
User:NE2/railroad redirects
| NE2/railroad redirects | |
|---|---|
| A a | |
 | |
| Usage | |
| Writing system | Latin script |
| Type | Alphabetic |
| Language of origin | Latin language |
| Sound values | |
| In Unicode | U+0041, U+0061 |
| Alphabetical position | 1 |
| History | |
| Development | |
| Time period | c. 700 BCE – present |
| Descendants | |
| Sisters | |
| Other | |
| Associated graphs | a(x), ae, eau, au |
| Writing direction | Left-to-right |
| NE2/railroad redirects |
| ISO basic Latin alphabet |
|---|
| AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz |
A, or a, is the first letter and the first vowel letter of the Latin alphabet,[1][2] used in the modern English alphabet, and others worldwide. Its name in English is a (pronounced /ˈeɪ/ AY), plural aes.[nb 1][2]
It is similar in shape to the Ancient Greek letter alpha, from which it derives.[3] The uppercase version consists of the two slanting sides of a triangle, crossed in the middle by a horizontal bar. The lowercase version is often written in one of two forms: the double-storey |a| and single-storey |ɑ|. The latter is commonly used in handwriting and fonts based on it, especially fonts intended to be read by children, and is also found in italic type.
In English, a is the indefinite article, with the alternative form an.
Name
In English, the name of the letter is the long A sound, pronounced /ˈeɪ/. Its name in most other languages matches the letter's pronunciation in open syllables.

History
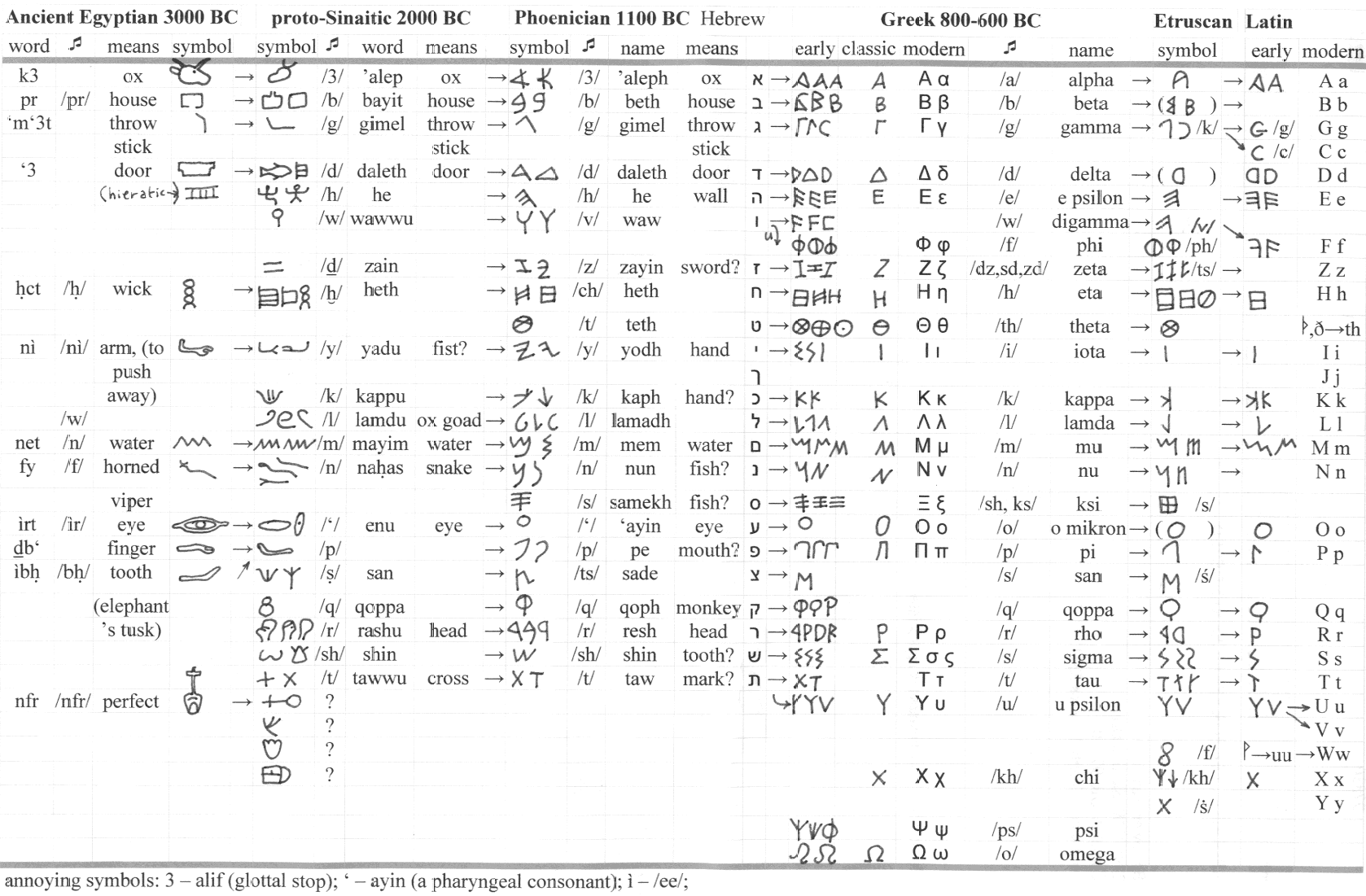
The earliest known ancestor of A is aleph—the first letter of the Phoenician alphabet[4]—where it represented a glottal stop [ʔ], as Phoenician only used consonantal letters. In turn, the ancestor of aleph may have been a pictogram of an ox head in proto-Sinaitic script[5] influenced by Egyptian hieroglyphs, styled as a triangular head with two horns extended.
When the ancient Greeks adopted the alphabet, they had no use for a letter representing a glottal stop—so they adapted sign to represent the vowel /a/, calling the letter by the similar name alpha. In the earliest Greek inscriptions dating to the 8th century BC following the Greek Dark Ages, the letter rests upon its side. However, in the later Greek alphabet it generally resembles the modern capital form—though many local varieties can be distinguished by the shortening of one leg, or by the angle at which the cross line is set.
The Etruscans brought the Greek alphabet to the Italian Peninsula, and left the form of alpha unchanged. When the Romans adopted the Etruscan alphabet to write Latin, the resulting form used in the Latin script would come to be used to write many other languages, including English.
| Egyptian | Proto-Sinaitic | Proto-Canaanite | Phoenician | Western Greek | Etruscan | Latin |
|---|---|---|---|---|---|---|
Typographic variants


During Roman times, there were many variant forms of the letter A. First was the monumental or lapidary style, which was used when inscribing on stone or other more permanent media. There was also a cursive style used for everyday or utilitarian writing, which was done on more perishable surfaces. Due to the perishable nature of these surfaces, there are not as many examples of this style as there are of the monumental, but there are still many surviving examples of different types of cursive, such as majuscule cursive, minuscule cursive, and semi-cursive minuscule. Variants also existed that were intermediate between the monumental and cursive styles. The known variants include the early semi-uncial, the uncial, and the later semi-uncial.[6]
 Blackletter Blackletter
|
||
 Roman Roman
|
 Italic Italic
|
 Script Script
|
At the end of the Roman Empire (5th century AD), several variants of the cursive minuscule developed through Western Europe. Among these were the semi-cursive minuscule of Italy, the Merovingian script in France, the Visigothic script in Spain, and the Insular or Anglo-Irish semi-uncial or Anglo-Saxon majuscule of Great Britain. By the ninth century, the Caroline script, which was very similar to the present-day form, was the principal form used in book-making, before the advent of the printing press. This form was derived through a combining of prior forms.[6]

15th-century Italy saw the formation of the two main variants that are known today. These variants, the Italic and Roman forms, were derived from the Caroline Script version. The Italic form ⟨ɑ⟩, also called script a, is often used in handwriting; it consists of a circle with a vertical stroke on its right. In the hands of medieval Irish and English writers, this form gradually developed from a 5th-century form resembling the Greek letter tau ⟨τ⟩.[4] The Roman form ⟨a⟩ is found in most printed material, and consists of a small loop with an arc over it.[6] Both derive from the majuscule form ⟨A⟩. In Greek handwriting, it was common to join the left leg and horizontal stroke into a single loop, as demonstrated by the uncial version shown. Many fonts then made the right leg vertical. In some of these, the serif that began the right leg stroke developed into an arc, resulting in the printed form, while in others it was dropped, resulting in the modern handwritten form. Graphic designers refer to the Italic and Roman forms as single-decker a and double decker a respectively.
Italic type is commonly used to mark emphasis or more generally to distinguish one part of a text from the rest set in Roman type. There are some other cases aside from italic type where script a ⟨ɑ⟩, also called Latin alpha, is used in contrast with Latin ⟨a⟩, such as in the International Phonetic Alphabet.
Use in writing systems
| Orthography | Phonemes |
|---|---|
| Standard Chinese (Pinyin) | /a/ |
| English | /æ/, /ɑː/, /ɒ/, /ɔː/, /ɛː/, /eɪ/, /ə/ |
| French | /a/, /ɑ/ |
| German | /a/, /aː/ |
| Portuguese | /a/, /ɐ/ |
| Saanich | /e/ |
| Spanish | /a/ |
| Turkish | /a/ |
English

In modern English orthography, the letter ⟨a⟩ represents at least seven different vowel sounds, here represented using the vowels of Received Pronunciation, with effects of ⟨r⟩ ignored and mergers in General American mentioned where relevant:
- the near-open front unrounded vowel /æ/ as in pad
- the open back unrounded vowel /ɑː/ as in father—merged with /ɒ/ as /ɑ/ in General American—which is closer to its original Latin and Greek sound[5]
- the open back rounded vowel /ɒ/ (merged with /ɑː/ as /ɑ/ in General American) in was and what[4]
- the open-mid back rounded vowel /ɔː/ in water
- the diphthong /eɪ/ as in ace and major, usually when ⟨a⟩ is followed by one, or occasionally two, consonants and then another vowel letter—this results from Middle English lengthening followed by the Great Vowel Shift
- a schwa /ə/ in many unstressed syllables, as in about, comma, solar
The double ⟨aa⟩ sequence does not occur in native English words, but is found in some words derived from foreign languages such as Aaron and aardvark.[8] However, ⟨a⟩ occurs in many common digraphs, all with their own sound or sounds, particularly ⟨ai⟩, ⟨au⟩, ⟨aw⟩, ⟨ay⟩, ⟨ea⟩ and ⟨oa⟩.
⟨a⟩ is the third-most-commonly used letter in English after ⟨e⟩ and ⟨t⟩, as well as in French; it is the second most common in Spanish, and the most common in Portuguese. ⟨a⟩ represents approximately 8.2% of letters as used in English texts;[9] the figure is around 7.6% in French[10] 11.5% in Spanish,[11] and 14.6% in Portuguese.[12]
Other languages
In most languages that use the Latin alphabet, ⟨a⟩ denotes an open unrounded vowel, such as /a/, /ä/, or /ɑ/. An exception is Saanich, in which ⟨a⟩—and the glyph ⟨Á⟩—stands for a close-mid front unrounded vowel /e/.
Other systems
- In the International Phonetic Alphabet, ⟨a⟩ is used for the open front unrounded vowel, ⟨ä⟩ is used for the open central unrounded vowel, and ⟨ɑ⟩ is used for the open back unrounded vowel.
- In X-SAMPA, ⟨a⟩ is used for the open front unrounded vowel and ⟨A⟩ is used for the open back unrounded vowel.
Other uses
- When using base-16 notation, A is the conventional numeral corresponding to the number 10.
- In algebra, the letter a along with various other letters of the alphabet is often used to denote a variable, with various conventional meanings in different areas of mathematics. In 1637, René Descartes "invented the convention of representing unknowns in equations by x, y, and z, and knowns by a, b, and c",[13] and this convention is still often followed, especially in elementary algebra.
- In geometry, capital Latin letters are used to denote objects including line segments, lines, and rays[6] A capital A is also typically used as one of the letters to represent an angle in a triangle, the lowercase a representing the side opposite angle A.[5]
- A is often used to denote something or someone of a better or more prestigious quality or status: A−, A or A+, the best grade that can be assigned by teachers for students' schoolwork; "A grade" for clean restaurants; A-list celebrities, etc. Such associations can have a motivating effect, as exposure to the letter A has been found to improve performance, when compared with other letters.[14]
- A is used to denote size, as in a narrow size shoe,[5] or a small cup size in a brassiere.[15]
Related characters
Latin alphabet
- ⟨Æ æ⟩: a ligature of ⟨AE⟩ originally used in Latin
- ⟨A⟩ with diacritics: Å å Ǻ ǻ Ḁ ḁ ẚ Ă ă Ặ ặ Ắ ắ Ằ ằ Ẳ ẳ Ẵ ẵ Ȃ ȃ Â â Ậ ậ Ấ ấ Ầ ầ Ẫ ẫ Ẩ ẩ Ả ả Ǎ ǎ Ⱥ ⱥ Ȧ ȧ Ǡ ǡ Ạ ạ Ä ä Ǟ ǟ À à Ȁ ȁ Á á Ā ā Ā̀ ā̀ Ã ã Ą ą Ą́ ą́ Ą̃ ą̃ A̲ a̲ ᶏ[16]
- Phonetic alphabet symbols related to A—the International Phonetic Alphabet only uses lowercase, but uppercase forms are used in some other writing systems:
- ⟨Ɑ ɑ⟩: Latin alpha, represents an open back unrounded vowel in the IPA
- ⟨ᶐ⟩: Latin small alpha with a retroflex hook[16]
- ⟨Ɐ ɐ⟩: Turned A, represents a near-open central vowel in the IPA
- ⟨Λ ʌ⟩: Turned V, represents an open-mid back unrounded vowel in IPA
- ⟨Ɒ ɒ⟩: Turned alpha or script A, represents an open back rounded vowel in the IPA
- ⟨ᶛ⟩: Modifier letter small turned alpha[16]
- ⟨ᴀ⟩: Small capital A, an obsolete or non-standard symbol in the International Phonetic Alphabet used to represent various sounds (mainly open vowels)
- ⟨A a ᵄ⟩: Modifier letters are used in the Uralic Phonetic Alphabet (UPA),[17] sometimes encoded with Unicode subscripts and superscripts
- ⟨a⟩: Subscript small a is used in Indo-European studies[18]
- ⟨ꬱ⟩: Small letter a reversed-schwa is used in the Teuthonista phonetic transcription system[19]
- ⟨Ꞻ ꞻ⟩: Glottal A, used in the transliteration of Ugaritic[20]
Derived signs, symbols and abbreviations
- ⟨ª⟩: ordinal indicator
- ⟨Å⟩: Ångström sign
- ⟨∀⟩: turned capital letter A, used in predicate logic to specify universal quantification ("for all")
- ⟨@⟩: At sign
- ⟨₳⟩: Argentine austral
- ⟨Ⓐ⟩: anarchy symbol
Ancestor and sibling letters
- ⟨𐤀⟩: Phoenician aleph, from which the following symbols originally derive:[21]
- ⟨Ա ա⟩: Armenian letter ayb
Other representations
Computing
The Latin letters ⟨A⟩ and ⟨a⟩ have Unicode encodings U+0041 A LATIN CAPITAL LETTER A and U+0061 a LATIN SMALL LETTER A. These are the same code points as those used in ASCII and ISO 8859. There are also precomposed character encodings for ⟨A⟩ and ⟨a⟩ with diacritics, for most of those listed above; the remainder are produced using combining diacritics.
Variant forms of the letter have unique code points for specialist use: the alphanumeric symbols set in mathematics and science, Latin alpha in linguistics, and halfwidth and fullwidth forms for legacy CJK font compatibility. The Cyrillic and Greek homoglyphs of the Latin ⟨A⟩ have separate encodings U+0410 А CYRILLIC CAPITAL LETTER A and U+0391 Α GREEK CAPITAL LETTER ALPHA.
Other
| NATO phonetic | Morse code |
| Alpha |

|
|

|

|

|
| Signal flag | Flag semaphore | American manual alphabet (ASL fingerspelling) | British manual alphabet (BSL fingerspelling) | Braille dots-1 Unified English Braille |

Notes
- ^ Aes is the plural of the name of the letter. The plural of the letter itself is rendered As, A's, as, or a's.
References
- ^ "Latin alphabet". Encyclopædia Britannica.
- ^ a b Simpson & Weiner 1989, p. 1.
- ^ McCarter 1974, p. 54.
- ^ a b c Hoiberg 2010, p. 1.
- ^ a b c d Hall-Quest 1997, p. 1.
- ^ a b c d Diringer 2000, p. 1.
- ^ Mankin, Jennifer; Simner, Julia (May 30, 2017). "A Is for Apple: the Role of Letter-Word Associations in the Development of Grapheme-Colour Synaesthesia" (PDF). Multisensory Research. 30 (3–5): 409–446. doi:10.1163/22134808-00002554. ISSN 2213-4794. PMID 31287075. Retrieved December 16, 2023.
- ^ Gelb & Whiting 1998, p. 45
- ^ "Letter frequency (English)". Archived from the original on 2021-03-04. Retrieved 2022-01-03.
- ^ "Corpus de Thomas Tempé" (in French). Archived from the original on 2007-09-30. Retrieved 2007-06-15.
- ^ Pratt, Fletcher (1942). Secret and Urgent: The story of codes and ciphers. Garden City, NY: Blue Ribbon. pp. 254–5. OCLC 795065.
- ^ "Frequência da ocorrência de letras no Português" (in Portuguese). Archived from the original on 2009-08-03. Retrieved 2009-06-16.
- ^ Tom Sorell, Descartes: A Very Short Introduction, (2000). New York: Oxford University Press. p. 19.
- ^ Ciani & Sheldon 2010, pp. 99–100.
- ^ Luciani, Jené (2009). The Bra Book: The Fashion Formula to Finding the Perfect Bra. Dallas: Benbella. p. 13. ISBN 978-1-933771-94-6.
- ^ a b c Constable, Peter (19 April 2004), L2/04-132 Proposal to Add Additional Phonetic Characters to the UCS (PDF), archived (PDF) from the original on 2017-10-11, retrieved 2018-03-24 – via www.unicode.org
- ^ Everson, Michael; et al. (20 March 2002), L2/02-141: Uralic Phonetic Alphabet Characters for the UCS (PDF), archived (PDF) from the original on 2018-02-19, retrieved 2018-03-24 – via www.unicode.org
- ^ Anderson, Deborah; Everson, Michael (7 June 2004), L2/04-191: Proposal to Encode Six Indo-Europeanist Phonetic Characters in the UCS (PDF), archived (PDF) from the original on 2017-10-11, retrieved 2018-03-24 – via www.unicode.org
- ^ Everson, Michael; Dicklberger, Alois; Pentzlin, Karl; Wandl-Vogt, Eveline (2 June 2011), L2/11-202: Revised Proposal to Encode "Teuthonista" Phonetic Characters in the UCS (PDF), archived (PDF) from the original on 2017-10-11, retrieved 2018-03-24 – via www.unicode.org
- ^ Suignard, Michel (9 May 2017), L2/17-076R2: Revised Proposal for the Encoding of an Egyptological YOD and Ugaritic Characters (PDF), archived (PDF) from the original on 2019-03-30, retrieved 8 March 2019 – via www.unicode.org
- ^ Jensen, Hans (1969). Sign, Symbol, and Script. New York: G. P. Putman's Sons.
- ^ "Hebrew Lesson of the Week: The Letter Aleph". 2013-02-17. Archived from the original on 2018-05-26. Retrieved 2018-05-25 – via The Times of Israel.
- ^ "Cyrillic Alphabet". Encyclopædia Britannica. Archived from the original on 2018-05-26. Retrieved 2018-05-25.
- ^ Silvestre, M. J. B. (1850). Universal Palaeography. Translated by Madden, Frederic. London: Henry G. Bohn. Retrieved 27 October 2020.
- ^ Frothingham, A. L. Jr. (1891). "Italic Studies". Archaeological News. American Journal of Archaeology. 7 (4): 534. JSTOR 496497. Retrieved 27 October 2020.
- ^ Steele, Philippa M., ed. (2017). Understanding Relations Between Scripts: The Aegean Writing Systems. Oxford: Oxbow. ISBN 978-1-78570-647-9. Retrieved 27 October 2020.
- ^ Fortson, Benjamin W. (2010). Indo-European Language and Culture: An Introduction (2nd ed.). Wiley. ISBN 978-1-4443-5968-8. Retrieved 27 October 2020.
Bibliography
- "English Letter Frequency". Math Explorer's Club. Cornell University. 2004. Archived from the original on 2014-04-22. Retrieved 2014-05-28.
- "Percentages of Letter Frequencies per Thousand Words". Trinity College. 2006. Archived from the original on 2007-01-25. Retrieved 2015-05-11.
- Ciani, Keith D.; Sheldon, Kennon M. (2010). "A Versus F: The Effects of Implicit Letter Priming on Cognitive Performance". British Journal of Educational Psychology. 80 (1): 99–119. doi:10.1348/000709909X466479. PMID 19622200.
- Diringer, David (2000). "A". In Bayer, Patricia (ed.). Encyclopedia Americana. Vol. I. Danbury, CT: Grolier. ISBN 978-0-717-20133-4.
- Gelb, I. J.; Whiting, R. M. (1998). "A". In Ranson, K. Anne (ed.). Academic American Encyclopedia. Vol. I. Danbury, CT: Grolier. ISBN 978-0-7172-2068-7.
- Hall-Quest, Olga Wilbourne (1997). "A". In Johnston, Bernard (ed.). Collier's Encyclopedia. Vol. I. New York: P. F. Collier.
- Hoiberg, Dale H., ed. (2010). "A". Encyclopædia Britannica. Vol. 1. Chicago. ISBN 978-1-59339-837-8.
{{cite encyclopedia}}: CS1 maint: location missing publisher (link) - McCarter, P. Kyle (1974). "The Early Diffusion of the Alphabet". The Biblical Archaeologist. 37 (3): 54–68. JSTOR 3210965. S2CID 126182369.
- Simpson, J. A.; Weiner, E. S. C., eds. (1989). "A". Oxford English Dictionary. Vol. I (2nd ed.). Oxford University Press. ISBN 978-0-19-861213-1.
External links
- History of the Alphabet Archived 10 April 2021 at the Wayback Machine
 Texts on Wikisource:
Texts on Wikisource:
- "A" in A Dictionary of the English Language by Samuel Johnson
- . Encyclopædia Britannica. Vol. I (9th ed.). 1878. p. 1.
- "A". The American Cyclopædia. 1879.
- "A". Encyclopædia Britannica. Vol. I (11th ed.). 1911. p. 1.
- "A". The New Student's Reference Work. 1914.
- "A". Collier's New Encyclopedia. 1921.
| B | |
|---|---|
| B b | |
 | |
| Usage | |
| Writing system | Latin script English alphabet ISO basic Latin alphabet |
| Type | Alphabetic |
| Language of origin | Latin language |
| Sound values | (Adapted variations) |
| In Unicode | U+0042, U+0062 |
| Alphabetical position | 2 Numerical value: 2 |
| History | |
| Development | |
| Time period | unknown to present |
| Descendants | |
| Sisters | |
| Other | |
| Associated graphs | bv bh bp bm bf |
| Associated numbers | 2 |
| Writing direction | Left-to-right |
| NE2/railroad redirects |
| ISO basic Latin alphabet |
|---|
| AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz |
B, or b, is the second letter of the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is bee (pronounced /ˈbiː/), plural bees.[1][2]
It represents the voiced bilabial stop in many languages, including English. In some other languages, it is used to represent other bilabial consonants.
History
| Egyptian Pr |
Phoenician bēt |
Western Greek beta |
Etruscan B |
Latin B |
|---|---|---|---|---|

|
The Roman ⟨B⟩ derived from the Greek capital beta ⟨Β⟩ via its Etruscan and Cumaean variants. The Greek letter was an adaptation of the Phoenician letter bēt ⟨𐤁⟩.[3] The Egyptian hieroglyph for the consonant /b/ had been an image of a foot and calf ⟨ ![]() ⟩,[4] but bēt (Phoenician for "house") was a modified form of a Proto-Sinaitic glyph ⟨
⟩,[4] but bēt (Phoenician for "house") was a modified form of a Proto-Sinaitic glyph ⟨ ![]() ⟩ adapted from the separate hieroglyph Pr ⟨
⟩ adapted from the separate hieroglyph Pr ⟨ ![]() ⟩ meaning "house".[5][a] The Hebrew letter bet ⟨ב⟩ is a separate development of the Phoenician letter.[3]
⟩ meaning "house".[5][a] The Hebrew letter bet ⟨ב⟩ is a separate development of the Phoenician letter.[3]
By Byzantine times, the Greek letter ⟨Β⟩ came to be pronounced /v/,[3] so that it is known in modern Greek as víta (still written βήτα). The Cyrillic letter ve ⟨В⟩ represents the same sound, so a modified form known as be ⟨Б⟩ was developed to represent the Slavic languages' /b/.[3] (Modern Greek continues to lack a letter for the voiced bilabial plosive and transliterates such sounds from other languages using the digraph/consonant cluster ⟨μπ⟩, mp.)
Old English was originally written in runes, whose equivalent letter was beorc ⟨ᛒ⟩, meaning "birch". Beorc dates to at least the 2nd-century Elder Futhark, which is now thought to have derived from the Old Italic alphabets' ⟨ 𐌁 ⟩ either directly or via Latin ⟨![]() ⟩.
⟩.
The uncial ⟨![]() ⟩ and half-uncial ⟨
⟩ and half-uncial ⟨![]() ⟩ introduced by the Gregorian and Irish missions gradually developed into the Insular scripts' ⟨
⟩ introduced by the Gregorian and Irish missions gradually developed into the Insular scripts' ⟨![]() ⟩. These Old English Latin alphabets supplanted the earlier runes, whose use was fully banned under King Canute in the early 11th century. The Norman Conquest popularised the Carolingian half-uncial forms which latter developed into blackletter ⟨
⟩. These Old English Latin alphabets supplanted the earlier runes, whose use was fully banned under King Canute in the early 11th century. The Norman Conquest popularised the Carolingian half-uncial forms which latter developed into blackletter ⟨ ![]() ⟩. Around 1300, letter case was increasingly distinguished, with upper- and lower-case B taking separate meanings. Following the advent of printing in the 15th century, the Holy Roman Empire (Germany) and Scandinavia continued to use forms of blackletter (particularly Fraktur), while England eventually adopted the humanist and antiqua scripts developed in Renaissance Italy from a combination of Roman inscriptions and Carolingian texts. The present forms of the English cursive B were developed by the 17th century.
⟩. Around 1300, letter case was increasingly distinguished, with upper- and lower-case B taking separate meanings. Following the advent of printing in the 15th century, the Holy Roman Empire (Germany) and Scandinavia continued to use forms of blackletter (particularly Fraktur), while England eventually adopted the humanist and antiqua scripts developed in Renaissance Italy from a combination of Roman inscriptions and Carolingian texts. The present forms of the English cursive B were developed by the 17th century.

Use in writing systems
| Orthography | Phonemes |
|---|---|
| Standard Chinese (Pinyin) | /p/ |
| English | /b/ |
| French | /b/, /p/ |
| German | /b/, /p/ |
| Portuguese | /b/ |
| Spanish | /b/ |
| Turkish | /b/ |
English
In English, ⟨b⟩ denotes the voiced bilabial stop /b/, as in bib. In English, it is sometimes silent. This occurs particularly in words ending in ⟨mb⟩, such as lamb and bomb, some of which originally had a /b/ sound, while some had the letter ⟨b⟩ added by analogy (see Phonological history of English consonant clusters). The ⟨b⟩ in debt, doubt, subtle, and related words was added in the 16th century as an etymological spelling, intended to make the words more like their Latin originals (debitum, dubito, subtilis).
As /b/ is one of the sounds subject to Grimm's Law, words which have ⟨b⟩ in English and other Germanic languages may find their cognates in other Indo-European languages appearing with ⟨bh⟩, ⟨p⟩, ⟨f⟩ or ⟨φ⟩ instead.[3] For example, compare the various cognates of the word brother. It is the seventh least frequently used letter in the English language (after V, K, J, X, Q, and Z), with a frequency of about 1.5% in words.
Other languages
Many other languages besides English use ⟨b⟩ to represent a voiced bilabial stop.
In Estonian, Danish, Faroese, Icelandic, Scottish Gaelic and Mandarin Chinese Pinyin, ⟨b⟩ does not denote a voiced consonant. Instead, it represents a voiceless /p/ that contrasts with either a geminated /pː/ (in Estonian) or an aspirated /ph/ (in Danish, Faroese, Icelandic, Scottish Gaelic and Pinyin) represented by ⟨p⟩. In Fijian ⟨b⟩ represents a prenasalised /mb/, whereas in Zulu and Xhosa it represents an implosive /ɓ/, in contrast to the digraph ⟨bh⟩ which represents /b/. Finnish uses ⟨b⟩ only in loanwords.
Other systems
In the International Phonetic Alphabet, [b] is used to represent the voiced bilabial stop phone. In phonological transcription systems for specific languages, /b/ may be used to represent a lenis phoneme, not necessarily voiced, that contrasts with fortis /p/ (which may have greater aspiration, tenseness or duration).
Other uses
- In the base-16 numbering system, B is a number that corresponds to the number 11 in decimal (base 10) counting.
- B is a musical note. In English-speaking countries, it represents Si, the 12th note of a chromatic scale built on C. In Central Europe and Scandinavia, "B" is used to denote B-flat and the 12th note of the chromatic scale is denoted "H". Archaic forms of 'b', the b quadratum (square b, ♮) and b rotundum (round b, ♭) are used in musical notation as the symbols for natural and flat, respectively.
- In Contracted (grade 2) English braille, ⟨b⟩ stands for "but" when in isolation.
- In computer science, B is the symbol for byte, a unit of information storage.
- In engineering, B is the symbol for bel, a unit of level.
- In chemistry, B is the symbol for boron, a chemical element.
Related characters
Ancestors, descendants and siblings
- 𐤁 : Semitic letter Bet, from which the following symbols originally derive
- Β β : Greek letter Beta, from which B derives
- Ⲃ ⲃ Coptic letter Bēta, which derives from Greek Beta
- В в : Cyrillic letter Ve, which also derives from Beta
- Б б : Cyrillic letter Be, which also derives from Beta
- ʙ : A small capital B, used as the lowercase B in a number of alphabets during romanization
- 𐌁 : Old Italic B, which derives from Greek Beta
- ᛒ : Runic letter Berkanan, which probably derives from Old Italic B
- 𐌱 : Gothic letter bercna, which derives from Greek Beta
- IPA-specific symbols related to B: ɓ ʙ β 𐞄[6] 𐞅[6]
- B with diacritics: Ƀ ƀ Ḃ ḃ Ḅ ḅ Ḇ ḇ Ɓ ɓ ᵬ[7] ᶀ[8]
- Ꞗ ꞗ : B with flourish
- ᴃ ᴯ B b : Barred B and various modifier letters are used in the Uralic Phonetic Alphabet.[9]
- Ƃ ƃ : B with topbar
Derived ligatures, abbreviations, signs and symbols
- ␢ : U+2422 ␢ BLANK SYMBOL
- ฿ : Thai baht
- ₿ : Bitcoin
- ♭: The flat in music, mentioned above, still closely resembles lowercase b.
Other representations
Computing
The Latin letters ⟨B⟩ and ⟨b⟩ have Unicode encodings U+0042 B LATIN CAPITAL LETTER B and U+0062 b LATIN SMALL LETTER B. These are the same code points as those used in ASCII and ISO 8859. There are also precomposed character encodings for ⟨B⟩ and ⟨b⟩ with diacritics, for most of those listed above; the remainder are produced using combining diacritics.
Variant forms of the letter have unique code points for specialist use: the alphanumeric symbols set in mathematics and science, Latin beta in linguistics, and halfwidth and fullwidth forms for legacy CJK font compatibility. The Cyrillic and Greek homoglyphs of the Latin ⟨B⟩ have separate encodings: U+0412 В CYRILLIC CAPITAL LETTER VE and U+0392 Β GREEK CAPITAL LETTER BETA.
Other
| NATO phonetic | Morse code |
| Bravo |

|
|

|

|

|
| Signal flag | Flag semaphore | American manual alphabet (ASL fingerspelling) | British manual alphabet (BSL fingerspelling) | Braille dots-12 Unified English Braille |

Notes
- ^ It also resembles the hieroglyph for /h/ ⟨
 ⟩ meaning "manor" or "reed shelter".
⟩ meaning "manor" or "reed shelter".
References
- ^ "B", Oxford English Dictionary, 2nd ed., Oxford: Oxford University Press, 1989
- ^ "B", Merriam-Webster's 3rd New International Dictionary of the English Language, Unabridged, 1993
- ^ a b c d e Baynes, T. S., ed. (1878), , Encyclopædia Britannica, vol. 3 (9th ed.), New York: Charles Scribner's Sons, p. 173
- ^ Schumann-Antelme, Ruth; Rossini, Stéphane (1998), Illustrated Hieroglyphics Handbook, English translation by Sterling Publishing (2002), pp. 22–23, ISBN 1-4027-0025-3
- ^ Goldwasser, Orly (Mar–Apr 2010), "How the Alphabet Was Born from Hieroglyphs", Biblical Archaeology Review, vol. 36, Washington: Biblical Archaeology Society, ISSN 0098-9444, archived from the original on 30 June 2016, retrieved 11 August 2015
- ^ a b Miller, Kirk; Ashby, Michael (2020-11-08). "L2/20-252R: Unicode request for IPA modifier-letters (a), pulmonic" (PDF).
- ^ Constable, Peter (30 September 2003). "L2/03-174R2: Proposal to Encode Phonetic Symbols with Middle Tilde in the UCS" (PDF). Archived (PDF) from the original on 11 October 2017. Retrieved 24 March 2018.
- ^ Constable, Peter (19 April 2004). "L2/04-132 Proposal to add additional phonetic characters to the UCS" (PDF). Archived (PDF) from the original on 11 October 2017. Retrieved 24 March 2018.
- ^ Everson, Michael; et al. (20 March 2002). "L2/02-141: Uralic Phonetic Alphabet characters for the UCS" (PDF). Archived (PDF) from the original on 19 February 2018. Retrieved 24 March 2018.
External links
 Media related to NE2/railroad redirects at Wikimedia Commons
Media related to NE2/railroad redirects at Wikimedia Commons The dictionary definition of B at Wiktionary
The dictionary definition of B at Wiktionary- The dictionary definition of b at Wiktionary
- Giles, Peter (1911), , Encyclopædia Britannica, vol. 3 (11th ed.), p. 87
| C | |
|---|---|
| C c | |
 | |
| Usage | |
| Writing system | Latin script |
| Type | Alphabetic |
| Language of origin | Latin language |
| Sound values | |
| In Unicode | U+0043, U+0063 |
| Alphabetical position | 3 Numerical value: 100 |
| History | |
| Development | |
| Sisters | |
| Other | |
| Associated numbers | 100 |
| NE2/railroad redirects |
| ISO basic Latin alphabet |
|---|
| AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz |

C, or c, is the third letter of the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is cee (pronounced /ˈsiː/), plural cees.[1]
History
| Egyptian | Phoenician gaml |
Western Greek Gamma |
Etruscan C |
Old Latin C (G) |
Latin C | ||
|---|---|---|---|---|---|---|---|
|
"C" comes from the same letter as "G". The Semites named it gimel. The sign is possibly adapted from an Egyptian hieroglyph for a staff sling, which may have been the meaning of the name gimel. Another possibility is that it depicted a camel, the Semitic name for which was gamal. Barry B. Powell, a specialist in the history of writing, states "It is hard to imagine how gimel = "camel" can be derived from the picture of a camel (it may show his hump, or his head and neck!)".[2]
In the Etruscan language, plosive consonants had no contrastive voicing, so the Greek 'Γ' (Gamma) was adopted into the Etruscan alphabet to represent /k/. Already in the Western Greek alphabet, Gamma first took a '![]() ' form in Early Etruscan, then '
' form in Early Etruscan, then '![]() ' in Classical Etruscan. In Latin, it eventually took the 'c' form in Classical Latin. In the earliest Latin inscriptions, the letters 'c k q' were used to represent the sounds /k/ and /ɡ/ (which were not differentiated in writing). Of these, 'q' was used to represent /k/ or /ɡ/ before a rounded vowel, 'k' before 'a', and 'c' elsewhere.[3] During the 3rd century BC, a modified character was introduced for /ɡ/, and 'c' itself was retained for /k/. The use of 'c' (and its variant 'g') replaced most usages of 'k' and 'q'. Hence, in the classical period and after, 'g' was treated as the equivalent of Greek gamma, and 'c' as the equivalent of kappa; this shows in the romanization of Greek words, as in 'ΚΑΔΜΟΣ', 'ΚΥΡΟΣ', and 'ΦΩΚΙΣ' came into Latin as 'cadmvs', 'cyrvs' and 'phocis', respectively.
' in Classical Etruscan. In Latin, it eventually took the 'c' form in Classical Latin. In the earliest Latin inscriptions, the letters 'c k q' were used to represent the sounds /k/ and /ɡ/ (which were not differentiated in writing). Of these, 'q' was used to represent /k/ or /ɡ/ before a rounded vowel, 'k' before 'a', and 'c' elsewhere.[3] During the 3rd century BC, a modified character was introduced for /ɡ/, and 'c' itself was retained for /k/. The use of 'c' (and its variant 'g') replaced most usages of 'k' and 'q'. Hence, in the classical period and after, 'g' was treated as the equivalent of Greek gamma, and 'c' as the equivalent of kappa; this shows in the romanization of Greek words, as in 'ΚΑΔΜΟΣ', 'ΚΥΡΟΣ', and 'ΦΩΚΙΣ' came into Latin as 'cadmvs', 'cyrvs' and 'phocis', respectively.
Other alphabets have letters homoglyphic to 'c' but not analogous in use and derivation, like the Cyrillic letter Es (С, с) which derives from the lunate sigma.
Later use
When the Roman alphabet was introduced into Britain, ⟨c⟩ represented only /k/, and this value of the letter has been retained in loanwords to all the insular Celtic languages: in Welsh,[4] Irish, and Gaelic, ⟨c⟩ represents only /k/. The Old English Latin-based writing system was learned from the Celts, apparently of Ireland; hence, ⟨c⟩ in Old English also originally represented /k/; the Modern English words kin, break, broken, thick, and seek all come from Old English words written with ⟨c⟩: cyn, brecan, brocen, þicc, and séoc. However, during the course of the Old English period, /k/ before front vowels (/e/ and /i/) was palatalized, having changed by the tenth century to [tʃ], though ⟨c⟩ was still used, as in cir(i)ce, wrecc(e)a. On the continent, meanwhile, a similar phonetic change before the same two vowels had also been going on in almost all modern romance languages (for example, in Italian).
In Vulgar Latin, /k/ became palatalized to [tʃ] in Italy and Dalmatia; in France and the Iberian Peninsula, it became [ts]. Yet for these new sounds, ⟨c⟩ was still used before the letters ⟨e⟩ and ⟨i⟩. The letter thus represented two distinct values. Subsequently, the Latin phoneme /kw/ (spelled ⟨qv⟩) de-labialized to /k/, meaning that the various Romance languages had /k/ before front vowels. In addition, Norman used the letter ⟨k⟩ so that the sound /k/ could be represented by either ⟨k⟩ or ⟨c⟩, the latter of which could represent either /k/ or /ts/ depending on whether it preceded a front vowel letter or not. The convention of using both ⟨c⟩ and ⟨k⟩ was applied to the writing of English after the Norman Conquest, causing a considerable re-spelling of the Old English words. Thus, while Old English candel, clif, corn, crop, and cú, remained unchanged, cent, cǣᵹ (cēᵹ), cyng, brece, and sēoce, were now (without any change of sound) spelled Kent, keȝ, kyng, breke, and seoke; even cniht ('knight') was subsequently changed to kniht, and þic ('thick') was changed to thik or thikk. The Old English ⟨cw⟩ was also at length displaced by the French ⟨qu⟩ so that the Old English cwēn ('queen') and cwic ('quick') became Middle English quen and quik, respectively.
The sound [tʃ], to which Old English palatalized /k/ had advanced, also occurred in French, chiefly from Latin /k/ before ⟨a⟩. In French, it was represented by the digraph ⟨ch⟩, as in champ (from Latin camp-um), and this spelling was introduced into English: the Hatton Gospels, written c. 1160, have in Matt. i-iii, child, chyld, riche, and mychel, for the cild, rice, and mycel of the Old English version whence they were copied. In these cases, the Old English ⟨c⟩ gave way to ⟨k⟩, ⟨qu⟩ and ⟨ch⟩; on the other hand, ⟨c⟩ in its new value of /ts/ appeared largely in French words like processiun, emperice, and grace and was also substituted for ⟨ts⟩ in a few Old English words, as miltse, bletsien, in early Middle English milce, blecien. By the end of the thirteenth century, both in France and England, this sound /ts/ was de-affricated to /s/; and from that time, ⟨c⟩ has represented /s/ before front vowels either for etymological reasons, as in lance, cent, or to avoid the ambiguity due to the "etymological" use of ⟨s⟩ for /z/, as in ace, mice, once, pence, defence.
Thus, to show etymology, English spelling has advise, devise (instead of *advize, *devize), while advice, device, dice, ice, mice, twice, etc., do not reflect etymology; example has extended this to hence, pence, defence, etc., where there is no etymological reason for using ⟨c⟩. Former generations also wrote sence for sense. Hence, today, the Romance languages and English have a common feature inherited from Vulgar Latin spelling conventions where ⟨c⟩ takes on either a "hard" or "soft" value depending on the following letter.
Use in writing systems
| Orthography | Phonemes | Environment |
|---|---|---|
| Albanian | /ts/ | |
| Cypriot Arabic | /ʕ/ | |
| Azeri | /dʒ/ | |
| Berber | /ʃ/ | |
| Bukawa | /ʔ/ | |
| Catalan | /k/ | Except before e, i |
| /s/ | Before e, i | |
| Standard Chinese (Pinyin) | /tsʰ/ | |
| Crimean Tatar | /dʒ/ | |
| Cornish (Standard Written Form) | /s/ | |
| Czech | /ts/ | |
| Danish | /k/ | Except before e, i, y, æ, ø |
| /s/ | Before e, i, y, æ, ø | |
| Dutch | /k/ | Except before e, i, y |
| /s/ | Before e, i, y | |
| /tʃ/ | Before e, i in loanwords from Italian | |
| English | /k/ | Except before e, i, y |
| /s/ | Before e, i, y | |
| /ʃ/ | Before ea, ia, ie, io, iu | |
| Esperanto | /ts/ | |
| Fijian | /ð/ | |
| Filipino | /k/ | Except before e, i |
| /s/ | Before e, i | |
| French | /k/ | Except before e, i, y |
| /s/ | Before e, i, y | |
| Fula | /tʃ/ | |
| Gagauz | /dʒ/ | |
| Galician | /k/ | Except before e, i |
| /θ/ or /s/ | Before e, i | |
| German | /k/ | Except before ä, e, i, ö, ü, y in loanwords and names |
| /ts/ | Before ä, e, i, ö, ü, y in loanwords and names | |
| Hausa | /tʃ/ | |
| Hungarian | /ts/ | |
| Indonesian | /tʃ/ | |
| Irish | /k/ | Except before e, i; or after i |
| /c/ | Before e, i; or after i | |
| Italian | /k/ | Except before e, i |
| /tʃ/ | Before e, i | |
| Khmer (ALA-LC) | /c/ | |
| Kurmanji (Hawar) | /dʒ/ | |
| Latin | /k/ (and /g/ in early Latin) | |
| Latvian | /ts/ | |
| Malay | /tʃ/ | |
| Manding | /tʃ/ | |
| Norwegian | /k/ | Except before e, i, y, æ, ø in loanwords and names |
| /s/ | Before e, i, y, æ, ø in loanwords and names | |
| Polish | /ts/ | Except before i |
| /tɕ/ | Before i | |
| Portuguese | /k/ | Except before e, i, y |
| /s/ | Before e, i, y | |
| Romanian | /k/ | Except before e, i |
| /tʃ/ | Before e, i | |
| Romansh | /k/ | Except before e, i |
| /ts/ | Before e, i | |
| Scottish Gaelic | /kʰ/ | Except before e, i; or after i |
| /kʰʲ/ | Before e, i; or after i | |
| Serbo-Croatian | /ts/ | |
| Slovak | /ts/ | |
| Slovene | /ts/ | |
| Somali | /ʕ/ | |
| Spanish | /k/ | Except before e, i, y |
| /θ/ or /s/ | Before e, i, y | |
| Swedish | /k/ | Except before e, i, y, ä, ö |
| /s/ | Before e, i, y, ä, ö | |
| Tajik | /tʃ/ | |
| Tatar | /ʑ/ | |
| Turkish | /dʒ/ | |
| Valencian | /k/ | Except before e, i |
| /s/ | Before e, i | |
| Vietnamese | /k/ | Except word-finally |
| /k̚/ | Word-finally | |
| Welsh | /k/ | |
| Xhosa | /ǀ/ | |
| Yabem | /ʔ/ | |
| Yup'ik | /tʃ/ | |
| Zulu | /ǀ/ |
English
In English orthography, ⟨c⟩ generally represents the "soft" value of /s/ before the letters ⟨e⟩ (including the Latin-derived digraphs ⟨ae⟩ and ⟨oe⟩, or the corresponding ligatures ⟨æ⟩ and ⟨œ⟩), ⟨i⟩, and ⟨y⟩, and a "hard" value of /k/ before any other letters or at the end of a word. However, there are a number of exceptions in English: "soccer" and "Celt" are words that have /k/ where /s/ would be expected. The "soft" ⟨c⟩ may represent the /ʃ/ sound in the digraph ⟨ci⟩ when this precedes a vowel, as in the words 'delicious' and 'appreciate', and also in the word "ocean" and its derivatives.
The digraph ⟨ch⟩ most commonly represents /tʃ/, but can also represent /k/ (mainly in words of Greek origin) or /ʃ/ (mainly in words of French origin). For some dialects of English, it may also represent /x/ in words like loch, while other speakers pronounce the final sound as /k/. The trigraph ⟨tch⟩ always represents /tʃ/. The digraph ⟨ck⟩ is often used to represent the sound /k/ after short vowels, like in "wicket".
C is the twelfth most frequently used letter in the English language (after E, T, A, O, I, N, S, H, R, D, and L), with a frequency of about 2.8% in words.
Other languages
In the Romance languages French, Spanish, Italian, Romanian, and Portuguese, ⟨c⟩ generally has a "hard" value of /k/ and a "soft" value whose pronunciation varies by language. In French, Portuguese, Catalan, and Spanish from Latin America and some places in Spain, the soft ⟨c⟩ value is /s/ as it is in English. In the Spanish spoken in most of Spain, the soft ⟨c⟩ is a voiceless dental fricative /θ/. In Italian and Romanian, the soft ⟨c⟩ is [t͡ʃ].
Germanic languages usually use ⟨c⟩ for Romance loans or digraphs, such as ⟨ch⟩ and ⟨ck⟩, but the rules vary across languages. Of all the Germanic languages, only English uses the initial ⟨c⟩ in native Germanic words like come. Other than English, Dutch uses ⟨c⟩ the most, for most Romance loans and the digraph ⟨ch⟩. German uses ⟨c⟩ in the digraphs ⟨ch⟩ and ⟨ck⟩, and the trigraph ⟨sch⟩, but by itself only in unassimilated loanwords and proper names. Danish keeps soft ⟨c⟩ in Romance words but changes hard ⟨c⟩ to ⟨k⟩. Swedish has the same rules for soft and hard ⟨c⟩ as Danish, and also uses ⟨c⟩ in the digraph ⟨ck⟩ and the very common word och, "and". Norwegian, Afrikaans, and Icelandic are the most restrictive, replacing all cases of ⟨c⟩ with ⟨k⟩ or ⟨s⟩, and reserving ⟨c⟩ for unassimilated loanwords and names.
All Balto-Slavic languages that use the Latin alphabet, as well as Albanian, Hungarian, Pashto, several Sami languages, Esperanto, Ido, Interlingua, and Americanist phonetic notation (and those aboriginal languages of North America whose practical orthography derives from it), use ⟨c⟩ to represent /t͡s/, the voiceless alveolar or voiceless dental sibilant affricate. In Hanyu Pinyin, the standard romanization of Mandarin Chinese, the letter represents an aspirated version of this sound, /t͡sh/.
Among non-European languages that have adopted the Latin alphabet, ⟨c⟩ represents a variety of sounds. Yup'ik, Indonesian, Malay, and a number of African languages such as Hausa, Fula, and Manding share the soft Italian value of /t͡ʃ/. In Azeri, Crimean Tatar, Kurmanji Kurdish, and Turkish, ⟨c⟩ stands for the voiced counterpart of this sound, the voiced postalveolar affricate /d͡ʒ/. In Yabem and similar languages, such as Bukawa, ⟨c⟩ stands for a glottal stop /ʔ/. Xhosa and Zulu use this letter to represent the click /ǀ/. In some other African languages, such as Berber languages, ⟨c⟩ is used for /ʃ/. In Fijian, ⟨c⟩ stands for a voiced dental fricative /ð/, while in Somali it has the value of /ʕ/.
The letter ⟨c⟩ is also used as a transliteration of Cyrillic ⟨ц⟩ in the Latin forms of Serbian, Macedonian, and sometimes Ukrainian, along with the digraph ⟨ts⟩.
Other systems
As a phonetic symbol, lowercase ⟨c⟩ is the International Phonetic Alphabet (IPA) and X-SAMPA symbol for the voiceless palatal plosive, and capital ⟨C⟩ is the X-SAMPA symbol for the voiceless palatal fricative.
Digraphs
There are several common digraphs with ⟨c⟩, the most common being ⟨ch⟩, which in some languages (such as German) is far more common than ⟨c⟩ alone. ⟨ch⟩ takes various values in other languages.
As in English, ⟨ck⟩, with the value /k/, is often used after short vowels in other Germanic languages such as German and Swedish (other Germanic languages, such as Dutch and Norwegian, use ⟨kk⟩ instead). The digraph ⟨cz⟩ is found in Polish and ⟨cs⟩ in Hungarian, representing /t͡ʂ/ and /t͡ʃ/ respectively. The digraph ⟨sc⟩ represents /ʃ/ in Old English, Italian, and a few languages related to Italian (where this only happens before front vowels, while otherwise it represents /sk/). The trigraph ⟨sch⟩ represents /ʃ/ in German.
Other uses
- In the hexadecimal (base 16) numbering system, C is a number that corresponds to the number 12 in decimal (base 10) counting.
- In the Roman numeral system, C represents 100.
- Unit prefix c, meaning one hundredth.
Related characters
Ancestors, descendants and siblings

- 𐤂 : Semitic letter Gimel, from which the following symbols originally derive:
- Phonetic alphabet symbols related to C:
- ɕ : Small c with curl
- ʗ : Stretched c
- 𝼏 : Stretched c with curl – Used by Douglas Beach for a nasal click in his phonetic description of Khoekhoe.[5]
- 𝼝 : Small letter c with retroflex hook – Para-IPA version of the IPA retroflex tʂ.[6]
- ꟲ : Modifier letter capital c – Used to mark tone for the Chatino orthography in Oaxaca, Mexico; used as a generic transcription for a falling tone; also used in para-IPA notation.[7]
- ᶜ : Modifier letter small c[8]
- ᶝ : Modifier letter small c with curl[8]
- ᴄ : Small capital c is used in the Uralic Phonetic Alphabet.[9]
- Ꞔ ꞔ : C with palatal hook, used for writing Mandarin Chinese using the early draft version of pinyin romanization during the mid-1950s.[10]
Add to C with diacritics:
Derived ligatures, abbreviations, signs and symbols
- © : copyright symbol
- °C : degree Celsius
- ¢ : cent
- ₡ : colón (currency)
- ₢ : Brazilian cruzeiro (currency)
- ₵ : Ghana cedi (currency)
- ₠ : European Currency Unit CE
- : blackboard bold C, denoting the complex numbers
- ℭ : blackletter C
- Ꜿ ꜿ : Medieval abbreviation for Latin syllables con- and com-, and Portuguese -us and -os.[12]

Other representations
Computing
The Latin letters ⟨C⟩ and ⟨c⟩ have Unicode encodings U+0043 C LATIN CAPITAL LETTER C and U+0063 c LATIN SMALL LETTER C. These are the same code points as those used in ASCII and ISO 8859. There are also precomposed character encodings for ⟨C⟩ and ⟨c⟩ with diacritics, for most of those listed above; the remainder are produced using combining diacritics.
Variant forms of the letter have unique code points for specialist use: the alphanumeric symbols set in mathematics and science, voiceless palatal sounds in linguistics, and halfwidth and fullwidth forms for legacy CJK font compatibility. The Cyrillic homoglyph of the Latin ⟨C⟩ has a separate encoding: U+0421 С CYRILLIC CAPITAL LETTER ES.
Other
| NATO phonetic | Morse code |
| Charlie |

|
|

|

|

|
| Signal flag | Flag semaphore | American manual alphabet (ASL fingerspelling) | British manual alphabet (BSL fingerspelling) | Braille dots-14 Unified English Braille |

{kind=link}
{kind=link}
{kind=link}
See also
References
- ^ "C" Oxford English Dictionary, 2nd edition (1989); Merriam-Webster's Third New International Dictionary of the English Language, Unabridged (1993); "cee", op. cit.
- ^ Powell, Barry B. (27 Mar 2009). Writing: Theory and History of the Technology of Civilization. Wiley Blackwell. p. 182. ISBN 978-1405162562.
- ^ Sihler, Andrew L. (1995). New Comparative Grammar of Greek and Latin (illustrated ed.). New York: Oxford University Press. p. 21. ISBN 0-19-508345-8.
- ^ "Reading Middle Welsh -- 29 Medieval Spelling". www.mit.edu. Retrieved 2019-11-19.
- ^ Miller, Kirk; Sands, Bonny (2020-07-10). "L2/20-115R: Unicode request for additional phonetic click letters" (PDF).
- ^ Miller, Kirk (2021-01-11). "L2/21-041: Unicode request for additional para-IPA letters" (PDF).
- ^ Miller, Kirk; Cornelius, Craig (2020-09-25). "L2/20-251: Unicode request for modifier Latin capital letters" (PDF).
- ^ a b Constable, Peter (2004-04-19). "L2/04-132 Proposal to add additional phonetic characters to the UCS" (PDF).
- ^ Everson, Michael; et al. (2002-03-20). "L2/02-141: Uralic Phonetic Alphabet characters for the UCS" (PDF).
- ^ West, Andrew; Chan, Eiso; Everson, Michael (2017-01-16). "L2/17-013: Proposal to encode three uppercase Latin letters used in early Pinyin" (PDF).
- ^ Everson, Michael (2005-08-12). "L2/05-193R2: Proposal to add Claudian Latin letters to the UCS" (PDF).
- ^ Everson, Michael; Baker, Peter; Emiliano, António; Grammel, Florian; Haugen, Odd Einar; Luft, Diana; Pedro, Susana; Schumacher, Gerd; Stötzner, Andreas (2006-01-30). "L2/06-027: Proposal to add Medievalist characters to the UCS" (PDF).
External links
- Media related to NE2/railroad redirects at Wikimedia Commons
- The dictionary definition of C at Wiktionary
- The dictionary definition of c at Wiktionary