
Wikipedia:Bots/Requests for approval: Difference between revisions
{{BRFA|TedderBot|3|Open}} |
{{BRFA|DASHBot|8|Open -> Trial}} & {{BRFA|WildBot|3|Open -> Trial}} for Harej |
||
| (One intermediate revision by the same user not shown) | |||
| Line 4: | Line 4: | ||
<!-- Add NEW entries at the TOP of this section, on a new line directly below this message. --> |
<!-- Add NEW entries at the TOP of this section, on a new line directly below this message. --> |
||
{{BRFA|RjwilmsiBot|2|Open}} |
{{BRFA|RjwilmsiBot|2|Open}} |
||
| ⚫ | |||
{{BRFA|Redirectcreation Bot||Open}} |
{{BRFA|Redirectcreation Bot||Open}} |
||
{{BRFA|TedderBot|2|Open}} |
{{BRFA|TedderBot|2|Open}} |
||
| Line 17: | Line 16: | ||
{{BRFA|WildBot|4|Open}} |
{{BRFA|WildBot|4|Open}} |
||
{{BRFA|BotMultichill|5|Open}} |
{{BRFA|BotMultichill|5|Open}} |
||
| ⚫ | |||
{{BRFA|WildBot|3|Open}} |
|||
{{BRFA|Yobot|11|Open}} |
{{BRFA|Yobot|11|Open}} |
||
{{BRFA|SoxBot|20|Open}} |
{{BRFA|SoxBot|20|Open}} |
||
| Line 25: | Line 22: | ||
=Bots in a trial period= |
=Bots in a trial period= |
||
<!-- Add NEW trials here at the TOP of this section right BELOW this comment. --><!--Stop messing with BAGBot's comments!!! --ST --><!--NT--> |
<!-- Add NEW trials here at the TOP of this section right BELOW this comment. --><!--Stop messing with BAGBot's comments!!! --ST --><!--NT--> |
||
| ⚫ | |||
| ⚫ | |||
{{BRFA|Addbot|22|Trial}} |
{{BRFA|Addbot|22|Trial}} |
||
<!-- Add NEW entries at the TOP of this section. The other top. --> |
<!-- Add NEW entries at the TOP of this section. The other top. --> |
||
| Line 37: | Line 36: | ||
=Denied requests= |
=Denied requests= |
||
Bots that have been denied for operations will be listed here for informational purposes for at least 7 days before being archived. No other action is required for these bots. Older requests can be found in the [[:Category:Denied Wikipedia bot requests for approval|Archive]].<!--ND--> |
Bots that have been denied for operations will be listed here for informational purposes for at least 7 days before being archived. No other action is required for these bots. Older requests can be found in the [[:Category:Denied Wikipedia bot requests for approval|Archive]].<!--ND--> |
||
{{BRFA|GeneGoBot||Denied|08:20, 23 January 2010 (UTC)}} |
|||
{{BRFA|Template Maintenance Bot||Denied|22:29, 28 December 2009 (UTC)}} |
{{BRFA|Template Maintenance Bot||Denied|22:29, 28 December 2009 (UTC)}} |
||
{{BRFA|IronBot||Denied|02:18, 19 December 2009 (UTC)}} |
{{BRFA|IronBot||Denied|02:18, 19 December 2009 (UTC)}} |
||
Revision as of 08:24, 23 January 2010
| All editors are encouraged to participate in the requests below – your comments are appreciated more than you may think! |
New to bots on Wikipedia? Read these primers!
- Approval process – How these discussions work
- Overview/Policy – What bots are/What they can (or can't) do
- Dictionary – Explains bot-related jargon
To run a bot on the English Wikipedia, you must first get it approved. Follow the instructions below to add a request. If you are not familiar with programming consider asking someone else to run a bot for you.
| Instructions for bot operators | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||
| Bot-related archives (v·t·e) |
|---|
| Bot Name | Status | Created | Last editor | Date/Time | Last BAG editor | Date/Time |
|---|---|---|---|---|---|---|
| IznoBot 4 (T|C|B|F) | Open | 2024-07-13, 15:47:52 | Izno | 2024-07-13, 15:48:19 | Never edited by BAG | n/a |
| Platybot (T|C|B|F) | Open | 2024-07-08, 08:52:05 | BilledMammal | 2024-07-08, 11:47:35 | Never edited by BAG | n/a |
| BattyBot 81 (T|C|B|F) | On hold | 2024-02-07, 14:12:49 | ProcrastinatingReader | 2024-02-15, 12:09:35 | ProcrastinatingReader | 2024-02-15, 12:09:35 |
| C1MM-bot 2 (T|C|B|F) | In trial | 2024-06-25, 00:56:44 | Primefac | 2024-07-05, 17:53:58 | Primefac | 2024-07-05, 17:53:58 |
| BaranBOT 3 (T|C|B|F) | In trial | 2024-06-19, 05:08:35 | Primefac | 2024-07-10, 15:32:21 | Primefac | 2024-07-10, 15:32:21 |
| DannyS712 bot III 74 (T|C|B|F) | In trial | 2024-05-09, 00:02:12 | TheSandDoctor | 2024-07-13, 22:20:18 | TheSandDoctor | 2024-07-13, 22:20:18 |
| StradBot 2 (T|C|B|F) | In trial | 2024-02-17, 03:20:39 | SD0001 | 2024-02-17, 05:58:51 | SD0001 | 2024-02-17, 05:58:51 |
| CapsuleBot 2 (T|C|B|F) | Extended trial | 2023-06-14, 00:14:29 | Capsulecap | 2024-01-20, 02:36:30 | Primefac | 2024-01-15, 07:40:39 |
| AussieBot 1 (T|C|B|F) | Extended trial: User response needed! | 2023-03-22, 01:57:36 | Hawkeye7 | 2024-02-18, 23:33:13 | Primefac | 2024-02-18, 20:10:45 |
| DoggoBot 10 (T|C|B|F) | In trial | 2023-03-02, 02:55:00 | Frostly | 2024-02-21, 22:41:18 | Primefac | 2024-01-15, 07:40:49 |
| Mdann52 bot 14 (T|C|B|F) | Trial complete | 2024-06-10, 17:46:58 | Mdann52 | 2024-07-06, 08:56:38 | Primefac | 2024-07-05, 17:57:38 |
| BaranBOT 2 (T|C|B|F) | Trial complete | 2024-05-27, 14:01:46 | DreamRimmer | 2024-07-06, 14:03:24 | Primefac | 2024-06-27, 15:25:33 |
| PrimeBOT 39 (T|C|B|F) | On hold | 2023-05-11, 12:48:50 | Primefac | 2023-09-22, 10:51:59 | Headbomb | 2023-07-02, 17:38:58 |
Current requests for approval
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was
 Approved.
Approved.
Operator: Rjwilmsi
Automatic or Manually assisted: Automatic
Programming language(s): AWB
Source code available: AWB
Function overview: Tag redirect pages with WP:TMR tags
Links to relevant discussions (where appropriate): WP:TMR
Edit period(s): probably single run on release of new database dump
Estimated number of pages affected: Thousands. Exact number not yet clear.
Exclusion compliant (Y/N): Y
Already has a bot flag (Y/N): Y
Function details: Use a new general fix function in AWB being developed by me to tag redirect pages with one or more of the tags specified on WP:TMR. If possible I would like to keep the scope of authorisation open-ended to allow future expansion of the task without the need to bother the BAG for a small change. As it stands the current tagging criteria will be:
- where the redirect page title and the redirect target differ only by punctuation, tag with {{R from modification}} (e.g. diff) if not already tagged with that template.
- where the redirect page title equals the redirect target with diacritics replaced with the equivalent Latin character, tag with {{R from title without diacritics}} (no example as yet) if not already tagged with that template.
- Other similar tagging per WP:TMR. Clearly only some of the tags can be decided by a bot.
Scope: mainspace en-wiki only. Redirect pages only.
Note on number of pages: I'm not currently clear on what database dump includes the title and text of redirects, so don't yet know volumes.
Discussion
If I could request that redirects to disambiguation pages that aren't already tagged get tagged with {{R from unknown disambiguation}} that will give WP:Disambiguation something to work with - a generated list that can then be sorted into the various redirect classes for disambiguation pages. Josh Parris 10:29, 21 January 2010 (UTC)
![]() Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. MBisanz talk 16:46, 27 January 2010 (UTC)
Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. MBisanz talk 16:46, 27 January 2010 (UTC)
 Trial complete.. No problems. Rjwilmsi 08:19, 28 January 2010 (UTC)
Trial complete.. No problems. Rjwilmsi 08:19, 28 January 2010 (UTC)
 Approved. Nice work. Tim1357 (talk) 03:58, 30 January 2010 (UTC)
Approved. Nice work. Tim1357 (talk) 03:58, 30 January 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was
 Withdrawn by operator.
Withdrawn by operator.
Operator: Smallman12q
Automatic or Manually assisted: Automatic
Programming language(s): VB.Net using the DotNetWikiBot Framework
Source code available: Available on request.
Function overview: To create redirect pages towards a target page.
Links to relevant discussions (where appropriate):
Edit period(s): Daily/weekly
Estimated number of pages affected: Few hundred per week
Exclusion compliant (Y/N): N/A
Already has a bot flag (Y/N): N
Function details: The purpose of the bot will be to create redirect pages based on a given list. It can also redirect to sections. It is not compliant in that it will only create a redirect on a blank page, therefore, there is no need to check for bot templates.
For example, the bot could create a set of redirects to United States incarceration rate from a list such as
U.S. incarceration rate
American incarceration rate
Rate of incarceration in America
Rate of incarceration in the United States
Incarceration rate in the United States
The idea is to increase the number of redirects so more people can find what they are looking for.
- Addition 1
The bot could also check the page view statistics for a page for a minimum number prior to creating a redirect. It also could check the page view statistics for a redirect after a page has been created to see if the redirect is worth keeping.
Discussion
Any thoughts on this? Anyone beside me see a need for this?Smallman12q (talk) 19:01, 8 January 2010 (UTC)
- I don't really think this is a great idea. It has the potential to create an infinite number of redirects and some of them might be very low value. The javascript predictive title search and search engine should typically be enough to get readers where they need to be. –xenotalk 19:07, 8 January 2010 (UTC)
- I'm sure that there could be some that are of value. The idea is to make it much easier to create redirects.Smallman12q (talk) 19:35, 8 January 2010 (UTC)
- (e/c)I don't think this is necessary. We have a search engine for a reason. To use your example, when searching for all of the potential redirect titles, United States incarceration rate always comes up in the first page of results ("U.S. incarceration rate" is the only one that doesn't return it in the top 4 results). Mr.Z-man 19:16, 8 January 2010 (UTC)
- Same with mr. z man. However, there is a need for bots to create redirects for US states, and with variations on capitilizations. There are scripts in pywikipedia that do this. Tim1357 (talk) 21:55, 8 January 2010 (UTC)
- Different capitalization should be handled automatically by the search engine. Most US states are only 1-word, what redirects do they need? Mr.Z-man 15:50, 10 January 2010 (UTC)
- I suggest you float your proposal at Wikipedia talk:Redirects for discussion, the folk there have a good understand of what constitutes a good redirect. Josh Parris 23:23, 8 January 2010 (UTC)
- I cleaned up over 3000 redirects created by a bot. I don't know how many wound up usable, probably less than 10%. It's not a good idea, imo. Redirects require thought, not bots. However, standard variations in capitalization from use laziness, if that's a problem for wikipedia, that might be useful. --IP69.226.103.13 | Talk about me. 05:10, 9 January 2010 (UTC)
- I'm hesitant to approve only because I'm unsure how the bot will heuristically decide a redirect is needed and what form it should take. MBisanz talk 05:48, 10 January 2010 (UTC)
- A list of article names that should be redirected are provided. The bot then goes through and creates the articles as redirects.Smallman12q (talk) 17:30, 10 January 2010 (UTC)
- Does this mean the idea is: a user requests that a list of redirects be created and the bot creates only those listed redirects? This is something different, a user tool, and that would be okay, if the bot only created redirects specified by another user. This could be useful. --IP69.226.103.13 | Talk about me. 22:55, 10 January 2010 (UTC)
- I'm still not too sure. If its too easy to create redirects, users might just feed it huge lists of unnecessary redirects, so the end result wouldn't be much better than the original idea. If this is done, the bot should run a search via the API and verify that the requested title doesn't come up in the first 20 results. Mr.Z-man 23:41, 10 January 2010 (UTC)
- Well I've added a few more features to it. I believe it'll serve more as a tool for certain tasks...see below.
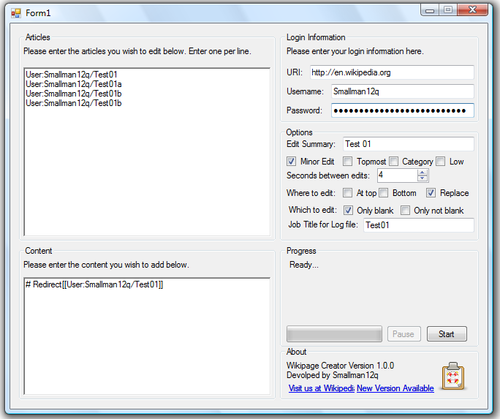
- Any thoughts as to whether this would be a useful tool?Smallman12q (talk) 14:22, 11 January 2010 (UTC)
- Before I release this tool...anybody have any thoughts?Smallman12q (talk) 14:33, 15 January 2010 (UTC)
- I withdraw my request as it will be developed as an automated tool.Smallman12q (talk) 23:59, 24 January 2010 (UTC)
- Before I release this tool...anybody have any thoughts?Smallman12q (talk) 14:33, 15 January 2010 (UTC)
- Well I've added a few more features to it. I believe it'll serve more as a tool for certain tasks...see below.
- I'm still not too sure. If its too easy to create redirects, users might just feed it huge lists of unnecessary redirects, so the end result wouldn't be much better than the original idea. If this is done, the bot should run a search via the API and verify that the requested title doesn't come up in the first 20 results. Mr.Z-man 23:41, 10 January 2010 (UTC)
- Does this mean the idea is: a user requests that a list of redirects be created and the bot creates only those listed redirects? This is something different, a user tool, and that would be okay, if the bot only created redirects specified by another user. This could be useful. --IP69.226.103.13 | Talk about me. 22:55, 10 January 2010 (UTC)

 Withdrawn by operator. Withdrawn by operator Q T C 02:32, 25 January 2010 (UTC)
Withdrawn by operator. Withdrawn by operator Q T C 02:32, 25 January 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Tedder
Automatic or Manually assisted: Automatic, supervised
Programming language(s): perl
Source code available: yes, github, password is outside of repository
Function overview: Rename transclusions of FOO to BAR. Specific request: Wikipedia:Bot requests#Change of template name.
Links to relevant discussions (where appropriate):
Trivial task, so the only consensus necessary should be a given BOTREQ: Wikipedia:Bot requests#Change of template name.
Edit period(s): One-time Manually run.
Estimated number of pages affected: 58 Unknown, depends on request. Trials and delays between edits are possible.
Exclusion compliant (Y/N): Yes.
Already has a bot flag (Y/N): No.
Function details: Simple regex substitution: s/{{Space telescopes/{{Space observatories/g using "embeddedin" and "backlinks" on namespace 0 to find list. Logs to User:TedderBot/TranscludeReplace/log.
Keep in mind I'm asking for approval of any sort of transclusion type change, not just this specific one. It's still an incredibly limited scope. since this is my first (successful?) botreq.
Discussion
- Can't 58 pages be simply edited with AWB? –Juliancolton | Talk 15:07, 4 January 2010 (UTC)
- Yes, definitely. And now the root problem has been taken care of. It'd be nice, however, to have this approved for use in the general case. tedder (talk) 15:45, 4 January 2010 (UTC)
- You're asking for approval for a bot that changes the used name of templates generally? Who decides which templates? Is the original problem fixed? Josh Parris 01:48, 5 January 2010 (UTC)
- Yes, definitely. And now the root problem has been taken care of. It'd be nice, however, to have this approved for use in the general case. tedder (talk) 15:45, 4 January 2010 (UTC)
Hi. So the original problem is moot, but the idea is to have a bot that can run, on demand and with consensus of the given template community, to update template names. tedder (talk) 06:18, 5 January 2010 (UTC)
- Is the template community WP:TfD? Or Wikipedia:Redirects for discussion, or Wikipedia:Requested moves? Josh Parris 06:37, 5 January 2010 (UTC)
- Sorry, I meant the relevant wikiproject, the template talk, or whoever is discussing the template. For instance, {{WikiProject Oregon}} is at WP:WPORE. tedder (talk) 06:44, 5 January 2010 (UTC)
- How will these communities know that this bot is able to serve them? Josh Parris 06:48, 5 January 2010 (UTC)
- Sorry, I meant the relevant wikiproject, the template talk, or whoever is discussing the template. For instance, {{WikiProject Oregon}} is at WP:WPORE. tedder (talk) 06:44, 5 January 2010 (UTC)
- As was noted on the bot request, unless the old name needs to be repurposed for something else, or other rare reasons, we don't need to fix redirects that aren't broken. Mr.Z-man 17:10, 5 January 2010 (UTC)
Trying to understand the request: so this is the sort of bot that you want to have so that you can complete possible, future request-type-things? Even if it doesn't actually get its tasks from that particular page. Ale_Jrbtalk 18:33, 6 January 2010 (UTC)
- That's correct, Ale. It's not like I'd go through an unilaterally/arbitrarily change templates. I can see a group wanting to unify templates from {{PROJECTNAME}} to {{WikiProject PROJECTNAME}}, for instance. However, if it's not desired because the preference of a project is overruled by "don't fix what isn't broken", then this should be withdrawn. tedder (talk) 18:37, 6 January 2010 (UTC)
- I'm not sure if this is problematic dealing with wikiprojects, if the project can show a clear-cut consensus for a change. But I think the bigger projects might not show this readily, and the smaller projects may get no input. Is there a place where this can be discussed in general, like the community pumps, or someplace more specific, asking projects whether a dedicated bot for project templates would serve a purpose? I don't think it's far-fetched to assign a bot to doing tasks as they come up by community agreement. --IP69.226.103.13 | Talk about me. 05:30, 9 January 2010 (UTC)
- I offered my help at WT:TFD. Im not sure that applies to this. Tim1357 (talk) 19:45, 10 January 2010 (UTC)
- I'm not sure if this is problematic dealing with wikiprojects, if the project can show a clear-cut consensus for a change. But I think the bigger projects might not show this readily, and the smaller projects may get no input. Is there a place where this can be discussed in general, like the community pumps, or someplace more specific, asking projects whether a dedicated bot for project templates would serve a purpose? I don't think it's far-fetched to assign a bot to doing tasks as they come up by community agreement. --IP69.226.103.13 | Talk about me. 05:30, 9 January 2010 (UTC)
- Is anybody still interested with this? –Juliancolton | Talk 22:32, 9 February 2010 (UTC)
IMO, this bot has to be rejected, someone do the changes manually and Tedder can request other tasks for its bot. -- Magioladitis (talk) 22:40, 11 February 2010 (UTC)
- Why does it "has to be rejected"(sic)? tedder (talk) 22:51, 11 February 2010 (UTC)
- I don't see the need for a general "template replacement bot". AWB can be used to do "{{foo}}" → "{{bar}}" replacements (assuming there is reason for it), so why would we need a bot to handle these? The operator is not requesting approval for more complex replacements (e.g., "{{foo|bar}}" → "{{baz|bur}}", that would actually require a bot and specific code; they are requesting approval for a general-purpose, simple replacement bot. Other than slightly less work (esp. if there are a lot of pages involved), I don't see a reason for it: AWB would probably get the job done faster, because there are hundreds upon hundreds of users with access to it, and any one of them could complete the task, but in order for the task to be done with this bot, you would need to be notified. Unless, of course, I misunderstand the task? — The Earwig @ 23:32, 11 February 2010 (UTC)
- I replaced all Space telescopes -> Space observatories using AWB. -- Magioladitis (talk) 17:34, 13 February 2010 (UTC)
- I don't see the need for a general "template replacement bot". AWB can be used to do "{{foo}}" → "{{bar}}" replacements (assuming there is reason for it), so why would we need a bot to handle these? The operator is not requesting approval for more complex replacements (e.g., "{{foo|bar}}" → "{{baz|bur}}", that would actually require a bot and specific code; they are requesting approval for a general-purpose, simple replacement bot. Other than slightly less work (esp. if there are a lot of pages involved), I don't see a reason for it: AWB would probably get the job done faster, because there are hundreds upon hundreds of users with access to it, and any one of them could complete the task, but in order for the task to be done with this bot, you would need to be notified. Unless, of course, I misunderstand the task? — The Earwig @ 23:32, 11 February 2010 (UTC)
![]() Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. Please address Wikipedia:Bot requests/Archive 34#Update Template Transclusions a 7000 transclusion request. Your source code doesn't seem particularly generalized. Do you intend to change to be more flexible? Josh Parris 08:00, 26 February 2010 (UTC)
Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. Please address Wikipedia:Bot requests/Archive 34#Update Template Transclusions a 7000 transclusion request. Your source code doesn't seem particularly generalized. Do you intend to change to be more flexible? Josh Parris 08:00, 26 February 2010 (UTC)
- Why the request says only one-time run and 58 pages affected? I thought it wanted to change only the pages I fixed. If this bot is gonna do more stuff, we have to change the request above. -- Magioladitis (talk) 08:54, 26 February 2010 (UTC)
- This is a good point. Tedder, please update the request to reflect your current proposal. Josh Parris 09:38, 26 February 2010 (UTC)
 Doing... Making some changes, will modify before running, and will run against one fix before doing 50. tedder (talk) 19:17, 26 February 2010 (UTC)
Doing... Making some changes, will modify before running, and will run against one fix before doing 50. tedder (talk) 19:17, 26 February 2010 (UTC)
- Okay, I genericized the script, added a page documenting the request, and then ran against (almost) 50 requests. Here's the log: User:TedderBot/TranscludeReplace/log. tedder (talk) 20:30, 26 February 2010 (UTC)
- Can you do minor changes at the same time? More specifically in talk pages if a change is made change: talkheader"" to "talk header", "skiptotalk" to "skip to talk", "WPBS" to "WikiProjectBannerShell". This will help my project in making talk pages for readable.
- If you run it manually I 100% agree that you do it but I think some substitutions can be done automatically. Moreover, no need to log every edit. Just record date, which substitution you did and how many articles were affected. -- Magioladitis (talk) 03:05, 27 February 2010 (UTC)
- Okay, I genericized the script, added a page documenting the request, and then ran against (almost) 50 requests. Here's the log: User:TedderBot/TranscludeReplace/log. tedder (talk) 20:30, 26 February 2010 (UTC)
- This is a good point. Tedder, please update the request to reflect your current proposal. Josh Parris 09:38, 26 February 2010 (UTC)
- The script isn't really built to do AWB-style changes. I'm nervous that adding in those changes isn't going to get consensus- but if it does, it'd be a PERFECT use of this script- run it manually or automatically and keep fixing them up as WPBS keeps getting used, for instance. tedder (talk) 04:57, 27 February 2010 (UTC)
- I suggest that these changes can be done ONLY if the major substitution is done. My bot (Yobot) has already a similar approval and they are no complains. -- Magioladitis (talk) 10:09, 27 February 2010 (UTC)
- The script isn't really built to do AWB-style changes. I'm nervous that adding in those changes isn't going to get consensus- but if it does, it'd be a PERFECT use of this script- run it manually or automatically and keep fixing them up as WPBS keeps getting used, for instance. tedder (talk) 04:57, 27 February 2010 (UTC)
- The behaviour of your bot is as described in your BRFA. Do you intend to accommodate Magioladitis' request, or press on as the BRFA is currently framed? Josh Parris 12:07, 27 February 2010 (UTC)
- I don't intend to add in the additional behavior- trying to keep the bot with a narrow scope. tedder (talk) 14:23, 27 February 2010 (UTC)
![]() Approved. having reviewed the trial edits and the sources, and given Tedder's desire to keep it simple, this bot task seems useful and harmless. Josh Parris 06:23, 28 February 2010 (UTC)
Approved. having reviewed the trial edits and the sources, and given Tedder's desire to keep it simple, this bot task seems useful and harmless. Josh Parris 06:23, 28 February 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Basilicofresco
Automatic or Manually assisted: Auto (where not stated differently)
Programming language(s): python (pywikipedia)
Source code available: standard pywikipedia
Function overview: remove useless piping within wikilinks links syntax
Links to relevant discussions (where appropriate): Wikipedia talk:Piped link#Changing existing links to piped links with capital first letter?
Edit period(s): every few months (or less) using the xml dump file
Estimated number of pages affected: 20k (rough guess)
Exclusion compliant (Y/N): Y
Already has a bot flag (Y/N): Y
| Discussion regarding original proposal |
|---|
| The following discussion has been closed. Please do not modify it. |
|
Function details: as stated in Wikipedia:Piped link#When not to use we should never use piped links to convert first letter to lower case. This well-tested bot will correct occurences like [[Country code second-level domain|country code second-level domain]]. Already in use on italian Wikipedia. More examples:
DiscussionThree things:
Tim1357 (talk) 15:15, 28 December 2009 (UTC)
TBH, I really don't like the idea of a bot making 16000 edits that will result in no visible change to the rendered page. Its like WP:NOTBROKEN, except with possibly fewer benefits. Mr.Z-man 22:43, 28 December 2009 (UTC)
There is nothing wrong with having another smackbot. However, I think we should ask Rich to give the bot's code to User:Basilicofresco, so we can cram as many general fixes into one edit as possible. Tim1357 (talk) 02:40, 30 December 2009 (UTC)
I like the idea of adding general fixes to other bots. --IP69.226.103.13 (talk) 16:59, 30 December 2009 (UTC)
Well, I can easily add other fixes, for example:
Basilicofresco (msg) 13:50, 3 January 2010 (UTC)
Yes, they are. The above examples are real. Do you prefer to carefully eye-check 3 million of pages and manually edit about 4k pages? (1:820, guess based on random articles sampling) -- Basilicofresco (msg) 08:53, 4 January 2010 (UTC)
FrescoBot 2 bisNever mind, if the majority considers "cosmetic" my proposal about useless pipings, I can remove it. I'm here to help you, not to raise my editcount. So, what about the second group of replacements? -- Basilicofresco (msg) 20:59, 5 January 2010 (UTC)
Fixing also external linksI'm testing on italian wikipedia a new set of regex for syntax errors in external links. It probably would be nice to add them here in order to create a single task. I will add details here as soon as possible. -- Basilicofresco (msg) 09:02, 9 January 2010 (UTC) |
Function details: (new proposal) Using replace.py I will apply several accurate regular expressions in order to correct these errors:
Example: wrong wikisource --> replaced wikisource = error as appears in the article --> replaced text as appears in the article
- External links
- [HTTP://www.google.it link] --> [http://www.google.it link] = link --> link
- [http://http://www.google.it link] --> [http://www.google.it link] = link --> link
- [http:www.google.it link] --> [http://www.google.it link] = [http:www.google.it link] --> link
- [http:/www.google.it link] --> [http://www.google.it link] = [http:/www.google.it link] --> link
- [http:///www.google.it link] --> [http://www.google.it link] = link --> link
- [[http://www.google.it link]] --> [http://www.google.it link] = [link] --> link
- [[http://www.google.it link] --> [http://www.google.it link] = [link --> link
- [http:://www.google.it link] --> [http://www.google.it link] = [http:://www.google.it link] --> link
- [http//www.google.it link] --> [http://www.google.it link] = [http//www.google.it link] --> link
- something[http://www.google.it link] --> something [http://www.google.it link] = somethinglink --> something link
- [http://www.google.it link]something --> [http://www.google.it link] something = linksomething--> link something
- few other very rare variants - (manually assisted)
- [http://images.google.com/imgres?imgurl=http://habitant.org/images/stignatius.jpg&imgrefurl=http://habitant.org/houghton/fcgenealogy.htm&h=287&w=320&sz=29&hl=en&start=33&um=1&tbnid=ibPawlbIEskUcM:&tbnh=106&tbnw=118&prev=/images%3Fq%3DHoughton%2BMI%26start%3D20%26ndsp%3D20%26svnum%3D10%26um%3D1%26hl%3Den%26sa%3DN Flat Broke Blues Band Photo Album] --> [http://www.flatbrokebluesband.com/photos.php Flat Broke Blues Band Photo Album] = Flat Broke Blues Band Photo Album --> Flat Broke Blues Band Photo Album
- [http://images.google.com/imgres?imgurl=http://habitant.org/images/stignatius.jpg&imgrefurl=http://habitant.org/houghton/fcgenealogy.htm&h=287&w=320&sz=29&hl=en&start=33&um=1&tbnid=ibPawlbIEskUcM:&tbnh=106&tbnw=118&prev=/images%3Fq%3DHoughton%2BMI%26start%3D20%26ndsp%3D20%26svnum%3D10%26um%3D1%26hl%3Den%26sa%3DN Google Image Result for http://www.flatbrokebluesband.com/photos.php<!-- Bot generated title -->] --> [http://www.flatbrokebluesband.com/photos.php] = Google Image Result for http://www.flatbrokebluesband.com/photos.php --> [1]
{kind=link}
- Wikilinks
- [[Sonar||sidescan sonar]] --> [[Sonar|sidescan sonar]] = |sidescan sonar --> sidescan sonar
- [['''''sonar''''']] --> '''''[[sonar]]''''' = sonar --> sonar
- [['''sonar''']] --> '''[[sonar]]''' = sonar --> sonar
- [[''sonar'']] --> ''[[sonar]]'' = sonar --> sonar
- [["sonar"]] --> "[[sonar]]" = "sonar" --> "sonar" - I will avoid the few (24) exceptions, eg. "Them")
- [[(sonar)]] --> ([[sonar]]) = (sonar) --> (sonar) - I will avoid the few (28) exceptions, eg. (not adam)
- [['sonar']] --> '[[sonar]]' = 'sonar' --> 'sonar' - I will avoid the few (1) exceptions, eg. 'Hours'
- [[sonar,]] --> [[sonar]], = sonar, --> sonar, - I will avoid the few (1) exceptions, eg. Alors voilà,
- something[[sonar]] --> something [[sonar]] = somethingsonar --> something sonar
- something[[ sonar]] --> something [[sonar]] = somethingsonar --> something sonar
- [[1992-1998]] --> [[1992]]-[[1998]] = 1992-1998 --> 1992-1998 - any type of dash, I will avoid the few (26) exceptions, eg. 1967–1970, I will also avoid any decade eg. 1950-1959 (I just created these redirects to decades in order to capture any red-but-plausible wikilink)
- [[1992-98]] --> [[1992]]-[[1998|98]] = 1992-98 --> 1992-98 - any type of dash, I will avoid the few (2) exceptions, eg. 1806-20, I will avoid potentially ambiguous intervals (cross-century) eg. 1862-34
- [[Nile Delta ]]and --> [[Nile Delta]] and = Nile Delta and --> Nile Delta and - (manually assisted)
- [[sonar.]] --> [[sonar]]. = sonar. --> sonar. - (manually assisted)
- few other very rare variants - (manually assisted)
- Internal links conversion
- [http://en.wikipedia.org/wiki/ECFS_%28cable_system%29 ECFS] --> [[ECFS (cable system)|ECFS]] = ECFS --> ECFS (handles piping and common url encoding)
- [http://en.wikipedia.org/wiki/File:Flag_of_Brunei.svg Flag of Brunei] --> [[:File:Flag of Brunei.svg|Flag of Brunei]] = Flag of Brunei --> Flag of Brunei (properly handles files and categories)
- [http://fr.wikipedia.org/wiki/Ren%C3%A9-Maurice_Gattefoss%C3%A9 René-Maurice Gattefossé] --> [[:fr:René-Maurice Gattefossé|René-Maurice Gattefossé]] = René-Maurice Gattefossé --> René-Maurice Gattefossé (handles links to wikipedia in foreign languages)
- [http://en.wikipedia.org/wiki/Louise_Marie_Ad%C3%A9la%C3%AFde_de_Bourbon-Penthi%C3%A8vre Mme de Genliss] --> [[Louise Marie Adélaïde de Bourbon-Penthièvre|Mme de Genliss]] = Mme de Genliss --> Mme de Genliss (converts a good number of unicode sequences)
- [http://hi.wikipedia.org/wiki/%E0%A4%B5%E0%A4%BF%E0%A4%95%E0%A4%BF%E0%A4%AA%E0%A5%80%E0%A4%A1%E0%A4%BF%E0%A4%AF%E0%A4%BE:%E0%A4%87%E0%A4%82%E0%A4%9F%E0%A4%B0%E0%A4%A8%E0%A5%87%E0%A4%9F_%E0%A4%AA%E0%A4%B0_%E0%A4%B9%E0%A4%BF%E0%A4%A8%E0%A5%8D%E0%A4%A6%E0%A5%80_%E0%A4%95%E0%A5%87_%E0%A4%B8%E0%A4%BE%E0%A4%A7%E0%A4%A8 Tools and Techniques for Hindi Computing] --> [[:hi:%E0%A4%B5%E0%A4%BF%E0%A4%95%E0%A4%BF%E0%A4%AA%E0%A5%80%E0%A4%A1%E0%A4%BF%E0%A4%AF%E0%A4%BE:%E0%A4%87%E0%A4%82%E0%A4%9F%E0%A4%B0%E0%A4%A8%E0%A5%87%E0%A4%9F %E0%A4%AA%E0%A4%B0 %E0%A4%B9%E0%A4%BF%E0%A4%A8%E0%A5%8D%E0%A4%A6%E0%A5%80 %E0%A4%95%E0%A5%87 %E0%A4%B8%E0%A4%BE%E0%A4%A7%E0%A4%A8|Tools and Techniques for Hindi Computing]] = Tools and Techniques for Hindi Computing --> Tools and Techniques for Hindi Computing (does not screw up with exotic not-recognized unicode sequences)
{kind=link}
{kind=link}
Discussion about new proposal
What will you do in the event of people creating articles that you don't currently have in your exceptions? Ale_Jrbtalk 19:41, 16 January 2010 (UTC)
- Excluding years intervals, there are currently only 60 exceptions over 3162000 articles. This means 60/3162000 = 1/52700. The probability of replacing a red wikilink (article missing) with a "incorrect" red wikilink (missing quotes/brakets/etc.) is about 1/52700. Pretty low. Moreover any new article with such a peculiar name will likely came with a redirect from the cleaned name. The risk is negligible and acceptable considering this task for example will fix +3k broken wikilinks. However what I can do is to periodically update the exception list, make my best to avoid any error and promptly correct any problem. -- Basilicofresco (msg) 13:15, 17 January 2010 (UTC)
- Periodic updates to the list sounds like a reasonable work-around. How often do you think you'll update the list of exception cases? Josh Parris 04:31, 19 January 2010 (UTC)
- I plan to run the script every time is available a new dump file and I'm going to check for new exclusions before every run. It is the safest method. -- Basilicofresco (msg) 08:41, 19 January 2010 (UTC)
Perhaps a heuristic you could use is that if the link is a redirect, you can repair; if it's an article, you can't repair. How does this fit with the exceptions you have identified? Josh Parris 12:53, 18 January 2010 (UTC)
- Of course, I created the exclusion list starting from the existing articles with a matched name. -- Basilicofresco (msg) 19:51, 18 January 2010 (UTC)
Meanwhile I also tested the not trivial conversion of "internal links" in wikilinks (take a look above). As you asked after my first proposal I put toghether a good bunch of several tasks. Let me know if there are any other common link problems I can solve of if you would like I reintroduce also the cleaning from useless piping. -- Basilicofresco (msg) 09:35, 21 January 2010 (UTC)
I would like to know which ones are currently fixed by WP:AWB and/or are part of WP:CHECKWIKI i.e. they are fixed in daily basis from many editors -- Magioladitis (talk) 09:28, 24 January 2010 (UTC)
- I don't know. Probably few fixes are included or partially-included, but it is far from being a problem. Can I start with some test edits so we can see if AWB editors are really able to correct any error on every page on daily basis? -- Basilicofresco (msg) 12:05, 24 January 2010 (UTC)
Info: This is what AWB can do atm. -- Magioladitis (talk) 15:23, 9 February 2010 (UTC) ...and some more. Basilicofresco, very good ideas! PS Better poke someone from BAG to get approved. -- Magioladitis (talk) 19:46, 9 February 2010 (UTC)
Update: I'm performing additional tests in order to further improve the above collection. I will soon ping a BAG operator. -- Basilicofresco (msg) 09:41, 12 February 2010 (UTC)
Useless piping
I checked the 2009/11/28 dump and I found out that just about 7% of useless pipings (existing at that date) have been corrected since its creation (2 months and 15 days ago). It means that AWB "daily basis" fixing is simply not enough. Many of you criticized the first proposal (usless piping removal only) because "cosmetic only". Ok, but now there is a whole collection of fixes and adding also a useless piping removal imho seems appropriate and balanced. See also Wikipedia:Piped link#When not to use. Is there any objection? -- Basilicofresco (msg) 16:07, 12 February 2010 (UTC)
- Useless piping (improved)
- [[Sidescan sonar|Sidescan sonar]] --> [[Sidescan sonar]] = Sidescan sonar --> Sidescan sonar
- [[sidescan sonar|Sidescan sonar]] --> [[Sidescan sonar]] = Sidescan sonar --> Sidescan sonar
- [[Sidescan sonar|sidescan sonar]] --> [[sidescan sonar]] = sidescan sonar --> sidescan sonar
- [[Breakfast_of_Champions|Breakfast of Champions]] --> [[Breakfast of Champions]] = Breakfast of Champions --> Breakfast of Champions
- [[Breakfast of Champions|"Breakfast of Champions"]] --> "[[Breakfast of Champions]]" = "Breakfast of Champions" --> "Breakfast of Champions" - also with ( ) and '' ''
- [[Breakfast_of_Champions|"Breakfast of Champions"]] --> "[[Breakfast of Champions]]" = "Breakfast of Champions" --> "Breakfast of Champions" - also with ( ) and '' ''
- other minor variants
Basilicofresco (msg) 16:07, 12 February 2010 (UTC)
- I support these fixes if the number is so big. -- Magioladitis (talk) 16:13, 12 February 2010 (UTC)
- Info: that's what AWB can do v.5.0.1.0 (rev. 6203). -- Magioladitis (talk) 10:51, 13 February 2010 (UTC)
Basilicofresco, where will your list of exceptions be located? Will be updated manually or automatically? Can other editors update it? -- Magioladitis (talk) 10:53, 13 February 2010 (UTC)
- Exceptions were located on my userspace on it.wikipedia, but they are now also present here. I'm going to systematically check for new exclusions among page names on the fresh dump before every run (1 per month or less). Obiouvsly suggestions are always welcome. -- Basilicofresco (msg) 18:47, 13 February 2010 (UTC)
- I think the majority of your fixes are good (i.e., the ones that change the way the page appears or the ones that change the final target of the link), and I would be interested in approving this bot for a trial. However, I'm not so sure if certain fixes you mentioned above are necessary, such as the ones that only change wikicode, and do not affect the final rendered page. A bot making an edit solely for cosmetic purposes, and not to fix links that are actually broken, may be a little wasteful (e.g., Sidescan sonar → Sidescan sonar). I think it would be best to stick with external links/wikilinks/internal link conversions, and avoid fixing useless piping for now. — The Earwig @ 01:43, 18 February 2010 (UTC)
- It's part of CHECKWIKI anyway. Some people solely do that. Why not a bot to save us time and effort? Of course it depends of the amount of edits done per day. We need some estimate but I don't think there were be many anyway. -- Magioladitis (talk) 07:29, 18 February 2010 (UTC)
- Useless piping is considered a middle priority issue by checkwiki project. And, as you can see, they pointed out the problem should be corrected by "AWB, AutoEd, BOT". I checked againg the november dump with a larger sampling (900 old mistakes in the middle of the dump) and the test shows that only about 150 (17%) were corrected during the past 3 months. IMO general fixes of AWB and AutoEd are in need of help. For this reason I asked again for your opinion. Other comments are welcome. -- Basilicofresco (msg) 08:10, 19 February 2010 (UTC)
- Fair enough. Approved for trial (50 edits) Please provide a link to the relevant contributions and/or diffs when the trial is complete., with all fixes enabled. — The Earwig @ 16:11, 19 February 2010 (UTC)
- Fair enough.
- Done. The most common corrections are missing spaces near links, useless piping and wiki/interwikification of "fake" external links. -- Basilicofresco (msg) 18:52, 20 February 2010 (UTC)
- Trial complete. Results look good. Any comments/objections before this task is approved? — The Earwig @ 22:23, 20 February 2010 (UTC)
- Is the code soemwhere published? --Magioladitis (talk) 23:28, 20 February 2010 (UTC)
- No, but if everything will go fine, I will probably publish it in a near future. -- Basilicofresco (msg) 01:26, 21 February 2010 (UTC)
- Is the code soemwhere published? --Magioladitis (talk) 23:28, 20 February 2010 (UTC)
- Ps. I'm going to include also namespace 6 because it's useful and harmless (tested). Is it ok? -- Basilicofresco (msg) 06:52, 22 February 2010 (UTC)
If there are no objections, I'm ready to start. -- Basilicofresco (msg) 15:01, 24 February 2010 (UTC)
![]() Approved. after reviewing the results, which provide a good example of the breadth of functionality to be exercised. Josh Parris 10:21, 25 February 2010 (UTC)
Approved. after reviewing the results, which provide a good example of the breadth of functionality to be exercised. Josh Parris 10:21, 25 February 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Written by Kingpin13, will be run by Sodam Yat ThaddeusB to start off with
Automatic or Manually assisted: Automatic
Programming language(s): C# using DotNetWikiBot
Source code available: No
Function overview: Will take over from User:CSDWarnBot
Links to relevant discussions (where appropriate): recent discussion at WT:CSD / Disscussion which led to CSDWarnBot's block
Edit period(s): Continuous
Estimated number of pages affected: 50+ per day, according to CSDWarnBot's edits
Exclusion compliant (Y/N): Yes
Already has a bot flag (Y/N): N
Function details: The reason CSDWarnBot was stopped is because it wasn't waiting before notifying users, this bot will wait 15 minutes (this time can be very easily changed if wanted). Basically, for each page tagged under CSD, the bot will check if the creator of the page was warned, if not, then the bot will warn the creator.
Discussion
The main problem is what template the bot should use to notify the user. I'll have a look into creating one :). - Kingpin13 (talk) 19:06, 17 November 2009 (UTC)
- Note discussion on talk: Wikipedia talk:Bots/Requests for approval/SDPatrolBot II - Kingpin13 (talk) 08:58, 18 November 2009 (UTC)
- Can the bot also notify the CSDer that they should notify the creator of the article in a timely fashion? Time looks good.
- Why run by Sodam Yot? The user page suggests he has is not willing to discuss issues about deletion:
It's rare that I actually re-visit a discussion that I'm not actively involved in. If I commented on an AFD or marked an article for Speedy Deletion, I'm not actually paying attention to it beyond that point. Should my points be proven wrong, or should evidence that I missed surface, I have no problem with an Admin reading my !vote the other way.
- Deletions are a matter of community consensus that results from discussions. A user who make unilateral decisions and announces an unwillingness or rather lack of concern about the discussion does not strike me as an appropriate bot operator. The second sentence is pointless, admins aren't going to say, "Oh, I read this guy's user page, and he won't mind if I discount his vote." So, essentially the user is commenting on AfDs and marking articles for speedy deletion, but is not amenable to community input once he's voiced his opinion on the article.
- So, he'll operate the bot and ignore what the bot does? IMO this bot should not go forward with this operator. --IP69.226.103.13 (talk) 11:24, 19 November 2009 (UTC)
- Firstly, I don't take that as him saying he doesn't care about it, rather that he doesn't manage to keep track of it. Anyway, I will be running this bot too, it's just I don't have a computer running 24/7, which Sodam Yat does. But I will most likely be the one paying attention to what the bot does, as I'm the one who has written it, and therefore the one who will actually be able to address concerns. - Kingpin13 (talk) 12:31, 19 November 2009 (UTC)
- P.S. Yes the bot can identify the nominator (and already does). I can have it leave them a message too. - Kingpin13 (talk) 12:34, 19 November 2009 (UTC)
- I think this is useful as it will cut down on repeat offenders who don't understand it's a courtesy to prioritize nominating the article's creator. --IP69.226.103.13 (talk) 19:27, 19 November 2009 (UTC)
- That was mainly because I rarely comment in AFD debates, and do not add them to my watchlist. So if I make an argument based on something presented, and that is later proven incorrect, chances are I will not recheck my !vote to make sure it is still the correct choice. If someone wants to bring something to my attention, I will be more than happy to talk about it. While I run the bot, I will make every effort to monitor it while I am available, and will try to check periodically even if I am away, in case something is going wrong. Sodam Yat (talk) 16:35, 19 November 2009 (UTC)
- My concerns are not alleviated. A bot operator has to keep track of what the bot does. I have to say that bot policy does not favor an operator who sees community consensus as his putting in his vote and then ignoring the discussion. Wikipedia is an encyclopedia written by community consensus. It's actually working. Bots require community consensus and operators who are communicating with the community. I am uncomfortable with this bot being operated at any time by this user, as I see high potential for unnecessary drama and incivility due to the operator's stated lack of involvement in developing community consensus for deletion discussions. This is particularly a problem with this bot and this bot operator. User:Sodam Yat has offered, on my user talk page, to attempt to find another operator to work with Kingpin13 on running the bot, and I think he should be taken up on this offer.
- As usual, I have no issues with Kingpin13 as operator or coder. --IP69.226.103.13 (talk) 19:27, 19 November 2009 (UTC)
- In light of the concerns raised, I withdraw my offer to run the bot. If I am able to find someone else to run it, I will do so, but even if I cannot I can't in good conscience run a bot with opposition. Sodam Yat (talk) 19:50, 19 November 2009 (UTC)
- Well, that's a shame IMO. I've contacted ThaddeusB, since he mentioned something about it.. - Kingpin13 (talk) 20:02, 19 November 2009 (UTC)
- If I don't get back to this, just a note that I see no issues with ThaddeusB as a bot operator. --IP69.226.103.13 (talk) 20:07, 19 November 2009 (UTC)
- Well, that's a shame IMO. I've contacted ThaddeusB, since he mentioned something about it.. - Kingpin13 (talk) 20:02, 19 November 2009 (UTC)
- In light of the concerns raised, I withdraw my offer to run the bot. If I am able to find someone else to run it, I will do so, but even if I cannot I can't in good conscience run a bot with opposition. Sodam Yat (talk) 19:50, 19 November 2009 (UTC)
- Kingpin has asked me to run the bot and I would be happy to do so. Reducing BITE on Wikipedia is one of the things I care deeply about, so I will of course respond to any questions/complaints that come in. My C is fairly rudimentary, but I trust that Kingpin will make sure any bugs that may arise get ironed out.
As far as the bot goes, I have two comments:
- I think a 10 minute delay would be sufficient.
- The templated message needed to be carefully crafted. I trust a draft version of it will be released soon.
- --ThaddeusB (talk) 01:16, 20 November 2009 (UTC)
- So basically, the bot will do the following: For certain CSD types, it will wait until at least 10 minutes after the CSD tag was placed on the article and then notify the creator of the article if they have not been notified already. Will it also not bother notifying if the creator has edited the article within that 10 minutes? Will it catch a situation where the creator was notified and deleted the notification? Was the suggestion at Wikipedia talk:Bots/Requests for approval/SDPatrolBot II#Template bombing implemented? If the bot's templates are not to be fully protected, will it verify that they have not been vandalized before substing them? Will the bot have a non-admin shutoff? Does the exclusion compliance include
{{bots|optout=something}}(is there even an appropriate "something"?)? - The bot's userpage also needs to be updated to indicate just which CSD types will be processed and which template(s) will be used, and to indicate the current operator(s); an editnotice pointing out that posting to the bot's talk page to contest a CSD is inappropriate and futile would probably also be helpful. Also, please verify that the account password is only known to the appropriate person or persons (i.e. if Sodam Yat ever knew the password, it must have been changed). Anomie⚔ 03:33, 2 December 2009 (UTC)
- The bot doesn't care if the article has been edited since the CSD tag was placed. But it won't notify if the csd tag has been removed, or the page deleted (it won't be able to read the page anyway). The bot will actually be searching the history for the nominator, so removal of the warning shouldn't matter. The template bombing has not yet been implemented, but it should be pretty easy, I'm just yet to actually write the code. I don't plan on having a non-admin shutoff, but I could if it's wanted. At the moment, only I know the password, once the bot is approved I'll let ThaddeusB know. I'll either have fully protected templates, or keep them in code and off-wiki. ThaddeusB; 10 minutes is good by me. And I will try to get around to the template creation soon :), - Kingpin13 (talk) 14:21, 2 December 2009 (UTC)
- P.S. About the exclusion compliance; at the moment the only parameter in optout which will stop the bot is the bot's name, I could add more if wanted..? - Kingpin13 (talk) 14:30, 2 December 2009 (UTC)
- Sounds good about the templates and the password. The bot's userpage still needs updating, the rest of the questions were really just to throw ideas out there. Do consider implementing the check for not notifying if the creator edited the article since the CSD went up along with the anti-bombing, unless there is something I'm missing where they are likely to not have noticed the CSD when they made the edit. Let me know when the anti-bombing and templates are ready and I'll give a trial. Anomie⚔ 20:48, 2 December 2009 (UTC)
- I don't see a point in a non-admin shut off for this bot with this task and operator, even with change of operator, the task itself does not require a non-admin shut-off, imo. Looks fine, details covered, monitored by competent bot operators/watchers. --69.226.100.7 (talk) 19:49, 22 December 2009 (UTC)
- So basically, the bot will do the following: For certain CSD types, it will wait until at least 10 minutes after the CSD tag was placed on the article and then notify the creator of the article if they have not been notified already. Will it also not bother notifying if the creator has edited the article within that 10 minutes? Will it catch a situation where the creator was notified and deleted the notification? Was the suggestion at Wikipedia talk:Bots/Requests for approval/SDPatrolBot II#Template bombing implemented? If the bot's templates are not to be fully protected, will it verify that they have not been vandalized before substing them? Will the bot have a non-admin shutoff? Does the exclusion compliance include
- {{OperatorAssistanceNeeded}} Status report Mr. Pin? MBisanz talk 00:59, 16 December 2009 (UTC)
- The difficult thing is the templates :/. I'll try very hard to get them started today :D. - Kingpin13 (talk) 09:46, 16 December 2009 (UTC)
- Great, thanks for the update. MBisanz talk 10:22, 30 December 2009 (UTC)
- Haha, really sorry about the slow progress of this :/ - Kingpin13 (talk) 21:52, 30 December 2009 (UTC)
- No hurry, it'll just be attribute to BAGS ponderous ways. --IP69.226.103.13 | Talk about me. 07:33, 2 January 2010 (UTC)
- Haha, really sorry about the slow progress of this :/ - Kingpin13 (talk) 21:52, 30 December 2009 (UTC)
- Great, thanks for the update. MBisanz talk 10:22, 30 December 2009 (UTC)
- The difficult thing is the templates :/. I'll try very hard to get them started today :D. - Kingpin13 (talk) 09:46, 16 December 2009 (UTC)
How does the bot detect whether someone has been notified? — Carl (CBM · talk) 23:09, 6 January 2010 (UTC)
- At the moment it is just if the user's talk page has been edited since the page was created (to avoid template bombing). - Kingpin13 (talk) 10:06, 14 January 2010 (UTC)
Kingpin: these templates may be of use to you: Wikipedia:Bots/Requests for approval/SoxBot VII 3. (X! · talk) · @751 · 17:01, 9 January 2010 (UTC)
- Thanks X! - Kingpin13 (talk) 10:06, 14 January 2010 (UTC)
- Hi Kingpin, I understand the bot will not be able to notify the author if their page has been both tagged and deleted within ten minutes. I wouldn't want to delay implementation of the Bot, as I still see the bot as very much needed even with that limitation, but I would appreciate it if you could find a workaround for this. ϢereSpielChequers 18:55, 9 January 2010 (UTC)
- Well, I can shorten it to a matter of seconds/a minute (depending on the number of articles the bot is looking through). But it depends partly on ThaddeusB.
I have now created the warnings (they can be seen at User:SDPatrolBot II/Warning Examples). I haven't created one for every CSD, but if someone else wants to make some more I can add them to the bot. - Kingpin13 (talk) 10:06, 14 January 2010 (UTC)- Thanks, I think the gap between article tag and informing the author is important as it allows for manual and tailored messages; I was just wondering if there was some workaround that would still inform the author even if the article had been deleted in the interim. Is the problem that without making it an admin bot it can't see the deleted articles; or would it require it to be continuously running, keeping a log of tagged articles and then checking ten minutes later so that it could avoid warning the author if either the article was still there and no longer tagged or the author had been notified in the meantime? ϢereSpielChequers 11:09, 14 January 2010 (UTC)
- Yuh, the problem is that the bot (as a non-admin bot) can't see deleted edits, and although it does keep a log of the pages which have been tagged for deletion, it checks the page just before notifying the user, so the only workaround would be for the bot to be an admin (which isn't possible with me as op). BAG: The bot should be pretty much ready for a trial if we want :) - Kingpin13 (talk) 16:47, 16 January 2010 (UTC)
- A couple quick notes: I am sure changing the delay at some future point would not be an issue, if the need arises. I am an admin, so if admin functionality is decided to be necessary, that won't be an issue. --ThaddeusB (talk) 01:05, 21 January 2010 (UTC)
- But it would prove to be a bit of a problem with me coding it. I'd be happy to give the source code to an admin willing to take a shot at making this work with deleted pages. - Kingpin13 (talk) 13:09, 22 January 2010 (UTC)
- A couple quick notes: I am sure changing the delay at some future point would not be an issue, if the need arises. I am an admin, so if admin functionality is decided to be necessary, that won't be an issue. --ThaddeusB (talk) 01:05, 21 January 2010 (UTC)
- Yuh, the problem is that the bot (as a non-admin bot) can't see deleted edits, and although it does keep a log of the pages which have been tagged for deletion, it checks the page just before notifying the user, so the only workaround would be for the bot to be an admin (which isn't possible with me as op). BAG: The bot should be pretty much ready for a trial if we want :) - Kingpin13 (talk) 16:47, 16 January 2010 (UTC)
- Thanks, I think the gap between article tag and informing the author is important as it allows for manual and tailored messages; I was just wondering if there was some workaround that would still inform the author even if the article had been deleted in the interim. Is the problem that without making it an admin bot it can't see the deleted articles; or would it require it to be continuously running, keeping a log of tagged articles and then checking ten minutes later so that it could avoid warning the author if either the article was still there and no longer tagged or the author had been notified in the meantime? ϢereSpielChequers 11:09, 14 January 2010 (UTC)
- Well, I can shorten it to a matter of seconds/a minute (depending on the number of articles the bot is looking through). But it depends partly on ThaddeusB.
![]() Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. Tim1357 (talk) 16:41, 24 January 2010 (UTC)
Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. Tim1357 (talk) 16:41, 24 January 2010 (UTC)
- Grr, trying to get this done asap, but for some reason DotNetWikiBot is refusing to work properly in this particular project (it was fine before, and is working in other projects), I'm working on finding the cause of this. Sorry for the delay - Kingpin13 (talk) 20:58, 27 January 2010 (UTC)
- Trial complete. I messed up the first few edits, - Kingpin13 (talk) 16:57, 2 February 2010 (UTC)
- Approved. Looks like everything went well. Good luck! (X! · talk) · @783 · 17:47, 3 February 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was
 Request Expired.
Request Expired.
Operator: ThaddeusB
Automatic or Manually assisted: automatic, unsupervised
Programming language(s): Perl
Source code available: here
Function overview: fill in tables with data on prehistoric creatures
Edit period(s): one time run
Estimated number of pages affected: 13
Exclusion compliant (Y/N): N/A - this only applies to user & talk pages, correct?
Already has a bot flag (Y/N): N
Function details: Using a large database of information downloaded from http://paleodb.org and http://strata.geology.wisc.edu/jack/ the first function of this bot will be to fill in the tables found in various "list of" articles. A sample entry has been filled in here. Any data that is missing from the database will simply to left blank.
Only a tiny number of pages will be affected, but the amount of bot filled in content will be immense. As such, I am suggesting the bot trial be something along the lines of "the first 10 entries on each page" rather than a number of edits.
A copy of the database is available here (425k). The database is organized as follows:
Genus--Valid?--Naming Scientist--Year named--Time period it lived during--Approx dates lived--locations
- A "1" in the valid column means it is currently listed as a valid genus, "NoData" means it couldn't be determined - most likely because there are two genus with the same name, and "No-{explanation}" means it is not currently listed as a valid genus.
- Data proceed by a "*" means it was derived from Sepkoski's data, using the dates found here (compiled by User:Abyssal). All other data came from paleodb, using their fossil collection data for more precise dates (when available.)
- Spot checking of my data is encouraged, although I'm confident no novel errors have been introduced. If anyone knows of additional sources to derive similar data, let me know and I'll incorporate those sources into the database.
List of pages to to affected: (might be expanded slightly if others are found)
- List of prehistoric starfish
- List of prehistoric barnacles
- List of crinoid genera
- List of prehistoric echinoids
- List of edrioasteroids
- List of graptolites
- List of prehistoric sea cucumbers
- List of hyoliths
- List of prehistoric malacostracans
- List of prehistoric brittle stars
- List of prehistoric ostracods
- List of prehistoric chitons
- List of prehistoric stylophorans
Discussion
Source code will be published shortly, although the code itself is a quite simple "read from db publish to Wikipedia" operation. --ThaddeusB (talk) 01:48, 3 September 2009 (UTC)
- Now available here. --ThaddeusB (talk) 13:16, 8 September 2009 (UTC)
I have spammed asked the relevant projects for input: [2] --ThaddeusB (talk) 02:08, 3 September 2009 (UTC)
- Wikipedia talk:WikiProject Gastropods#BOT notice.
- List of genera of Monoplacophora would be fine. (Uncertain Monoplacophora/Gastropoda should be on separate list. See Monoplacophora#Fossil species.) --Snek01 (talk) 09:29, 3 September 2009 (UTC)
Bullets?
Maybe the countries should be a bulleted list to save horizontal space. IE:
- Poland
- Switzerland
as opposed to "Switzerland, Poland". Abyssal (talk) 15:30, 3 September 2009 (UTC)
- Which is preferable: Option 1
| Genus | Authors | Year | Status | Age | Location(s) | Notes |
|---|---|---|---|---|---|---|
| Advenaster | Hess | 1955 | Valid | Late Bajocian to Late Callovian | Switzerland, Poland | |
| SampleEntry | Hess | 1955 | Valid | Early Cretaceous to present | Switzerland, Poland, United States, France | |
| Bad Genus | Invalid | rank changed to subgenus, name to Genus (Sub genus) |
- Option 2
| Genus | Authors | Year | Status | Age | Location(s) | Notes |
|---|---|---|---|---|---|---|
| Advenaster | Hess | 1955 | Valid | Late Bajocian to Late Callovian | Switzerland Poland |
|
| SampleEntry | Hess | 1955 | Valid | Early Cretaceous to present | Switzerland Poland United States France |
|
| Bad Genus | Invalid | rank changed to subgenus, name to Genus (Sub genus) |
- or Option 3
| Genus | Authors | Year | Status | Age | Location(s) | Notes |
|---|---|---|---|---|---|---|
| Advenaster | Hess | 1955 | Valid | Late Bajocian to Late Callovian |
|
|
| SampleEntry | Hess | 1955 | Valid | Early Cretaceous to present |
|
|
| Bad Genus | Invalid | rank changed to subgenus, name to Genus (Sub genus) |
- Any is fine by me. --ThaddeusB (talk) 18:49, 3 September 2009 (UTC)
- Definitely 2 or 3, although I don't care which. I love that you're using the sort template. <3 Also, could you have the year link to the "year in paleontology" article? And link to the countries? Abyssal (talk) 04:35, 4 September 2009 (UTC)
- No problem, I will link the date & countries. --ThaddeusB (talk) 13:45, 4 September 2009 (UTC)
- Hmm, WP:Context and all that - re countries. Surprise links to "year in" are not that great either. Rich Farmbrough, 09:51, 6 September 2009 (UTC).
- No problem, I will link the date & countries. --ThaddeusB (talk) 13:45, 4 September 2009 (UTC)
- Definitely 2 or 3, although I don't care which. I love that you're using the sort template. <3 Also, could you have the year link to the "year in paleontology" article? And link to the countries? Abyssal (talk) 04:35, 4 September 2009 (UTC)
Invalid genera should be in separate table, because it is better for general public. If there is any reason to have them together, then it could be also OK. Such tables will be also useful. --Snek01 (talk) 11:48, 4 September 2009 (UTC)
- I'm neutral on linking the countries, although I will point out that such links would allow someone to easily figure out where in the world the fossil was found. I view the "year in" links as completely appropriate as naming of new genus is something that is/should be covered in those articles. --ThaddeusB (talk) 13:16, 8 September 2009 (UTC)
- The bot is only going by the entries that already exist in the tables & it looks like there are only about 5 invalid entries across the dozen or so pages. As such, I've leave it up to regular editors to pull the entries out of the main table rather than trying to write a function to do it.
Improper age sorting (fixed)
A sample update has been performed here. --ThaddeusB (talk) 13:16, 8 September 2009 (UTC)
- I haven't had time to look closely at it, but I notice the age sorting isn't working right, but I can't figure out why. Any idea? Abyssal (talk) 18:31, 8 September 2009 (UTC)
- Hmm, could you be more specific as it seems to work for me. The first click put it from most recent to oldest and the second from oldest to most recent. --ThaddeusB (talk) 00:57, 9 September 2009 (UTC)
- The first 20% or so is alright, but after the Miocene (when viewed in ascending order) it starts listing Jurassic stages, then it goes back to Pleistocene, and for some reason Cretaceous ages are listed as if they were the oldest. It's looked this way both at home and at school. The browser I used is Firefox. Abyssal (talk) 19:09, 9 September 2009 (UTC)
- OK, I figured out the problem. Apparently the {{sort}} template doesn't work properly with numbers, so everything is being sorted "alphabetically" - that is 1 < 10 < 2 etc. It was only coincidence that the first 20% is still correct (and I didn't look down far enough to realize the error). I'll add a fix for this tonight & re-upload the sample page. --ThaddeusB (talk) 20:05, 9 September 2009 (UTC)
- Good sleuthing! Abyssal (talk) 22:28, 9 September 2009 (UTC)
- OK, I figured out the problem. Apparently the {{sort}} template doesn't work properly with numbers, so everything is being sorted "alphabetically" - that is 1 < 10 < 2 etc. It was only coincidence that the first 20% is still correct (and I didn't look down far enough to realize the error). I'll add a fix for this tonight & re-upload the sample page. --ThaddeusB (talk) 20:05, 9 September 2009 (UTC)
- The first 20% or so is alright, but after the Miocene (when viewed in ascending order) it starts listing Jurassic stages, then it goes back to Pleistocene, and for some reason Cretaceous ages are listed as if they were the oldest. It's looked this way both at home and at school. The browser I used is Firefox. Abyssal (talk) 19:09, 9 September 2009 (UTC)
- Hmm, could you be more specific as it seems to work for me. The first click put it from most recent to oldest and the second from oldest to most recent. --ThaddeusB (talk) 00:57, 9 September 2009 (UTC)
I believe the latest upload fixes the issues. --ThaddeusB (talk) 21:19, 10 September 2009 (UTC)
- How did you fix the problem (I'll need to use the same method for other articles). Abyssal (talk) 02:28, 11 September 2009 (UTC)
- By adding enough zeros in front of the numbers to make them correctly sort as strings. That is, by converting "1.23" to "001.23", "45" to "045", etc. --ThaddeusB (talk) 20:41, 12 September 2009 (UTC)
Need for outside input
Just a thought, but in light of the Anybot debacle - it might be a good idea to put a call out to the WikiProjects and recruit some marine biologists/fossil guys/crustacean guys/etc. to come take a look at your trial edits and check them over with a fine tooth comb before the bot is given final approval. If Anybot taught us anything, it's how simple errors in interpreting database content can lead to masses of incorrect information going live to the 'pedia and remaining there for months, unnoticed. --Kurt Shaped Box (talk) 22:28, 10 September 2009 (UTC)
- I certainly want several people to look over the data and have notified the 6 most relevant WikiProjects. So far, those notices don't seem to have attracted many people. :( --ThaddeusB (talk) 22:45, 10 September 2009 (UTC)
- Can you try asking specific editors by the type of articles you intend to produce? Asking editors if they will check the data? --69.225.12.99 (talk) 02:34, 11 September 2009 (UTC)
13 pages? Why do we need to approve a bot for that? Run your program. Dump the output to a screen. Post it by hand. Preview. Save. A bot will save you a few minutes whilst vastly increasing the risk to the project. Hesperian 23:55, 10 September 2009 (UTC)
- First off, let's not be ridiculous - me running a program locally & manually uploading the data is no less of a risk than me running a program locally & it automatically uploading the data. Now, there are several reasons I am requesting approval rather than just uploading the data:
- Yes it will only edit a few pages, but the amount of data it will import is immense, as we are talking about the automated filling of several thousand table entries. The amount of info that is being auto generated and added deserves community consent, IMO.
- I want as many people as possible to look it over to make sure the bot isn't adding inaccurate info. If I just uploaded it all in my name, it wouldn't get the same scrutiny
- There is a planned second part of this task (automated creation of stubs) that will edit thousands of articles. This will be a separate BRFA, but the idea here is to get any bugs/inaccurate input data fixed on a relatively non-controversial task before moving onto a possibly controversial one. If the bot can handle accurate adding content to existing articles, then there is concrete evidence that it should be able to create stubs with prose based on the same information.
- I hope that clear it up. --ThaddeusB (talk) 00:20, 11 September 2009 (UTC)
- I obviously agree with Thad. This sort of tedious point-by-point extraction of information from a database is what bots are Wikipedia bots are made for. As someone who has filled similar tables out manually, I can vouch that using a bot for this purpose is the most effective way to accomplish it. Abyssal (talk) 02:18, 11 September 2009 (UTC)
- I agree with that, Abyssal. I run scripts like that myself. But you don't need a bot account to run a script against an external data source. You only need a bot account to post the formatted results to Wikipedia. Personally I prefer to run my scripts, examine the results, tweak the scripts and run them again if necessary, iterate, eventually load the results into an edit window, preview, tweak, and finally save. It is a lesser risk to do it this way. The risk is only the same if you are going to copy-paste-save without examining the results, just like a bot would do. And in that case, I cannot comprehend why a bot is necessary. Once you've generated the data, posting 13 pages by hand will take you 6½ minutes. Thaddeus, I sure hope you'll be spending more time than that implementing and testing your bot. So where is the benefit? I also dispute the scrutiny argument. People don't scrutinise bots more; they largely ignore them until they screw up royally. And no, you don't need to obtain community consent before you edit Wikipedia, even if you are posting big pages. Hesperian 05:42, 16 September 2009 (UTC)
- I already have examine the input data, tested the bot, and reviewed its results fairly extensively. I've probably put around 40 hours into it in fact. I am well aware that I didn't need approval to do this task. I merely feel it is better to do it with approval than without. This vetting process has already led to some subtle improvements that likely would have never happened if I'd only reviewed the output on my own. --ThaddeusB (talk) 13:09, 16 September 2009 (UTC)
- I agree with that, Abyssal. I run scripts like that myself. But you don't need a bot account to run a script against an external data source. You only need a bot account to post the formatted results to Wikipedia. Personally I prefer to run my scripts, examine the results, tweak the scripts and run them again if necessary, iterate, eventually load the results into an edit window, preview, tweak, and finally save. It is a lesser risk to do it this way. The risk is only the same if you are going to copy-paste-save without examining the results, just like a bot would do. And in that case, I cannot comprehend why a bot is necessary. Once you've generated the data, posting 13 pages by hand will take you 6½ minutes. Thaddeus, I sure hope you'll be spending more time than that implementing and testing your bot. So where is the benefit? I also dispute the scrutiny argument. People don't scrutinise bots more; they largely ignore them until they screw up royally. And no, you don't need to obtain community consent before you edit Wikipedia, even if you are posting big pages. Hesperian 05:42, 16 September 2009 (UTC)
- I obviously agree with Thad. This sort of tedious point-by-point extraction of information from a database is what bots are Wikipedia bots are made for. As someone who has filled similar tables out manually, I can vouch that using a bot for this purpose is the most effective way to accomplish it. Abyssal (talk) 02:18, 11 September 2009 (UTC)
Discussion regarding some objections
- In my opinion, I don't think this bot should go forward without proactive community support for the bot. This means more than no one disapproves or shows negative interest. It requires editors from relevant projects get on board for vetting uploaded data. Without a group of editors to check data, it is my opinion the potential for another AnyBot type mess exists. Yes, this is the type of work that bots should be used for, in my opinion. But it requires a human editorial community to accompany the creation of articles. I'm also not thrilled with the sideways answers to some of my questions about this bot, before the RFBA. A single straight-forward answer to a question, when first asked, is more in keeping with the kind of communication that should be done when running bots that create articles, in my opinion. --69.225.12.99 (talk) 02:33, 11 September 2009 (UTC)
- To be fair, no one asked me a single question. An IP (possibly you) asked Abyssal some questions, but they seemed to be directed towards his editing activities & not this bot. Additionally, he obviously didn't know the exactly details of how the bot would operate since he wasn't programming it... and frankly I didn't know the exact details either since it wasn't complete yet. I have explained what the bot plans to do in this BRFA (which is the correct place to do so), released the source code, and released the database. I personally have manually checked dozens of entries and I'm pretty sure Abyssal has as well. If you are offering your help in spot checking, then please check how many ever entries you want from the database, against whatever data source you can. If you find any problems, by all means please tell me so I can make adjustments to the database.
- Beyond that, there really isn't anything I can do. I can't force people to spot check the data. Nor can I, or anyone else, check more than a trivial % of the total. I have to rely on the accuracy of the data I obtained from reliable sources. I can't verify every piece of data by hand, but only confirm the general integrity of the sources from which the data came. --ThaddeusB (talk) 03:06, 11 September 2009 (UTC)
- And BTW, the bot isn't going to be creating any articles at this time. --ThaddeusB (talk) 03:08, 11 September 2009 (UTC)
- In my opinion, I don't think this bot should go forward without proactive community support for the bot. This means more than no one disapproves or shows negative interest. It requires editors from relevant projects get on board for vetting uploaded data. Without a group of editors to check data, it is my opinion the potential for another AnyBot type mess exists. Yes, this is the type of work that bots should be used for, in my opinion. But it requires a human editorial community to accompany the creation of articles. I'm also not thrilled with the sideways answers to some of my questions about this bot, before the RFBA. A single straight-forward answer to a question, when first asked, is more in keeping with the kind of communication that should be done when running bots that create articles, in my opinion. --69.225.12.99 (talk) 02:33, 11 September 2009 (UTC)
- If the bot is going to be creating tables of data on wikipedia and there is not a single editor outside of the creators interested in the data, there appears to be no desire for the bot on wikipedia. If aren't willing to check the data and are not interested enough to comment on the bot, who wants the bot?
- According to bot policy, to gain approval, a bot must :
- be harmless
- be useful
- not consume resources unnecessarily
- perform only tasks for which there is consensus
- carefully adhere to relevant policies and guidelines
- use informative messages, appropriately worded, in any edit summaries or messages left for users
- Consensus involves discussion and other editors. No other editors = no discussion = no consensus for the task to be done, much less by a bot. --69.225.12.99 (talk) 06:57, 11 September 2009 (UTC)
- You are mistaken about the way Wikipedia works. Discussion is not needed to take action, discussion is only needed if the action taken if met with objection. Being bold is a core principle. If we had to discuss every action first, very little would actually get done. The task clearly falls under policy so there is already consensus to do the task. This discussion is to establish that my bot can do the task accurately and efficiently.
- Second, you mistake low input for lack of interest. Just because few people have commented here, doesn't mean no one is interested in the data. We are talking about scientific data on prehistoric creatures here, not Britney Spears. The audience interested in this material is limited, of course, but nearly everyone would agree that this sort of information is at least as important to have on Wikipedia as pop culture, even though far fewer people are interested in it.
- Third, you misunderstand what this request is for. The request is to fill in the existing tables, not create new ones. Technically (as pointed out by Hesperian) I do not even need BOT approval to do the task. The request was created in part to solicit additional eyes to make sure the data is accurate. Again, the information is 100% from reliable sources and a bot will copy the information far more accurately than a human ever could. So, I ask again are you willing to look over the data? Or are you just trying to block the task from happening? --ThaddeusB (talk) 15:28, 11 September 2009 (UTC)
- No, I'm not mistaken about how wikipedia works, and I'm not mistaken about your insulting me rather than addressing the issue. The use of bots does not function by the, be bold, run a bot, make 10,000 entries, then decide if the community wants it theory. Please read the bots policy in its entirety before requesting approval for a bot. It is your responsibility as a bot operator to adhere to bot policy. You can't do that if you don't know it.
- I think it's time to close this bot request for approval until there is community consensus for this task to be done. The lack of editors monitoring AnyBot was problematic enough, but that bot at least had some community consensus. This bot has absolutely none, and its operator denies there is any need for community consensus for its task. This is a bad start. Couple with the bot operator's combative nature and inability and/or unwillingness to address issues, I can't see anything but disaster and another mess of 1000s of entries for someone else to clean up. --69.225.12.99 (talk) 16:32, 11 September 2009 (UTC)
- As the creator, designer, and near sole contributor to Wikipedia's lists of prehistoric invertebrates, and also the user who "proactively" sought out someone capable of programming a bot to perform the task at hand, I am curious as to who you expect us to seek consensus from. Should I make sock puppets and then ask them if they approve? I created every single one of the lists ContentCreationBOT will be contributing to, and somewhere around 23-26 of the 28 lists of prehistoric invertebrates in total on Wikipedia. Yes, I gave a range of pages there, as in "I created so many of them that I've lost count." The community-of-people-who-contribute-to-Wikipedia's-lists-of-prehistoric-invertebrates consists nearly entirely of myself, and there is strong consensus between myself and I that this task should move ahead. It's also nice of you to dishonestly claim that we're creating stubs here. We've worked diligently for months preparing this bot and you're willing to shut us down without even having read the description of the task we're requesting approval for. And the when we don't just hump up and take it, you throw a hissy fit and demand that the discussion be closed. Wow. Abyssal (talk) 17:20, 11 September 2009 (UTC)
- I didn't use the word stub, until now. I think that this type of personal attack of people ("you throw a hissy fit") who have questions and concerns about the bot, once more, bodes poorly for the use of this bot to create any type of content. --69.225.12.99 (talk) 03:39, 12 September 2009 (UTC)
- I took "create 10,000 entries" as you implying the bot would engage in stub generation, if that's not what you meant, sorry. Assuming you were referring to the data-adding task the bot isn't "creating" the enries, it's filling in blank entries in tables that already exist. Abyssal (talk) 18:15, 12 September 2009 (UTC)
- I didn't use the word stub, until now. I think that this type of personal attack of people ("you throw a hissy fit") who have questions and concerns about the bot, once more, bodes poorly for the use of this bot to create any type of content. --69.225.12.99 (talk) 03:39, 12 September 2009 (UTC)
- As the creator, designer, and near sole contributor to Wikipedia's lists of prehistoric invertebrates, and also the user who "proactively" sought out someone capable of programming a bot to perform the task at hand, I am curious as to who you expect us to seek consensus from. Should I make sock puppets and then ask them if they approve? I created every single one of the lists ContentCreationBOT will be contributing to, and somewhere around 23-26 of the 28 lists of prehistoric invertebrates in total on Wikipedia. Yes, I gave a range of pages there, as in "I created so many of them that I've lost count." The community-of-people-who-contribute-to-Wikipedia's-lists-of-prehistoric-invertebrates consists nearly entirely of myself, and there is strong consensus between myself and I that this task should move ahead. It's also nice of you to dishonestly claim that we're creating stubs here. We've worked diligently for months preparing this bot and you're willing to shut us down without even having read the description of the task we're requesting approval for. And the when we don't just hump up and take it, you throw a hissy fit and demand that the discussion be closed. Wow. Abyssal (talk) 17:20, 11 September 2009 (UTC)
- 1) I didn't insult you, and I am sorry you took it that way. I merely stated that you don't appear to understand what consensus means (at least as it applies to bot tasks).
- 2) "Perform only tasks for which there is consensus" means perform a task for which there is generally consensus. It doesn't mean we need 20 editors to come comment on every bot and say "yep, there is consensus for this task." There is already implicit consensus for adding this sort of information to articles as it has been done hundreds of time by many different editors with no objections. The bot can just do it faster and more accurately.
- 3) I have 3 approved bots and understand bot policy thoroughly.
- 4) You are arguing over semantics, not substance. I most certainly didn't claim the bot doesn't need consensus.
- 5) I can't "address the issue" as you have not outlined any actual issue with either the bot or the RS data it is using. You have only stated your personally opinion that you think more people should look at the data.
- 6) Do you have any actual policy based objection to the task of filling in existing tables with reliable source data? Or any objections to the data/code to put it on Wikipedia?
- 7) If the bot is rejected I will just manually upload the exact same data - as is my right as an editor - and the community will loose the benefit of explicitly knowing it was extracted from a database by a bot. Again, I didn't even have to ask for approval of this task as there is no actual need to automate the uploading. I did so for the community's benefit. --ThaddeusB (talk) 16:56, 11 September 2009 (UTC)
- Consensus involves discussion and other editors. No other editors = no discussion = no consensus for the task to be done, much less by a bot. --69.225.12.99 (talk) 06:57, 11 September 2009 (UTC)
I would also like to add that the data has been looked over by accredited scientists or it wouldn't have been on Paleodb.org to begin with. To expect me or anyone else to manually check every entry is completely unreasonable and, in my opinion, would be more likely to introduce novel errors than improve overall accuracy even if it was possible. --ThaddeusB (talk) 17:02, 11 September 2009 (UTC)
- I stand by my original "hissy fit." --69.225.12.99 (talk) 03:39, 12 September 2009 (UTC)
- Does that mean you also stand by your refusal to provide any concrete objections? --ThaddeusB (talk) 17:38, 12 September 2009 (UTC)
- I stand by my original "hissy fit." --69.225.12.99 (talk) 03:39, 12 September 2009 (UTC)
Question for ThaddeusB and Abyssal
As a matter of interest - and this may help to assuage "the IP algae guy"'s (as I think of him, based on our previous work together cleaning up after Anybot and in lieu of a better name) doubts and concerns, how familiar are you guys with the taxonomy of prehistoric invertebrates in a non-WP context? Is this your chosen field, area of scholarly interest or hobby? IOW - do you *know* these ex-critters, or are you strictly data-processing here?
The reason I ask is so that it may be established how likely it would be that a subtle misunderstanding/misinterpretation of the data presented at Paleodb (perhaps due to incorrect assumptions being made from incomplete knowledge) could occur, go unnoticed during the transfer because no-one knows what to look for - and thus result in massive factual errors being introduced to the wiki. Going back to Anybot, one of the reasons that it failed so hard was the that BotOp didn't really 'know' algae to any great extent - but did he earnestly believe that he was capable of extracting the data automatically and formatting it into encyclopedia articles. That's all well and good, if it works - but well as misunderstanding some fundamental algae-related terms, he incorrectly assumed (as far as I am aware) that 'number of taxa/species listed at AlgaeBase = number of taxa/species known to science' and ran with it. Then, as there was no-one else around at the time who knew better (or perhaps because no-one else even looked at the resultant articles once they'd gone live), the assumption was made that the bot's output was correct. IIRC, the systematic errors were only uncovered when "IP algae guy"'s students started handing in coursework containing WP-sourced nonsense.
This scenario may not be exactly applicable to the Paleodb dataset - but before this goes any further, I would like to gauge the likelihood of the same thought process being applied again and leading to a different, but equally-borked end result. --Kurt Shaped Box (talk) 09:09, 12 September 2009 (UTC)
- I believe the main problem with Anybot was programming, not lack of knowledge - although the second obviously contributed. The programmer made several fundamental errors like not resetting variables & making it runnable from a remote location without a password. These problems were not caught because 1) the code wasn't published and 2) no one who knew what they were doing looked over the sample stubs from the trial run. My code has been published, as has the data, as has a sample page. The code is not runnable remotely.
- I do not personally have any knowledge of the subject. I was solicited as a capable bot op, with (what I believe to be) a reputation for carefully checking my bots' output & correcting errors. Abyssal is the one with the knowledge of the subject and the idea for the bot. He was doing the task manually for some time, but some users contacted him to say they thought a bot would do the task faster and more accurately, which is true. A human copy and pasting data will make an occasional error despite their understanding of the subject that a bot wouldn't make.
- The reason I have been asking User:Abyssal about the bot is because there are problems with the fish stubs he/she created en masse. I am still waiting for him/her to respond to a question about the fish stubs I put on the user's talk page on May 30th.
- While Abyssal claims to be the only working invertebrate paleontologist on wikipedia that is incorrect. I edit invertebrate paleo articles as do a number of my colleagues. Ultimately I will be more concerned about the stubs, but, thank you Kurt Shaped Box for reminding me how I met Abyssal: correcting problems with stubs. Oh, by the way, I'm not really algae guy, as I've said before, I'm marine invertebrate paleo guy. --69.225.12.99 (talk) 09:29, 12 September 2009 (UTC)
- You are putting words in Abyssal's mouth. He didn't claim to be the "only working invertebrate paleontologist." He claimed to be the only one working on the specific articles for which this bot will provide data. Additionally, the error you found is precisely why this task should be done by a bot. No human is going to be able to copy gobs of data without introducing novel errors. A well made bot, won't introduce novel errors, although obviously it won't correct any errors in the original data either. (However, by Wikipedia policy we really should be goign by what the source says anyway, not using our own knowledge.) If you have any source to cross-check the paleodb data against, I'd love to hear it. Otherwise, I say that this is the best available data and that there is absolutely nothing wrong with reproducing it.
- Again, why are you trying to block this task. You say you have knowledge with the subject, yet you refuse to offer you help looking over the data. You demand I find people willing to do this, yet you yourself are a prime candidate to help & refuse. Why? --ThaddeusB (talk) 17:38, 12 September 2009 (UTC)
- If anyone has issues with the stubs I made before, all they have to do is ask. If they've asked and I've forgotten to respond, all they have to do is ask again and remind me. That's much nicer than asking, then waiting for months before bringing it up as an act of passive aggression. Also, the substubs I created are not only irrelevant to the discussion on face, but they also bear little resemblence to the fuller, more complete stubs that ContentCreationBOT may create in the future and serve as a poor analogy for such. Abyssal (talk) 18:30, 12 September 2009 (UTC)
- Okay - 'Marine Invertebrate Paleo Guy' is is, then... :) By the way, is this the user talkpage post you're talking about? If so, Abyssal did reply to you. --Kurt Shaped Box (talk) 09:41, 12 September 2009 (UTC)
- No, in fact he/she didn't. The last question I posed has been ignored since it was posted--reread the post about the two articles with similar names. He/she only responded to the first part, agreeing I had corrected his data for the one article, and thanking me for doing so, but not for the question of whether both articles for what appear to be a single organism should be on wikipedia. This last is precisely the type of mistake that needs reviewed and corrected by humans with content creation bots. This bots owner and assistant have resorted to bullying. Bullying by the bot operators coupled with failure to act = giant mess on wikipedia that someone else has to clean up. It took months and probably a dozen wikipedia editors to clean up the AnyBot mess. In my opinion it's time to put an end to this RfBA as a place for User:ThaddeusB to post his personal attacks, since he doesn't have what is necessary for running a bot of this nature, and is focused on attacking me rather than getting the bot together. --69.225.12.99 (talk) 18:17, 12 September 2009 (UTC)
- The only one attempting to bully people here is you with your whole I don't agree with this so let's shut down discussion right now attitude. You have repeatedly demanded this not take place, but still have yet to offer a single constructive comment. You say I am focused on "attacking you rather than getting the bot together." Um, the bot is together. There is nothing to "get together." Again, you have yet to offer a single actionable complaint with the actual bot that I can address.
- You claim to be interested in making sure the bot doesn't make any errors, yet you refuse to help. I think it is pretty clear that your objection is either philosophical against this sort of task ever being done, or is motivated by personal dislike for me and/or Abyssal.
- I have not made a single personal attack against you. I merely comments on your comments, just as you have commented on mine. Somehow it is perfectly acceptable for you to distort others comments and say whatever crap you want about them, but if they dare mention you in a reply they are personally attacking you?
- Finally "this is the kind of mistake that needs to be reviewed by humans" is an irrelevant comment because this mistake was made by a human, not a bot. In fact, this example is proof why the task should be done by a bot - humans will always make some mistakes when copying large amounts of data. --ThaddeusB (talk) 19:05, 12 September 2009 (UTC)
- I'm male, no need to use the double pronoun thing. As for bots adding errors, the articles won't be set in stone after creation, they will be subjected to the same scrutiny and incremental revisions and fact-checking that all other Wikipedia articles are. It's almost certain that bot generated content will introduce some errors, however, our human editors do substantial amounts of that as well. If a human added 99% good information and 1% inaccurate information, we would think of them as doing a good job. It's illogical to demand more from an automated contributor than from a flesh-and-blood one, but you seem to be expressing that double standard anyway. "Failure to act"? We've already run succesful demonstrations and made the full code public! What would it take to please you? As for us being bullies, well, an old proverb comes to mind. Abyssal (talk) 18:51, 12 September 2009 (UTC)
- I understand that all bots can hiccup and make mistakes from time to time. Unless they start crapflooding, blanking or overwriting a huge number of articles, it's a pretty matter to put right. I'm more concerned about systematic errors that could result in non-apparent-except-to-experts factual inaccuracies across the majority of the bot-generated content. How confident are you with the subject matter at hand and the interpretation of the database content that this may be avoided - or if it did occur, that you'd be able to spot it quickly? I don't want it to come across as though I'm picking on you and ThaddeusB here - but Anybot has left me wary of bots that autogenerate content in this manner, wary enough at least to be thorough in asking questions. --Kurt Shaped Box (talk) 20:17, 12 September 2009 (UTC)
- I think that thorough testing and a bit of preliminary fact-checking will demonstrate whether or not ContentCreationBOT can succesfully utilize the database to generate new content for Wikpedia. If it does prove successful in drawing from the database, then any errors will be on the database's side and thus out of our control. However, since the database was compiled and is operated by scientists, I have confidence that there will be no major problems. At this point it's really just a matter of testing. Abyssal (talk) 15:22, 14 September 2009 (UTC)
- One of the reasons the anybot mess wound up so spectacularly bad was poor communication on the part of the bot operator and unwillingness to respond to concerns. These two users see expressions of concerns about their bot as an opportunity to attack someone for expressing concerns. This will make communication hard to impossible. Poor communication means it won't matter how a mistake is made, because the response will be to attack those who raise issues. And keep attacking and attacking them. Then come back and attack them some more. In my opinion, it simply doesn't matter, once an attitude of this manner has taken hold of the bot operator, there will be no means for issues of concern about the bot to be raised, no means for problems with the data to be pointed out. All such actions will get is an attack. And another attack, and an attack from a different angle, and a new attack. --69.225.12.99 (talk) 06:43, 13 September 2009 (UTC)
- For the dozenth time, do you have any actual objection to express or are you just trying to block the bot? Also, for the dozenth time I can't address "your concerns" until you actually express something concrete. And no that isn't a personal attack despite what you seem to think. --ThaddeusB (talk) 13:06, 13 September 2009 (UTC)
- I understand that all bots can hiccup and make mistakes from time to time. Unless they start crapflooding, blanking or overwriting a huge number of articles, it's a pretty matter to put right. I'm more concerned about systematic errors that could result in non-apparent-except-to-experts factual inaccuracies across the majority of the bot-generated content. How confident are you with the subject matter at hand and the interpretation of the database content that this may be avoided - or if it did occur, that you'd be able to spot it quickly? I don't want it to come across as though I'm picking on you and ThaddeusB here - but Anybot has left me wary of bots that autogenerate content in this manner, wary enough at least to be thorough in asking questions. --Kurt Shaped Box (talk) 20:17, 12 September 2009 (UTC)
- Oh yeah, I see what you mean. Abyssal - could you check to see whether Graphiuricthys and Graphiurichthys (with an extra 'h') are supposed to be two separate articles? --Kurt Shaped Box (talk) 20:23, 12 September 2009 (UTC)
- Thay're the same animal, so far as I can tell, but both have been used in the technical literature. I'm not sure which one is correct. Abyssal (talk) 15:16, 14 September 2009 (UTC)
- What to do, then? Pick the most commonly used name and redirect the other article to it (Google Scholar would suggest that 'Graphiurichthys' is the way to go)? I know that these two were human-created articles - but this is exactly the sort of thing that the bot must not be permitted to do, if it starts creating stubs. --Kurt Shaped Box (talk) 19:47, 14 September 2009 (UTC)
- Sepkoski spelled it wrong. It seems I added both the correct and incorrect spellings, forgot about it, and accidentally created an article for both. The problem seems to be pure human error on my part, and therefore unlikely to be duplicated by a bot. Abyssal (talk) 13:03, 15 September 2009 (UTC)
- What to do, then? Pick the most commonly used name and redirect the other article to it (Google Scholar would suggest that 'Graphiurichthys' is the way to go)? I know that these two were human-created articles - but this is exactly the sort of thing that the bot must not be permitted to do, if it starts creating stubs. --Kurt Shaped Box (talk) 19:47, 14 September 2009 (UTC)
- Thay're the same animal, so far as I can tell, but both have been used in the technical literature. I'm not sure which one is correct. Abyssal (talk) 15:16, 14 September 2009 (UTC)
- No, in fact he/she didn't. The last question I posed has been ignored since it was posted--reread the post about the two articles with similar names. He/she only responded to the first part, agreeing I had corrected his data for the one article, and thanking me for doing so, but not for the question of whether both articles for what appear to be a single organism should be on wikipedia. This last is precisely the type of mistake that needs reviewed and corrected by humans with content creation bots. This bots owner and assistant have resorted to bullying. Bullying by the bot operators coupled with failure to act = giant mess on wikipedia that someone else has to clean up. It took months and probably a dozen wikipedia editors to clean up the AnyBot mess. In my opinion it's time to put an end to this RfBA as a place for User:ThaddeusB to post his personal attacks, since he doesn't have what is necessary for running a bot of this nature, and is focused on attacking me rather than getting the bot together. --69.225.12.99 (talk) 18:17, 12 September 2009 (UTC)
The problem with anybot was not necessarily the database. The data at algaeBase are fine, and the means of gathering data are identified. Part of what led to a huge mess, that caused the deletion of over 4000 articles and a couple of thousand redirects, was the lack of understanding of the data by the human coder and no community involvement in checking and verifying the articles.
Add to this an operator who would not deal with the problem articles as they were pointed out and you get a couple dozen other editors having to sort out the mess and delete the content.
In spite of the accusation of my being "passive-aggressive" two problem articles generated by Abyssal have been on wikipedia for a long time. He's willing to throw accusations at me, but still hasn't risen to the occasion of correcting the error. If he's going to leave articles that need deleted or corrected up, and these are just two, maybe he's expecting that someone else will clean up after the bot.
These are just two articles with little information in them, and one article is wrong and needs to be either a redirect or deleted. If this bot contributes 10,000 data items, who's going to check for accuracy? If there is any inaccuracy who's going to clean it up?
It seems ThaddeusB is going to blame me for not cleaning up the articles he wants to create-no, I'll do my own volunteer work on wikipedia, not yours, ThaddeusB. Let me know when you're going to start creating the articles I want. And Abyssal is going to throw accusations at the reporters of errors, but not going to correct errors.
Anybot generated errors due to human mistakes. Bots are subject to human errors. An unwillingness to address or correct errors is not an indicator for responsible bot running. --69.225.3.119 (talk) 05:18, 17 September 2009 (UTC)
- Yet again do you have any actual objection I can address? Anybot's code was never checked & it seems was riddled with errors. I am sorry that happened, but its operator's problems are not a reflection on me. This bot's code has been checked & verified that it will copy the data exactly as planned. Further, there is no special knowledge required to copy, for example, the naming scientist from a database to a table.
- I most certainly will listen to complaints if you have any that I can actually address. So far your complaints consist of 1) I won't manually check every entry and 2) I allegedly won't respond to complaints. The first is an unreasonable demand that would defeat the point of the bot. The second is merely speculation on your part, and runs contrary to my actual history on Wikipedia.
- Then there is your constant stretching the truth\drawing unreasonable conclusions. E.g., "two problem articles generated by Abyssal" somehow equates to this bot screwing up massively. Wow, a human that made two errors in over 2000 articles. (OK, he probably actually made a few more, but clearly the error rate is very low.) One of which was copying Sepkoski's non-standard spelling, which is hardly a serious error. That is hardly reason to shut down this bot. And again, it is completely disingenuous to compare stub creation to filling in a table - the two are hardly the same thing.
- Finally, I am not asking you to check 10,000 items I am just asking you to be reasonable and not expect me to check every item either. I have checked about 100 items and found no errors. That is a reasonable spot check. Others have checked some items as well. If you are unwilling to check even one item, then you have no right to complain that others haven't checked enough. --ThaddeusB (talk) 12:23, 17 September 2009 (UTC)
- I'd feel a little less concerned about all this if Abyssal had fixed those duplicate articles already. It's been a few days now since they were pointed out to him. Now, if the bot buggers up the current task, fixing it will be a simple matter of a few one-click reverts. However, if something goes wrong if/when the bot starts creating stubs and we end up with another Anybot-type mess, I'd hope that A. would be much more enthusiastic in trying to put it right (being the guy with the subject knowledge) than he seems to be WRT the above. --Kurt Shaped Box (talk) 23:17, 17 September 2009 (UTC)
- I went ahead and redirect it myself. Rest assured that if the stub creation (which obviously isn't being approved in this task) were to go awry I wouldn't hesitate to "delete all" first and then go and find the problem before starting over from scratch. --ThaddeusB (talk) 01:59, 18 September 2009 (UTC)
- I'd feel a little less concerned about all this if Abyssal had fixed those duplicate articles already. It's been a few days now since they were pointed out to him. Now, if the bot buggers up the current task, fixing it will be a simple matter of a few one-click reverts. However, if something goes wrong if/when the bot starts creating stubs and we end up with another Anybot-type mess, I'd hope that A. would be much more enthusiastic in trying to put it right (being the guy with the subject knowledge) than he seems to be WRT the above. --Kurt Shaped Box (talk) 23:17, 17 September 2009 (UTC)
My impression from following this discussion (and participating slightly) is that the bot operator is reasonably careful and conservative, and appreciates the concerns being raised in the aftermath of the AnyBot debacle. There is no reason to tar Thaddeus with that brush. So long as Thaddeus continues to bear in mind the concerns raised here, and works slowly, and works closely with Abyssal or someone else who has a solid grasp of the field, and is willing to put the brakes if and when problems and issues are raised by others, then I am not opposed to this going ahead. Hesperian 23:52, 17 September 2009 (UTC)
- I will certainly be cautious with this. I view myself as directly responsible for every edit my bots make & always proceed with caution. I always comb my bots' contributions and try to stamp out even the tiniest errors before releasing them on a larger scale. I assure everyone reading this that I most certainly will take any and all complaints about data integrity seriously.
- Furthermore, I am well aware the reputation of bots that produce content has been severely tarnished by Anybot. This is part of the reason I brought this minor task here to begin with. Sure, I could have just uploaded the tables manually and no one would have ever questioned it. However, I want accurate data and I want to start re-building the community's trust that bots can build content. Thus I came here. --ThaddeusB (talk) 01:52, 18 September 2009 (UTC)
--ThaddeusB (talk) 01:52, 18 September 2009 (UTC)
- Thank you. I still think we should run some more trials before going ahead, just to be safe. Abyssal (talk) 01:04, 18 September 2009 (UTC)
- I disagree with you, Hesperian. The attitude by ThaddeusB and Abyssal is: they are not responsible for the mistakes the bot makes. I was accused of being "passive aggressive" for failing to parent Abyssal through a correction of an article mistake he made. I don't think this is a team that will clean up after themselves.
- The correct response to the problem with the two articles, to show good faith effort toward dealing with future problems with bots, would have been for one of them to correct the articles immediately. But, no, it was more important to call someone names ("passive aggressive) than to make the encyclopedia accurate.
- There is no community support for this bot. ThaddeusB is weirdly trying to bully me into being the bot's monitor. If he can't get anyone to check the bot, and he is not able to, and Abyssal won't, and the community isn't interested, why should this bot go forward?
- The way to deal with someone who disagrees with something you want and to gain their support is to address their concerns, stay rigorously on target on the issue, and don't tell them they are "passive-aggressive," "throwing hissy fits," "mistaken about how wikipedia operates." All of these comments are personal issues about me. If they are more important than the data, maybe the data aren't that valuable or useful to the encyclopedia.
- ThaddeusB and Abyssal have established how they will act already: They will make personal accusations against people raising issues about the bot.
- This bot is a disaster in the making because of its operating team. That's my passive aggressive, mistaken-user, can't-raise-substantive-issues, hissy-fitting opinion. --69.225.3.119 (talk) 05:09, 18 September 2009 (UTC)
- If you don't have any concrete objections (and you have yet to offer any), and no actual evidence of how I'll address complaints, then this is just your personal opinion and nothing more. And if you look at my actual record with my actual bots, you will see that I do address actual complaints in a timely manner.
- No one is trying to force you to do anything, but you posted here and said you think the bot will screw up but offered no evidence. Of course I am going to respond to that by telling you to check the data if you think it'll mess up. I have personally already checked it & found it to be accurate, but that isn't good enough for you.
- Yet again, I can't respond to some theoretical eventual complaint until one actually surfaces. Yet again, do you have an actual complaint with the bot or is this just a philosophical objection and/or personal vendetta?
- P.S. Saying someone is mistaken about something isn't a "personal issue" and I take no responsibility for the other two comments, which I didn't make. --ThaddeusB (talk) 13:18, 18 September 2009 (UTC)
- The correct response to the problem with the two articles would have been to tell you to shut up and stay on topic, but I tried to be more diplomatic. I said part of the reason your problems with edits I made (that are irrelevant to ContentCreationBOT's approval) were not addressed is because I get busy and sometimes forget about messages left on my talk page. Further, I said, if you had problems with me not addressing those issues, all you had to do was remind me about them on my talk page. Instead you waited weeks and weeks and only bought the subject up when you could use it to beat me over the head in an unrelated discussion, namely, this one. "Name-calling" or not, I stand by my description of your actions as "passive agressive."
- I have little reason to believe that you raised the issue out of legitimate concern because even after you expressed the complaint you were not very helpful in the matter of getting your own problems addressed. No progress was made towards resolving your own issues until Kurt Shaped Box stepped in. Not that any of this matters, because this is the ContentCreationBOT request for approval discussion page, not the "whine about Abyssal making an error that wasn't even entirely his own fault in a tiny article on an obscure genus prehistoric fish" discussion page.
- There is no community support for this bot? What? Who should we be asking? The guy who started the List of graptolites? That was me. What about its chief contributor? Me, again. List of prehistoric starfish? That's me as well. List of prehistoric barnacles? Another one by me. Crap! List of crinoid genera? Uh oh, it looks like a pattern is emerging. Turns out I'm both the creator and sole major contributor to every single page that the bot is slated to edit. Every. single. one. If you can find another major contributor to the articles, please do invite them to see if we can form a consensus.
- Thad trying to bully you into monitoring the bot? Come on. You claim to be an invertebrate paleontologist and you're on a website based around volunteering to edit encyclopedia articles. So, when we come here with a plan to add a lot of information to encyclopedia articles on prehistoric invertebrates, and then you oppose the addition of information to articles in your field complain that no would be monitoring the data, it's only natural that we stare at you in disbelief. Regarding my willingness to fact-check, considering that I've explicitly called for more fact checking and testing before we proceed with the bot, even though we've both performed successful tests and received tentative approval from another member, your claim that I'm unwilling to check the data rings very hollow.
- I'd love to "rigorously" stay on topic, but someone keeps raising issues about stub creation and something to do with a typo in the title of an article I created about a prehistoric fish no one has ever heard of. I'd love to address your very serious objections, but for the life of me I can't remember them. I remember a complaint about a lack of consensus, but when I pointed out that I was the only one who contributed any meaningful content to the articles the bot would edit, and that I both supported and actively solicited the creation of the bot, you ignored me. Other than that, all I remember is a long series of complaints that we weren't taking your complaints seriously enough.
I see no issues with this bots proposed work, and all the legitimate issues raised have been addressed. Unless the anon IP wishes to raise a useful objection that has to do with this specific bot approval request, I don't see any further issues which need to be addressed. I'm in favor of approving the bot as it currently stands for this test run on the 13 lists given above (and perhaps the additional ones listed below if they are similar enough and the source database contains information which could be added to them). ···日本穣? · 投稿 · Talk to Nihonjoe 14:18, 23 September 2009 (UTC)
- I've raised issues, and ThaddeusB and Abyssal have played word games and delivered personal insults and criticisms against me as a person. If this is the response to issues before it's running, this is, imo, how they'll respond when it's running: insult the person who raises the issue (personal attacks), play word games (wikilawyering), insult the level of wikipedia knowledge of the person raising the issue (biting the newbie--although I'm not new), and demand that if someone has a problem with the data they should devote their wiki career to monitoring the bot's input.
- No. That's my opinion. --69.225.3.119 (talk) 22:45, 23 September 2009 (UTC)
- You have absolutely refused to make any concrete objection that can be addressed. Instead you merely repeat the same line over and over about this bot will obviously screw up because Abyssal and I are bad people.
- According to your own words, you have the ability to provide expert advice on the material. Your advice on the data would be appreciated, but apparently all you want to do is criticize others and offer nothing. It's a shame that you want to play petty games ("they tried to bully me into helping, so I won't help") rather than helping to improve Wikipedia. --ThaddeusB (talk) 23:39, 23 September 2009 (UTC)
- I see that despite your fervent insistence that this proposal not go forward, Mr. IP, that my challenge for you to remind us of just one of your many very informed and serious objections continues to go unanswered. Abyssal (talk) 00:11, 24 September 2009 (UTC)
- Given the work generated for volunteers and the risks to Wikipedia's credibility when these bots go badly wrong, in my view there should be almost a standard of proof applied to bots wishing to undertake such work. If it is met, fine, then it goes ahead. But it appears one is not being applied (note I am not blaming present parties for this, I am blaming BAG for making themselves the sole arbiters and granters of such things then failing to take responsibility). This is quite dangerous given the scale of the Anybot fiasco, and some others I have seen at times where semi-automated accounts and bots have gone on mass creation sprees which have had to be deleted. Is it possible to generate a dataset or even a list with the bot (as in, not articles) with all data to be included that some appropriate person with the requisite knowledge can check, and if we can do say 500 or 1,000 of those and they basically work fine then go create the articles as per the original plan. That way we get the articles but they're credible at the end of the process. I believe Abyssal is acting in good faith, the problem is not that but the lack of a checking process by people who know the content area or a meaningful approval process - even I wouldn't feel comfortable applying under such circumstances. Orderinchaos 02:04, 24 September 2009 (UTC)
- I see that despite your fervent insistence that this proposal not go forward, Mr. IP, that my challenge for you to remind us of just one of your many very informed and serious objections continues to go unanswered. Abyssal (talk) 00:11, 24 September 2009 (UTC)
Code review
ThaddeusB asked me for a code review, so here it is. Not much to mention, really:
- The error checking could use some work. You properly check for HTTP errors, but for API errors in the initial page query
or for json decoding errors (i.e. a truncated response)(never mind, from_json just dies on error). - $timestamp2 will not have a value unless you run into a maxlag error when querying the edit token (check rvprop in the first query). That would probably give an error in the action=edit request.
- Will it output a period such as "Mid Ashgill to Mid Ashgill"? If so, wouldn't that be better as just "Mid Ashgill"?
- It looks like it will screw up the location field if the last entry is not a one-word location name; that may be left over from changing from plain text to a bulleted list. Should the <br /> and the substr($line, 0, -4); line just be removed?
- I note that the bot will wipe out whatever content is currently in the tables, even those marked "NoData". This may not matter, as I don't know whether there is any such content currently in the tables for those entries. It also seems that it will die if any of the tables contains a genus not in the database, which is an appropriately safe failure mode.
Anomie⚔ 16:41, 13 September 2009 (UTC)
- Thank for the help. I fixed all the errors. The "Mid Ashgill to Mid Ashgill" thing was something I meant to correct, but apparently forgot to do. The location thing was indeed left over from changing to a bulleted list. All of the tables are currently blank, so overwriting them isn't an issue. If I needed to rerun the task for some unforeseen reason I'd change the code to be more cautious at that time. --ThaddeusB (talk) 02:55, 15 September 2009 (UTC)
- Not a programmer, so I can't say much, but thanks for reviewing the code. Also, the "Ashgill to Ashgill" thing has been bothering me, too. Is it possible to to remove the duplicate? Abyssal (talk) 15:14, 14 September 2009 (UTC)
Additional pages
The bot may also be useful on the following pages:
- List of acanthodians
- List of placoderms
- List of sarcopterygians
- List of prehistoric octocorals
- List of prehistoric medusozoans
- List of xiphosurans
- List of eurypterids
These pages would work well with the bot if put into the table format:
- List of prehistoric cartilaginous fish
- List of prehistoric jawless fish
- List of prehistoric amphibians
Abyssal (talk) 16:37, 17 September 2009 (UTC)
Trial?
Is this ready for a trial? Mr.Z-man 00:43, 24 September 2009 (UTC)
- So, this is a 100% dismissal of all objections to the bot? Why? --69.225.3.119 (talk) 01:04, 24 September 2009 (UTC)
- Oh, so this is what your bad faith-filled tirade on my talk page and the village pump is about. No, its a request for someone to summarize the huge amount of text above. If it was a dismissal of concerns, I probably would have actually done something other than ask a simple question. Mr.Z-man 01:45, 24 September 2009 (UTC)
- No, no, it's a hissy fit, not a tirade. And, if you had read the discussion you would have known that.
- You asked elsewhere if there was a summary for another bot. Here, you don't ask for a summary, you ask if it's ready for trial. This implies that the next step is a trial. --69.225.3.119 (talk) 01:54, 24 September 2009 (UTC)
- My apologies for not being perfectly consistent. That's what you get with unpaid labor. Mr.Z-man 01:59, 24 September 2009 (UTC)
- Sorry, for the bold, but I want to point out that successful trials have already been run. A link to the results of the test are here. Abyssal (talk) 15:10, 24 September 2009 (UTC)
- My apologies for not being perfectly consistent. That's what you get with unpaid labor. Mr.Z-man 01:59, 24 September 2009 (UTC)
- It would seem from reading the text that it is not yet ready for a trial. Orderinchaos 01:56, 24 September 2009 (UTC)
- On what basis? I will be happy to address any actual concerns but the only objection to date is 69.225's philosophical objection that 1) bots shouldn't do this sort of task unless every scrap of data is pre-approved and 2) I am a bad person who won't address concerns when they are raised. --ThaddeusB (talk) 02:00, 24 September 2009 (UTC)
- I raised issues. I think that bots should be used for content creation. You missed my anybot arguments. I was the editor in support of bots being used for content creation. I think User:Hesperian was against it. And, ThaddeusB, I think you're the one telling me I'm having hissy fits, I'm passive-aggressive, and now this ridiculous comment. You can continue to ignore all of my issues and call them invalid. But, my issues stand. --69.225.3.119 (talk) 02:15, 24 September 2009 (UTC)
- I obviously am too stupid to get your objections because I have told you 10 times I don't see any that aren't "there is no consensus" or "you must check every fact manually" (neither of which I can address because they are both your opinion only). I have requested be specific 10 times and you have ignored me 10 times, so who exactly is ignoring who? Oh and for the record a didn't make a single one of those comments you attributed to me, so I would appreciate it if you strike that part of the comment. --ThaddeusB (talk) 02:24, 24 September 2009 (UTC)
- Yes, of course, if I say something is a problem, and you say it ain't, it must not be an issue. Oh, I'm sorry, are they Abyssal's comments? Well, still, you're an administrator, you've approved this discussion being held while one party is being personally attacked. So, no, I won't strike it. I will render a correction: the personal attacks and insults are above. They were issued by Abyssal without any desire to see them stricken by this administrator.
- Call my issues what you want. Dismiss them. Allow others to call me names. I raised objections. You still choose to ignore them. If you choose to ignore my issues and then claim I'm ignoring you, that's just a game. I will continue to not play your game, while you dismiss my issues. No community consensus. Bot operator aggressively ignoring issues, encouraging personal attacks. --69.225.3.119 (talk) 02:29, 24 September 2009 (UTC)
- Yes, I ignored Abyssal's personal comments. That doesn't mean I approved of them. I also ignored various personal comments you directed at me and Abyssal. That doesn't mean I approved of them either. --ThaddeusB (talk) 02:40, 24 September 2009 (UTC)
- Please also note, that while some of the things I've said were a bit uncivil, and maybe even in poor taste, I only said them after the anonymous IP had displayed a pattern of rudeness and condescension both here and on my talk page that potentially stretched back months. I would hereby like to apologize for anything inappropriate I've said thusfar. Abyssal (talk) 15:23, 24 September 2009 (UTC)
- Yes, I ignored Abyssal's personal comments. That doesn't mean I approved of them. I also ignored various personal comments you directed at me and Abyssal. That doesn't mean I approved of them either. --ThaddeusB (talk) 02:40, 24 September 2009 (UTC)
- I obviously am too stupid to get your objections because I have told you 10 times I don't see any that aren't "there is no consensus" or "you must check every fact manually" (neither of which I can address because they are both your opinion only). I have requested be specific 10 times and you have ignored me 10 times, so who exactly is ignoring who? Oh and for the record a didn't make a single one of those comments you attributed to me, so I would appreciate it if you strike that part of the comment. --ThaddeusB (talk) 02:24, 24 September 2009 (UTC)
- I raised issues. I think that bots should be used for content creation. You missed my anybot arguments. I was the editor in support of bots being used for content creation. I think User:Hesperian was against it. And, ThaddeusB, I think you're the one telling me I'm having hissy fits, I'm passive-aggressive, and now this ridiculous comment. You can continue to ignore all of my issues and call them invalid. But, my issues stand. --69.225.3.119 (talk) 02:15, 24 September 2009 (UTC)
- On what basis? I will be happy to address any actual concerns but the only objection to date is 69.225's philosophical objection that 1) bots shouldn't do this sort of task unless every scrap of data is pre-approved and 2) I am a bad person who won't address concerns when they are raised. --ThaddeusB (talk) 02:00, 24 September 2009 (UTC)
- Oh, so this is what your bad faith-filled tirade on my talk page and the village pump is about. No, its a request for someone to summarize the huge amount of text above. If it was a dismissal of concerns, I probably would have actually done something other than ask a simple question. Mr.Z-man 01:45, 24 September 2009 (UTC)
Ive reviewed the discussion and the anon's complaints are for the most part invalid. the only issue that I see is limited input from the affected wikiprojects. something that we cannot force, the only thing I can suggest is make a post to ANI and see if that brings in a wider group for input. otherwise I thing a small trial would be useful. βcommand 02:05, 24 September 2009 (UTC)
- My issues are valid. If you can only claim they aren't without naming them and identifying their invalidity, just to parrot Thaddeus, you haven't increased the support for this bot. It doesn't matter if the projects don't support it. Fact is, Thaddeus hasn't gotten anyone who supports the creation of data in paleontology tables. --69.225.3.119 (talk) 02:15, 24 September 2009 (UTC)
- Ok let me explain the facts to you since you obviously ignored everyone elses comments. The information in question is coming from a very reliable source. The bot operator is not creating articles, just expanding a few lists. The operator has spot checked and confirmed that the data in question is reliable. there are several other uses who work in related areas have confirmed that the information is correct, and the programming of the bot is accurate so that there will be no issues with the imported information. The only real complaint that I see left is the fact that you did not like what anybot's method of operation. on that point we agree. this bot however will not be creating articles but rather filling in tables from a reliable database on existing articles. Please stop trying to raise the drama level. if you have any issues that have not been addressed the best method is a numbered list with a short explanation. βcommand 02:26, 24 September 2009 (UTC)
- No, I didn't ignore it, and others won't get it either because the credits for the information are incorrect. I understand the bot is putting data into lists (thanks for not reading my comments, but saying you've read everyone else's instead). The bot operator is not a vertebrate paleontologist. He hasn't confirmed the reliability of the data. What other users have confirmed? The ultimate purpose of "ContentCreationBot" is to create content.
The drama level? Ignored, called names, personally attacked gets drama. Don't issue personal attacks, don't dismiss my legitimate complaints. No drama. And, stay on target. That helps no drama also. --69.225.3.119 (talk) 02:32, 24 September 2009 (UTC)
- I see no proof other than your word that your anything more than a 13 year old child who is attempting to make a point by forum shopping, leaving uncivil comments, and attacking others. The information that the bot is adding is reliable. you have yet to prove otherwise. So unless you can actually make a logical statement and prove that the content and database the bot will be using is wrong (besides a few typos) I see no reason for your behavior. βcommand 02:39, 24 September 2009 (UTC)
- Ahem! Enough, Betacommand! You've been warned about this before. This is not the way for you to interact with people. Stick to the actual 'bot issue at hand (Goodness knows! There's been enough diversion from the core focus of the discussion, already.), and do not give us your guesses about who participants in the discussion may be. Uncle G (talk) 03:43, 24 September 2009 (UTC)
- I am not asking for approval to create stubs at this time, so the bot's "ultimate purpose" is irrelevant to this BRFA. --ThaddeusB (talk) 02:38, 24 September 2009 (UTC)
- I see no proof other than your word that your anything more than a 13 year old child who is attempting to make a point by forum shopping, leaving uncivil comments, and attacking others. The information that the bot is adding is reliable. you have yet to prove otherwise. So unless you can actually make a logical statement and prove that the content and database the bot will be using is wrong (besides a few typos) I see no reason for your behavior. βcommand 02:39, 24 September 2009 (UTC)
- No, I didn't ignore it, and others won't get it either because the credits for the information are incorrect. I understand the bot is putting data into lists (thanks for not reading my comments, but saying you've read everyone else's instead). The bot operator is not a vertebrate paleontologist. He hasn't confirmed the reliability of the data. What other users have confirmed? The ultimate purpose of "ContentCreationBot" is to create content.
- Ok let me explain the facts to you since you obviously ignored everyone elses comments. The information in question is coming from a very reliable source. The bot operator is not creating articles, just expanding a few lists. The operator has spot checked and confirmed that the data in question is reliable. there are several other uses who work in related areas have confirmed that the information is correct, and the programming of the bot is accurate so that there will be no issues with the imported information. The only real complaint that I see left is the fact that you did not like what anybot's method of operation. on that point we agree. this bot however will not be creating articles but rather filling in tables from a reliable database on existing articles. Please stop trying to raise the drama level. if you have any issues that have not been addressed the best method is a numbered list with a short explanation. βcommand 02:26, 24 September 2009 (UTC)
Doesn't matter, since I'm a hissy-fitting, drama mongoring, passive-aggressive 13-year-old. I suggest you now delete all the anybot articles I saved, because you don't really want a hissy-fitting, drama mongoring, passive-aggressive, 13-year-old writing articles. That's a good one, though, since I'm 13 I'm incompetent. I missed the age limit earlier. My bad. --69.225.3.119 (talk) 02:46, 24 September 2009 (UTC)
- No one has criticized or doubted the quality of your work outside the BRFA or how valuable you are to Wikipedia as an editor. My issues, and so far every issue I've seen raised against you has regarded your conduct here. Please stop trying to play the victim here. Abyssal (talk) 15:17, 24 September 2009 (UTC)
No need for approval
A "bot" that runs one time only on 23 pages is not distinguishable from a human editor and does not require approval. In fact, you could generate the content for the 23 pages on your local computer and then save them by hand using your usual account. So there is not really need for a discussion here at all. Just do the edits, and then discuss them on the talk pages of the articles involved like you would discuss any other edits. — Carl (CBM · talk) 02:54, 24 September 2009 (UTC)
- Nonetheless, ThaddeusB should be applauded for seeking approval anyway, so that experts can review the data sources, and we don't repeat history. Learning from history, and acting upon that learning, is a good thing. In all of the above, it seems that none of the self-declared subject experts have provided the necessary evaluation of the data source. Uncle G (talk) 03:33, 24 September 2009 (UTC)
- I agree with both comments here. The actual edits could very well be made by a human; it may have even been easier to leave a note on a few WikiProject's talk pages and discuss it there, but no matter. This will have to do as an alternative outlet for discussion about the task. Easily noticed by reading the discussion above is the fact that this has morphed into less of a conversation about the actual edits the bot will make, and more of an unconstructive argument between various parties. I just hope we can return to discussing the task itself. Regards, The Earwig (Talk | Contribs) 03:54, 24 September 2009 (UTC)
- That's the issue. When we are talking about 23 edits total, which is the current scope of this request, there is nothing for BAG to review. The edits themselves can be reviewed so easily that its counterproductive to spend too long trying to do a technical review of the code. Moreover, this forum is not ideal for discussion of content issues, as the discussion above painfully highlights. A discussion on a wikiproject page would be much more likely to be productive. BAG is not intended to review the quality of data sources. — Carl (CBM · talk) 10:46, 24 September 2009 (UTC)
- I agree with both comments here. The actual edits could very well be made by a human; it may have even been easier to leave a note on a few WikiProject's talk pages and discuss it there, but no matter. This will have to do as an alternative outlet for discussion about the task. Easily noticed by reading the discussion above is the fact that this has morphed into less of a conversation about the actual edits the bot will make, and more of an unconstructive argument between various parties. I just hope we can return to discussing the task itself. Regards, The Earwig (Talk | Contribs) 03:54, 24 September 2009 (UTC)
- Please not that I have said on several occasions that I was aware approval wasn't actually required. The reason I sought approval was to make it explicit where the content came from (I bot pulling RS data). I could have just done the actual edits manually and avoid the drama. In retrospect, maybe that would have been best. However, I will say this process has resulted in some improvements to the output, so it wasn't a total waste. --ThaddeusB (talk) 12:58, 24 September 2009 (UTC)
Note: I will be modifying the code to fix the problem outlined here. I thank 69.255 for pointing out this error, and kindly ask him/her to restrict future comments to indicate specific problems that can be addressed. --ThaddeusB (talk) 01:04, 25 September 2009 (UTC)
- For the record, here is my reply to the issue which the IP reverted as "taunting" --ThaddeusB (talk) 15:24, 25 September 2009 (UTC)
- Could you explain, in layman's terms, how that error occurred? Is this a widespread problem, affecting a significant percentage of the trial run output? If so, I suggest that a fresh trial run be carried out following the fix. I'm not going to comment on the drama that occurred over the last day or so, of which I was completely oblivious to until now - save to say that we should probably just attempt to put it in the past and move on from it. --Kurt Shaped Box (talk) 02:04, 25 September 2009 (UTC)
- The bot fills the "Age" column based on the fossil record information returned by Paleodb. In this case, the fossil record says 14ma to 4ma; however, the genus is actually extant and thus obviously the fossil record is insufficient. Since over 90% of the db is extinct, this particular problem should be quite rare. However, it does raise a question about the accuracy of using the fossil record in general.
- I used the fossil record to estimate ages because I feel this is, in general, the best estimate available. However, the fossil record is very much incomplete (and paleo's db is far from a complete record of the known fossil record either) - a fact which is not obvious to the casual observer. As such, I will address this concern via the following adjustments:
- Any genus that is extant will get "present" as the end date regardless of the fossil record
- The column will be renamed to "estimated time period" (or alternate upon suggestion)
- A footnote disclaimer will be added to state the estimates are based off the fossil record, which by nature makes them imperfect.
- I am also open to suggestions about alternative sources for age range estimates.
- Once the code is adjusted, I will re-upload the demo page. (I suggest every one use this terminology to describe that page, as it isn't a "trial" in the BAg sense of the word.) --ThaddeusB (talk) 03:00, 25 September 2009 (UTC)
- There is no significant percentage of the output. There are only 23 pages, so even 100% would be an insignificant percentage. That's why the whole idea of "trial runs" is flawed in this case. — Carl (CBM · talk) 02:25, 25 September 2009 (UTC)
- You may have missed it, but in the original requested (way up there somewhere :)) I suggested having the bot fill in only a small percentage of each table for the trial rather than the normal "X pages" approach. --ThaddeusB (talk) 03:00, 25 September 2009 (UTC)
- As long as it fits with the size limits, the size of the edit really isn't the issue. A "trial" is warranted when the bot is going to make a lot of actions, so that it would be painful to have to undo them all. The expectation is that the bot operator will carefully review every edit in the trial to make sure there are no technical problems. The size of the edits during the trial is entirely up to the bot operator. The difficulty here is that this project, regardless of any other merits it might have, simply doesn't fit into the framework for approving bots. — Carl (CBM · talk) 10:55, 25 September 2009 (UTC)
- I am well aware of the "rules", including WP:IAR. I thought it would be beneficial to get approval for the bot, even though none was technically required, as thus I filled the request. Can we please stop the wikilawyering now? --ThaddeusB (talk) 15:24, 25 September 2009 (UTC)
- I'm saying there are more appropriate forms of review than BAG for this task (for example, the talk pages of the articles involved, or a wikiproject page). As you say below, you are not even looking for a bot flag — so why create a "bot" account, for a task that has none of the attributes of a bot? I wanted to bring up this point in case other people see this nomination and mistakenly think it represents our best practice for when to ask for bot approval. — Carl (CBM · talk) 02:20, 26 September 2009 (UTC)
- Fair enough, thanks for clarifying. --ThaddeusB (talk) 03:05, 26 September 2009 (UTC)
- I'm saying there are more appropriate forms of review than BAG for this task (for example, the talk pages of the articles involved, or a wikiproject page). As you say below, you are not even looking for a bot flag — so why create a "bot" account, for a task that has none of the attributes of a bot? I wanted to bring up this point in case other people see this nomination and mistakenly think it represents our best practice for when to ask for bot approval. — Carl (CBM · talk) 02:20, 26 September 2009 (UTC)
Chaunax
69.225.5.4 directs my attention to the original version of the article Chaunax, posted by Abyssal back in May. I must say I find this a disappointingly poor effort at a cookie-cutter stub. Problems include
- Unsubstituted {{pagename}} templates;
- Omission of class, order and family from the taxobox;
- Specifying (but leaving blank) taxobox parameters that are inappropriate for a genus article, such as "binomial";
- The absense of a fossil range, a piece of information that I would have thought was critical to the decision to post a stub like this;
- The incorrect claim that it is extinct;
- The redundancy of referring to it as both "extinct" and "prehistoric" in the same sentence. "Prehistoric" implies "extinct"; extant genera that are present in the fossil record are never referred to as prehistoric.
- The absence of references.
Naturally the false claim that the genus is extinct is the biggest problem.
This sums up the problem with content creation bots. (1) They introduce errors; and (2) even when they don't introduce errors, they produce clunky, incomplete, redundant articles that utterly fail to communicate in an interesting or informative manner.
I don't want to beat a straw man here; but it does seem reasonable to assume that the purpose of ContentCreationBOT is to enable the creation of these dreadful cookie-cutter stubs on a grand scale. Am I wrong? If so, what steps have or will be taken to ensure that the content produced is more useful than the example above?
Hesperian 12:16, 25 September 2009 (UTC)
- Thad and I have prepared at least a tentative template that is much more thorough than my "cookie cutter stubs." Further input and ideas are appreciated.
- The possibility of introducing inaccurate claims to Wikipedia is a real one, and could come from two sources. 1, faulty information in the database and 2, the bot mishandling the data. Source one is unlikely, since the database is maintained by experts. Source two is preventable and is the reason we'll have to do test runs. We recognize the possibility of things going very much awry, and we have always intended to proceed cautiously. It's one of the reasons we decided to try the data-table filling process- to prove the bot could handle the data properly.
- I don't claim to have made good stubs, but surely you wouldn't suggest that a very short "substub" is worse than having no article at all? If all the stub did was set up the basic framework for the article, then it still would justify their creation. Say you wanted to create the Chaunax article. First you'd have to go to another animal article, copy the taxobox, replace the data, etc. Then you'd have to find out the best stub template to use and add it. Then add the name, portal templates, links, etc. Let's just say that it takes three minutes of time to do that. Now, if every prehistoric fish was done manually, the community would have to spend three minutes for every article. Lets say I made 500 stubs the cookie-cutter way. Because I'm just copy-pasting, article creation time is instantaneous. Therefore, if I had created 500 practically instantaneously, I had saved the community the approximate 25 man-hours worth of work. It's the same idea with the bot. If the bot creates 5,000 stubs (which would all be much higher in quality than the one I made, see the template), the amount of work saved would be 250 man-hours even if all it had done was build the basic set-up of the article.
- I'm not going to respond to specific criticisms of the Chaunax article, not because they aren't valid (they were, although I'd still personally refer to extant ancient taxa as prehistoric), but because the bot-generated stubs will be so much better in quality than my "cookie cutter" types that they aren't really relevant.
- To answer your last question, we do intend to create large numbers of relatively high-quality stubs eventually however this particular discussion is supposed to be only about the data-table completion. We will start another Request for Approval when we feel that we're more prepared to handle the much larger task of stub-creation. Thanks for the input! Abyssal (talk) 15:51, 25 September 2009 (UTC)
- "I don't want to beat a straw man here" well that is exactly what you are doing.
- 1) The "horrible stub" wasn't created via any sort of automation but rather by hand by Abyssal
- 2) I am not asking for approval to create stubs at this time --ThaddeusB (talk) 15:26, 25 September 2009 (UTC)
- I did ask "Am I wrong? If so, what steps have or will be taken...?" You haven't answered that. Abyssal has, but the link he has provided, User:ThaddeusB/PAC template, fails to re-assure me.
Re (2), If I posted a request here that said "I am requesting permission to scratch my backside... but later I might want to deploy my bot to correct spelling errors... but right now I am only requesting permission to scratch my backside", I'm pretty sure discussion would centre on my proposal to deploy a bot to correct spelling errors. This is only natural. Hesperian 05:52, 26 September 2009 (UTC)
- Considering I am not asking for approval to make stubs, am not ready to make them, and if when\I am, I would most certainly have to post a new request to do so it is completely reasonable for me not to want to debate them here. --ThaddeusB (talk) 15:11, 26 September 2009 (UTC)
- I did ask "Am I wrong? If so, what steps have or will be taken...?" You haven't answered that. Abyssal has, but the link he has provided, User:ThaddeusB/PAC template, fails to re-assure me.
It's an example of how articles created by people without knowledge in the subject area aren't useful. I had corrected a few hundred of Abyssal's fish stubs, making them more useful by adding class, when I was interrupted by the Anybot mess. This article problem is relevant to this discussion because the article was added by Abyssal, who is strongly advocating for this bot and worked with ThaddeusB on creating the bot.
Adding 10,000 pieces of data to 23 pages is worse than not having the data, when those adding the data are not reading the database correctly (see Abyssal's sample "successful" upload above) and admit (above) they don't have the necessary expertise to read the database correctly. If wikipedia editors don't know if the data are correct, they do not belong on wikipedia for any amount of time. They do not belong uploaded by a bot or by a human.
As I said early on, until this bot has experts (whether paleontologists or wikipedia enthusiasts on the taxa) on board, its task is inappropriate. It is not supported by the community. The community is not asking for unvetted data to be uploaded. Abyssal and Thaddeus don't know the data, can't tell when it's incorrect, and they don't act quickly when they create articles that are incorrect. --69.225.5.4 (talk) 20:26, 25 September 2009 (UTC)
I think also that Abyssal's comment that the test run can prove the bot can handle the data correctly should be remarked upon, because, what the test run did was prove exactly my problem with this bot: it doesn't matter if the bot can handle the data correctly when there is no one available who can vet the data. --69.225.5.4 (talk) 20:37, 25 September 2009 (UTC)
- The fish articles aren't relevant, no matter how hard you insist that they are. You might as well choose any random project I've engaged in on Wikipedia. The fish articles will not reflect the quality of the created stubs because we are using a different template for the article design. They were not created by the same process that will be used here. We are not even supposed to be discussing the planned stub creation process here. Also your language is misleading. If you were just adding class information, that's not "correcting," that's just "adding."
- We can read the database just fine. It doesn't matter if we understand the content, it's just a matter of making sure the content added to article is the same as is in the database. If the generated article on Abyssalgenus says its a member of the Thadidae while the PBDB says it's a Kurtboxid, then we know an error has been made regardless as to whether we understand the basics of either taxon's anatomy/classification/lifestyle/etc. The only skills needed to ensure the validity of the final result is the ability to compare the data in the article to the data listed in the database, either the words will be exactly the same or an error will have occurred. Expertise is irrelevant.
- What do you mean, implying that the bot handled the data correctly? The bot didn't handle the data correctly, it failed to verify the "age range" information for Cryptoplax with the "basic information" data in the first tab. That mishandling was supposedly the basis of the complaint you raised yesterday on your talk page. It has nothing to do with mine or Thad's ability to read the database. Even as a non-programmer I can see an easy solution for this: use the Sepkoski age range data for extant species and the PBDB "age range" information solely for extinct taxa. Had we forseen that the problem would have never occurred, but you can't forsee everything which is why we ran the test in the first place. Abyssal (talk) 23:34, 25 September 2009 (UTC)
- You're the one who said you ran the trial to prove the bot can handle the data correctly, see your above post.
"It doesn't matter if we understand the content, it's just a matter of making sure the content added to article is the same as is in the database."
- Yes, it matters if you understand the content. You didn't, so you posted a "successful" trial that included wrong information. The information in the database was correct. It still is correct. It lists the species as Late Miocene to recent. --69.225.5.4 (talk) 00:08, 26 September 2009 (UTC)
- I thought you were going to stay on topic? I guess that was either an empty promise or you are completely incapable or unwilling to do so.
- At least a dozen times you have said Abyssal and I have admitted to having no knowledge about the subject. That is entirely 100% untrue. I have stated I am not an expert, but that is not the same thing as "having no clue." Abyssal has never said anything at all about not having knowledge of the subject and indeed he has contributed more to paleobiology on Wikipedia than nearly anyone else.
- Abyssal has created more than 1000 articles on prehistoric genus. You have to date found 3 that contained errors. Wow, a human with only a 99.97% accuracy rate must clearly be a complete fool who doesn't know a thing about the subject matter. Right?
- Every post you make is a half-truth or distortion of the facts. You repeatedly make insulting claims like I ignore all feedback, or that I asked for you to be blocked, that have absolutely no basis in fact. You claim to be an expert yet you refuse to provide a single concrete criticism until after 3 weeks of bickering and a block for being disruptive. You claim you want a bot to supply this data, but your actions say otherwise. Tell me, what is your real motivation here? If you want to help, than please do so. If you want to argue, than please go someplace else.
- I 100% absolutely want every shred of data produced by this bot to be accurate. I will listen to any concrete complaints you or anyone else has, and will fix any actual problems that are identified. However, your standard some magic human that can review 10000 items and instantly knew item 245 is an error is impossible to meet. There is not one person on the entire planet with the ability to do what you demand. Anybot was a horrible POS, but I had absolutely nothing to do with that, so please stop taking out your rightful hatred of that bot on me. --ThaddeusB (talk) 23:37, 25 September 2009 (UTC)
- Take the personal comments elsewhere, ThaddeusB. --69.225.5.4 (talk) 00:08, 26 September 2009 (UTC)
- LOL, your refusal to be truthful is directly relevant to this conversation. You can't just imply I'm incompetent, post outright lies about what I & Abyssal have said previously, claim I never listen to people, and ignore 90% of everything that is said and harp on the 10% that looks bad, and not expect me to comment on it. You hate the very idea of this bot (despite your claims to the contrary) and your actions make it quite clear you are interested only in derailing the bot, not in making it work correctly. --ThaddeusB (talk) 00:16, 26 September 2009 (UTC)
- Take the personal comments elsewhere, ThaddeusB. --69.225.5.4 (talk) 00:08, 26 September 2009 (UTC)
Note: after a productive conversation with 69.225, I have sent out requests for more expert input. --ThaddeusB (talk) 03:40, 26 September 2009 (UTC)
Let it drop
Considering you're only proposing to make 30-odd edits, which you're entirely capable of doing through your user account; and considering this request has been utterly derailed, for better or for worse; it seems to me that the best way forward for you is to let this request drop, and go ahead and produce these lists, if you still want to. If and when the time comes that you want to do something that actually requires approval, a fresh start to this approval process would be useful for everyone concerned. By that time you will have learned from the experience of posting these lists, and you'll go into the approval process knowing that some of us are still smarting from the last debacle, and need concrete reassurance. Hesperian 05:52, 26 September 2009 (UTC)
- I still think it is more appropriate to make bot edits under a bot account rather than hiding them under my own user name. If I had just put them under my own name to begin with, of course, none of this would have ever happened, but I really don't think that would have been better. For example, no one would have questioned anything and whatever errors that might have occured most likely would never have been caught. --ThaddeusB (talk) 15:05, 26 September 2009 (UTC)
- I agree with Thad. Despite the drama we did get feedback that saved us from very serious errors. Abyssal (talk) 16:16, 26 September 2009 (UTC)
- Don't "hide bot edits under your own name". Make human edits. There are only 30 of them. Hesperian 06:47, 27 September 2009 (UTC)
- I meant hide the fact that table was generated by a script - I didn't mean make the script upload them under my name. --ThaddeusB (talk) 16:25, 27 September 2009 (UTC)
- Don't "hide bot edits under your own name". Make human edits. There are only 30 of them. Hesperian 06:47, 27 September 2009 (UTC)
- There is no reason to worry about whether the content of a single edit is generated by a script or not. If the content of the edit is good, it doesn't matter if a script made it, and if the content is flawed, it also don't matter. I use a scripts somewhat often to create citation templates, for example, but there is no reason I need to indicate that in the edit summary. Indeed, it would even be valid in this case to let the script upload the content in your name, provided that you review the content yourself. — Carl (CBM · talk) 03:21, 30 September 2009 (UTC)
Bot flag?
Are you asking for a bot flag? There seems to be no need for one. --Apoc2400 (talk) 21:15, 25 September 2009 (UTC)
- If it doesn't get one, that is fine by me. --ThaddeusB (talk) 23:37, 25 September 2009 (UTC)
- FWIW, I would support a bot flag if one was given. I agree that one is not necessary for this test, however. ···日本穣? · 投稿 · Talk to Nihonjoe 06:46, 30 September 2009 (UTC)
Task approval
Let's just approve this task! It's a handful of edits, and its good that it's been through the process. Or approve a trial run of 25 edits... They can be reverted and re-run if there are any problems. Rich Farmbrough, 01:56, 13 October 2009 (UTC). {{BAGAssistanceNeeded}}
- It is currently stalled probably because of some issues that arose from expert input about one of the lists. It's only a handful of edits, but each edit is hundreds of lines in a table, for a total of thousands of lines of information.
- As there is an issue about the validity of the genera in the lists that should be addressed first, there's no point in pushing the bot operator to get the bot going to create data that will be mirrored and is incorrect.
- Which reminds me, I have to delete a made up organization from an article that shows up in 77 google hits, all wiki mirrors. It's much politer to not do this in the first place, meaning not create articles with faulty data to begin with, rather than go and correct them after the fact. There's no hurry here. --69.225.5.4 (talk) 04:53, 13 October 2009 (UTC)
- Fix the bug won't be difficult, but I haven't had a chance to do it yet because I've been busy with more pressing tasks. Once I've fixed it, I'll update here. --ThaddeusB (talk) 14:33, 13 October 2009 (UTC)
Note: Before we actually run this thin we'll have to recreate the table for the List of prehistoric barnacles. A user has insisted it be removed until it can be filled. Abyssal (talk) 03:58, 4 December 2009 (UTC)
- Starting next week, I'm on real-life vacation, so I should have a lot more on wiki time. I should be able to make the necessary changes to the bot, re-run the test, and seek appropriate input then. --ThaddeusB (talk) 04:20, 4 December 2009 (UTC)
- Awesome. Abyssal (talk) 04:35, 4 December 2009 (UTC)
{{OperatorAssistanceNeeded}} News? MBisanz talk 01:26, 3 January 2010 (UTC)
- I'll be expiring this soon if it isn't going to run. MBisanz talk 05:46, 10 January 2010 (UTC)
- I just returned to Wikipedia after an unexpected month long absence. Will look into fixing/re-running this within the next few days. --ThaddeusB (talk) 05:11, 15 January 2010 (UTC)
- Awesome. Ale_Jrbtalk 20:57, 17 January 2010 (UTC)
- THanks for the update. MBisanz talk 22:35, 29 January 2010 (UTC)
- If everything is all fixed up and ready to run, let's see a Approved for trial (5 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. when you get a chance. (X! · talk) · @860 · 19:38, 3 February 2010 (UTC)
- If everything is all fixed up and ready to run, let's see a
- I just returned to Wikipedia after an unexpected month long absence. Will look into fixing/re-running this within the next few days. --ThaddeusB (talk) 05:11, 15 January 2010 (UTC)
![]() A user has requested the attention of the operator. Once the operator has seen this message and replied, please deactivate this tag. (user notified) News? Josh Parris 06:33, 23 February 2010 (UTC)
A user has requested the attention of the operator. Once the operator has seen this message and replied, please deactivate this tag. (user notified) News? Josh Parris 06:33, 23 February 2010 (UTC)
- This BRFA has been open for far too long. I will expire this soon if the operator does not start the trial. — The Earwig (talk) 02:17, 4 March 2010 (UTC)
- Don't you think that's a bit unfair considering our original attempt to get this approved was obstructed by a troll for so long that the project pretty much lost steam? Abyssal (talk) 13:22, 4 March 2010 (UTC)
- Examining User_talk:ThaddeusB it appears the bot lied. Please wait while I try to raise the operator... Josh Parris 13:54, 4 March 2010 (UTC)
- Abyssal, actually, I do not think it's unfair. While the bot started out with some obstruction, keep in mind it has been in trial without any obstructive comments for over a month, and the operator has been active during that time. I don't see the problem with expiring it if the operator does not respond or start the trial. And by the way, Josh Parris, while the bot didn't notify ThaddeusB when you posted the operator assistance request, I had notified him three days earlier, so the operator has been sufficiently notified in my opinion. — The Earwig (talk) 02:50, 9 March 2010 (UTC)
- Examining User_talk:ThaddeusB it appears the bot lied. Please wait while I try to raise the operator... Josh Parris 13:54, 4 March 2010 (UTC)
- Don't you think that's a bit unfair considering our original attempt to get this approved was obstructed by a troll for so long that the project pretty much lost steam? Abyssal (talk) 13:22, 4 March 2010 (UTC)
No operator attention for a month. ![]() Request Expired. Josh Parris 03:00, 9 March 2010 (UTC)
Request Expired. Josh Parris 03:00, 9 March 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
Requests to add a task to an already-approved bot
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Withdrawn by operator.
Operator: Harej
Automatic or Manually assisted: Automatic
Programming language(s): PHP
Source code available: User:Full-date unlinking bot/code
Function overview: Removes links from dates.
Edit period(s): Continuous
Estimated number of pages affected:
Space Fully linked
date triplesDates with
punctuation errorsCategory 142 4 Portal 7,486 1,604 Total 7,628 1,608
Exclusion compliant (Y/N): Yes
Already has a bot flag (Y/N): Yes
Function details:' On Wikipedia:Full-date unlinking bot, a consensus was achieved that full dates (a month, a day, and a year) should not be linked to in articles unless they are germane to the articles themselves (for example, in articles on dates themselves). Now that the work – representing the first phase of automated delinking – is complete, I request bot approval to remove links of full dates, as defined previously in Wikipedia:Bots/Requests_for_approval/Full-date_unlinking_bot in category and portal space. The details of operation and exceptions are available on User:Full-date unlinking bot.
Requested by: Ohconfucius ¡digame! 14:54, 22 January 2010 (UTC)
- Addendum
New articles are created each month by editors who may be unaware of our linking protocols and policies. I would propose a monthly bot run, or to program the bot to patrol recent changes, particularly to delink dates of these recently created articles, and any other articles which may have been linked by editors unaware of our practices Ohconfucius ¡digame! 01:31, 30 January 2010 (UTC)struck as withdrawn.
Discussion
I ask for a stay on this because as of now, I have a script that relies on linked dates in the MFD archives. It's not a big deal and I'll strike this statement as soon as I fix it. @harej 03:19, 23 January 2010 (UTC)
- Thanks, Harej; however, I still support the principle of Ohconfucius's application. Tony (talk) 03:58, 30 January 2010 (UTC)
- Oppose. Bots cannot discern what users are or are not aware of. Rerunning the bot monthly is equivalent to deciding that full date linking is entirely forbidden. Jc3s5h (talk) 22:24, 7 February 2010 (UTC)
- But what about newly created articles? Ohconfucius ¡digame! 02:38, 8 February 2010 (UTC)
- Oppose. Bots cannot discern what users are or are not aware of. Rerunning the bot monthly is equivalent to deciding that full date linking is entirely forbidden. Jc3s5h (talk) 22:24, 7 February 2010 (UTC)
- If the proposal were reworded to confine itself to suitable classes of articles that really could be detected by a bot, such as new articles, I would not object. However, I would want to see the proposal thoroughly reworded so its approval would not be seen as a tacit approval to extend its reach into inappropriate areas. Jc3s5h (talk) 03:54, 8 February 2010 (UTC)
- In the interests of being able to start processing portal and category space, I have struck the addended request above. It appears that there is no opposition to the primary request. Can I ask for a speedy approval, please? Ohconfucius ¡digame! 02:53, 9 February 2010 (UTC)
- Speedy approval is only given out is special cases (e.g. an exact clone of an already approved and uncontroversial bot, interwiki bots etc). Date unlinking has proved controversial in the past, so a speed approval would be a bad idea imo. --Chris 11:42, 10 February 2010 (UTC)
- It may be true that delinking was once controversial, 'once' being the operative word here. The bot's first run did not generate any further noise, so the above comment probably reflects obsolete thinking, IMHO. This request has been open for nearly three weeks, so it's not all that speedy, by any standards. Ohconfucius ¡digame! 14:26, 10 February 2010 (UTC)
- Regardless of procedural details (i.e. "speedy approved" or not), what else is needed before the bot can be approved for this task? Dabomb87 (talk) 23:46, 10 February 2010 (UTC)
- It may be true that delinking was once controversial, 'once' being the operative word here. The bot's first run did not generate any further noise, so the above comment probably reflects obsolete thinking, IMHO. This request has been open for nearly three weeks, so it's not all that speedy, by any standards. Ohconfucius ¡digame! 14:26, 10 February 2010 (UTC)
- Speedy approval is only given out is special cases (e.g. an exact clone of an already approved and uncontroversial bot, interwiki bots etc). Date unlinking has proved controversial in the past, so a speed approval would be a bad idea imo. --Chris 11:42, 10 February 2010 (UTC)
![]() Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. — The Earwig @ 04:30, 20 February 2010 (UTC)
Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. — The Earwig @ 04:30, 20 February 2010 (UTC)
{{OperatorAssistanceNeeded|D}}Any updates? — The Earwig (talk) 02:00, 4 March 2010 (UTC)
To be totally honest I'm not interested in this. If someone else is interested in making the necessary code adjustments and then running the bot, let me know and I can hand over the password. harej 03:37, 5 March 2010 (UTC)
- Hm. I'll expire this in two weeks or so if no one is willing to take over. — The Earwig (talk) 18:28, 6 March 2010 (UTC)
![]() Withdrawn by operator. I have a feeling no one is going to take over this task. If you would like to run the bot, please contact harej. — The Earwig (talk) 03:28, 9 March 2010 (UTC)
Withdrawn by operator. I have a feeling no one is going to take over this task. If you would like to run the bot, please contact harej. — The Earwig (talk) 03:28, 9 March 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Josh Parris
Automatic or Manually assisted: Automatic
Programming language(s): Python
Source code available: https://svn.toolserver.org/svnroot/josh/redirects/
Function overview: Bypass redirects tagged {{R from incorrect name}}
Links to relevant discussions (where appropriate): Wikipedia:Redirects for discussion/Log/2010 January 4#American Broadcasting Corporation, Wikipedia:Bot requests/Archive 33#Need a Bot for a Job (missing, but can be seen at http://en.wikipedia.org/w/index.php?title=Wikipedia:Bot_requests/Archive_33&oldid=339120664 ), Wikipedia:Bot requests/Archive 33#Change "Financial crisis of 2007–2009" to "Financial crisis of 2007–2010", Wikipedia:Bots/Requests for approval/WildBot 2
Edit period(s): periodic, perhaps daily
Estimated number of pages affected: Initial run: there are about a thousand redirects in Category:Redirects from incorrect names, so many thousands of pages could be affected. Subsequent runs: dozens of pages, perhaps not even that many, depends on the rate of use of incorrect name redirects.
Exclusion compliant (Y/N): Y, standard in pywikipedia
Already has a bot flag (Y/N): Y
Function details: Every redirect in Category:Redirects from incorrect names will be evaluated for semantic correctness with 11 tests. For examples of the checks run, see User:Josh Parris/Redirects from incorrect names. Redirects that fail any test will not be processed.
Normally bypassing redirects is strongly discouraged by WP:NOTBROKEN, but in this case {{R from incorrect name}} places these redirects into Category:Redirects from incorrect names and also Category:Unprintworthy redirects; WP:NOTBROKEN expressly permits bypassing.
For redirects that are semantically clean, in any linking article the redirects will be replaced: [[redirectname#section|piped text]] will be changed to [[correctname#section|piped text]], where correctname is either supplied as a parameter to {{R from incorrect name}} or the redirect target. The presence of either #section or piped text is not necessary.
Discussion
![]() Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. will you publish the actual semantic tests? MBisanz talk 03:50, 24 January 2010 (UTC)
Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. will you publish the actual semantic tests? MBisanz talk 03:50, 24 January 2010 (UTC)
- Various versions of User:Josh Parris/Redirects from incorrect names in the page history contain in total all the tests, they are (the final test is done from two different perspectives):
- Page is not a redirect yet is in Category:Redirects from incorrect names
- Redirect is in Category:Redirects from incorrect names without a redirect template
- Redirect requires a capitalization template
- Redirect has a correct name parameter but that correct name isn't an article
- Redirects with a mismatch between the correct name and the redirect target - for example, the correct name is a redirect targeting a different article
- Redirect targets a #section, but don't use a template appropriate for redirects targeting a #section
- Redirect targets a #section, but don't use a template to specify the correct name
- Redirect is to a #section, but is missing correct name parameter
- Redirect targets a #section with a template, but the #section doesn't exist
- Redirect targets an #anchor that doesn't exist in the target article
- Once source code is available, you'll be able to inspect the evaluation routines. Josh Parris 08:06, 24 January 2010 (UTC)
![]() Doing... Apologies for the delay; I've been nursing WildBot's disambiguation activities and that's soaked up all the time I intended to devote to this. During development I discovered it's not uncommon for links to appear in {{main}} and variants, so if so no wikilinks can be found, the bot falls back to raw text substitution to deal with templates. I've also taken the liberty of not changing pages in talk or Wikipedia namespaces.
Doing... Apologies for the delay; I've been nursing WildBot's disambiguation activities and that's soaked up all the time I intended to devote to this. During development I discovered it's not uncommon for links to appear in {{main}} and variants, so if so no wikilinks can be found, the bot falls back to raw text substitution to deal with templates. I've also taken the liberty of not changing pages in talk or Wikipedia namespaces.
I paused WildBot's normal activity to perform the trial, to leave the trial edits in a contiguous lump, but the two runs have a substantial delay - this is the bot loading all thousand redirects and validating them. The second run is broken up by a bunch of API unavailability. I ensured that trial edits would include the redirects included in Wikipedia:Bots/Requests for approval/WildBot 2. I was expecting I'd have to do something tricky to ensure a good breadth of articles edited, but it turns out there aren't all that many links to these dodgy redirects. 30 Trial edits: http://en.wikipedia.org/w/index.php?title=Special:Contributions&offset=201002090515058&limit=30&target=WildBot - around this time I had to restart the bot, as it somehow lost its http connection. And kept losing it; I'm going to write a pile of recovery code given that a run takes about an hour.
Current status: 30/50 done. Josh Parris 06:23, 9 February 2010 (UTC)
![]() Trial complete. The final 20 edits are http://en.wikipedia.org/w/index.php?title=Special:Contributions&offset=20100209234825&limit=20&target=WildBot that recovery code really helps; it seems that perhaps pywikipedia has some difficulty in storing large pages without getting its knickers in a knot. Josh Parris 23:53, 9 February 2010 (UTC)
Trial complete. The final 20 edits are http://en.wikipedia.org/w/index.php?title=Special:Contributions&offset=20100209234825&limit=20&target=WildBot that recovery code really helps; it seems that perhaps pywikipedia has some difficulty in storing large pages without getting its knickers in a knot. Josh Parris 23:53, 9 February 2010 (UTC)
- The trial results look good, but is it really necessary to edit pages in the userspace? Many users keep database reports or personal backlogs in their userspaces, so a bot modifying this area of Wikipedia may cause trouble. — The Earwig @ 18:10, 10 February 2010 (UTC)
- I was hoping that by editing in userspace, incorrect names would be corrected before drafts became articles. Let's ignore the fact that the dump in question was very, very old (and, as such, wrong insofar as it stood when edited). The semantic behind {{R from incorrect name}} is that use of the incorrect name is wrong and ought to be corrected. Incorrect names are a dead end; they ought not be used. I can see two reasonable responses to the difficulty of userspace links: dogmatic insistence that they be changed, and permissive freedom to use Incorrect names in userspace; I'm leaning towards the former. As a personal backlog, assuming this is some kind of article-in-progress, the link ought to be fixed; database reports are grayer. Given how few uses of incorrect names there are, I'm willing to check each edit individually to ensure no existing userspace pages are adversely affected, revert and tag those that are, and let the bot run free in the future. Josh Parris 09:17, 11 February 2010 (UTC)
![]() Approved. — The Earwig @ 23:25, 14 February 2010 (UTC)
Approved. — The Earwig @ 23:25, 14 February 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Multichill
Automatic or Manually assisted: Automatic
Programming language(s): Python (pywikipedia)
Source code available: Simple script based on a sql query and pywikipedia
Function overview: Tag about 20.000 files with {{Nowcommons}}
Links to relevant discussions (where appropriate): Tagging images with {{Nowcommons}} happens all the time, just not to all images. This bot tries to clean that up.
Edit period(s): One big run, later smaller runs to clean up again.
Estimated number of pages affected: 20.000 pages in the file namespace
Exclusion compliant (Y/N): Y
Already has a bot flag (Y/N): Y
Function details: Files get transfered to Commons all the time, unfortunately often users forget to tag the file here with {{subst:ncd}}. Current backlog is about 20.000 files. I want to run a bot to tag these files. The bot will skip images tagged with {{NoCommons}}. I already did a test run with some Navy images. See the recent (deleted?) contributions. multichill (talk) 22:08, 19 January 2010 (UTC)
Discussion
Adding "NowCommons" to the relevant files would be a good help. It makes it much easyer to find the dupes. Multichill is very experienced and the task is rather simple so I see no reason not to say "Yes thank you". --MGA73 (talk) 19:21, 20 January 2010 (UTC)
{{BotTrial}} MBisanz talk 03:48, 24 January 2010 (UTC)
- {{BAGAssistanceNeeded}} He did an edit of 200 images I think. Check recent deleted contributions. :-) --MGA73 (talk) 10:03, 24 January 2010 (UTC)
- {{OperatorAssistanceNeeded}}. Hey multi-chill I see that you have done quite a bit of images. Next time try and keep it to what you were approved to do. I assume your trial is complete now? Tim1357 (talk) 16:54, 24 January 2010 (UTC)
- Trial complete. Dear Tim-1-3-5-7, I'm already approved for moving images to Commons. This request is about tagging 20.000 images with {{NowCommons}}. As MGA73 mentioned: Yes I did a test run on a bunch of Navy images, see the deleted contributions. multichill (talk) 17:12, 24 January 2010 (UTC)
- I see. Thats fine then. I cannot see deleted contributions, but from the ones that are live I think everything looks ok.
- {{OperatorAssistanceNeeded}}. Hey multi-chill I see that you have done quite a bit of images. Next time try and keep it to what you were approved to do. I assume your trial is complete now? Tim1357 (talk) 16:54, 24 January 2010 (UTC)
- {{BAGAssistanceNeeded}} He did an edit of 200 images I think. Check recent deleted contributions. :-) --MGA73 (talk) 10:03, 24 January 2010 (UTC)
![]() Approved. Tim1357 (talk) 19:09, 24 January 2010 (UTC)
Approved. Tim1357 (talk) 19:09, 24 January 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Magioladitis
Automatic or Manually assisted: Automatic, supervised
Programming language(s): AWB
Source code available: It's AWB auto-tagger. Code is available
Function overview: Auto-untagging of orphans / Auto(un)tagging for wikify, deadend, uncategorised and remove expand tags if articles are stubs.
Links to relevant discussions (where appropriate): Per my message in Wikipedia_talk:Orphan#AWB_and_Orphans, AWB in the past tagged a lot of articles as orphans incorrectly. The bug was found and fixed (version 5.0.0.1). Orphanage was a backlog and need help. See also my message in Wikipedia talk:WikiProject Orphanage.
Edit period(s): One time run
Estimated number of pages affected: It will run though 152,851 articles and affect minimum 4,000 according to my estimation based on a test run.
Exclusion compliant (Y/N): Y
Already has a bot flag (Y/N): Y
Function details:
I will run AWB with genfixes off. Only auto-tagger will be activated. This means that the only actions will be: Tagging and untagging with: {{wikify}}, {{deadend}}, {{uncategorised}} and removing {{orphan}} (if article proven not orphan), {{expand}} (if article is a stub -per expand's usage) and {{stub}} if article is not a stub. It will only run in the subcategories of Category:Orphaned articles and it will be one time run. Since the AWB' bug is fixed no more semi-automated edits will produce a bug.
I already did a test run as Magioladitis and no problems occurred. Following previous concerns about AWB and stubs I 'll check all edits that affected stub tags. AWB's Genfixes will be turned off.
In my intention is to run the procedure only once. I ll re-run it in case Wikipedia:WikiProject Orphanage asks me to. -- Magioladitis (talk) 23:56, 16 January 2010 (UTC)
Discussion
Can you explain how a bot can determine that an article needs to be wikified? --Jc3s5h (talk) 00:14, 17 January 2010 (UTC)
- The method AWB currently uses is that adds the {{wikify}} to articles that have less than 3 links or the number of links is less than 0.25% of article's size. As far as I know there were no complains of AWB incorrectly tagging articles with wikify. I f there are suggestions how the method can be improved I would like to read it. Moreover, I already have requested that AWB does only part of the auto-tagging by user's request. It's a good chance that this will be implemented at some point to enable us to have flexibility. -- Magioladitis (talk) 03:10, 17 January 2010 (UTC)
- Considering that the method you use specifically identifies a dead end article, it would be better to only use {{Dead end}}, because the Wikify template could be applied for several other reasons too (for example, a plain text article copied from some public domain source, with no Wiki markup at all). In the absence of any talk page discussion, the reader is left wondering why the Wikify template is there. --Jc3s5h (talk) 04:24, 17 January 2010 (UTC)
- AWB will add a {{deadend}} in the case the article has no links but I understand your concerns. Wikify is not only about links. I 'll discuss changes to the code with AWB team. -- Magioladitis (talk) 10:43, 17 January 2010 (UTC)
I can run a modified version of AWB that won't add/remove wikify. -- Magioladitis (talk) 23:42, 20 January 2010 (UTC)
On hold. Some hours ago I was reported that orphan tagging is misbehaving again. Probably due to API changes. I put this BRFA on hold until problem is solved. -- Magioladitis (talk) 17:26, 23 January 2010 (UTC) Resume. Bug fixed. More details in WP:AWB/B. -- Magioladitis (talk) 01:03, 24 January 2010 (UTC)
![]() Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. harej 00:54, 29 January 2010 (UTC)
Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. harej 00:54, 29 January 2010 (UTC)
![]() Trial complete. Yobot ran in Category:Orphaned articles from October 2006. It scanned 922 pages and made 50 edits.
Trial complete. Yobot ran in Category:Orphaned articles from October 2006. It scanned 922 pages and made 50 edits.
- In 47 cases it removed orphan tag only
- In 1 case it removed orphan tag and stub tags
- In 2 case it removed stub tags
- In 1 case it added deadend tag
Just to be in the safe side, I ran with AWB v. 5.0.0.1, rev6152, skipping in case a wikify tag was there or AWB was trying to add it. It skipped 14 pages for this reason.
Procedure started at 01:34, 29 January 2010 and finished at 02:01, 29 January 2010.
Some comments:
- I expect the proportion of article to be fixed to get bigger in articles with newer tags. More than 50% of the orphans were tagged in February 2009.
- I am not completely satisfied with the result because I would like to follow the strict definition of WP:ORPHAN and exclude from count dab pages. This can't be done with the current software.
-- Magioladitis (talk) 02:05, 29 January 2010 (UTC)
PS I did 21 more just to finish the category. -- Magioladitis (talk) 02:24, 29 January 2010 (UTC)
- Approved. ⇌ Jake Wartenberg 02:07, 4 February 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Withdrawn by operator.
SoxBot 20
Operator: X!
Automatic or Manually assisted: Automatic
Programming language(s): PHP
Source code available: Not yet, will release at some point
Function overview: Tag articles with {{orfud}} per WP:NFCC#7.
Links to relevant discussions (where appropriate): This was previously approved for BJBot (link).
Edit period(s): Daily
Estimated number of pages affected: Probably a couple hundred a day. (Rough estimate)
Exclusion compliant (Y/N): Y
Already has a bot flag (Y/N): Y
Function details: This bot will go through all the fair-use images uploaded to the wiki. For each one, it will:
- Check if it is indeed tagged with a fair use template
- Check if it is not used in any articles
- Check if it is not already tagged as orfud
If it satisfies those three requirements, it will put {{subst:orfud}} at the top or the image page.
Discussion
Bot appropriate task, the nature of the images being tagged and their not being in articles indicates community consensus. My only concern would be if someone is writing an article and just uploaded the image? Is there some time constraint on when the tagging will be done relative to the uploading? Competent and communicative bot operator, no other concerns with this bot or operator. --IP69.226.103.13 (talk) 20:23, 28 December 2009 (UTC)
- One question and one answer, IP69.226.103.13 ORFU has a mandatory waiting period between tagging and deletion so that will not be an issue. But does the bot check for image redirects and how the redirects are used? βcommand 01:01, 29 December 2009 (UTC)
- Thanks Betacommand. Looks good to me, then. --IP69.226.103.13 (talk) 01:20, 29 December 2009 (UTC)
- {{OperatorAssistanceNeeded}} For Beta's questions, also could you advertise this somewhere appropriate since these tasks tend to be contentious. MBisanz talk 10:16, 30 December 2009 (UTC)
- Really? Good catch, then. One more reason to get a little input before moving forward, as it would not have occurred to me that getting rid of orphaned fair use images would be contentious. Please link back to discussion here, as I am curious to follow. --IP69.226.103.13 19:20, 31 December 2009 (UTC)
- Yep, anything to do with fairuse images tends to be controversial and gets strict scrutiny from BAG. MBisanz talk 04:44, 1 January 2010 (UTC)
- Really? Good catch, then. One more reason to get a little input before moving forward, as it would not have occurred to me that getting rid of orphaned fair use images would be contentious. Please link back to discussion here, as I am curious to follow. --IP69.226.103.13 19:20, 31 December 2009 (UTC)
I've spammed WP:AN, WP:VPR, and WT:NFCC. Hopefully, that will suffice. (X! · talk) · @979 · 22:29, 1 January 2010 (UTC)
- The task is good but there as some tweaks to keep the ire down. Need a lag between an image's creation and checking if it is orphaned, otherwise people who press the upload button may, while editing the article to add the image shortly after, see the orange talk bar. Almost every image when just uploaded is orphaned—say 30-60 minutes ? Has anyone got thoughts on how to manage 10→7000 messages on one talkpage during a run ?. Avoiding this is going to involve more programming but I think is worth some time. Apart from those two points - this all looks good. - Peripitus (Talk) 23:25, 1 January 2010 (UTC)
- I'm going to have it wait a week after being uploaded to prevent this. (X! · talk) · @046 · 00:06, 2 January 2010 (UTC)
- Then I have no objections - just be prepared for rankled comments if the bot drops repeated messages on one user's page - Peripitus (Talk) 00:57, 2 January 2010 (UTC)
- A week is probably overkill, maybe 48 hours? But a week is fine. Let's wait for response from the pages you spammed, though. I have no problems with this bot in general, as I think the community has been fairly alerted and BAG members seem in the know and on top of the type of community concerns that may arise with this bot. --IP69.226.103.13 | Talk about me. 07:36, 2 January 2010 (UTC)
- Do you know roughly how many FU images are currently orphaned, and would be caught in the first run of the bot? Pushing the whole backlog into one day of Category:Orphaned non-free use Wikipedia files might be a bit overwhelming, and the backlog should maybe be chipped away more gradually. Not sure what's preferable though, maybe having the backlog where people can see it on-wiki is actually better. Amalthea 11:53, 2 January 2010 (UTC)
- If there are editors who routinely work from the category to clean it up, then their preferences as a group for how it is done should be considered, imo. --IP69.226.103.13 | Talk about me. 18:25, 2 January 2010 (UTC)
- MBisanz can probably be comment on that, I regularly see him cleaning out the category. He uses the Twinkle mass deletion tool, but I assume he'll manually checks history and usage of each image first. If the bot floods the category and we trust the bot to categorize them correctly, it wouldn't be hard to whip up a tool to go through the category and delete all those that were tagged by the bot, still have no incoming links (properly interpreting redirects), and have no changes in history or log of file and file description page since the tagging. Of course, such a tool would also need BAG approval. :) So again, a rough estimate how big the flood will be would be helpful. Amalthea 18:55, 2 January 2010 (UTC)
- If there are editors who routinely work from the category to clean it up, then their preferences as a group for how it is done should be considered, imo. --IP69.226.103.13 | Talk about me. 18:25, 2 January 2010 (UTC)
- Are you going to notify the initial uploader, i.e. not the uploader of the latest or last remaining revision (fair use reduce!), but the original uploader who created the file description page? ({{Di-orphaned fair use-notice}}) Amalthea 11:53, 2 January 2010 (UTC)
- At the moment, it notifies the original uploader. (X! · talk) · @257 · 05:10, 7 January 2010 (UTC)
- Got code? Amalthea 11:53, 2 January 2010 (UTC)
- I'll have to sanitize it first. (X! · talk) · @257 · 05:10, 7 January 2010 (UTC)
- Beta, I seem to remember that you previously ran a bot that notified article talk pages about pending deletion of unused images with FUR pointing to their article. What was the issue with that, simply the volume of the spamming and the comparatively few images that actually required action? Amalthea 11:53, 2 January 2010 (UTC)
- Then I have no objections - just be prepared for rankled comments if the bot drops repeated messages on one user's page - Peripitus (Talk) 00:57, 2 January 2010 (UTC)
- Amalthea, I usually look at the logs of User:ImageRemovalBot after doing CSD#F5 cleanouts to see which ones were wrongly deleted; this bot would be paired with the already approved User:Orphaned image deletion bot admin bot, which would clear out the category, and that does check to make sure the image is orphaned. I think BJweeks ran a bot similar to this that did go back everyday and make sure the image was still orphaned, but I'm not sure. Also, I don't remember how Beta's old program worked. MBisanz talk 01:18, 3 January 2010 (UTC)
- Ah, darn, I've read about User:Orphaned image deletion bot, backlog is not an issue then. Thanks, Amalthea 01:47, 3 January 2010 (UTC)
- I find it concerning if there is no human-in-the-loop at all in the deletion process. --Apoc2400 (talk) 15:56, 5 January 2010 (UTC)
- What role do you envisage a human playing? Josh Parris 16:08, 5 January 2010 (UTC)
- For example, checking that the image wasn't mistakingly removed from an article or removed by vandalism. --Apoc2400 (talk) 18:44, 5 January 2010 (UTC)
- Are there tools available to discover that? Josh Parris 21:56, 5 January 2010 (UTC)
- No, tools won't work on this, although from historical practice, admins at most check if an image is in current use, not if it was removed mistakenly, due to the sheer number of images that are orphaned at any given time. MBisanz talk 22:26, 5 January 2010 (UTC)
- Are there tools available to discover that? Josh Parris 21:56, 5 January 2010 (UTC)
- For example, checking that the image wasn't mistakingly removed from an article or removed by vandalism. --Apoc2400 (talk) 18:44, 5 January 2010 (UTC)
- What role do you envisage a human playing? Josh Parris 16:08, 5 January 2010 (UTC)
- I find it concerning if there is no human-in-the-loop at all in the deletion process. --Apoc2400 (talk) 15:56, 5 January 2010 (UTC)
We need to estimate how many pages will be tagged overall. Depending on that number, we should think about staggering the bot run so that only so many per day are tagged. — Carl (CBM · talk) 14:04, 6 January 2010 (UTC)
P.S. As I was looking into this I ran into a more serious issue with image redirects, see below. — Carl (CBM · talk) 14:19, 6 January 2010 (UTC)
- To answer my own question, there are just under 1000 unused images non-free images at the moment, and another ~700 that are only used via redirects. I would think that limiting the tagging to 100/day would keep the daily workload manageable and still get rid of any backlog pretty quickly. — Carl (CBM · talk) 14:33, 6 January 2010 (UTC)
Image redirects
Does the bot properly recognize image redirects? For example, the non-free image File:"A" stamp of the US, 1978.jpg is unused according to the regular user interface and according to the API [3], but it has a redirect from File:1743.jpg and that redirect is included as an image in Non-denominated postage [4]. So the bot needs to handle this sort of thing. I see it mentioned above but without any response about whether the code actuall handles it. Since the code is not released, I can't just look it up. — Carl (CBM · talk) 14:19, 6 January 2010 (UTC)
{kind=link}
![[3]](https://en.wikipedia.org/w/api.php?action=query&list=imageusage&iutitle=File:%22A%22%20stamp%20of%20the%20US,%201978.jpg){kind=link}
{kind=link}
![[4]](https://en.wikipedia.org/w/api.php?action=query&list=imageusage&iutitle=File:1743.jpg){kind=link}
- Hmm... image redirects was not in my consideration. I guess I have two courses of options: 1) Check for all redirects and get their usage, or 2) ignore images with redirects. The second is easier to program, yet the first is probably the better option. I think I'll end up programming in the first one, but it won't end up being programmed in until late next week due to IRL stuff. (X! · talk) · @258 · 05:12, 7 January 2010 (UTC)
- If you have a toolserver account, here is the code I used to get the counts. It's much easier to let the database make the subqueries for you. — Carl (CBM · talk) 13:20, 8 January 2010 (UTC)
create temporary table u_cbm.foo ( f_title varchar(255) );
insert into u_cbm.foo
select ip.page_title
from page as ip
join categorylinks on ip.page_id = cl_from and cl_to = 'All_non-free_media'
left join imagelinks on il_to = ip.page_title
where page_namespace = 6 and isnull(il_from);
select f_title as y from u_cbm.foo as xx
where not exists
(select 1
from page as rp
join redirect on rp.page_id = rd_from and rd_namespace = 6
join imagelinks on il_to = rp.page_title
where rd_title = xx.f_title);
- Just an idea. Would it not be nice if a bot changed "links" to images so it used the actual image and not the redirect (redirects could then be deleted)? I can imagine it would be a help to more than just this one bot here? --MGA73 (talk) 19:33, 21 January 2010 (UTC)
![]() Withdrawn by operator. I simply don't have enough time in real life to dedicate the hard work necessary into this bot. (X! · talk) · @299 · 06:11, 25 January 2010 (UTC)
Withdrawn by operator. I simply don't have enough time in real life to dedicate the hard work necessary into this bot. (X! · talk) · @299 · 06:11, 25 January 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
Bots in a trial period
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Withdrawn by operator.
Operator: Tim1357
Automatic or Manually assisted: Automatic
Programming language(s): Python (pywikipedia)
Source code available: I use basic.py, and some regex
Function overview: add {{Ibid}} to reference sections on articles that use <ref>Ibid.</ref>, <ref>op. cit.</ref> or <ref>loc. cit.</ref>
Links to relevant discussions (where appropriate): MOS: Wikipedia:Footnotes#Style_recommendations (first bullet)
Edit period(s): One time
Estimated number of pages affected: I dont know
Exclusion compliant (Y/N): Yes
Already has a bot flag (Y/N): Yes
Function details: Because I know of no way to use the API for this, I will do a dump scan for articles matching the regex:
re.search('/<\s?ref[^\>]*\s*((I|i)bid\.?|(O|o)p\.?\s?(c|C)it\.?|(L|l)oc\.?\s?(c|C)it\.?)
if that, then:
text = re.sub(\=\=(\n[^(\=\=)](<\s?(r|R)eferences|{{\s?(R|r)eflist)),==\n{{Ibid|date = {{subst:MONTHNAME}} {{subst:YEAR}}}}\\1,text,1,re.M)
Discussion
I havent tested the regex but it should work. Tim1357 (talk) 17:56, 17 January 2010 (UTC)
- I proposed Wikipedia_talk:AutoWikiBrowser/Feature_requests#Add_.7B.7BIbid.7D.7D_to_auto-tagger. -- Magioladitis (talk) 00:33, 21 January 2010 (UTC)
![]() Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. @harej 03:27, 23 January 2010 (UTC)
Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. @harej 03:27, 23 January 2010 (UTC)
AWB implements this too: Wikipedia_talk:AutoWikiBrowser/Feature_requests/Archive_7#Add_.7B.7BIbid.7D.7D_to_auto-tagger. We are interested in any changes in the regex. -- Magioladitis (talk) 08:59, 11 February 2010 (UTC)
{{OperatorAssistanceNeeded}} Any news? MBisanz talk 08:54, 20 February 2010 (UTC)
- My understanding is that Tim1357 is waiting for Toolserver access. Josh Parris 09:57, 20 February 2010 (UTC)
- Thats true. This job requires a dump scan, and to do that I need a toolserver account. I have already been approved, and I'm waiting for someone to create an account for me. Tim1357 (talk) 02:04, 21 February 2010 (UTC)
- I finally got around to generating the list of articles that list Ibid as a reference. Ill get around to testing sometime this/next week. Tim1357 (talk) 23:21, 27 February 2010 (UTC)
 A user has requested the attention of the operator. Once the operator has seen this message and replied, please deactivate this tag. (user notified) Any updates? Are you almost ready to run this? — The Earwig (talk) 01:33, 20 March 2010 (UTC)
A user has requested the attention of the operator. Once the operator has seen this message and replied, please deactivate this tag. (user notified) Any updates? Are you almost ready to run this? — The Earwig (talk) 01:33, 20 March 2010 (UTC)
- I'll expire this in a day or so if you don't start the trial. — The Earwig (talk) 19:33, 28 March 2010 (UTC)
- Withdrawn by operator. Sorry, ill reopen later. Tim1357 (talk) 19:45, 28 March 2010 (UTC)
- I'll expire this in a day or so if you don't start the trial. — The Earwig (talk) 19:33, 28 March 2010 (UTC)
- I finally got around to generating the list of articles that list Ibid as a reference. Ill get around to testing sometime this/next week. Tim1357 (talk) 23:21, 27 February 2010 (UTC)
- Thats true. This job requires a dump scan, and to do that I need a toolserver account. I have already been approved, and I'm waiting for someone to create an account for me. Tim1357 (talk) 02:04, 21 February 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Josh Parris
Automatic or Manually assisted: Automatic
Programming language(s): Python, pywikipedia
Source code available: https://svn.toolserver.org/svnroot/josh/ (revision 6)
Function overview: Add checking of #section anchors for existence to existing bot
Links to relevant discussions (where appropriate): Guideline: Wikipedia:Linking#Checking links as they are created
Edit period(s): Continuous
Estimated number of pages affected: I'd guess less than 5% of new pages have #section links, and perhaps 20% of those would be wrong. At 1000/new pages a day, this would be about 10 edits. Hard figures show: 4% of new pages have #section links, and 32.5% of these are wrong; At 1000/new pages a day, this would be about 13 edits/day.
Exclusion compliant (Y/N): Y, standard in pywikipedia
Already has a bot flag (Y/N): Y
Function details: At the same time as checking new page's wiki markup for links to dab pages, the bot will also check for links containing a #section anchor to ensure the anchor appears on the target page. Normally this is a section heading, but there are techniques available (templates like {{Anchor}} and raw HTML tags) which create an anchor without a ==section==; to detect these cases, the HTML of the target page will be downloaded and searched for these anchors.
| WildBot found one or more links in this article with broken #section; for more information on #section links see Wikipedia:Linking#Piped links to sections of articles. The broken #section links found were: Broadway#Golden years, New York#Histery |
Discussion
This is certainly a good idea. @harej 16:22, 17 January 2010 (UTC)
- Isnt there an inline template for this, similar to {{deadlink}} or something? If there is it would certianly be more helpfull. Would you mind telling me why you think this should only be limited to new pages? You could do a dump scan for the whole project. Tim1357 (talk) 16:57, 17 January 2010 (UTC)
- Bandwidth; I just don't have it. Running the bot as is consumes a solid 20% of a bandwidth I have available. Unless I get a Toolserver account, recent changes or a database scan is off the cards. Additionally, I've got plans to make the bot smarter and more helpful, so I don't want to bomb every broken page link in the 'pedia with a mere advisory. Josh Parris 22:20, 17 January 2010 (UTC)
- You could get a Toolserver account if you'd like; it would probably help with the running of your bot and it's not very difficult to get one if you can demonstrate need. @harej 00:34, 18 January 2010 (UTC)
- DaB said he'll look at my application from 29th Dec on Sunday. Today's Sunday in Germany I believe. Or has it just finished? Anyway, WildBot's approval may help things along there. Josh Parris 00:53, 18 January 2010 (UTC)
- You could get a Toolserver account if you'd like; it would probably help with the running of your bot and it's not very difficult to get one if you can demonstrate need. @harej 00:34, 18 January 2010 (UTC)
- I've had a look, there's nothing for inline work. It may be inappropriate to inline too, because the link still kind-of works, it just goes to the target page rather than a part thereof. Josh Parris 00:58, 18 January 2010 (UTC)
- Bandwidth; I just don't have it. Running the bot as is consumes a solid 20% of a bandwidth I have available. Unless I get a Toolserver account, recent changes or a database scan is off the cards. Additionally, I've got plans to make the bot smarter and more helpful, so I don't want to bomb every broken page link in the 'pedia with a mere advisory. Josh Parris 22:20, 17 January 2010 (UTC)
- On another note, I would appreciate it if the bot only works only in the main-namespace. Tim1357 (talk) 16:57, 17 January 2010 (UTC)
- I was thinking along these lines but couldn't think of a reason not to check the other namespaces the bot currently patrols. What difficulties do you foresee outside of mainspace? Josh Parris 22:20, 17 January 2010 (UTC)
- Damn, one other thing. It is generaly frowned upon for bots to download the html markup. If I may suggest a more server-friendly version: use http://en.wikipedia.org/w/index.php?title=<title>&action=raw&templates=expand. That solves the problem of the {{Anchor}} template. Tim1357 (talk) 17:06, 17 January 2010 (UTC)
- That's pretty much what I've done; I called the API version (which I'm not sure, having seen your suggestion, is the best idea). Josh Parris 22:20, 17 January 2010 (UTC)
- So in order of questions:
- That's pretty much what I've done; I called the API version (which I'm not sure, having seen your suggestion, is the best idea). Josh Parris 22:20, 17 January 2010 (UTC)
- Thats ok, if you only want to do new pages, thats fine. You could look into the toolserver idea if you want.
- My reasoning is that there realy is no need for notifications outside of the mainspace. Plus there is no "talk" pages for talk pages, if you know what I mean.
- Ok, if you really need to download the html, thats fine. I just thought the templates=expand bit would be helpful; I myself just found out about it. Tim1357 (talk) 00:55, 18 January 2010 (UTC)
- Yes, I prefer your method over my API call. WildBot task 1 doesn't do talk pages, so no probs there. Toolserver account is in process. Josh Parris 01:07, 18 January 2010 (UTC)
- Nice, this gets the thumbs up from me as long as this acts in the manor that the Disambiguation Wildbot does. Tim1357 (talk) 01:10, 18 January 2010 (UTC)
![]() Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. @harej 03:30, 23 January 2010 (UTC)
Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. @harej 03:30, 23 January 2010 (UTC)
![]() Coding... adding this functionality has demanded a substantial internal redesign for WildBot, as it's no longer making one edit to a talk page (at least, not internally). The hard figures above were produced by a very rough draft. Josh Parris 22:20, 24 January 2010 (UTC)
Coding... adding this functionality has demanded a substantial internal redesign for WildBot, as it's no longer making one edit to a talk page (at least, not internally). The hard figures above were produced by a very rough draft. Josh Parris 22:20, 24 January 2010 (UTC)
![]() Doing... The trial has commenced, with some preliminary results are available in this a seeded group of #section checking with nine hits. The rest of the results are going to be spread out though the normal run of WildBot. There's code to limit it to 50 #section edits per run. Josh Parris 01:01, 26 January 2010 (UTC)
Doing... The trial has commenced, with some preliminary results are available in this a seeded group of #section checking with nine hits. The rest of the results are going to be spread out though the normal run of WildBot. There's code to limit it to 50 #section edits per run. Josh Parris 01:01, 26 January 2010 (UTC)
- Thus far 25 edits have been made, and I've discovered a number of things. Turns out that pywikipedia has code to detect valid section references - but it doesn't work correctly when there's markup; the common case being an article link in a section header. People put all kinds of crazy stuff into section headers. I won't bore you with the stories. I seem to have bitten off quite a large, chewy part of the world. The internal re-coding has been shaken-out, so I'll soon be tidying up the code and running that in production. Josh Parris 13:57, 27 January 2010 (UTC)
- 33 edits Josh Parris 04:33, 28 January 2010 (UTC)
![]() Trial complete. I'll be posting links to the edits in a few hours Josh Parris 02:45, 29 January 2010 (UTC)
Trial complete. I'll be posting links to the edits in a few hours Josh Parris 02:45, 29 January 2010 (UTC)
If I might add, this has been terribly buggy. I'm going to be keeping a very close eye on it in its early life, the multitude of problem that turned up during the trial haven't endeared the code to me. Josh Parris 11:48, 29 January 2010 (UTC)
- Approved. Seems good to me. Tim1357 (talk) 00:54, 30 January 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Request Expired.
Operator: ·Add§hore· Talk To Me!
Automatic or Manually Assisted: Automatic
Programming Language(s): PHP
Function Overview: Removing uncat tags from articles which contain the tag but also contain categorys.
Edit period(s): Continuous / 1 Time daily run (each)
Already has a bot flag (Y/N): Y
Function Details: Adding and removing both uncat and orphan tags
Discussion
The tasks have previously been approved (please see [5] [6] [7]. This BRFA is to see if the tasks should still continue as the approval was 10 months ago. All questions comments and other observations are welcome. ·Add§hore· Talk To Me! 17:21, 9 January 2010 (UTC)
- It is my understanding that bot approvals last indefinitely unless you have actually put an expiration date on yours (I haven't checked your links yet). @harej 18:14, 9 January 2010 (UTC)
- A couple of comments:
- Orphan Tagging: Tagging of orphans created some controversy awhile back. I recommend before re-starting that task you post at WP:Orphan, Template:Orphan, and the Village Pump.
- Orphan Untagging: My bot (JL-Bot) does this already though there is no harm in having multiple bots do it. However, your previous BFRA says you're using this ToolServer report. If you are, please be sure to double check the article yourself before removing the orphan template as that report does have bugs. For example, it will sometimes list new articles without any links.
- An observation: occasionally I will partially address a tag and thus leave the tag on the article; for categorization, I'll add one I can think of, but it will be obvious to me that there would be another that I can't figure out in a timely way. Admittedly, this is sub-optimal, but there you go.
- I don't think there's any easy way to detect that an article needs multiple categories; do you think it's a reasonable idea to say a tag-half-actioned article has had that tag actioned? (This isn't a loaded question, it's just a question)
- As a way around this objection, you could say that if any bottom-of-the-category-tree category is used, or multiple categories are used, then it's been "correctly categorized".
- I'm not quite sure what you mean by 'actioning a tag', but your concerns don't seem relevant. For purposes of {{uncategorized}}, an article either has categories or it doesn't have categories. It isn't about whether categorization is complete or correct (that's handled by other templates like {{cat improve}}). I agree that a bot detecting that an article needs multiple categories is problematic, but that's not what this is about. The report detects whether an article has any categories which is straightforward. -- JLaTondre (talk) 15:16, 10 January 2010 (UTC)
- Okay, I've been doing things wrong. Josh Parris 15:47, 10 January 2010 (UTC)
- Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. MBisanz talk 05:40, 11 January 2010 (UTC)
- It would have been nice if Addshore had responded to my comments above first. Given the previous debates over orphan tagging, I don't think that should be considered an uncontroversial task without greater exposure. -- JLaTondre (talk) 21:37, 11 January 2010 (UTC)
- Sorry for my slow reply, I have been having exams. I will happily post at WP:Orphan, Template:Orphan, and the Village Pump. The task itself was very visible when it was first approved so I may as well do it again and see if anything has changed. I do know there are already bots un-tagging orphan (JL-Bot) but the more the merrier and the quicker things will get done. Soon my bot will also be on the toolserver and I will be able to do direct DB queries, and the bot does currently check before it acts on an article. As for the current definition that I am using for an orphan, 1 link from the main space not including lists or diambigs (this is the same as the orphanage). — Preceding unsigned comment added by Addshore (talk • contribs) 17:03, 12 January 2010
- You're right that the task was very visible the first time. It stirred up quite a bit of objection to the orphan tag. The criteria is actually 3 links. It is recommended that articles not be tagged unless they have no links. But if was manually tagged, it shouldn't be removed unless the article has 3. There are also pages that are excluded from being orphans (dabs, names, SIA). -- JLaTondre (talk) 14:02, 16 January 2010 (UTC)
- {{OperatorAssistanceNeeded|D}} Any update on the trial or followup questions? MBisanz talk 02:49, 24 January 2010 (UTC)
Just to be more accurate: The criteria for orphans is:
- 3 links to the article directly OR to its redirects.
- Redirects(and dabs) don't count in the number of links.
- Redirects and dabs should not be tagged as orphans.
AWB does must of it right now. Check my BRFA in Wikipedia:Bots/Requests for approval/Yobot 11. -- Magioladitis (talk) 09:27, 25 January 2010 (UTC)
- Sorry for my slow reply. I have just restructured my bot so at the moment I cannot fun the orphan side of it. ·Add§hore· Talk To Me! 16:49, 25 January 2010 (UTC)
I think it's better if Addbot works only with uncat tags. 10 months ago Addbot added orphan tag to 80,000 articles. This is more than half of the backlog we already have. The Orphanage has requested some kind of cease fire. -- Magioladitis (talk) 14:45, 4 February 2010 (UTC)
![]() A user has requested the attention of the operator. Once the operator has seen this message and replied, please deactivate this tag. (user notified) What is the current status of the bot - is it able to undertake a trial, regardless of the intent to run? Josh Parris 06:36, 23 February 2010 (UTC)
A user has requested the attention of the operator. Once the operator has seen this message and replied, please deactivate this tag. (user notified) What is the current status of the bot - is it able to undertake a trial, regardless of the intent to run? Josh Parris 06:36, 23 February 2010 (UTC)
![]() Request Expired. Operator has been inactive for nearly two months. Josh Parris 03:20, 9 March 2010 (UTC)
Request Expired. Operator has been inactive for nearly two months. Josh Parris 03:20, 9 March 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
Bots that have completed the trial period
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Tim1357
Automatic or Manually assisted:
Programming language(s): Python
Source code available:I dont want you to throw up; its pretty ugly.
Function overview: Per the nearly 150 kilobytes of conversation at Wikipedia talk:WikiProject Albums (permalink), the bot moves rating in the |Ratings= parameter of {{Infobox Album}} to the newly created {{Album ratings}}.
Links to relevant discussions (where appropriate): See above
Edit period(s): Once, with perhaps a run afterwards to clean up what I miss.
Estimated number of pages affected: From my testing I'd say maybe half of all articles with {{Infobox Album}} (If this is true, the bot would edit approx. 45,000 pages. — The Earwig @ 07:29, 2 January 2010 (UTC))
Exclusion compliant (Y/N): Y
Already has a bot flag (Y/N): Y
Function details: Syntax:
- Get Article text.
- Get contents of Infobox Album (including nested templates)
- Get contents of |Rating parameter (including nested templates)
- Remove parameter and contents from template
- Split contents by (newline)*
- For each review, seperate into two parts: Reviewer and Score
- Turn all html links into references, name them "Reviewer" Review
- Put all content into {{Album ratings}}
- Look for the first section that contains any of the following: Reception,Review,critical,Release ; put {{Album ratings}} at beggining
- If none is found, look for section that contains Track (as in Track Listing); create section before it named "Reception", put {{Album ratings}} at begining and {{Arprose}} at the end.
- if none is found, use first section as section; create section named "Reception", put {{Album ratings}} at begining and {{Arprose}} at the end.
- Go to next.
Discussion
- If this bot makes it to the trial stage, I request an extended trial. This is because 90% of the work I did for the bot was in regex. It is hard to see errors in regular expression code, and the only way I think I will find those errors is by testing the bot in the real world. Tim1357 (talk) 06:33, 1 January 2010 (UTC)
- Note: I added a link to the source code. I only included the bits that I wrote, because everything else utilizes what is in basic.py (the basic frameworks for pywikipedia) Tim1357 (talk) 05:39, 2 January 2010 (UTC)
- Some Sample edits Tim1357 (talk) 06:43, 2 January 2010 (UTC)
- You didn't mention whether the bot was supervised or unsupervised. I assume that once approved, the bot will run fully unsupervised, yes? — The Earwig @ 07:29, 2 January 2010 (UTC)
- Oh, verry sorry. Yes, once I am confident that the bot will not damage anything, then I will let it go un-supervised. Tim1357 (talk) 15:41, 2 January 2010 (UTC)
![]() Approved for extended trial. Please provide a link to the relevant contributions and/or diffs when the trial is complete. MBisanz talk 00:50, 3 January 2010 (UTC)
Approved for extended trial. Please provide a link to the relevant contributions and/or diffs when the trial is complete. MBisanz talk 00:50, 3 January 2010 (UTC)
- Thanks, I appreciate this because there are lots of little errors that need fixing. Tim1357 (talk) 16:28, 3 January 2010 (UTC)
- I'm stuck right now on one error. The following regex:
- Thanks, I appreciate this because there are lots of little errors that need fixing. Tim1357 (talk) 16:28, 3 January 2010 (UTC)
{{[\s_]*Infobox[\s_]Album(({{(({{(({{.*?}})|.)*}})|.)*}})|.)*}}
which is supposed to match only the contents of the Infobox Album template, matches way much more then it is supposed to. Any Ideas? Tim1357 (talk) 04:34, 9 January 2010 (UTC)
- I find that rather than using
.*?you ought to try[^\}\|]*?when matching template names; for template contents drop the\|Josh Parris 04:41, 9 January 2010 (UTC)- Ok I changed *? to * but that dosen't change anything with my problem. Also
[^\}\|]*?stops at the first "|", which does not work in my case. Tim1357 (talk) 04:44, 9 January 2010 (UTC)- Being a little more specific, try:
- Ok I changed *? to * but that dosen't change anything with my problem. Also
{{[\s_]*Infobox[\s_]Album(({{(({{(({{[^\}]*?}})|.)*}})|.)*}})|.)*}}
- Mind you, that's theoretical, without test data, so YMMV Josh Parris 04:48, 9 January 2010 (UTC)
- The difficult page is Bookends Josh Parris 05:19, 9 January 2010 (UTC)
- Ok, I think I found a solution. Its pretty cheap, but It works. Im continuing the trial now, and will try to get 50 pages edited without an error. Tim1357 (talk) 21:45, 19 January 2010 (UTC)
 Done See the log. I know the edit summary is screwed up in the latter parts. Its an easy fix. I think I didn't miss anything other then that.... Tim1357 (talk) 00:32, 20 January 2010 (UTC)
Done See the log. I know the edit summary is screwed up in the latter parts. Its an easy fix. I think I didn't miss anything other then that.... Tim1357 (talk) 00:32, 20 January 2010 (UTC)
- Ok, I think I found a solution. Its pretty cheap, but It works. Im continuing the trial now, and will try to get 50 pages edited without an error. Tim1357 (talk) 21:45, 19 January 2010 (UTC)
![]() Approved. Just be sure that the edit summaries are fixed. (X! · talk) · @291 · 05:58, 25 January 2010 (UTC)
Approved. Just be sure that the edit summaries are fixed. (X! · talk) · @291 · 05:58, 25 January 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
- The following discussion is an archived debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA. The result of the discussion was Approved.
Operator: Tim1357
Automatic or Manually assisted: Automatic
Programming language(s): Python (pywikipedia)
Source code available: If ya want it.
Function overview: Remove non-free images from non-mainspaces.
Links to relevant discussions (where appropriate):
Edit period(s): Daily
Estimated number of pages affected: 1000 to start. I have no idea how many after the backlog is done.
Exclusion compliant (Y/N): Y
Already has a bot flag (Y/N): N
Function details: Replaces BJBot, generates a list of Fair-Use images in non-mainspace from Betacommand's tool here. Then, it replaces any and all fair use images with File:NonFreeImageRemoved.svg. It replaces multiple images at the same time (if there are more than one in the page). I am considering making a new version of NonFreeImageRemoved.svg, so that when it replaces the image, it does not fill the entire page. Perhaps the new image would be 200px. That way the biggest it could be would be 200px. See what happens otherwise here.
{kind=link}
Discussion
Per the request of SoWhy, the bot changes all images in the talk namespaces to links. Tim1357 (talk) 23:32, 27 December 2009 (UTC)
- UPDATE: Also per the recomendation of SoWhy, the bot will leave a note on the talk page of the user that added the image. Tim1357 (talk) 01:59, 28 December 2009 (UTC)
It's an appropriate task, as non-free images should never be in non-main space. --IP69.226.103.13 (talk) 20:19, 28 December 2009 (UTC)
- Will it pick up Non-free images from their inclusion in the non-free media category or my transclusion of a non-free image template? MBisanz talk 10:17, 30 December 2009 (UTC)
- I'm not sure how betacommand generates the list. Let me ask him. Tim1357 (talk) 14:03, 30 December 2009 (UTC)
- The list is apparently from Category:All non-free media Tim1357 (talk) 03:05, 31 December 2009 (UTC)
- (recursive of course) Tim1357 (talk) 03:10, 31 December 2009 (UTC)
- What do you mean "recursive of course?" --IP69.226.103.13 19:18, 31 December 2009 (UTC)
- Oh, im sorry. Recursive means that it finds all the files that are in subcategorys as well. That means that articles in Category:Non-free_musical_artist_logos are included in the list, as Category:Non-free_musical_artist_logos is a sub-category of Category:All non-free media. If there are sub-sub categories (i.e. categories in sub-categories) it finds the files in those categories as well. Tim1357 (talk) 19:30, 31 December 2009 (UTC)
- Well, recursive has a different specific technical meaning, so it's more useful, imo, in a bot discussion, which is a community discussion, to say it will check subcategories too, unless you're discussing the code in particular. In this case it's about what it does. Thanks. --IP69.226.103.13 19:36, 31 December 2009 (UTC)
- You're right. Thanks : ) Tim1357 (talk) 00:28, 1 January 2010 (UTC)
- Well, recursive has a different specific technical meaning, so it's more useful, imo, in a bot discussion, which is a community discussion, to say it will check subcategories too, unless you're discussing the code in particular. In this case it's about what it does. Thanks. --IP69.226.103.13 19:36, 31 December 2009 (UTC)
- Oh, im sorry. Recursive means that it finds all the files that are in subcategorys as well. That means that articles in Category:Non-free_musical_artist_logos are included in the list, as Category:Non-free_musical_artist_logos is a sub-category of Category:All non-free media. If there are sub-sub categories (i.e. categories in sub-categories) it finds the files in those categories as well. Tim1357 (talk) 19:30, 31 December 2009 (UTC)
- What do you mean "recursive of course?" --IP69.226.103.13 19:18, 31 December 2009 (UTC)
- (recursive of course) Tim1357 (talk) 03:10, 31 December 2009 (UTC)
- The list is apparently from Category:All non-free media Tim1357 (talk) 03:05, 31 December 2009 (UTC)
- I'm not sure how betacommand generates the list. Let me ask him. Tim1357 (talk) 14:03, 30 December 2009 (UTC)
I've scaled the default size of File:NonFreeImageRemoved.svg to 200×200px to avoid the problem you noted above. It's an SVG, so this should have no effect when it's used with an explicit size.
I'd also like to suggest that the bot should leave the name of the replaced file visible in some way, e.g. in a <!-- comment --> or, where possible, linked from the caption. People something include non-free images in discussions also outside the odd namespaces (e.g. on the village pumps or the refdesks, and IME quite often at the graphics lab), and it can be annoying to have to dig through the history for the name of the image being discussed. Alternatively, perhaps the bot should treat the Wikipedia: namespace as if it were a talk namespace. —Ilmari Karonen (talk) 10:02, 1 January 2010 (UTC)
- I was thinking that too, I like the Idea of a comment. The only problem is: sometimes the non-free image is in an infobox, and Im not sure how to turn those into links, as they often-times do not have the [[File: or [[Image: markers within the box. Tim1357 (talk) 16:03, 1 January 2010 (UTC)
- Ok, seems like a good idea to trial as soon as we can figure out the infobox issue, I think User:ST47 had a solution to that once, so you might try emailing him. MBisanz talk 00:53, 3 January 2010 (UTC)
- You can also try asking one of the editors who does a lot of work with templates (User:ThaddeusB?), or check the infobox discussion pages to find someone. --IP69.226.103.13 | Talk about me. 05:18, 3 January 2010 (UTC)
- For infoboxes, I think simply including the original image name in a <!-- comment --> (as in, say, "
|image = NonFreeImageRemoved.svg<!-- Original_image_name.jpg -->") is probably the best solution. The MediaWiki parser strips comments pretty early, so they shouldn't affect the infobox syntax. —Ilmari Karonen (talk) 14:58, 3 January 2010 (UTC)- Ok, I guess that works ok. Tim1357 (talk) 16:26, 3 January 2010 (UTC)
- For infoboxes, I think simply including the original image name in a <!-- comment --> (as in, say, "
- You can also try asking one of the editors who does a lot of work with templates (User:ThaddeusB?), or check the infobox discussion pages to find someone. --IP69.226.103.13 | Talk about me. 05:18, 3 January 2010 (UTC)
Will the bot avoid editing the same page a number of times in a row, such as happened with BJBot here? - Kingpin13 (talk) 09:04, 5 January 2010 (UTC)
- I dont know why that page was edited, isnt it in the mainspace? Anyways, the bot will group multiple files into a single edit. Tim1357 (talk) 01:33, 7 January 2010 (UTC)
- I can't spot it being mentioned anywhere; will the bot be ignoring pages in Category:Wikipedia non-free content criteria exemptions? - Kingpin13 (talk) 09:52, 8 January 2010 (UTC)
- Not yet, ill find a way to code that in there. Tim1357 (talk) 22:00, 8 January 2010 (UTC)
- Doing... Tim1357 (talk) 18:36, 10 January 2010 (UTC)
- All Done with the code, the bot trys to link the image if it can, and replaces it with File:NonFreeImageRemoved.svg if it cant. In all cases, it leaves an inline comment, leaving the images name if it was replaced. Im ready for trial if nobody objects. {{BAGAssistanceNeeded}} Tim1357 (talk) 02:30, 11 January 2010 (UTC)
- No objections from me. The sooner we clean these problems up, the better, imo. --IP69.226.103.13 | Talk about me. 22:47, 10 January 2010 (UTC)
- All
- Not yet, ill find a way to code that in there. Tim1357 (talk) 22:00, 8 January 2010 (UTC)
- I can't spot it being mentioned anywhere; will the bot be ignoring pages in Category:Wikipedia non-free content criteria exemptions? - Kingpin13 (talk) 09:52, 8 January 2010 (UTC)
- Approved for trial (50 edits). Please provide a link to the relevant contributions and/or diffs when the trial is complete. MBisanz talk 05:38, 11 January 2010 (UTC)
- Done see /log Tim1357 (talk) 06:07, 15 January 2010 (UTC)
- I don't see any user warnings...? - Kingpin13 (talk) 09:53, 15 January 2010 (UTC)
- Comments (1) Error: The bot removed File:WorcsCoatArms.jpg from 13 pages doing so based on the image existing on the list at Betacommand's list. Good so far. However, another editor changed the license on the image to a free one (sidebar: probably improperly). The bot did not look at the current tagging of the image to see if it is still marked as non-free. This is probably not a huge issue, as Betacommand's report runs once every 24 hours. Very few images are going to be erroneously removed by this shortcoming. (2) About time! Betacommand's list is always hovering around 900-1200 entries. I try hard every day to fight the length of the list down, with no success in reducing the number of violations overall. The number of new violations per day is roughly equivalent to the number of violations removed. This bot will finally overcome that list and keep things in line. Yeah! (3) Discussion on development articles a discussion that has some bearing on what this bot can do is present at Wikipedia_talk:Non-free_content#Non-free_images_on_sandbox.2Fuserspace_developing_articles. --Hammersoft (talk) 15:19, 15 January 2010 (UTC)
- Problem What if someone labels a popular PD image as non-free. Concieveably, such an image (like one used in a popular user box) could be removed from thousands of pages causing significant, unnecessary problems. Second of all, it appears Hammersoft used this bot to remove said 13 instances of the image unlike what was claimed above (that the bot removed the image). — BQZip01 — talk 21:27, 15 January 2010 (UTC)
- In relation to this, perhaps a limit could be placed, where if the image appears on more than X pages, it won't be removed without some-kind-of human confirmation, such as whacking a {{Seriously, we're not kidding, this ought to be deleted}} type template onto the image, or just leaving it up to humans altogether. So: Tim1357, what's the count of whatlinkshere for the current crop of candidate images? Is it something like 98% have two or less? Josh Parris 23:09, 15 January 2010 (UTC)
{kind=link}
- Ahh comments! I will respond to requests in the order they were received so:
- Kingpin, damn i forgot, done (will make it exclusion compliant and skip if already notified user)
- Josh Parris and BQZip01, good idea, If the bot is all of a sudden told to remove more then say 7 copies of an image, It will skip it an log it.
(sorry I went a bit over 50 I think)
Tim1357 (talk) 01:45, 16 January 2010 (UTC)
- I like the basic idea (pulling back things that don't meet our criteria). What I'm most concerned about is the volume we're talking about here. Imagine an image that people use all over Wikipedia (like a check mark) being labeled as non-free right before DASHBot 5 makes its run. Someone would have to go back through the edit history (and if estimates of 800-1200 are accurate) sifting through all those edits to undo those that were removed could be a serious problem (especially when finding a few dozen edits out of thousands each day). A better solution, IMHO, would be to allow users to use an application that runs this code (instead of an automatic bot) under their names and look at each individual image (allowing some personal interaction and personal determination on each image). As it is, even running only on only 7 images max could cause lots of problems and would be a major pain to fix any errors. It is easy to find images that are not used properly (just look at the images and look at what articles it is used in), it is hard to undo such actions as they are on numerous pages and, once removed, are not linked by anything except one person's edit history. With the problems when uploading images, as it is quite easy to have the wrong tag and those tags available are largely incomplete/missing many options, I'm not sure this bot application is a good idea at this time. — BQZip01 — talk 04:11, 16 January 2010 (UTC)
- An idea to fix this and make undo actions significantly easier would be to log such actions on the image page. Something like
- DASHBot has removed this image from [page A], [Page B], and [Page C]. Please consider the copyright status of this image and Wikipedia's Non free content criteria before re-adding this image to additional pages.
- each link would record the action of the bot, thereby making undo actions much easier and appropriately centralized. These links could be removed after 30 days to de-clutter the page. If this process is added, I would have no problem bumping up the limit to 30 or 40 images at a time. Thoughts? — BQZip01 — talk 04:16, 16 January 2010 (UTC)
- Another idea would be to check each rev in the history of the file, and only remove if the image has always been NFC. - Kingpin13 (talk) 06:30, 16 January 2010 (UTC)
- That's a good alternative too, but that still leaves the problem of images that simply have the wrong tag from uploading. Perhaps a combination of the two? — BQZip01 — talk 15:52, 16 January 2010 (UTC)
- In theory, any file that all of a sudden needs to be removed from many pages, means that it was just recently tagged as such. For that reason, the bot logs all images that call for more then ten removals to a special page. It checks another page to see if it has the OK to remove the file. In other words, it waits for human review before it precedes in removing the files en masse. Tim1357 (talk) 04:55, 17 January 2010 (UTC)
- Ok, but will the person's name who reviews this be attached to the edit? What about logging such edits on the associated image page? image's talk page? — BQZip01 — talk 08:55, 17 January 2010 (UTC)
- Update also I created a list of users not to be warned again. Tim1357 (talk) 04:57, 17 January 2010 (UTC)
- Well, in my humble opinion, I think having the list in one place is a lot better then pinging talk pages. Many of those pages, mind you, are not watched. This way someone can know the place to go in order to review images. Tim1357 (talk) 15:38, 17 January 2010 (UTC)
- My understanding is that BQZip01 was asking if there would be an audit trail in place and obvious. Josh Parris 15:54, 17 January 2010 (UTC)
- Yeppers! However, it seems to me that the image talk page might be an ideal place to annotate such information (I have no problem if that info is removed even a few days after (it will remain in the edit history anyway). — BQZip01 — talk 16:01, 17 January 2010 (UTC)
- My understanding is that BQZip01 was asking if there would be an audit trail in place and obvious. Josh Parris 15:54, 17 January 2010 (UTC)
- Well, in my humble opinion, I think having the list in one place is a lot better then pinging talk pages. Many of those pages, mind you, are not watched. This way someone can know the place to go in order to review images. Tim1357 (talk) 15:38, 17 January 2010 (UTC)
- In theory, any file that all of a sudden needs to be removed from many pages, means that it was just recently tagged as such. For that reason, the bot logs all images that call for more then ten removals to a special page. It checks another page to see if it has the OK to remove the file. In other words, it waits for human review before it precedes in removing the files en masse. Tim1357 (talk) 04:55, 17 January 2010 (UTC)
- That's a good alternative too, but that still leaves the problem of images that simply have the wrong tag from uploading. Perhaps a combination of the two? — BQZip01 — talk 15:52, 16 January 2010 (UTC)
- Another idea would be to check each rev in the history of the file, and only remove if the image has always been NFC. - Kingpin13 (talk) 06:30, 16 January 2010 (UTC)
- An idea to fix this and make undo actions significantly easier would be to log such actions on the image page. Something like
- Absolutely, however, finding such changes is problematic. If a bot makes 5000 changes in a day, it takes a long time to sift through and find such changes in the edit history. While you can find any page on which and image is used by simply looking on the image page, you cannot look on the image page to find images that used to be on other pages.
- Let's use an example where this bot finds an image tagged for fair use with some rationales given. In conjunction, there are 10 violations of WP:NFCC since the image is being used on 10 user pages. The bot removes user page images and continues with its deletions. 2 days later someone looks at their user page and finds the image missing, fixes the erroneous tag (the image was actually PD), and re-adds it to his user page. The other 9 images are never re-added because no one knew that they were removed in the first place (searching through thousands of edits to see if anyone else's pages were affected is a tedious use of time).
- If you provide diffs to each of the removals on the talk page of the "offending" image, it would eliminate the searching and easily centralize any corrections. — BQZip01 — talk 18:17, 17 January 2010 (UTC)
- Darn internet makes it hard to communicate. Thanks for clearing that up. Yes, I can provide a log of difs for when the bot removes files from pages. Ill put a list of diffs, by file, in a table at User:DASHBot/HumanReview. Tim1357 (talk) 18:31, 17 January 2010 (UTC)
- Thanks. That's a great idea, but I still think it would be better to annotate it on the image page, image talk page, or at least provide a link to your table in the edit summary. Does that work for you? — BQZip01 — talk 18:53, 17 January 2010 (UTC)
- Sure, ill leave a link to the page in the edit summary, as I think it is a good idea to keep all of the log in one place. Tim1357 (talk) 18:57, 17 January 2010 (UTC)
- Hmmm...I'm thinking there may be a problem with this. It runs into the same problem: finding the changes in the first place. If there is no change to the image, then finding all of these changes is a problem. If such changes are mentioned on the image talk page (or just a diff to the log update), they can easily be found and reverted if needed. — BQZip01 — talk 19:05, 17 January 2010 (UTC)
- Sure, ill leave a link to the page in the edit summary, as I think it is a good idea to keep all of the log in one place. Tim1357 (talk) 18:57, 17 January 2010 (UTC)
- Thanks. That's a great idea, but I still think it would be better to annotate it on the image page, image talk page, or at least provide a link to your table in the edit summary. Does that work for you? — BQZip01 — talk 18:53, 17 January 2010 (UTC)
- Darn internet makes it hard to communicate. Thanks for clearing that up. Yes, I can provide a log of difs for when the bot removes files from pages. Ill put a list of diffs, by file, in a table at User:DASHBot/HumanReview. Tim1357 (talk) 18:31, 17 January 2010 (UTC)
If I may step in to clarify here: it appears that BQZip01 is asking for all image removals be noted on the image's talk page, and I would suggest some sort of notice placed on the image's page pointing to the talk-page. The intention here is that if images have been removed in error, then on the image's talk page is a list of all the reversions that need to be made / the affected pages. "Here's every article that used to use this image, before the bot had its way with them". Please correct me if I'm wrong.
As an aside, there might even be an easy way "Click here to revert these removals"-style to undo the bot's actions (presumably by having the bot do so). Josh Parris 00:59, 20 January 2010 (UTC)
- Ok here is what I think is a reasonable compromise:
- The edit summary looks like this: Robot: Removing N Non-Free files per WP:NFCC#9 (Shutoff | Log | Error?)
- The talk pages of Images are not edited, I think it is kind of spammy, and really serves no purpose.
- The user-message has links to the log and the error page.
- The log page is sorted by day. Each Day has its own table, with the actions sorted by file. The table will contain links to diffs performed by the bot.
- Anytime more then 40 images are called to be removed, it waits for human conformation.
- I hope that works well for everyone.
Tim1357 (talk) 02:04, 20 January 2010 (UTC)
- Tim, I love what you are trying to do here, but I think you are missing the point that Josh and I are trying to make. Let's say an image with an improper label is used on 39 user pages and is removed by a human, with no link to the image or its talk page, no one knows what was removed unless you were watching the pages upon which it was used. I agree it is "kind of spammy", but that is kind of the point. I have no problem with appending
- ==DASHBot image removal==
- DASHBot removed this image from N pages on [www.google.com 21 January 2009] ~~~~
- N would be the number of pages (you're already tracking this) and should be easy to insert.
- The link would be to the log entry.
- This would make changes much easier.
- Also, will the log feature a clickable link to undo a group of actions? or will each individual page require an individual "undo" (don't get me wrong but fixing any problems would be a gold mine for my edit count :-) ) — BQZip01 — talk 02:19, 21 January 2010 (UTC)
- I have multiple reasons why that would not be a good idea:
- BJBot Once removed a fair use image from one of my userspace draft. I was confused for a second, but the edit comment, the inline comment and the userpage all explained it to me. I did not think of checking the talk page.
- Included in the user message explanation is a link to report errors (my talk page). Note that the bot logs all removals, so the log will be useful to anyone.
- There are hundreds of files to be removed each week. What if the same file is removed multiple times from an unwatched talk page? That could ammount to a huge ammount of posts to a talk page that nobody will ever look at anyways.
- I think leaving messages on talk pages is overkill. User talk pages should suffice, along with the edit summaries, and the inline comments.
- Ok thats it. And in IRC, Josh_Parris and I discussed this. He had some reservations, but seemed to sign off on this. Ill get him to comment here again if he can. Tim1357 (talk) 02:33, 21 January 2010 (UTC)
- I did express reservations, right up to the point where Tim1357 pointed out that if images were removed in error, he'd fix the problem himself. Given the bot will only run while Tim1357 is still around, it's the ultimate fall-back; he can go trawling through the logs to figure out what needs reverting.
- Having read BQZip01's comments, I believe his scenario is one where the user in question is not using the image on their user page, but may perhaps be the creator of the image. Suddenly she notices that the image isn't used on 38 pages, it's used on 2. There's no where for her to go to discover what happened. (BQZip01, correct me if this scenario is not similar to what you are envisaging) If this is the scenario BQZip01 is contemplating, you might get around it by simply placing a single note on the talkpage "At various times this image was removed from one or more user pages as required by <insert link>; for details inquire at User Talk:DASHBot or see the bot logs at <insert location>" Josh Parris 12:08, 21 January 2010 (UTC)
- That's basically the gist of it. Somehow I am failing to get the point across to Tim (my fault Tim, not yours).
- In your scenario, BJBot removed the image and you checked the edit history. Let's say you fixed the tag on the page and decided to add it back into your page. What you don't know is that the same image was removed from 38 other pages (a hypothetical situation here) and you wouldn't have any idea that actually happened unless you were watching one of those pages. You have no way to know what the Bot did. While you can see the log, you will have to know what date it was removed on in which articles it was used to find the appropriate diff(s) to undo. — BQZip01 — talk 17:45, 21 January 2010 (UTC)
- Sorry, I missed the comment that you'd fix any errors yourself. By all means press ahead! — BQZip01 — talk 06:20, 25 January 2010 (UTC)
- I have multiple reasons why that would not be a good idea:
- Tim, I love what you are trying to do here, but I think you are missing the point that Josh and I are trying to make. Let's say an image with an improper label is used on 39 user pages and is removed by a human, with no link to the image or its talk page, no one knows what was removed unless you were watching the pages upon which it was used. I agree it is "kind of spammy", but that is kind of the point. I have no problem with appending
- Appears issues are resolved, approving. Approved. MBisanz talk 20:06, 2 February 2010 (UTC)
- The above discussion is preserved as an archive of the debate. Please do not modify it. To request review of this BRFA, please start a new section at WT:BRFA.
Approved requests
Bots that have been approved for operations after a successful BRFA will be listed here for informational purposes. No other approval action is required for these bots. Recently approved requests can be found here (edit), while old requests can be found in the archives.
- RustyBot (BRFA · contribs · actions log · block log · flag log · user rights) Approved 18:05, 5 July 2024 (UTC) (bot has flag)
- Mdann52 bot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 15) Approved 18:05, 5 July 2024 (UTC) (bot has flag)
- Qwerfjkl (bot) (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 30) Approved 18:05, 5 July 2024 (UTC) (bot has flag)
- PrimeBOT (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 45) Approved 13:47, 29 May 2024 (UTC) (bot has flag)
- Numberguy6Bot (BRFA · contribs · actions log · block log · flag log · user rights) Approved 13:18, 26 May 2024 (UTC) (bot has flag)
- BsoykaBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 3) Approved 13:18, 26 May 2024 (UTC) (bot has flag)
- SDZeroBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 13) Approved 13:08, 26 May 2024 (UTC) (bot has flag)
- CopyPatrolBot (BRFA · contribs · actions log · block log · flag log · user rights) Approved 12:59, 18 May 2024 (UTC) (bot has flag)
- Qwerfjkl (bot) (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 29) Approved 11:35, 3 May 2024 (UTC) (bot has flag)
- ButlerBlogBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 4) Approved 11:35, 3 May 2024 (UTC) (bot has flag)
- PrimeBOT (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 42) Approved 11:39, 1 April 2024 (UTC) (bot has flag)
- PrimeBOT (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 43b) Approved 20:42, 31 March 2024 (UTC) (bot has flag)
- PrimeBOT (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 44) Approved 20:26, 31 March 2024 (UTC) (bot has flag)
- BattyBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 82) Approved 12:48, 30 March 2024 (UTC) (bot has flag)
- Qwerfjkl (bot) (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 28) Approved 07:32, 29 March 2024 (UTC) (bot has flag)
- Qwerfjkl (bot) (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 25) Approved 12:45, 13 March 2024 (UTC) (bot has flag)
- AnomieBOT (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 81) Approved 21:04, 10 March 2024 (UTC) (bot has flag)
- FrostlySnowman (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 11) Approved 09:40, 17 February 2024 (UTC) (bot has flag)
- AnomieBOT (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 82) Approved 19:58, 4 February 2024 (UTC) (bot has flag)
- PrimeBOT (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 43) Approved 13:45, 4 February 2024 (UTC) (bot has flag)
- SDZeroBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 12) Approved 16:43, 1 February 2024 (UTC) (bot has flag)
- The Sky Bot (BRFA · contribs · actions log · block log · flag log · user rights) Approved 13:02, 25 January 2024 (UTC) (bot has flag)
- DeadbeefBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 3) Approved 19:46, 23 January 2024 (UTC) (bot has flag)
- Qwerfjkl (bot) (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 26) Approved 14:24, 6 January 2024 (UTC) (bot has flag)
- BsoykaBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 2) Approved 13:35, 1 January 2024 (UTC) (bot has flag)
- ButlerBlogBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 3) Approved 13:35, 1 January 2024 (UTC) (bot has flag)
- Cewbot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 12) Approved 13:38, 31 December 2023 (UTC) (bot has flag)
- BattyBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 79) Approved 08:41, 31 December 2023 (UTC) (bot has flag)
- KiranBOT (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 8) Approved 16:54, 28 December 2023 (UTC) (bot has flag)
- BattyBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 80) Approved 14:13, 17 December 2023 (UTC) (bot has flag)
Denied requests
Bots that have been denied for operations will be listed here for informational purposes for at least 7 days before being archived. No other action is required for these bots. Older requests can be found in the Archive.
- GeneGoBot (BRFA · contribs · actions log · block log · flag log · user rights) Bot denied 08:20, 23 January 2010 (UTC)
- Template Maintenance Bot (BRFA · contribs · actions log · block log · flag log · user rights) Bot denied 22:29, 28 December 2009 (UTC)
- IronBot (BRFA · contribs · actions log · block log · flag log · user rights) Bot denied 02:18, 19 December 2009 (UTC)
- Andrea105Bot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 5) Bot denied 03:54, 14 December 2009 (UTC)
- Andrea105Bot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 4) Bot denied 03:54, 14 December 2009 (UTC)
- Andrea105Bot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 2) Bot denied 03:54, 14 December 2009 (UTC)
- MisterWikiBot (2nd) (BRFA · contribs · actions log · block log · flag log · user rights) Bot denied 20:30, 4 December 2009 (UTC)
- MisterWikiBot (BRFA · contribs · actions log · block log · flag log · user rights) Bot denied 16:48, 4 December 2009 (UTC)
- EmBOTellado (BRFA · contribs · actions log · block log · flag log · user rights) Bot denied 03:48, 2 December 2009 (UTC)
Expired/withdrawn requests
These requests have either expired, as information required by the operator was not provided, or been withdrawn. These tasks are not authorized to run, but such lack of authorization does not necessarily follow from a finding as to merit. A bot that, having been approved for testing, was not tested by an editor, or one for which the results of testing were not posted, for example, would appear here. Bot requests should not be placed here if there is an active discussion ongoing above. Operators whose requests have expired may reactivate their requests at anytime. The following list shows recent requests (if any) that have expired, listed here for informational purposes for at least 7 days before being archived. Older requests can be found in the respective archives: Expired, Withdrawn.
- SvickBOT (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 01:28, 22 January 2010 (UTC)
- CobraBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 3) Withdrawn by operator 01:57, 20 January 2010 (UTC)
- MWOAPBot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 21:56, 16 January 2010 (UTC)
- DASHBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 6) Withdrawn by operator 06:34, 8 January 2010 (UTC)
- SheepBot (BRFA · contribs · actions log · block log · flag log · user rights) Expired 20:46, 6 January 2010 (UTC)
- MWOAPBot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 08:50, 5 January 2010 (UTC)
- Coreva-Bot 2 (BRFA · contribs · actions log · block log · flag log · user rights) Expired 01:28, 3 January 2010 (UTC)
- SmackBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: XXII) Withdrawn by operator 21:43, 29 December 2009 (UTC)
- Chris G Bot 2 (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 2) Withdrawn by operator 11:00, 29 December 2009 (UTC)~
- DASHBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 2) Withdrawn by operator 17:09, 22 December 2009 (UTC)
- WaybackBot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 05:02, 10 December 2009 (UTC)
- DrilBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 5) Withdrawn by operator 04:50, 5 December 2009 (UTC)
- SmackBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: XXIII) Withdrawn by operator 14:23, 3 December 2009 (UTC)
- ActiveAdminBot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 01:29, 2 December 2009 (UTC)
- Mr.Z-bot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 8) Withdrawn by operator 21:59, 26 October 2009 (UTC)
- Robert SkyBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 4) Withdrawn by operator 00:44, 26 October 2009 (UTC)
- LuvRobot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 13:43, 16 October 2009 (UTC)
- Brunobot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 11:15, 6 October 2009 (UTC)
- MacMedBot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 08:00, 2 October 2009 (UTC)
- LivingBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 13) Withdrawn by operator 16:58, 30 September 2009 (UTC)
- FileBot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 04:55, 30 September 2009 (UTC)
- Erik9bot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 12) Withdrawn by operator 17:43, 13 September 2009 (UTC)
- SoxBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 18) Expired 00:52, 13 September 2009 (UTC)
- AbuseBot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 20:32, 3 September 2009 (UTC)
- Deonbot (BRFA · contribs · actions log · block log · flag log · user rights) Expired 00:52, 2 September 2009 (UTC)
- TedderBot (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 03:53, 15 August 2009 (UTC)
- MadmanBot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 9) Withdrawn by operator 21:30, 2 August 2009 (UTC)
- UnitBot (BRFA · contribs · actions log · block log · flag log · user rights) Expired 01:42, 1 August 2009 (UTC)
- CSDCheckBot (BRFA · contribs · actions log · block log · flag log · user rights) Expired 23:43, 31 July 2009 (UTC)
- SPCUClerkbot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 3) Expired 22:47, 31 July 2009 (UTC)
- CSDify (BRFA · contribs · actions log · block log · flag log · user rights) Withdrawn by operator 18:06, 31 July 2009 (UTC)
- Coreva-Bot (BRFA · contribs · actions log · block log · flag log · user rights) (Task: 2) Expired 03:32, 26 July 2009 (UTC)