (squash games if you're interested...). Most of the times I'd like to watch videos I haven't watched before, however YouTube displays the same videos over and over again for the search.
Is there any browser extension or another method that gives an option to hide the already watched videos (e.g. the ones in my history list)? Gil_mo (talk) 04:10, 16 July 2013 (UTC)
- This Google Chrome extension apparently does this. Good luck! --Yellow1996 (talk) 16:14, 16 July 2013 (UTC)
Live exchange rates into a spreadsheet
Is there any way to get the Google exchange rates or other reliable exchange rates into a spreadsheet so that it will update daily online? Without slowing the computer down, encountering malware, or other disadvantages? Thanks. Itsmejudith (talk) 12:01, 16 July 2013 (UTC)
Need a freeware spreadsheet
I urgently need to enter some data in a simple spreadsheet, but the Excel spreadsheet on the notebook I have to use in the field is "locked up" because they lost the "product key" so it was never verified as being on the computer when it came out of the box. So basically I need a spreadsheet program on which I can enter several hundred rows of data with perhaps six columns, the data consisting of numbers and text in different columns, and then sort based on some of the data fields. I need to be able to export the data to a thumbdrive in some simple format like comma delimited ASCII and then I would like to be able to import it to legit Excel programs on other computers. I do not need any whistles and bell like formulas, graphs, charts, or fancy fonts and other razzle-dazzle formatting. The first Google Search result for freeware spreadsheet is "Kingsoft Spreadsheets Free 2012 (8.1.0.3030)" Are they a trustworthy software provider, or has someone found a better freeware spreadsheet? (I don't want to download a trojan horse or virus, or glitchy software which loses my input efforts.). Thanks. Edison (talk) 15:15, 16 July 2013 (UTC)
- LibreOffice-Calc or its close relative OpenOffice-Calc are free and open source; they're fairly heavyweight (they're pretty much on par with Excel). Or you can use Google Docs online, assuming the field in question has internet access. -- Finlay McWalterჷTalk 15:44, 16 July 2013 (UTC)
- Thanks for the recommendation. LibreOffice-Calc was easy to download and more than satisfies my needs. Mark this one "Resolved." Edison (talk) 16:48, 16 July 2013 (UTC)
Allow me! :) --Yellow1996 (talk) 16:58, 16 July 2013 (UTC)